
- 1用GVIM/VIM写Verilog——VIM配置分享_gvim svstemverilog 插件
- 2深度学习之RNN循环神经网络(理论+图解+Python代码部分)
- 3数据流分析(一)_数据流分析怎么写
- 4python 之弗洛伊德算法_floyd-warshall算法python代码
- 5FPGA 静态时序分析与约束(2)_quartus unconstrained path
- 6微信小程序开发与应用——字体样式设置_微信小程序style属性
- 7多无人机对组网雷达的协同干扰问题 数学建模
- 8Python实现mysql数据库验证_python3 构建一个源和目的都是mysql的数据校验程序
- 9Win10安装安卓模拟器入坑记_exagear win10
- 10岛屿数量(dfs)
大模型日报第二期_ootdiffusion
赞
踩
资讯
研究
20分钟学会装配电路板!开源SERL框架精密操控成功率100%,速度三倍于人类

贡献人:@刘奕龙
https://mp.weixin.qq.com/s/57LjCBFFe8Pgb4aXfp5wHg
近年来,机器人强化学习技术领域取得显著的进展,例如四足行走,抓取,灵巧操控等,但大多数局限于实验室展示阶段。将机器人强化学习技术广泛应用到实际生产环境仍面临众多挑战,这在一定程度上限制了其在真实场景的应用范围。强化学习技术在实际应用的过程中,任需克服包括奖励机制设定、环境重置、样本效率提升及动作安全性保障等多重复杂的问题。业内专家强调,解决强化学习技术实际落地的诸多难题,与算法本身的持续创新同等重要。面对这一挑战,来自加州大学伯克利、斯坦福大学、华盛顿大学以及谷歌的学者们共同开发了名为高效机器人强化学习套件(SERL)的开源软件框架,致力于推动强化学习技术在实际机器人应用中的广泛使用。
首次大规模多语言评估,支持7种语言,生物医学领域7B开源LLM

贡献人:@刘奕龙
https://mp.weixin.qq.com/s/vNHXaGmliqUqIA9TSB8Yvw
大语言模型 (LLM) 已应用于医疗保健和医学等专业领域。尽管有各种为健康环境量身定制的开源 LLM,但将通用 LLM 应用于医学领域仍存在重大挑战。近日,法国阿维尼翁大学(Avignon Université )、南特大学(Nantes Université)和 Zenidoc 的研究团队开发了 BioMistral,一个专为生物医学领域量身定制的开源 LLM,利用 Mistral 作为其基础模型,并在 PubMed Central 上进行了进一步的预训练。研究人员根据由 10 项既定的英语医学问答 (QA) 任务组成的基准对 BioMistral 进行了全面评估。还探索通过量化和模型合并方法获得的轻量级模型。结果证明了 BioMistral 与现有开源医疗模型相比具有卓越的性能,并且与专有模型相比具有竞争优势。最后,为了解决英语以外的数据有限的问题,并评估医学 LLM 的多语言泛化能力,自动将该基准翻译和评估为 7 种其他语言。这标志着医学领域 LLM 的首次大规模多语言评估。
产业
OPPO 刘作虎:10 年内,手机还是 AI 的最好载体

贡献人:@刘奕龙
https://mp.weixin.qq.com/s/-lzWh5_vCeUtiS29oRiagA
手机 AI 功能应该怎么做?上个时代最重要的智能设备,在 AI 时代是将体验升级,还是将被新设备取代?前几日,魅族宣布将停止传统「智能手机」新项目的开发,全力投入新一代 AI 设备,引起了小范围的热议。而 2 月 20 日,仿佛是一种回应,将 AI 功能部署到手机上最积极的手机厂商之一的 OPPO,宣布了其 AI 战略。OPPO 在手机的 AI 功能方面布局很早。在 2020 年,OPPO 就推出了其首个 AI 大模型。2023 年大语言模型蓬勃发展的一年,OPPO 坚定了 AI 手机的布局。2024 年年初,OPPO 发布了 Find X7,是首个能够在端侧应用 70 亿参数大语言模型的手机。
Sora新视频只发TikTok:OpenAI 4天涨粉10万

贡献人:@刘奕龙
https://mp.weixin.qq.com/s/FqO2OgM2VaDCkKaoJAzZGQ
Sora新视频,变成“抖音独占”了。悄无声息,OpenAI正式杀入TikTok,加上洗脑配乐直接让人刷到停不下来,疯狂引流吸粉中:短短4天,涨粉10万,50万赞——这还是不打枪不宣传的情况下。a16z合伙人惊呼,如果这是在信息流里刷出来的,绝对分不出真假。
Karpathy新视频又火了:从头构建GPT Tokenizer

贡献人:@刘奕龙
https://mp.weixin.qq.com/s/S5MAafk6WYGDsD_MReGSTg
技术大神卡帕西离职OpenAI以后,营业可谓相当积极啊。这不,前脚新项目刚上线,后脚全新的教学视频又给大伙整出来了:这次,是手把手教咱构建一个GPT Tokenizer(分词器),还是熟悉的时长(足足2小时13分钟)。Tokenizer即分词器是大语言模型pipeline中一个完全独立的阶段。它们有自己的训练集、算法(比如BPE,字节对编码),并在训练完成后实现两个功能:从字符串编码到token,以及从token解码回字符串。为什么我们需要关注它?卡帕西指出:因为LLM中的很多奇怪行为和问题都可以追溯到它。
推特
Jason Wei分享:作为OpenAI的技术员工,一个典型的工作日都做了什么

贡献人:@Angela Chen Hanzhe 2022
https://x.com/_jasonwei/status/1760032264120041684?s=20
我的典型工作日,作为OpenAI的技术员工:
[上午9:00] 起床
[上午9:30] 乘坐Waymo前往Mission SF上班。在Tartine买鳄梨吐司
[上午9:45] 背诵OpenAI宪章。向优化之神祈祷。学习苦涩的教训
[上午10:00] 会议(Google Meet)。讨论如何在更多数据上训练更大的模型
[上午11:00] 编写代码,在更多数据上训练更大的模型。合作伙伴=@hwchung27
[中午12:00] 在食堂吃午餐(素食,无麸质)
[下午1:00] 实际上在更多数据上训练大型模型
[下午2:00] 调试基础设施问题(为什么我要从master分支拉代码?)
[下午3:00] 照看模型训练。和Sora玩耍
[下午4:00] 提示工程师前述在更多数据上训练的大型模型
[下午4:30] 短暂休息,坐在鳄梨椅上。想知道Gemini Ultra到底有多好
[下午5:00] 头脑风暴,寻找模型的潜在算法改进
[下午5:05] 得出结论,算法变更风险太大。更安全的方法是扩大计算和数据规模
[下午6:00] 晚餐。与Roon共享蛤蜊浓汤
[下午7:00] 回家
[晚上8:00] 喝点葡萄酒,回到编码工作。巴尔默峰即将到来
[晚上9:00] 分析实验运行。我对wandb既爱又恨
[晚上10:00] 启动实验,隔夜运行,以便明早获得结果
[凌晨1:00] 实验实际启动
[凌晨1:15] 睡觉时间。萨提亚和詹森在上方守望。压缩是你所需要的一切。晚安
Carlos E. Perez:Groq是一种根本不同的AI架构

贡献人:@Angela Chen Hanzhe 2022
https://x.com/IntuitMachine/status/1759941976927924682?s=20
Groq是一种根本不同的AI架构
在新一代AI芯片初创公司中,Groq以其围绕编译器技术优化的极简高性能架构的根本不同方法脱颖而出。Groq的秘密武器是这种优先考虑编译器的方法,它避免了复杂性,转而追求为特定效率量身定制。
Groq架构的核心是一个几乎令人惊讶的极简设计,它摒弃了不必要的逻辑,转而专注于原始的并行吞吐量。硬件本身可比拟于ASIC(应用特定集成电路),这是一种为机器学习精细调优的电路。然而,与固定功能的ASIC不同,Groq利用了一个自定义编译器,可以适应并优化不同的模型。正是这种流线型架构和智能编译器的结合,使Groq与众不同。
关键的洞察是,许多AI芯片堆叠了组件,如GPU,这带来了额外的硬件和膨胀。Groq回归基本原理,认识到机器学习工作负载关乎在简单数据类型和操作上的大规模并行性。通过消除通用硬件甚至是局部性等概念,设计最大化了吞吐量和效率。
这是通过Groq的编译器实现的,该编译器位于软件框架(如TensorFlow)和硬件之间。编译器分析和优化神经网络图,将它们定制并映射到底层架构上以加速执行。它将计算分解为最小的操作以释放并行性。编译器还启用了如批量大小为1的推理等功能,确保所有硬件都被有效利用。
关键的是,Groq在最终确定硬件设计之前就构建了其编译器。软件洞察直接影响了架构。这种共同设计过程允许在没有遗留限制的情况下进行推理特定的优化。编译器还提供了运行时间的确定性保证,使得可靠的扩展成为可能。
Groq的编译器和架构共同形成了一个流线型、强大的机器学习推理引擎。创新的编译器优先方法允许进行自定义优化,平衡了灵活性与性能。Groq意识到,当软件和硬件对齐时,少可以是更多,这是一个随着AI工作负载不断演进而显得更加引人注目的配方,而不是追求复杂性。
Yao Fu:“长上下文将取代RAG”观点的反论和可能的解决方式

贡献人:@Angela Chen Hanzhe 2022
https://x.com/Francis_YAO_/status/1759962812229800012?s=20
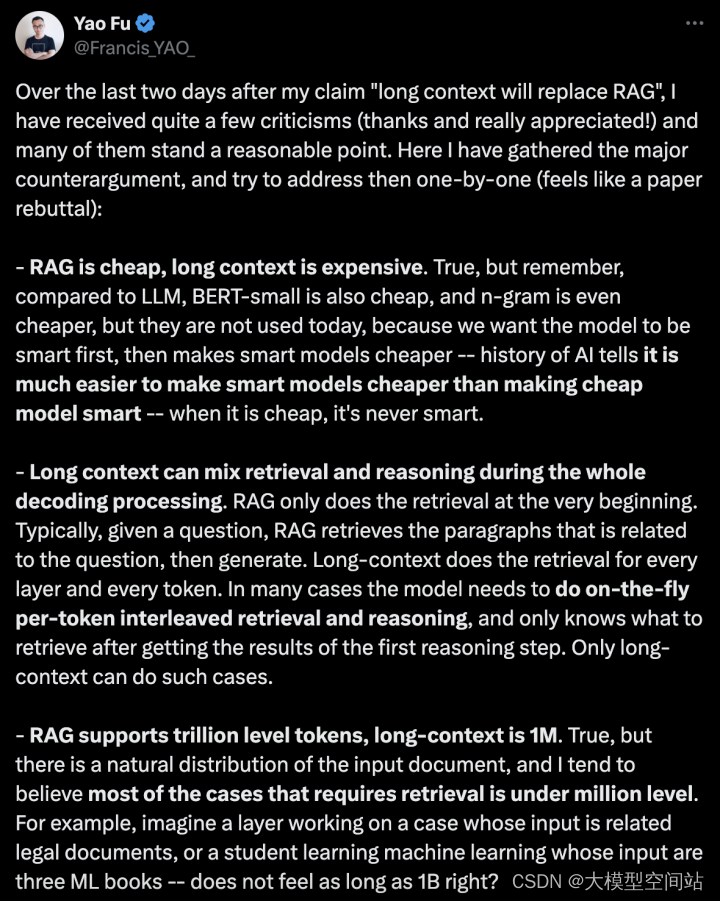
在我声称“长上下文将取代RAG”之后的最后两天里,我收到了不少批评(感谢,真的很感激!),其中许多是站得住脚的。在这里,我收集了主要的反论,并尝试一一解决(感觉像是一篇论文的驳斥):
•RAG便宜,长上下文昂贵。确实如此,但请记住,相比于大型语言模型(LLM),BERT-small也很便宜,n-gram甚至更便宜,但他们今天不被使用,因为我们首先希望模型先聪明起来,然后再让聪明的模型变得便宜——人工智能的历史告诉我们,让聪明的模型变得便宜比让便宜的模型变聪明要容易得多——当它便宜时,它永远不会聪明。
•长上下文可以在整个解码过程中混合检索和推理。RAG只在最开始进行检索。通常情况下,给定一个问题,RAG检索与问题相关的段落,然后生成。长上下文对每一层和每一个令牌都进行检索。在许多情况下,模型需要进行实时的每个令牌交错检索和推理,并且只有在获得第一步推理结果后才知道要检索什么。只有长上下文可以处理这样的情况。
•RAG支持万亿级令牌,长上下文是100万。确实如此,但输入文档有其自然分布,我倾向于相信大多数需要检索的情况都在百万级以下。例如,想象一个处理相关法律文件的案例的层,或者一个学习机器学习的学生,其输入是三本ML书——感觉不像10亿那么长对吧?
•RAG可以被缓存,长上下文需要重新输入整个文档。这是对长上下文的一个常见误解:有一种叫做KV缓存的东西,你也可以设计复杂的缓存和内存层次结构ML系统与kv缓存一起工作。这意味着,你只需读取输入一次,然后所有后续查询都将重用kv缓存。有人可能会说kv缓存很大——确实如此,但别担心,我们LLM研究人员会及时给你提供疯狂的kv缓存压缩算法。
•你还想调用搜索引擎,这也是一种检索。确实如此,在短期内,这将继续成立。然而,有些疯狂的研究人员的想象力可能很狂野——例如,为什么不让语言模型直接关注整个谷歌搜索索引,即,让模型吸收整个谷歌。我的意思是,既然你们相信通用人工智能,为什么不呢?
•今天的Gemini 1.5 1M上下文很慢。确实如此,它肯定需要更快。我对此持乐观态度——它肯定会快得多,并最终与RAG一样快
我们来看看事态将如何发展,好吗?
Karpathy推荐"我对大型语言模型的基准测试":一个全功能的测试评估框架
贡献人:@Angela Chen Hanzhe 2022
https://x.com/karpathy/status/1760022429605474550?s=20
"我对大型语言模型的基准测试"
https://nicholas.carlini.com/writing/2024/my-benchmark-for-large-language-models.html
这篇文章很不错,但不仅仅是特定的100个测试,GitHub上的代码看起来非常出色——一个全功能的测试评估框架,易于通过进一步的测试扩展并针对多个LLM运行。
https://github.com/carlini/yet-another-applied-llm-benchmark/tree/main
例如,目前100个测试在7个模型上的通过率:
•GPT-4:49%通过
•GPT-3.5:30%通过
•Claude 2.1:31%通过
•Claude Instant 1.2:23%通过
•Mistral Medium:25%通过
•Mistral Small:21%通过
•Gemini Pro:21%通过
我也非常喜欢从聊天历史中实际用例挖掘测试的想法。我认为人们会对许多“标准”的LLM评估基准测试的奇怪和人为性感到惊讶。现在……社区如何在这些基准测试上进行更多的合作……

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

