
热门标签
热门文章
- 1vue 子父组件传值,this.$emit 的使用_父组件 调用 this.$emit
- 2【入门向】k-means聚类函数详解(基于鸢尾花数据集)【MATLAB】_kmeans函数
- 3WPF将Xml数据源序列化到 ObservableCollection
类型集合上_.net xml observalcollection - 4VTK的Spline样条对比——vtkSCurveSpline、vtkKochanekSpline、vtkCardinalSpline和vtkParametricSpline
- 5pythonwebform菜单窗口动画在哪_Python GUI之tkinter窗口视窗教程大集合(看这篇就够了)...
- 6【前沿技术RPA】 一文学会用UiPath实现PDF自动化_uipath入门到精通pdf
- 7mysql 表空间收缩_MySQL 5.7新特性:在线收缩undo log表空间
- 8Docker的数据管理和端口映射实现容器访问_可以通过端口来直接访问docker,并进行管理了
- 9python开发数字人助理版_python搭建ai数字人开源
- 10.net使用正则表达式校验、匹配字符工具类
当前位置: article > 正文
使用本地 Llama 2 模型和向量数据库建立私有检索增强生成 (RAG) 系统 LangChain_rag+向量数据库
作者:小丑西瓜9 | 2024-02-23 00:49:52
赞
踩
rag+向量数据库
在人工智能领域,获取最新且准确的数据至关重要。检索增强生成(RAG)模型证明了这一点,它作为人工智能生态系统中的既定工具,利用大型语言模型与外部数据库的协同作用,提供更精确和最新的答案。借助 RAG,您不仅能获得黑匣子答案,还能获得黑匣子答案。您将收到基于直接从最新数据源提取的实时信息的见解。
然而,当 RAG 拥有可靠且高效的数据源时,它的力量才能真正发挥出来。这就是非结构化的闪光点。想象一下,有一个以各种格式和位置分布的数据宝库,利用它的任务感觉非常艰巨。Unstructured 就是为了弥补这一差距而专门设计的。它充当专为法学硕士设计的 ETL 管道,连接到您的数据(无论其格式或位置如何),将其转换和清理为简化且可用的格式。从本质上讲,非结构化正在为您的人工智能模型提供实时、可操作的数据。这是人工智能之旅的第一步,也是最关键的一步,将非结构化数据混乱转化为数据驱动的见解。
虽然许多组织倾向于基于云的 RAG 解决方案,但人们对本地实施的兴趣日益浓厚。这种转变是出于对数据隐私的担忧、减少延迟的愿望以及成本考虑。选择本地 RAG 系统意味着确保您的数据永远不会离开您的场所,这对于处理敏感或专有信息的实体来说至关重要。
在本文中,我们将探讨使用本地模型和矢量数据库构建私有 RAG 系统的细节。我们将分解该过程,并为那些对此类设置感兴趣的人提供分步指南。我们还将重点介绍为什么在您的设置中使用非结构化不仅是一种选择,而且是一种必要。
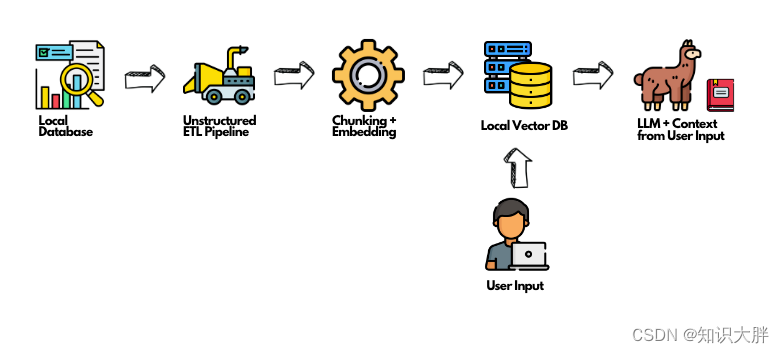
如何在本地 RAG 系统中使用非结构化:
Unstructur
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/132460
推荐阅读
相关标签

