
热门标签
热门文章
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
当前位置: article > 正文
深度学习笔记——pytorch实现双向GRU(BiGRU)
作者:小丑西瓜9 | 2024-04-29 13:28:51
赞
踩
双向gru
系列文章目录
机器学习笔记——梯度下降、反向传播
机器学习笔记——用pytorch实现线性回归
机器学习笔记——pytorch实现逻辑斯蒂回归Logistic regression
机器学习笔记——多层线性(回归)模型 Multilevel (Linear Regression) Model
深度学习笔记——pytorch构造数据集 Dataset and Dataloader
深度学习笔记——pytorch解决多分类问题 Multi-Class Classification
深度学习笔记——pytorch实现卷积神经网络CNN
深度学习笔记——卷积神经网络CNN进阶
深度学习笔记——循环神经网络 RNN
深度学习笔记——pytorch实现双向GRU
前言
参考视频——B站刘二大人《pytorch深度学习实践》
一、压缩填充张量 Pack_padded_sequence
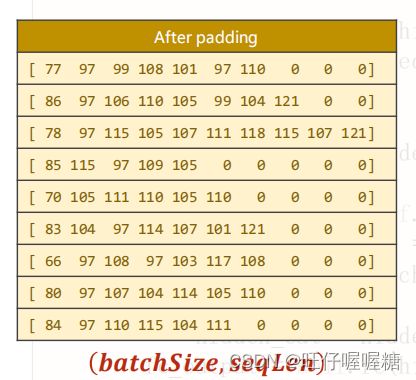
在交给模型处理数据之前,我们需要将数据做成矩阵。
由于每条序列的长短不一,我们将一个batch_size的序列做成矩阵时,需要选取最长的序列作为矩阵的宽,在其他序列填充0,形成矩阵。
但我们在计算时这些0就是无用的数据,浪费计算资源
因此提出了压缩填充张量 Pack_padded_sequence
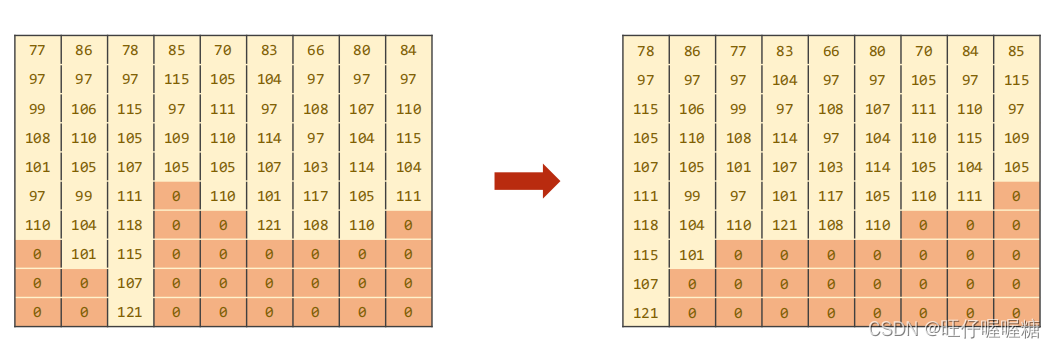
将矩阵转置后,并按序列长度排序
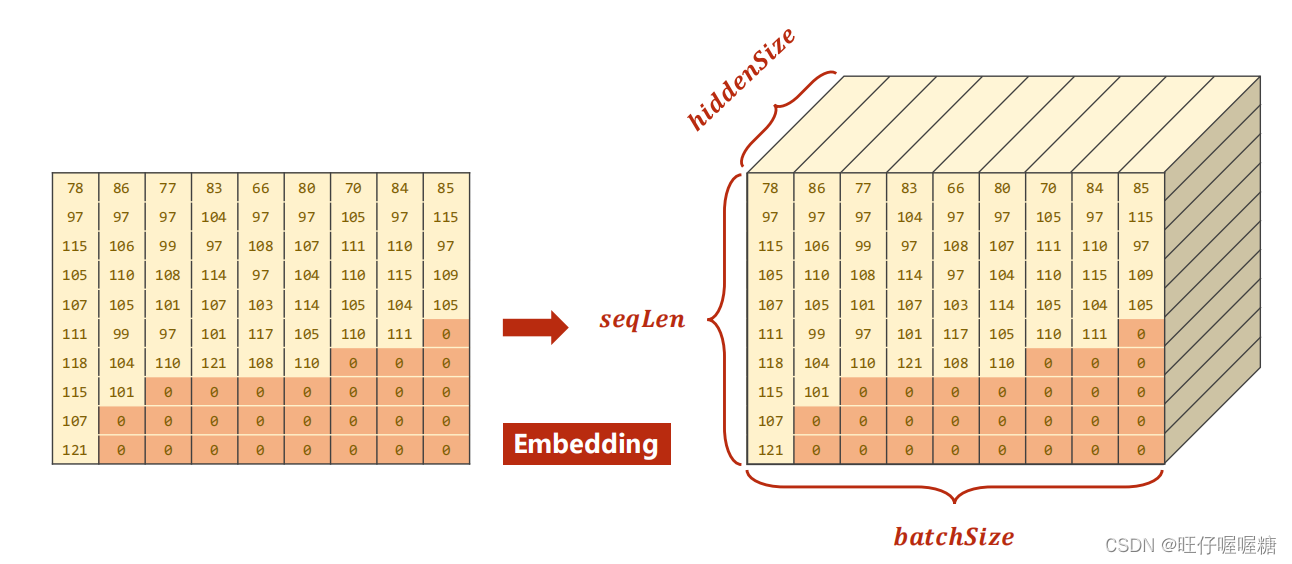
经过embedding层处理
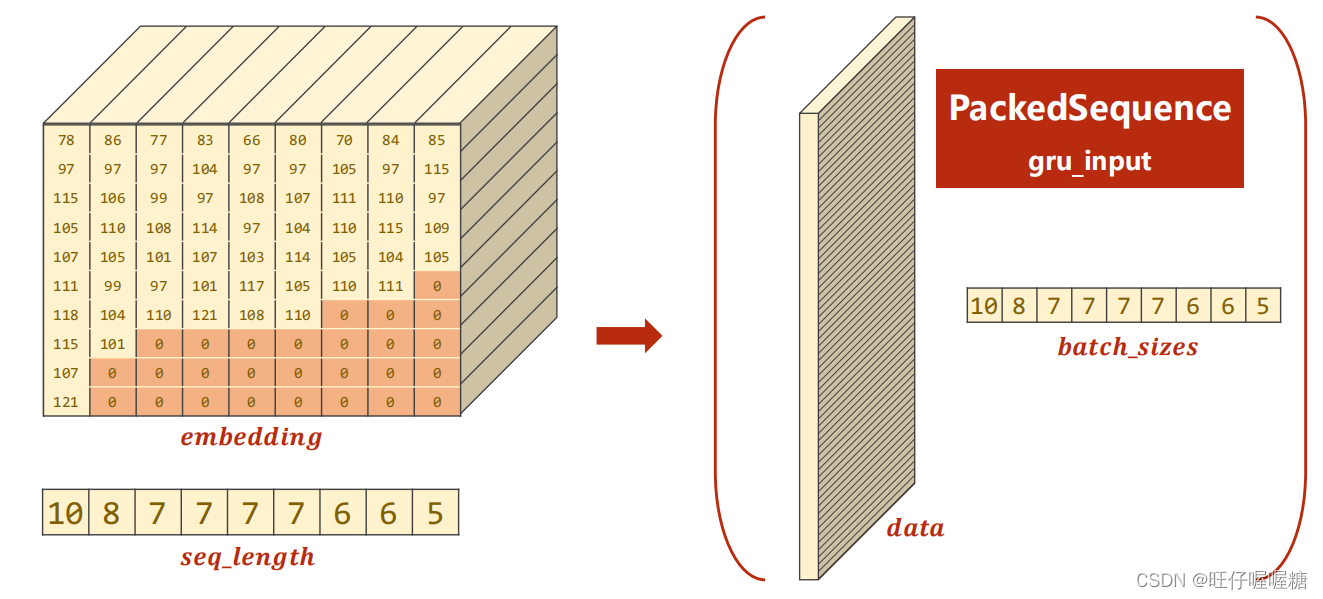
记录有效数据,在计算时只计算有效数据
二、代码
代码如下(示例):
#!/user/bin/env python3 # -*- coding: utf-8 -*- import torch from torch.utils.data import Dataset from torch.utils.data import DataLoader import pandas as pd import time import matplotlib.pyplot as plt import math BATCH_SIZE = 256 # batch size HIDDEN_SIZE = 100 # 隐层维度 N_LAYER = 2 # RNN层数 N_EPOCHS = 100 # 训练轮数 N_CHARS = 128 # 字符 USE_GPU = True # 是否使用gpu # prepare data class NameDataset(Dataset): def __init__(self, is_train_set=True): filename = 'data/names_train.csv' if is_train_set else 'data/names_test.csv' data = pd.read_csv(filename, delimiter=',', names=['names', 'country']) self.names = data['names'] self.len = len(self.names) self.countries = data['country'] self.countries_list = list(sorted(set(self.countries))) self.countries_dict = self.getCountryDict() self.countries_num = len(self.countries_list) def __getitem__(self, item): return self.names[item], self.countries_dict[self.countries[item]] def __len__(self): return self.len def getCountryDict(self): country_dict = {} for idx, country in enumerate(self.countries_list, 0): country_dict[country] = idx return country_dict def id2country(self, idx): return self.countries[idx] def getCountryNum(self): return self.countries_num # 训练集 train_data = NameDataset(is_train_set=True) trainloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) # 测试集 test_data = NameDataset(is_train_set=False) testloader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False) N_COUNTRY = train_data.getCountryNum() # 国家的数量 # 模型 class RNNClassifier(torch.nn.Module): def __init__(self, input_size, hidden_size, output_size, n_layer=1, bidirectional=True): super(RNNClassifier, self).__init__() self.hidden_size = hidden_size self.n_layer = n_layer self.n_directions = 2 if bidirectional else 1 self.emb = torch.nn.Embedding(input_size, hidden_size) self.gru = torch.nn.GRU(hidden_size, hidden_size, num_layers=n_layer, bidirectional=bidirectional) self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def forward(self, inputs, seq_lengths): inputs = create_tensor(inputs.t()) batch_size = inputs.size(1) hidden = self._init_hidden(batch_size) embedding = self.emb(inputs) gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths) # 用于提速 output, hidden = self.gru(gru_input, hidden) if self.n_directions == 2: # 如果是双向神经网络,则有两个hidden,需要将它们拼接起来 hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1) else: hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_output def _init_hidden(self, batch_size): hidden = torch.zeros(self.n_layer * self.n_directions, batch_size, self.hidden_size) return create_tensor(hidden) def create_tensor(tensor): if USE_GPU: device = torch.device('cuda') tensor = tensor.to(device) return tensor def make_tensors(names, countries): sequences_and_lengths = [name2list(name) for name in names] # 得到name所有字符的ASCII码值和name的长度 name_sequences = [sl[0] for sl in sequences_and_lengths] # 获取name中所有字符的ASCII码值 seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # 获取所有name的长度 # 获得所有name的tensor,形状 batch_size*max(seq_len) 即name的个数*最长的name的长度 seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() # 形状[name的个数*最长的name的长度] for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0): seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # 将所有name逐行填充到seq_tensor中 # sort by length to use pack_padded_sequence seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # 将seq_lengths按降序排列,perm_idx是排序后的序号 seq_tensor = seq_tensor[perm_idx] # seq_tensor中的顺序也随之改变 countries = countries[perm_idx] # countries中的顺序也随之改变 # 返回所有names转为ASCII码的tensor,所有names的长度的tensor,所有country的tensor return create_tensor(seq_tensor), \ create_tensor(seq_lengths), \ create_tensor(countries) def name2list(name): arr = [ord(c) for c in name] # 将string转为list且所有字符转为ASCII码值 return arr, len(arr) # 返回的是tuple([arr],len(arr)) def modelTrain(): total_loss = 0.0 for i, (names, countries) in enumerate(trainloader, 1): inputs, seq_lengths, targets = make_tensors(names, countries) output = Net(inputs, seq_lengths.to('cpu')) loss = criterion(output, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() if i % 10 == 0: # 每十个批次输出一次 print(f'[{time_since(start_time)}] Epoch {epoch}', end='') print(f'[{i * len(inputs)}/{len(train_data)}]', end='') print(f'loss={total_loss / i * len(inputs)}') return total_loss # 返回一轮训练的所有loss之和 def modelTest(): correct = 0 total = len(test_data) print('evaluating trained model...') with torch.no_grad(): for i, (names, countries) in enumerate(testloader, 1): inputs, seq_lengths, targets = make_tensors(names, countries) output = Net(inputs, seq_lengths.to('cpu')) pred = output.max(dim=1, keepdim=True)[1] correct += pred.eq(targets.view_as(pred)).sum().item() percent = '%.2f' % (100 * correct / total) print(f'Test set:Accuracy{correct}/{total} {percent}%') return correct / total def time_since(since): s = time.time() - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) if __name__ == '__main__': Net = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER, bidirectional=True) if USE_GPU: device = torch.device('cuda:0') Net.to(device) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(Net.parameters(), lr=0.001) start_time = time.time() print('Training for %d epochs...' % N_EPOCHS) acc_list = [] epoch_list=[] for epoch in range(1, N_EPOCHS + 1): modelTrain() acc = modelTest() acc_list.append(acc) epoch_list.append(epoch) plt.plot(epoch_list, acc_list) plt.xlabel('epoch') plt.ylabel('accuracy') plt.grid() plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
运行结果
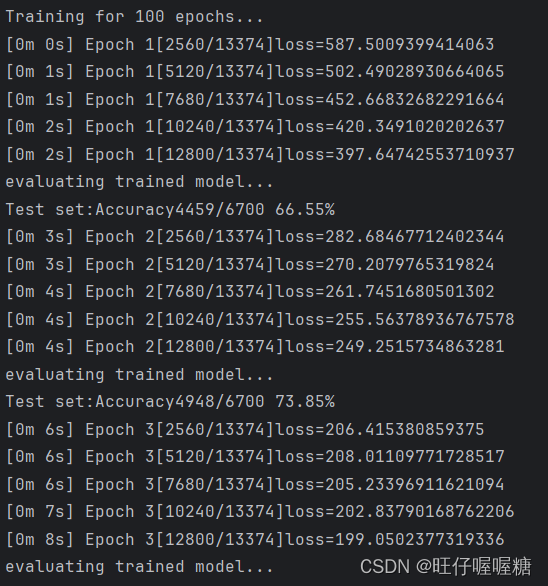
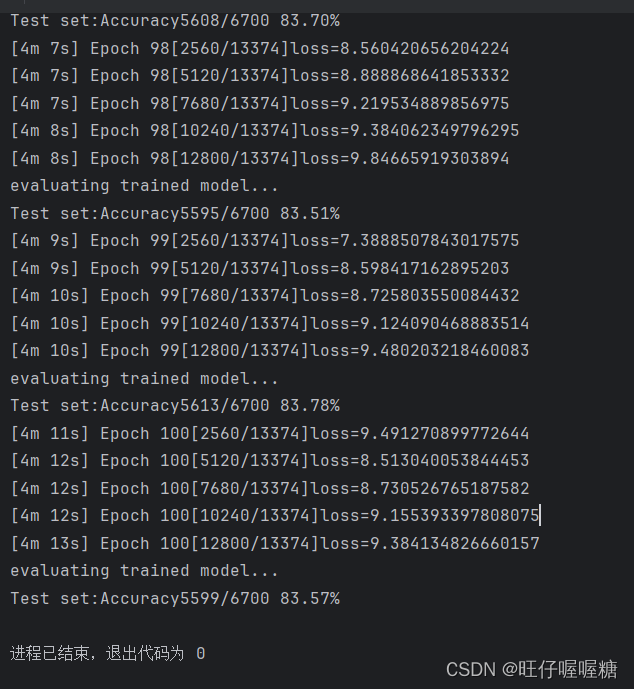
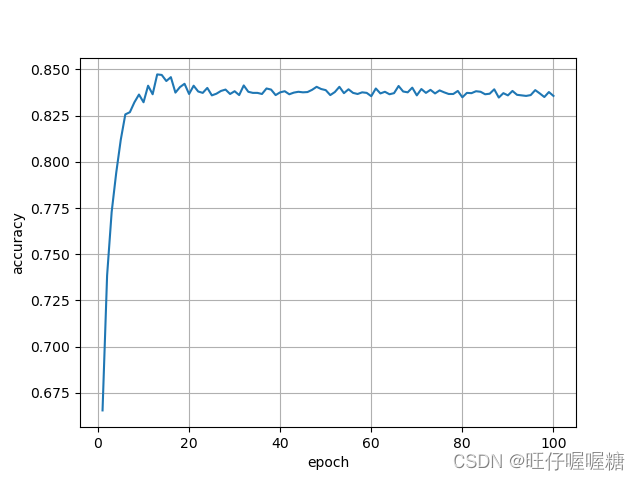
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/507987
推荐阅读
相关标签

