
- 1nltk 报错_lookuperror: *************************************
- 2spring boot 利用element框架上传图片_el-upload spring 表单图片上传
- 3window下使用linux子系统及基于wsl2安装docker_wsl 安装docker
- 4链路追踪详解(三):分布式链路追踪标准的演进
- 5element组件点击复选框不选中问题_element ui表格多选框,多选时不符合条件,点击不勾选
- 6大数据到底怎么学:数据科学概论与大数据学习误区
- 7Google 文件系统
- 8SDRAM操作说明——打开DDR3的大门_sdram芯片使用教程
- 9全链路日志追踪traceId(http、dubbo、mq)_链路追踪traceid
- 10NLP-词向量(Word Embedding)-2014:Glove【基于“词共现矩阵”的非0元素上的训练得到词向量】【Glove官网提供预训练词向量】【无法解决一词多义】_创建同义词向量
盘点:文本内容安全领域 深度学习的六个主流应用方法_深度学习在安全领域的应用
赞
踩
本文来自:易盾实验室
在深度学习技术兴起之前相当长的一段时间内,基于机器学习技术的文本分类方法占据着文本分类领域的统治地位。
如下图所示,特征工程+机器学习分类器一直是解决文本分类问题的标准范式。针对不同的业务场景,算法工程师需要精心设计相应的特征工程,以取得最佳的分类效果。

到2010年,深度学习技术逐渐兴起,文本分类领域的技术格局也相应的发生了变化。基于深度学习的文本分类方法打破了上述技术范式,对文本进行简单预处理后,直接喂给深度学习模型,进行端到端的训练和推断。一般性的,用于文本分类的深度学习模型最后一层为softmax层(多标签问题则为sigmoid),这相当于机器学习分类器中的LR模型。由此可见,模型的其余部分本质上就是在自动学习文本的特征表示,因此算法工程师再也不用操心特征工程的事情了。不过先别高兴得太早,文本特征学得好不好,取决于具体的深度学习模型结构设计和超参数设置,工程师们还是得把省下来的时间花在模型结构和超参数的调整上面。
本文根据易盾文本算法团队在内容安全领域的实践经验,介绍在项目中用过的一些深度学习模型以及对部分技术细节进行讨论。深度学习是近几年来的热门方向,学术界和工业界的研究人员提出了很多有价值的方法,本文所分享的方法只是其中少数代表性的工作,仅供读者参考。
CNN
 上图是一个典型的单层CNN模型结构。首先将文本转化成词向量矩阵,然后分别使用不同size的的卷积核对矩阵进行卷积,每组卷积输出多个feature map,然后进行max pooling后,把所有feature map拼接在一起,形成单个向量表示,最后加上一层全连接和softmax操作,输出分类分数。
上图是一个典型的单层CNN模型结构。首先将文本转化成词向量矩阵,然后分别使用不同size的的卷积核对矩阵进行卷积,每组卷积输出多个feature map,然后进行max pooling后,把所有feature map拼接在一起,形成单个向量表示,最后加上一层全连接和softmax操作,输出分类分数。
图中只是一个示例,各类超参数都比较小,在实际使用过程中,词向量大小50以上,卷积核的size一般取2~7,每个卷积的feature map数量在几十到几百。另外max pooling也可以换成其它的pooling方法,比如average pooling,不过总体来说还是max pooling比较适合分类场景。正常情况下,通过超参数的调优,单层CNN模型已经能够适用大多数文本分类场景。但也有人使用多层CNN模型的,我们的经验是参数数量差不多的前提下,多层CNN未发现有明显的效果提升。
RNN
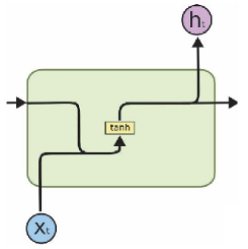
RNN模型主要用于处理序列数据,而文本天然的就是表示成若干词的序列,因此使用RNN模型来对文本进行建模是十分自然的事情。与全连接或卷积网络不同,RNN内部不同词对应的隐藏层相互之间是有联系的:当前词的隐藏层的输入除了输入层的输出,还包括前一个词的隐藏层的输出。

当序列长度较长时,基础的RNN模型存在梯度爆炸和梯度消失问题。LSTM和GRU是RNN的两种改良版本,它们通过门的机制对RNN中信息的传播进行控制,缓解了RNN的梯度消失问题(RNN梯度爆炸问题可以通过gradient clipping技术进行解决)。从图中可以看出,GRU与LSTM结构比较相似,主要不同之处在于GRU使用更新门来对LSTM的输入门和遗忘门进行简化。
由于RNN最后一个词的输出已经融合了前面词的信息,RNN用于文本分类时一般取最后一个词的输出作为整个文本的特征表示,即用最后的输出加上全连接和softmax计算分类分数。当然,一般我们会使用多层RNN的结构,用最后一个词的末层RNN的输出计算分类分数。
RNN的数据流动是单向的,只能从前往后或从后往前。Bi-RNN对此进行了改进,具体做法是使用前向RNN和后向RNN,把文本中最后一个词的前向RNN输出和第一个词的后向RNN输出拼接在一起,作为文本的特征表示。从我们的实践经验上看,Bi-RNN的这种改进效果提升很明显,我们知道attention对模型有较大的提升作用,但在某些业务场景里面attention对Bi-LSTM的提升比较有限,这说明Bi-LSTM自身的效果已经比较接近问题本身的理论上限。
RCNN
 RCNN也是早期深度学习技术应用于文本分类上面经常用到的模型之一。RCNN为每个词定义了left context和right context两个变量,具体计算方式如下:
RCNN也是早期深度学习技术应用于文本分类上面经常用到的模型之一。RCNN为每个词定义了left context和right context两个变量,具体计算方式如下:
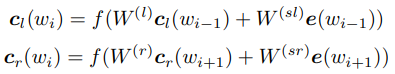
最终每个词由自身的词向量和两个context拼接共同表示,然后先接一层全连接层,再作max pooling形成单个的向量。这个模型为什么叫RCNN(Recurrent Convolutional Neural Networks)呢?首先,从left context和right context的定义可以看出这部分其实就是一个双向的RNN,只不过最后还拼接上原始的词向量。另外,这里并没有只取最后一个词的输出计算分类分数,而是对每个词的输出进行全连接再作max pooling。其实,这里的全连接等价于进行size为[1,emb_size]和strip为1的二维卷积操作,后面再跟着max pooling,这就是典型的CNN结构。
Attention
Attention机制被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。Attention机制可以理解成给定Q,从一系列K-V键值对中计算出各个V的权重,然后再对V进行加权平均。具体公式如下:

其中f函数对Q和K进行打分,可以有不同的实现方式,常见的有点积、缩放点积、加性、双线性等方法,我们也可以自己实现其它的计算方法。
我们注意到上述attention的计算涉及到Q、K、V三个输入,当Q=K时,这样的attention技术被称为self-attention。实际上,self-attention是目前用得最多的attention技术,它不需要额外的数据,只根据文本自身的上下文,就能计算文本中各个词的重要性。可以看出,attention本质上就是算各个词的权重,然后进行加权平均。而我们知道在word2vec问世以后,在怎么把多个词的词向量变成单个向量来表示句子的问题上,有一种做法就是加权平均,比如根据tf-idf加权平均。那么attention和这种加权平均的区别是什么?最本质的不同就是同一个词,普通的加权平均方法权重是固定不变的(最多乘以词频系数),attention方法的权重是根据上下文动态计算的,在不同的文本和不同的位置,它的权重都是不一样的。这就像人类的视觉注意力,看到不同的图像时重点关注的区域不一样,所以我们把这个技术叫做attention。同一个词在不同的上下文中得到不同的输出,这种特性使得attention方法天然的般配NLP中的一词多义问题。
具体到文本分类模型,attention的使用比较灵活,既可以单独使用attention进行分类,也可以和CNN、RNN等模型结合。目前常见的模型有transformer、HAN、RNN+attention、CNN+attention、Bi-RNN+attention等等,这里不再展开赘述。
FastText
FastText是Facebook在2016年开源的一个轻量级文本表示和文本分类工具。它的特点是在具有媲美当时复杂深度神经网络模型文本分类准确率的同时,训练和预测非常高效,CNN训练1天的数据,FastText只要几秒即可。

FastText之所以这么高效,主要有三个原因。第一,模型结构特别简单,对文本所有单词的embedding求平均然后加上softmax分类器。第二,这个softmax分类器是一个层次softmax分类器,这个在分类类别很多的时候比较有用。第三,FastText使用C++实现的,并且作者代码能力也非常强,因此虽然有很多复现版本,但都没有原版高效。
尽管模型结构简单,FastText使用了n-gram和subword两种技术,帮助提升了文本分类效果。n-gram有助于模型捕捉文本局部的单词顺序,而大部分文本分类任务并不需要太长的依赖关系。subword也叫char n-gram,就是把单词分解更小的子串片段,这能更好的对未登录词和稀有词进行建模,同时学习到相同词缀单词语义关系。
总的来说,FastText适用于对精确度要求不高同时需要较高实时性的文本分类场景,也可以作为新算法的一个baseline。
Bert
BERT是谷歌在2018年发布的一个预训练语言模型,它刷新了11个NLP任务的记录。BERT的发布使得NLP领域真正进入到了基于通用预训练模型进行下游任务的时代,同时也进入了大力出奇迹的时代——通过更多的数据、更大的模型获得更高的准确率,从此以后各家科技巨头推出的模型越来越大,训练用的数据也越来越多,简直就是在炫富。其实在BERT之前也有很多预训练语言模型的研究,像ELMo、GPT都是当时比较突出的成果,它们的很多思路和方法都被BERT借鉴了。
相比前辈们,BERT之所以引起这么大的关注,主要在于它的效果确实很惊艳,同时在多个NLP任务上面刷新记录,并且提升幅度都还挺大的。更重要的是,BERT用在这些任务上面并不需要精心设计下游网络,基本上都是接一个简单的预测结构,然后简单地fine-tuning一下就OK了。

BERT模型结构本身并不复杂,主要分为3个部分:最底层是embedding组件,包括词、位置和token types三种embedding的组合;中间层是由多个Transformer encoder组成的深度网络(base版本是12层,large版本是24层);上层是与训练任务相关的组件,主要就是softmax网络。BERT模型比较重要的创新有两方面,分别是Masked LM和Next Sentence Prediction(NSP)。Masked LM用[MASK]替换句子中的部分单词,模型的目标是预测[MASK]位置上的真实单词。
Masked LM技术的引入让BERT模型变成了自编码语言模型,它的优化目标不是最大化句子的似然函数,而是最大化mask部分的联合条件概率,因此BERT模型可以使用双向Transformer,使用前后上下文信息对当前词进行预测。
在BERT之前的语言模型都是没法做到真正双向的,这算是一个比较大的改进。NSP任务的引入让BERT模型能够更好的学习到句子层面上的整体语义。在NSP任务中,模型的输入是一个句子对(确切地讲是片段对,每个片段可能包含一个以上的句子),目标是预测输入的句子对是否是原文中连续的两个句子。训练数据50%来自语料中抽取的真实连续句子对,另外50%就是从语料中随机组合的。训练的时候模型的优化目标是最小化Masked LM和NSP的组合损失函数。
BERT模型用在文本分类过程也比较简单,模型输入就是单个文本,这里不需要对单词进行mask,也不用组成句子对,输出使用第一个词的输出作为文本的向量表示,然后接softmax网络。我们的实验结果表明BERT模型是本文介绍的所有方法中表现最好的,目前已经应用在线上部分复杂的业务场景中。
总结
本文只是介绍了易盾文本内容安全业务中用到的几种深度学习方法,实际上,网易易盾的内容安全服务包括文本检测、图片检测、视频检测、音频检测、人工审核和智能审核系统等产品,以及广告合规、网站内容检测、文档内容检测、历史数据清洗、音视频、社交娱乐、政企、媒体等解决方案。目前对外提供的内容安全服务已经升级为第三代人工智能技术,提供涉黄、涉政、暴恐、广告等十几大类上千小类的有害内容智能识别过滤服务,识别精准率超过99.8%。
上述所总结的,是目前业界解决文本分类问题的主流方法。如果使用固定的benchmark语料集进行评测,这些模型在准确率指标上面确实表现出一定的差异和优劣。但具体到文本内容安全的业务场景,我们很难得出哪个模型表现最好这样的结论。
在实际使用中,需要根据不同场景的文本特点,同时考虑样本规模、词汇量大小、处理时间、模型参数规模等各种因素,选择适当的模型。实际上,模型的作用是次要的,决定最终效果的关键因素是语料库的构建,有了规模足够大的高质量语料库,哪怕模型简陋一点,效果也是要好于复杂模型的。而语料库的构建是一项长期的工作,需要明确各种违规类别的标准并进行细分,清晰具体的标准是标注高质量语料库的前提。同时还要不断投入人力,收集和标注样本,让语料库的样本尽量覆盖到不同类型的数据。
此外,真实的文本内容安全系统也不是几个模型就能搞定的,它是一套成熟的解决方案,使用丰富的检测手段分别覆盖不同的场景,保证较高的检测率。
参考文献
-
https://www.aclweb.org/anthology/D14-1181
-
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
-
https://medium.com/@saurabh.rathor092/simple-rnn-vs-gru-vs-lstm-difference-lies-in-more-flexible-control-5f33e07b1e57
-
https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552
-
https://arxiv.org/pdf/1706.03762.pdf
-
https://arxiv.org/pdf/1810.04805.pdf

