
- 1Android通过Mapping.txt还原混淆过后的代码_apply mapping.txt 作用
- 2Python Flask 番外 01: 常见错误405 Method Not Allowed 及网络协议的相关知识_flask flask_jwt_extended 405 (method not allowed)
- 3防火墙的基本概念和分类_建筑防火墙主要有哪几种类型
- 4B站小甲鱼python学习笔记_b站extend函数
- 5【微服务】- SpringCloud整合OpenFeign及OpenFeign简单使用_spring feign 和 openfeign
- 6Mac/Windows Git配置SSH和Git常用命令(笔记)_mac 安装git 并配置ssh
- 72024最新版Java面试八股文大全(附各大厂面试真题及答案)_java八股
- 8wordcloud-中文_stfangso.ttf
- 9WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connec
- 10Codeup(云效)手把手教部署SpringCloud项目到私有主机_如何把项目部署到私网
7万张英伟达H100打造的Open AI王炸文生视频Sora功能原理详解|Sora注册全攻略_sora相对chatgpt对硬件要求的区别
赞
踩
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源

近日,OpenAI发布的基于Transformer架构的文生视频Sora,可谓是在AI圈掀起新的热潮。该模型具有强大的视频生成能力,可产生高达一分钟的高清视频,并且用户可以自由指定视频时间长度、分辨率和宽高比。据OpenAI的观点,Sora的诞生可能预示着物理世界通用模拟器的重大突破。
360集团创始人兼董事长周鸿祎在2024年亚布力中国企业家论坛第二十四届年会上分享了其对Sora模型的观察。“Sora的推出预示AI视频生成能力的突破,不仅推动了AI的发展,而且为企业的未来指明新的发展方向。通用人工智能的发展可能未来两三年内就能实现。”
他鼓励中国企业全面投身AI应用和研究,挖掘AI潜力,以寻找业务和工作流程中可能实现效益提升的机会。建议大型互联网公司应在通用大模型领域持续加大投入,而企业家则应构建企业级、产业级、场景化的垂直大模型;呼吁所有企业在AI的发展过程中积极参与,以适应和引领时代的变革。
周鸿祎对Sora模型的赞扬不仅限于其出色的视频生成能力,还深入到Sora模型的本质,强调其在模型理解世界的特别之处,解决了过去AI只能通过语言表达的局限,使得AI在认知层面有了"眼睛"。
他还以Sora模型为例,总结了人工智能的五个发展阶段:传统AI,人机交互,机器对世界的理解(基本实现通用AI),强人工智能,以及如果AI能总结出像爱因斯坦相对论那样的公式,就进入超级人工智能阶段。对于AI发展越来越快速的未来充满了期待和信心。
本文将深入探讨Sora文生视频技术的原理,做一个全面的视频大模型回顾及Sora与其他 AI 文本视频模型性能对比,对SORA模型的算力空间进行测算分析。让我们一起深入研究这个令人振奋的主题。
文末附:Sora账号一站式申请注册全攻略
关键词:Transformer;Sora;强人工智能;周鸿祎;AI服务器;A100;H100;A800;A100;算力空间;文本视频大模型Sora;Sora大模型;Sora AI
OpenAI 发布文生视频大模型 Sora
Sora文生视频技术原理
Sora是一款基于文本生成视频的新产品,被认为是首个达到基础模型等级品质的影片生成模型。其高品质的生成能力使其在影视娱乐、创作和广告等领域有着巨大的应用潜力。该模型的重要性在于它能够根据简单的文字描述生成各种类型的影片,包括电影预告片、写实影片和虚拟影片,其品质令人惊叹。Sora的发布标志着影片生成领域的一次革命,提供高度可控的模拟器,用于学习影片生成的各个方面,包括3D和4D的生成,以及物理性质和材质的模拟。技术上,Sora采用diffusion transformer模型,结合传统的Summator和DALL-E模型,并使用recaptioning技术和大量的合成数据进行训练。未来,Sora可能会面临一些挑战,比如开源和产品端结合等,但它在影片生成领域的潜力是巨大的,对AR/VR/MR等领域也有着广阔的应用前景。
通过Sora,我们可以想象到一个新的世界,一个充满无限可能性的世界。Sora的联想力越丰富,就能够产生更多、更丰富的时空碎块,这将为影片生成领域带来更多的创新和可能性。Diffusion作为一个画师,根据关键词特征值对应的可能性概率,在视频库中寻找合适的素材,从而为Sora提供更多的灵感和创意。通过Diffusion和Transformer的共同联想,Sora可以从巨大的视频库中生拉硬拽,将一张张碎块拼接成一部完整的影片,每秒播放几十张,呈现出令人惊叹的效果。
Sora的超高生成能力与广告界和娱乐领域的无穷可能性联系紧密,不容忽视的是Sora创新融合艺术与技术,致力于完美的光线追踪渲染效果,使创意成为艺术家的画布。挥洒自如的同时,更要强调Sora的巨大突破,那就是其"超大的时长"能力,能够连续生成高达一分钟的高清视频。在保持视角和风格一致性的同时,呈现的影片如同杰出艺术家在画布上精心调色,呼之欲出。
一、功能解读
OpenAI发布的Sora视频大模型主要具有生成视频、编辑视频以及从文本生成图像三项核心功能。其中,从文本生成视频和视频编辑是其最主要的AI功能。这些功能通过确保“物理世界常识”始终存在,以实现通用模拟工具的作用。换言之,Sora利用其核心AI功能,为用户提供一个能够持续应用物理世界常识的通用模拟工具。
1、文生视频
Sora基于DALL·E图像生成和视频生成技术,可根据用户提示词在一分钟以内生成各种分辨率和宽高比的视频。其3D一致性确保每个连续镜头中,物体间的空间关系维持一致,符合物理逻辑。远距离的相干性和物体的持久性也在其中,即便在视角变化或物体被遮挡的情况下,被遮挡的物体仍能保持其存在。Sora精细呈现物体与世界的互动性,无论是画布上的笔迹还是食物上的咬痕都不会被忽视,以此确保与真实世界的交互始终真实有效。不仅如此,Sora还能模拟数字世界,例如像Minecraft这类的虚拟环境,展现出对实际世界和虚拟世界的双重模拟能力,这让Sora有望成为通用的世界模拟工具。
2、视频编辑
Sora拥有时空视频扩展能力,能够精准分析视频中的时间线和空间关系。其具有强大的场景和风格改变能力,一键设置和风格化渲染使视频制作更为简便。Sora甚至可以无缝连接不同主题的场景视频,展现出创新的镜头语言和IP重组。值得一提的是,Sora能通过插值技术,实现两个截然不同主题和场景的视频之间的平滑过渡,这为视频创作提供无限可能。
3、掌控三维空间与视频连贯性的物理引擎
Sora模型的一大亮点是其对三维空间中物体的运动和交互的连贯性和逻辑性的掌控。该模型通过直接处理大量训练视频,无需预处理或调整,从而成功地学习物理世界建模。该技能使得Sora能生成在数字世界中的视频,其中物体和角色在三维空间中的移动和互动都非常连贯,即使物体被遮挡或离开画面,也能保持一致性。
从Sora到Lumiere等先进的视频模型,其关键性的转变在于不再过度依赖空间关联,而是加强对时间关联的理解。这些模型通过海量的视频数据学习和表征状态空间的动态性并处理非马尔可夫性。
然而,仅通过时间和空间的碎片往往无法理解底层规则,我们需要更深入的挖掘。科学家们可以将他们在物理、化学、生物等领域的长期研究以图像或视频的形式输入到这些视频生成的大模型中,进一步助力发掘潜在规律。
Sora的独特之处在于将视频生成模型泛化为物理引擎。如果我们能够将它和LLM GPT整合并实时运用,则可以接近或甚至达到人类感知的水平。然而,感知到概念的转换需要处理好生成过程中的采样和变分推断。
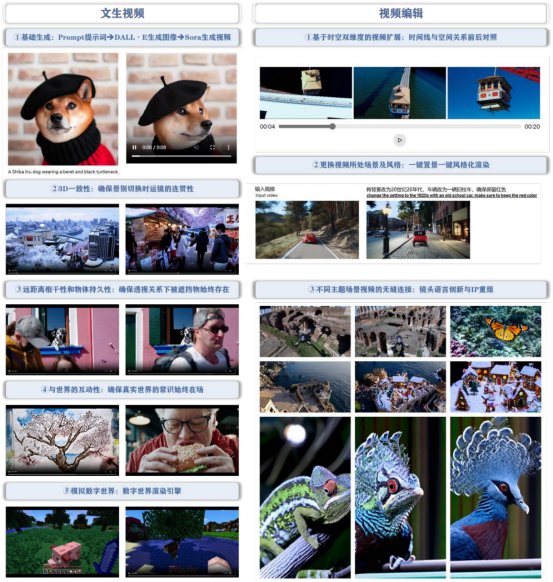
Sora 功能一览:文生视频+视频编辑,确保“物理世界常识”始终在场
二、Spacetime Latent Patches 潜变量时空碎片, 建构视觉语言系统
对视觉数据建模,Sora采用类似的Token Embedding策略,即通过高效且易于扩展的视觉数据表示模型碎片(Patch),为各种类型的视频和图像提供精准的表征。在这个过程中,视频被压缩并映射到一个低维的潜在变量空间,然后拆解成时空碎片。
在此基础上,Sora展示了其多样的能力:
1、理解自然语言
通过将DALLE3生成的视频文本描述和GPT生成的丰富文本prompts结合,Sora在训练过程中确立与GPT之间更精准的语言关系,使Token和Patch之间的“文字”达成统一。
2、将图像和视频作为prompts
用户提供图像或视频可以被自然地编码成时空碎片,以此进行各种图像和视频编辑任务,如生成动态图像、视频生成扩展、视频连接或编辑等。
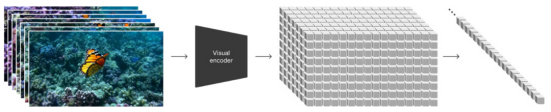
三、基于 Patches 视觉特征标记的 Diffusion Transformer 模型
OpenAI将Sora定义为Diffusion Transformer,该概念源自伯克利的研究成果Diffusion Transformer (DiT),并以此作为Sora设计架构的重要基础。这项工作名为"采用Transformer的可扩展扩散模型Scalable diffusion models with transformers",在AI研究领域有着广泛影响。
扩散模型的核心工作原理包括在训练数据中添加高斯噪声,然后学习反向去噪过程及恢复数据。当训练完成后,模型通过已学习的去噪过程将随机抽取的噪声转化为数据。在模型工作过程中,通过逐渐添加噪声,使图像向纯高斯噪声转化。训练扩散模型的目标是学习逆向过程,进而生成新数据。从信息熵角度看,原始的结构化信息熵较低,通过多次添加高斯噪声,信息熵会提高,逐渐掩盖原始结构信息。而在非结构化部分,即使只添加少量噪声也会使得信息变得混乱。学习目标就是找到这些原始结构化信息,可以理解为对“底片”的提取。
基本的扩散模型在处理过程中,不进行降维或压缩,保持较高的还原度,其学习过程主要参数化概率分布并用KL散度来衡量概率分布之间的距离。而Diffusion Transformer(DiT)模型则引入Transformer,对信息进行降维和压缩,并采用多层多头注意力和归一化技术,这使得它在扩散方式下提取“底片”信息的原理与LLM的重整化保持一致。
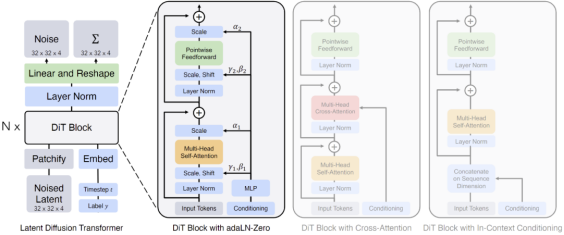
Sora是一个基于Patches视觉特征标记的Diffusion Transformer模型,其灵感源自于有着统一的代码、数学等自然语言文本模式的Tokens文本特征标记。其核心包括以下四个步骤:
1、视觉数据转化
将视觉数据,如视频和图像,压缩到低维潜在空间,并将其分解为带有时空特征的Patches。
2、视频压缩网络构建
训练一个视频压缩网络,将原始视频压缩成潜在特征,并在此压缩空间中进行训练生成视频。同时,训练一个解码器模型,将生成的潜在特征映射回像素空间。
3、提取视觉数据的时空潜在特征
从已压缩的输入视频中提取时空特征Patches。因为图像可以被看作是单帧视频,所以这个方案也适用于图像。基于Patches的表达使Sora对不同分辨率、视频时间和宽高比的视频和图像进行训练,且在推理阶段,可通过以正确大小的网格来排列随机初始化的Patches控制生成视频的大小。
4、推广Transformer模型到视频生成领域
Sora是一个Diffusion Transformer模型,接受输入嘈杂Patches,通过训练预测原始干净Patches,生成高清视频。随着训练计算量的增加,样本质量也有显著提高。
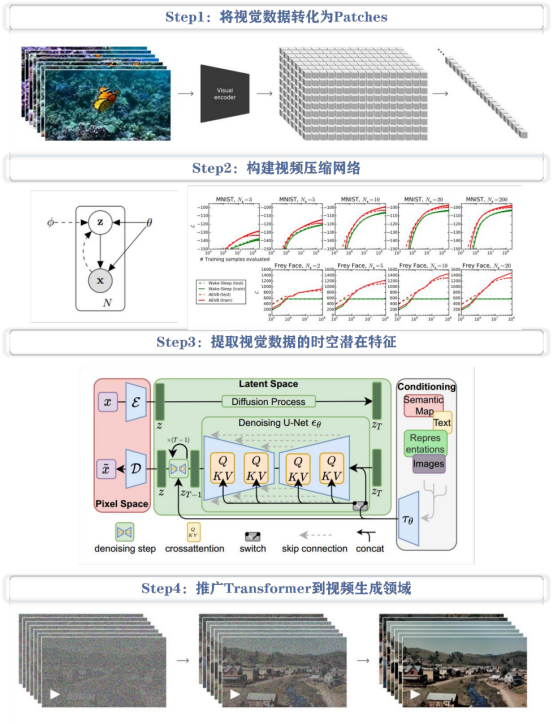
Sora 技术路径:基于 Patches 视觉特征标记的 Diffusion Transformer 模型
四、Patches 实现更灵活采样+更优化构图
Patches的使用提供更灵活采样和更优化视频构图两大优势。
1、训练角度
利用Patches进行原生视频采样扩大样本规模并避免标准化样本的步骤。在过去,处理不同分辨率和宽高比的视频通常需要进行剪辑或调整至标准格式。
2、推理角度
根据原生视频训练模型在生成新视频时,其构图和取景更为优化。举例来说,采样标准化样本生成视频在叙事主体部分被硬性分割开,而原生样本生成视频则保证叙事主体完整地出现在中间位置。

Why Patches?——更灵活的采样+更优化的构图
Sora通过结合DALL·E 3 DCS的描述性标题重述和GPT标题扩写方法,提高语言理解能力。为了训练文本到视频的生成系统,OpenAI使用DALL·E 3生成描述性的文本字幕,应用于训练集中的所有视频。同时,OpenAI还使用GPT将用户的短小提示转化为更长、更详细字幕,以提高视频输出质量。简言之,Sora通过利用DALL·E 3和GPT特性,实现对语言的深度理解和高质量的视频输出。

基于 DALL·E 3 DCS 的描述性标题重述与基于 GPT 的标题扩写
五、Sora 有局限性,但未来可期
尽管 Sora 在模拟能力方面已经取得了显著的进展,但它目前仍然存在许多局限性。例如,它不能准确 地模拟许多基本相互作用的物理过程,如玻璃破碎等。此外,在某些交互场景中,比如吃东西时,Sora 并不能总是产生正确的对象状态变化,包括在长时间样本中发展的不一致性或某些对象不受控的出现等。
我们相信随着技术的不断进步和创新,Sora 所展现出的能力预示着视频模型持续扩展的巨大潜力。未来, 期待看到更加先进的视频生成技术,能够更准确地模拟现实世界中的各种现象和行为,并为人们带来更加逼真、自然的视觉体验。

现有视频大模型对比
一、Runway-Gen2:综合实力最强的文生视频应用,内部训练数据集含2.4亿张图像和640万个视频剪辑
Gen2底层建立在扩散模型之上,能够支持包括文本到视频、图片到视频和图片+文字到视频在内的多种视频生成方式。默认情况下,Gen2可以生成4秒的视频,但用户可以通过输入已生成的图片来延长视频的播放时长。此外,Gen2提供一系列参数调整功能,如基础设置、摄像机运动以及运动画刷,让用户可以实现更多的个性化配置。其中最亮眼的功能,便是Gen2能精细控制生成内容的运动状态,甚至一键设置不同视频风格,为视频创作提供了极大的便利性。
尽管Gen2具有诸多显著的优点,但目前还存在一些不足之处。首先,Gen2的视频帧率相对较低,导致其呈现效果更像是连续的PPT播放。其次,当视频内容处在移动状态时,图片容易出现掉帧、模糊,甚至扭曲的现象。最后,从理解语义信息的角度来看,Gen2还有较大的提升空间,特别是在处理包含多元素提示词时,其能力相对较弱。尽管如此,对于Gen2来说,这些问题只是暂时的挑战,让我们一起期待它未来的表现。

Gen2一键生成不同风格图像
二、Stable Video Diffusion(SVD):开源文生视频平台,Stability.AI基于Stable Diffusion的演进
SVD模型不仅支持文本、图像生成视频,还支持多视角渲染和帧插入提升视频帧率。用户可以调整模型选择、视频尺寸、帧率及镜头移动距离等参数。其由Stability.AI基于大规模数据集进行多层训练,具备开源属性和优秀的图像生成能力,是Stability.AI产品家族中的一员,形成完整的多模态解决方案。
SVD的天花板主要由于硬件性能要求较高,限制平常用户使用。其支持的图片尺寸较小,限制了它的应用场景。此外,相机视角无法调节,且生成视频内容的精细控制能力有待提升。生成的视频清晰度和帧率也存在一些问题,表现在物体移动过程中有明显掉帧和形变。
尽管SVD与其他商用产品在帧率、分辨率、内容控制、风格选择和视频生成时长等方面存在差距,但其开源属性和对大规模数据的有效利用构成其独特优势。
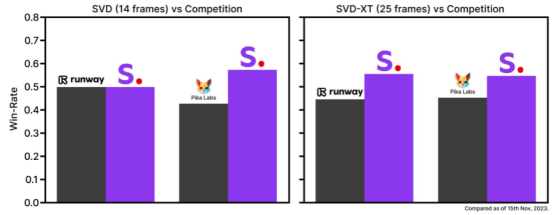
SVD与Runway2&Pika的比较
三、Pika:视频版Mid-journey
Pika支持从文本、图像和视频生成视频,时长默认为3秒,分辨率为24帧。提供用于调整摄像机运动、视频尺寸、帧数的参数,并提供会员特权如增长视频时长、提升分辨率和局部修改视频等。Pika独特之处在于其能产生背景稳定的视频,并能在视频中添加元素,如为人物添加眼镜等。
然而该模型在场景泛化和理解语义信息方面表现一般,例如无法正确区分“熊猫”和“猫”。此外,视频运镜过程中可能出现掉帧现象,人物的审美展示以及肢体细节展现尚有不足。
与Runway Gen2和SVD相比,该模型在卡通风格等特定场景下的表现突出,不过需要精准的提示词输入,而且对泛化场景的处理能力较弱。
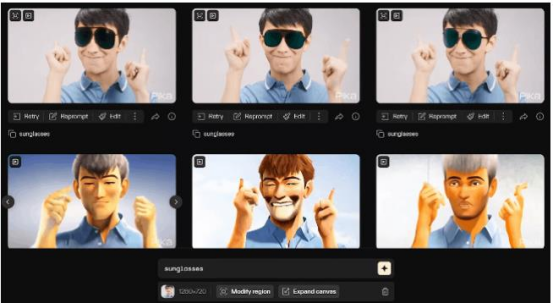
通过Pika给视频中的人像添加墨镜
四、Sora 与其他 AI 文本视频模型性能对比
![]()
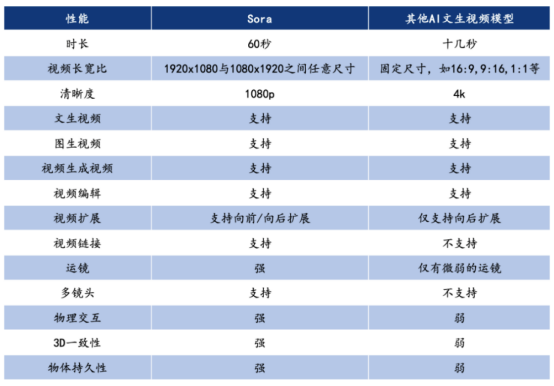
Sora 与其他 Al 文生视频模型性能对比
1、超长生成时间
Sora 支持 60s 视频生成,而且一镜到底,不仅主人物稳定,背景中的人物表现也十分稳定,可以从大中景无缝切换到脸部特写。在此之前,AI 视频工具都还在突破几秒内的连贯性,即使是 Runway 和 Pika 这样的“明星模型”,生成的视频长度也仅有 3 到 4 秒,Sora 的时常可以说已经达到了史诗级的记录。
2、单视频多角度镜头
Sora 可以在单个生成的视频中创建多个镜头,模拟复杂的摄像机运镜,同时准确地保持角色和视觉风格。在 OpenAI 的展示视频中一只狼对着月亮嚎叫,感到孤独,直到它找到狼群,多镜头无缝切换都保持了主体的一致。
3、理解物理世界
重要的是,Sora 不仅理解用户在提示中要求的内容,还能自己理解这些事物在现实世界中的存在方式。比如画家在画布上留下笔触,或者人物在吃食物时留下痕迹。火车穿过东京郊区,随着车窗内外光线环境和物体的变化,车窗上倒影的变化也几乎被按照现实世界的物理规律完美还原了出来。而在技术方面,Sora 打破了此前扩散模型局限性。Sora 采用的是 DALL·E3 的重标注技术,通过为视 觉训练数据生成详细描述的标题,使模型更加准确地遵循用户的文本指令生成视频,还能够为现有图片赋予动态效果或延伸视频内容的长度。
Sora模型算力空间测算
Sora模型性能强大,与其训练数据的高质量和多样性密切相关。通过大量吸取不同长度、分辨率和长宽比的视频和图像,Sora模型深度理解复杂的动态过程,并且有能力生成多种类型的高质量内容。仿照大语言模型的训练方式,Sora模型将取样多样性应用于视觉数据,从而实现全面的视频生成能力。
此外,Sora模型通过利用时空片段技术将多个视频片段打包进一个序列中,极大地提升视频生成的效率。该方法让模型更高效地学习大型数据集,从而提高生成高质量视频的能力,同时在计算资源使用上,相比其他模型架构,节省相当多的资源。
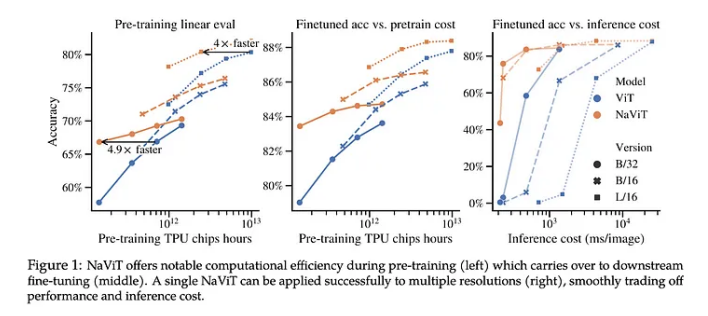
使用可变 patches 的 NaVit vs. 传统的 Vision Transformers
一、SORA模型训练与传统大模型的训练相比,为什么需要更多的算力?
SORA架构需要处理训练数据种类比较多,包括文本、图像以及视频,各种类型数据都需要单独的处理方式,分别进行处理之后再进行整合。图像和视频数据量大、复杂度高,特别消耗计算资源。例如,在处理图像数据时,每张图片需要被分解成许多面元(patch),而这个过程需要大量的计算资源。
二、ChatGPT-3和SORA模型的训练参数和数据量有什么区别?
对比GPT-3与SORA模型,两者在训练参数和数据量方面有许多不同。
1、训练参数
GPT-3和SORA的参数数量具有显著差距。GPT-3已经非常大,拥有1750亿个参数,而SORA模型对参数的需求更高。
2、训练数据
两者存在较大差异。GPT-3主要使用各种网络文本作为训练数据,包括网页、图书、文章等等。而SORA模型则需要处理多种类型的训练数据,包括文本、图像以及视频等。这意味着SORA在数据预处理以及训练过程中都需要做更多的工作。
总的来说,SORA模型在训练参数和数据量等方面都要比GPT-3更为复杂和庞大,需要更多计算资源。
三、SORA模型算力空间测算
Sora模型的出色性能与其训练数据的多样性与质量紧密相关。它吸纳大量不同长度、分辨率及长宽比的影像与图像,从而提升对复杂动态过程的理解,并具备生成多种类型高质量内容能力。模仿大型语言模型训练方式,Sora模型将取样多样性应用于视觉数据,完成全面的视频生成能力。
在效率方面,通过打包多个视频片段进一个序列中,Sora模型利用时空片段技术显著提升视频生成效率,既能高效学习大型数据集,又提高生成高质量视频的能力,节约了相较其他模型更多的计算资源。
谢赛宁在《Scalable Diffusion Models with Transformers》一文中测算结果表明,Sora模型参数量约为30亿,训练过去五年的YouTube所有视频需要约7.09万张H100运算一个月时间。当考虑到算力消耗,视频生成目前可能表现为试用状态。然而,未来技术优化或降低算力需求,有利于视频模型在推理应用中的广泛实施。
一文《An Image is Worth 16x16 Words Transformers for Image Recognition at Scale》中,一张图片大约等同于256个词,1分钟视频的生成大约需要超过一次文字问答的1000倍的算力。在预计训练期为10天的情况下,可能需要约368张英伟达H100显卡才能满足训练需求,展示训练顶级AI模型需求巨大的计算资源。
Sora模型将输入图像表示为16x16x3(3表示三原色)的数据块,而每个数据块实际上就是一串tokens。假设每张图片的分辨率为1920x1080,每个视频为30秒30FPS,那么patch的总大小约为3.73x10^16,可转化为约有4.86x10^13个tokens的数量。
Transformer模型架构参数量可能增加,假设SORA Transformer与ChatGPT-3相同,则可能需要约59500张英伟达H100显卡才能满足训练需求。这意味着,相较于目前的大语言模型,SORA的训练可能需要近百倍的算力。

模型训练算力需求测算
四、蓝海大脑AI服务器:驱动Sora模型训练的强大动力
探讨Sora等大规模深度学习模型训练,不可避免的话题便是AI服务器。尤其是在面临如此庞大和复杂的训练任务时,AI服务器重要性就尤为凸显。
蓝海大脑AI服务器是专为训练大规模深度学习模型而设计的专用服务器。平台采用A100、H100、A800、H800、B200等GPU显卡,为用户提供高度并行化和分布式计算能力,以应对大型神经网络的复杂训练任务。采用先进的硬件加速器,如GPU(图形处理单元)和TPU(张量处理单元),快速处理大规模数据集和复杂模型的训练过程。高效的任务调度和资源管理功能使用户能够轻松提交、监控和管理训练作业。创新的液冷散热技术,不仅满足静音、高效、节能基础需求,更在确保机器稳定运行的同时,提升服务器算力,实现了高算力和高效散热之间的完美结合。广泛应用于人工智能、自然语言处理、计算机视觉等领域。

Sora一站式申请注册流程
要想使用Sora,首先要确保您已经注册OpenAI账户并升级到ChatGPT Plus,Sora目前仍处于早期访问或测试阶段,还没有进入公测阶段,请耐心关注和等待。但是,据官方透露的消息,OpenAI近期大概率会宣布将Sora首批开放给Chatgpt Plus用户申请使用。所以,请务必提前准备好Chatgpt Plus。
一、打开openAI的官网:https://openai.com
二、点击官网search按钮:
三、输入apply,点击搜索
四、点击Pages,选择Red Teaming
五、填写表单
1. 建议用英文填写资料。
2. 带*是必填,如果自己不会写,可以参考案例,注意输入框有字数限制,别超过,否则会显示不全,影响申请。
3. 参考下图表单填写:
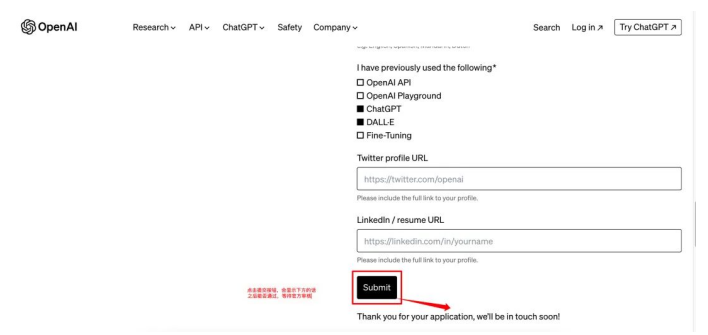
4. 整个页面全是英文,如果看不懂,用浏览器自带的翻译软件即可,但回答不能是中文。
5. 回答问题不知道选择哪个答案,或者写什么,用谷歌翻译、百度翻译,甚至可以直接问chatGPT得到答案。
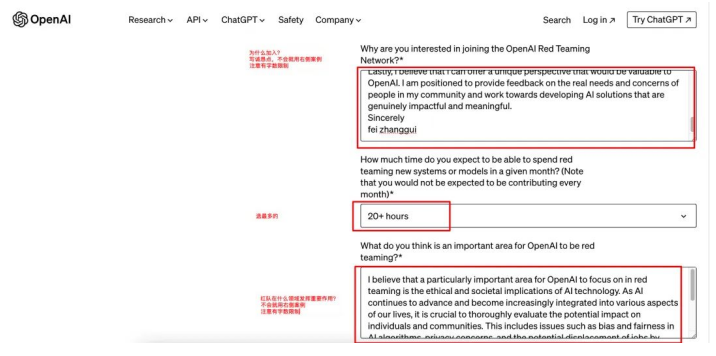
6. 回答“Why are you interested in joining the OpenAl Red TeamingNetwork?”参考示例:
Dear OpenAI Team,
I am reaching out with great enthusiasm for the opportunity to join OpenAI's Red Team. The idea of contributing to a group dedicated to rigorously testing and challenging AI models across various domains sparks immense excitement within me. My passion for joining OpenAI is driven by multiple facets, and I am confident in the value I can add to the team.
My conviction in the transformative power of AI fuels my desire to be part of this journey. I am deeply invested in exploring how AI can tackle challenges of inequality, aiming to foster a more just and equitable society. This ambition resonates with my core values and propels me to leverage my skills in this revolutionary field.
My interest in AI technology is not just a passing curiosity but a devoted pursuit. I've invested considerable time in understanding its fundamentals, which boosts my confidence in critiquing and evaluating AI models with clarity and depth.
Moreover, I am eager to bring a fresh perspective to OpenAI. My insights into the needs and concerns of my community equip me to contribute to the development of AI solutions that are not only innovative but also profoundly impactful.
Thank you for considering my application. I am eager to contribute to OpenAI's mission and be part of a team that stands at the forefront of AI research and application.
Best regards,
xxx xxx
7. 回答“What do you think is an important area for OpenAl to be redteaming?”的参考示例:
I am convinced that a critical focus for OpenAI's red teaming efforts should be the exploration of the ethical and societal dimensions of AI technology. As AI becomes more pervasive and integral to different facets of daily life, it's imperative to conduct deep analyses of its impacts on individuals and entire communities. This scrutiny should cover the examination of biases and fairness within AI algorithms, address privacy issues, and consider the implications of job automation. Through meticulous red teaming in these domains, OpenAI has the opportunity to guide the development and implementation of AI technologies in a manner that is both ethical and responsible. Achieving this would not only cultivate trust and acceptance among the wider population but also ensure OpenAI's pioneering role in an era increasingly influenced by AI. Such proactive measures are crucial for navigating the evolving landscape where AI's influence on society is profound and far-reaching.
六、点击submit按钮
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源

