
- 1行业现状?互联网公司为什么宁愿花20k招人,也不愿涨薪留住老员工~_互联网企业不晋升和加薪的原因有哪些
- 2初次使用git上传项目,教你一步步上传文件,经验分享_阿里云云效新建了代码库如何上传项目
- 3EMNLP2021 | 实体关系抽取新SoTA - 对NER和RE任务进行联合编码
- 4Delphi中小试Opencv--图像差异对比(大家来找茬辅助实现cvAbsDiff函数的使用)_delphi opencv
- 5如何把拉线位移传感器应用在浆纱机上_拉线传感器应用
- 6如何看待自然语言处理未来的走向?
- 7(附源码)计算机毕业设计SSM快递代收系统_ssm和vue校园快递代取系统
- 8LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
- 9猿创征文|大数据之离线数据处理总结+思维导图(全面总结)_离线大数据处理能力
- 10【无标题】_setupprodoffscrub无法连接网络
YOLOv8改进算法之添加CA注意力机制_yolov8添加注意力机制
赞
踩
1. CA注意力机制
CA(Coordinate Attention)注意力机制是一种用于加强深度学习模型对输入数据的空间结构理解的注意力机制。CA 注意力机制的核心思想是引入坐标信息,以便模型可以更好地理解不同位置之间的关系。如下图:

1. 输入特征: CA 注意力机制的输入通常是一个特征图,它通常是卷积神经网络(CNN)中的某一层的输出,具有以下形状:[C, H, W],其中:
C是通道数,表示特征图中的不同特征通道。H是高度,表示特征图的垂直维度。W是宽度,表示特征图的水平维度。
2. 全局平均池化: CA 注意力机制首先对输入特征图进行两次全局平均池化,一次在宽度方向上,一次在高度方向上。这两次操作分别得到两个特征映射:
- 在宽度方向上的平均池化得到特征映射
[C, H, 1]。 - 在高度方向上的平均池化得到特征映射
[C, 1, W]。
这两个特征映射分别捕捉了在宽度和高度方向上的全局特征。
3. 合并宽高特征: 将上述两个特征映射合并,通常通过简单的堆叠操作,得到一个新的特征层,形状为 [C, 1, H + W],其中 H + W 表示在宽度和高度两个方向上的维度合并在一起。
4. 卷积+标准化+激活函数: 对合并后的特征层进行卷积操作,通常是 1x1 卷积,以捕捉宽度和高度维度之间的关系。然后,通常会应用标准化(如批量标准化)和激活函数(如ReLU)来进一步处理特征,得到一个更加丰富的表示。
5. 再次分开: 分别从上述特征层中分离出宽度和高度方向的特征:
- 一个分支得到特征层
[C, 1, H]。 - 另一个分支得到特征层
[C, 1, W]。
6. 转置: 对分开的两个特征层进行转置操作,以恢复宽度和高度的维度,得到两个特征层分别为 [C, H, 1] 和 [C, 1, W]。
7. 通道调整和 Sigmoid: 对两个分开的特征层分别应用 1x1 卷积,以调整通道数,使其适应注意力计算。然后,应用 Sigmoid 激活函数,得到在宽度和高度维度上的注意力分数。这些分数用于指示不同位置的重要性。
8. 应用注意力: 将原始输入特征图与宽度和高度方向上的注意力分数相乘,得到 CA 注意力机制的输出。
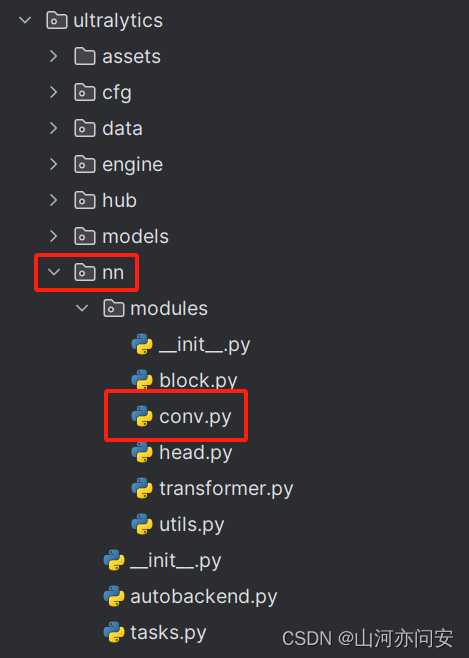
2. YOLOv8添加CA注意力机制
加入注意力机制,在ultralytics包中的nn包的modules里添加CA注意力模块,我这里选择在conv.py文件中添加CA注意力机制。
CA注意力机制代码如下:
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
-
-
- class h_sigmoid(nn.Module):
- def __init__(self, inplace=True):
- super(h_sigmoid, self).__init__()
- self.relu = nn.ReLU6(inplace=inplace)
-
- def forward(self, x):
- return self.relu(x + 3) / 6
-
-
- class h_swish(nn.Module):
- def __init__(self, inplace=True):
- super(h_swish, self).__init__()
- self.sigmoid = h_sigmoid(inplace=inplace)
-
- def forward(self, x):
- return x * self.sigmoid(x)
-
-
- class CoordAtt(nn.Module):
- def __init__(self, inp, reduction=32):
- super(CoordAtt, self).__init__()
- self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
- self.pool_w = nn.AdaptiveAvgPool2d((1, None))
-
- mip = max(8, inp // reduction)
-
- self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
- self.bn1 = nn.BatchNorm2d(mip)
- self.act = h_swish()
-
- self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
- self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
-
- def forward(self, x):
- identity = x
-
- n, c, h, w = x.size()
- x_h = self.pool_h(x)
- x_w = self.pool_w(x).permute(0, 1, 3, 2)
-
- y = torch.cat([x_h, x_w], dim=2)
- y = self.conv1(y)
- y = self.bn1(y)
- y = self.act(y)
-
- x_h, x_w = torch.split(y, [h, w], dim=2)
- x_w = x_w.permute(0, 1, 3, 2)
-
- a_h = self.conv_h(x_h).sigmoid()
- a_w = self.conv_w(x_w).sigmoid()
-
- out = identity * a_w * a_h
-
- return out
CA注意力机制的注册和引用如下:
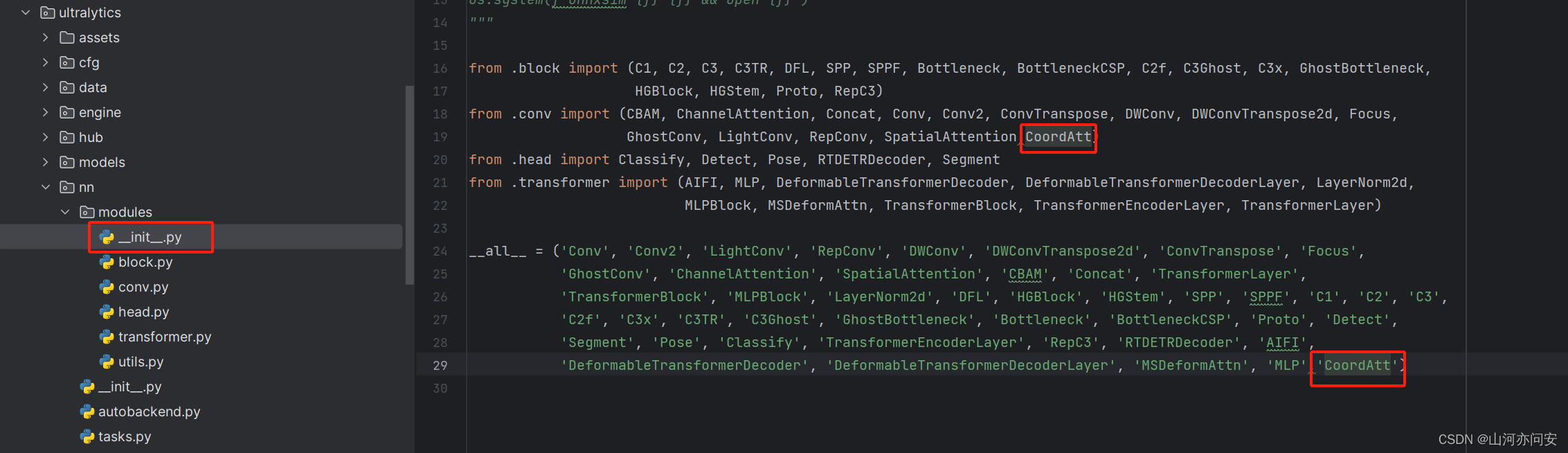
ultralytics/nn/modules/_init_.py文件中:
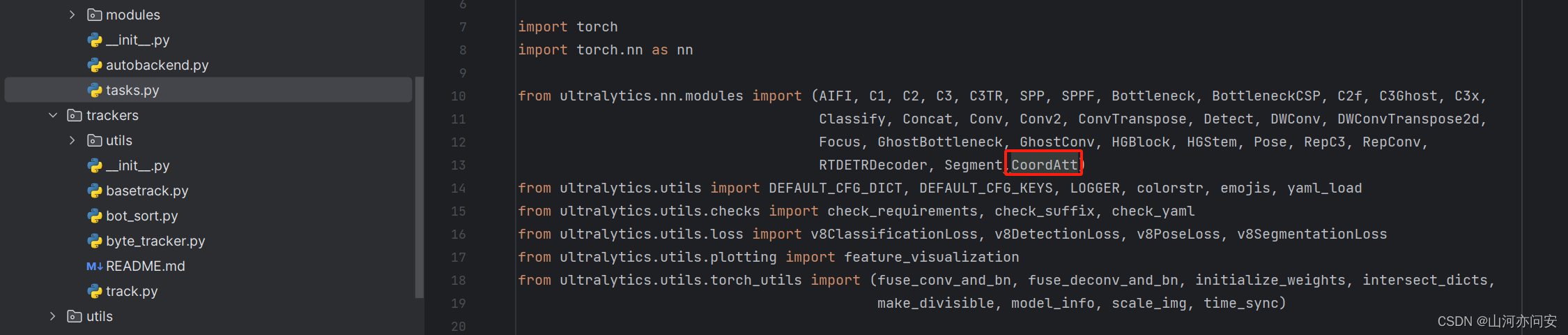
ultralytics/nn/tasks.py文件夹中:
在tasks.py中的parse_model中添加如下代码:
- elif m in {CoordAtt}:
- args=[ch[f],*args]
新建相应的yolov8s-CA.yaml文件,代码如下:
- # Ultralytics YOLO 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

