
- 1基于魏格纳函数和焦散线方法的自加速光束matlab模拟与仿真
- 2github 2fa 中国区认证解决_github sms 手机验证不支持中国
- 3Excel查找匹配函数(VLOOKUP):功能与应用解析
- 4用 MVP(最小可行性产品) 做低成本快速验证,为什么不灵了?| Liga译文
- 5关于前端技术文章_前端写一个关于技术方面的文章
- 6智能电销机器人《各版本机器人部署》_ai电销电话机器人php源码搭建部署(2022完整可用包安装使用
- 7云计算时代,NGINX将是你的“必杀技”_云计算为什么学nginx架构
- 8再见了,华为!_可信考试
- 9自然语言处理的发展及归纳介绍
- 10月薪9K!前台测试男生偷偷努力,工资翻倍转行5G网络优化工程师,“卷死”所有人!_5g网络优化测试赚钱吗
Hadoop大数据开发基础系列:三、Hadoop基础操作_hadoop基本用法
赞
踩
第三章、Hadoop基础操作
目录结构:
1.查看Hadoop集群的基本信息
1.1 查询集群的存储系统信息
1.2 查询系统的计算资源信息
2.上传文件到HDFS目录
2.1 了解HDFS文件系统
2.2 掌握HDFS的基本操作
2.3 任务实现
3.运行首个MapReduce任务
3.1 了解Hadoop官方的示例程序包
3.2 提交MapReduce任务给集群运行
4.管理多个MapReduce任务
4.1 查询MapReduce任务
4.2 中断MapReduce任务
5.小结
6.课后练习
主要背景:是统计某网站的用户登录次数,整个任务体系包括检查Hadoop集群资源、文件存储、分布式计算调用及任务监控等。
1.查看Hadoop集群的基本信息
Hadoop集群的数据存储是通过HDFS来实现的。HDFS是由一个NameNode和多个DataNode组成,构成了一个分布式的文件系统。通常有两种方式查看HDFS文件系统的信息,分别是命令行方式和浏览器方式。
Hadoop集群的计算资源也是分布在集群的各个节点上,通过ResourceManager与NodeManager来协同调配。一般可以通过浏览器访问ResourceManager的监控服务来查询Hadoop集群的计算资源。
1.1 查询集群的存储系统信息
(1)HDFS的监控服务通过NameNode的端口50070来访问,我们可以通过此界面看到运行情况

(2)通过命令行也可以查询HDFS信息。在集群服务器的终端,输入相关查询命令
hdfs dfsadmin -report [-live] [-dead] [-decommissioning]-live 输出在线节点基本信息及相关数据统计
-dead 输出失效节点的基本信息及相关数据统计
-decommissioning 停用节点的基本信息及相关数据统计
1.2 查询系统的计算资源信息
(1)通过ResourceManager可以方便地查询目前集群上的计算资源信息。进入8088端口:

(2)进入8042端口查看节点的各项资源信息:

根据以上显示的信息,就可以初步了解到当前集群的计算资源情况,主要包括集群上的可用计算节点、可用CPU核心与内存,以及各个节点自身的CPU及内存资源。
2.上传文件到HDFS目录
2.1 了解HDFS文件系统
HDFS是一个类Linux的独立的文件系统,其跟我们的了解操作系统目录类似。(可以通过web端查看文件目录信息)

2.2 掌握HDFS的基本操作
对于HDFS文件系统的基本操作,可以通过HDFS命令来实现,在终端,输入“hdfs dfs”命令,就可以完成对HDFS目录及文件的大部分管理操作,包括创建新目录、上传与下载文件、查看文件内容、删除文件等。
(1)创建新目录/user/dfstest
直接在终端输入 hdfs dfs 就可以得到提示的命令:

然后我们执行创建目录路径的命令:
注意,此命令只能主机创建目录,所以我们可以加-p来补全中间并不存在的目录结构:
![]()
hdfs dfs -mkdir -p /user/test/example![]()
然后我们在根目录下查看一下我们创建的hdfs文件目录:
- hdfs dfs -ls [path] //因为hdfs文件系统不同于Linux,所以要用hdfs命令才能看到
-
- //一定要注意一下,如果没有指定path,系统会自动的定向到path=/home/[username],因为我们并没有此目录,所以系统找不到,我们要指定path,根目录就直接用 / 即可。

(2)上传文件与下载文件
再创建一个新的文件夹,用于做测试
![]()
①上传文件
测试任务:利用 hdfs 命令把集群服务器节点上的本地文件 test1.txt 上传到 HDFS目录 /user/dfstest中
命令:
- hdfs dfs [-copyFromLocal [-f][-p][-l] <localsrc> <dst> ]
- //将文件从本地系统复制到HDFS文件系统,主要参数<localsrc>为本地路径,<dst>为要复制到的目的路径
-
- hdfs dfs [-moveFromLocal <localsrc> <dst>]
- //将文件从本地文件系统移动到HDFS文件系统,主要参数<localsrc>为本地路径,<dst>为要移动到的目的路径
-
- hdfs dfs [-put [-f][-p][-l] <localsrc> <dst>]
- //将文件从本地文件系统上传到HDFS文件系统,主要参数<localsrc>为本地路径,<dst>为要上传到的目的路径

②下载文件
同样,我们也可以从HDFS中下载需要的文件
命令:
- hdfs dfs [-copyTolocal [-p][-ignoreCrc][-crc] <src> <localdst>]
- //将文件从HDFS文件系统复制到本地文件系统,主要参数<src>为HDFS文件系统路径,<localdst>为本次存放文件路径
-
- hdfs dfs [-get [-p][-ignoreCrc][-crc] <src> <localdst>]
- //获取HDFS文件系统上指定路径的文件到本地文件系统,主要参数<src>为HDFS文件系统路径,<localdst>为本次存放文件路径
(3)查看文件内容
查看HDFS系统中的文件内容:
命令:
- hdfs dfs [-cat [-ignoreCrc] <src>]
- //查看HDFS文件内容,<src>指定文件路径
-
- hdfs dfs [-tail [-f] <file>]
- //查看HDFS最后1024字节,<file>指定文件路径
示例:

(4)删除文件或目录
- hdfs dfs [-rm [-f][-r][-skipTrash] <src>]
- //删除HDFS上的文件,主要参数-r用于递归删除,<src>指定删除的文件路径
-
- hdfs dfs [-rmdir [--ignore-fail-on-non-empty] <dir>]
- //如果删除的是一个目录,可以用此命令,主要参数<dir>指定目录路径
示例:
![]()
2.3 任务实现
(1)把email_log.txt传输到master的/testhadoop目录下

(2)将文件上传到HDFS文件系统的/user/dftest目录下
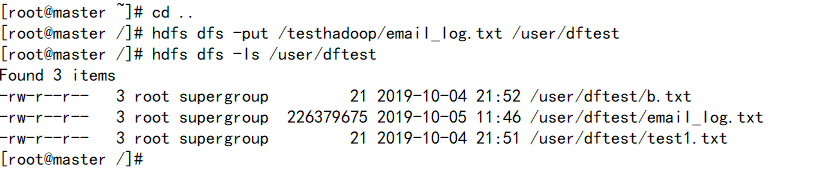
(3)在web端单击 email_log.txt 检查文件内容

我们可以看到文件分为两个块来存储(文件大小216M),每个文件块都有3个副本,分别存储在3个不同的数据节点上。
3.运行首个MapReduce任务
要求对HDFS文件目录中的数据文件/user/root/email_log.txt进行计算处理,统计出每个用户的登录次数,即可以等同于求出每个email出现的次数,可以进一步抽象为统计每个单词出现的频次。在Hadoop集群上执行程序包,即提交一个MapReduce任务,通常使用hadoop jar命令完成。
3.1 了解Hadoop官方的示例程序包
在集群服务器本地目录:“$HADOOP_HOME/share/hadoop/mapreduce/ ”中可以发现示例程序包 “hadoop-mapreduce-examples-2.7.7.jar”,这个程序包封装了一些常用的测试模块,内容如下:
| multifilewc | 统计多个文件中单词的数量 |
| pi | 应用quasi-Monte Carlo算法来估算圆周率π的值 |
| randomtextwriter | 在每个数据节点随机生成一个10GB的文本文件 |
| wordcount | 对输入文件的单词进行频次统计 |
| wordmean | 计算输入文件中单词的平均长度 |
| wordmedian | 计算输入文件中单词长度的中位数 |
| wordstandarddeviation | 计算输入文件中单词长度的标准差 |
在本次测试中,使用wordcount对email_log.txt文件中的数据进行登录次数统计。
3.2 提交MapReduce任务给集群运行
(1) 提交MapReduce任务时,hadoop jar 命令用法:
hadoop jar <jar> [mainClass] args
下面结合实例来对各个参数进行说明:
- hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /user/dftest/email_log.txt /user/dftest/output
-
- //<jar>是jar包的位置,[mainClass是指要使用的已封装好的类],args可以指定一些读取文件和输出文件的存放目录。
(2)运行日志如下:



(3)结果查看:

我们可以看到,在output文件中生成了两个新文件:一个是_SUCCESS,这是一个标识文件,表示这个任务执行完成;另一个是part-r-00000,即任务执行完成后产生的结果文件。
查看part-r-00000内容:

任务基本完成 ^_^ 。
4.管理多个MapReduce任务
Hadoop是一个多任务系统,可以同时为多个用户、多个作业处理多个数据集。对于提交到Hadoop集群的多个任务,如何进行管理呢,比如:如何知道集群完成了哪些任务;执行结果是成功还是失败;怎么检查任务的实际执行情况;如果某个任务执行时间过长,如何中断它?
4.1 查询MapReduce任务
(1)本例中用示例程序包内的PI类来执行估计π的值
- hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 10 100
-
- //后面两个参数代表Map数量与每个Map的测算次数,参数的值越大,计算出来的结果精度越高
(2)执行日志:


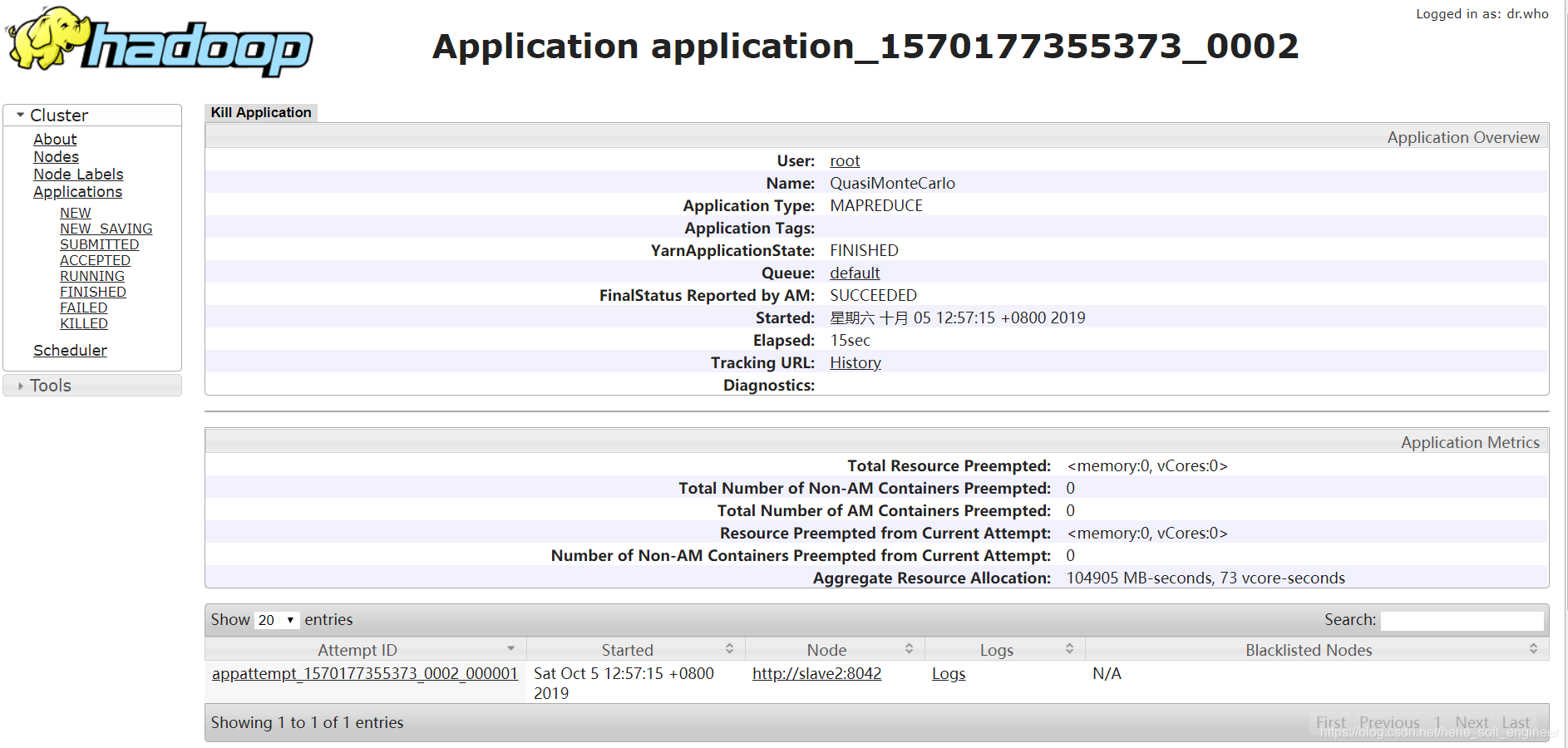
(3)查看刚刚提交的MapReduce任务的计算资源使用情况:
①在此页面我们可以实时看到集群资源的使用情况(因为执行完成,所以参数为初始参数)

②资源管理器显示的MapReduce任务列表:

③查看任务的详细信息:
(4)提交多任务:
同时启动集群的两个服务器终端,依次提交两个作业:wordcount和计算pi值
我们可以观察集群上的计算资源使用情况,有一个作业在运行中,占用了大部分的计算资源,另一个作业在等待状态(等待给它分配计算资源,当计算资源满足后,它才会开始执行)。
4.2 中断MapReduce任务
对已提交的MapReduce任务,在某些特殊情况下需要中断它,比如发现程序有异常、某个任务执行时间过长、占用大量计算资源等。
可以通过web界面上面的Application 页面选择界面上的选项“Kill Application”,选择确定即可中断该任务,再次刷新页面可以看到该任务已被终止,等待中的任务执行。
5.小结
本章主要介绍了Hadoop的基础操作知识,结合实际任务及多个实例,使我对Hadoop集群的文件操作系统与计算资源,以及提交MapReduce任务有了初步的了解。
6.小练习
(1)以 hadoop jar 提交MapReduce任务时,如果命令行中指定的输出目录已经存在,执行的结果将会是:C
A.覆盖原目录 B.自动创建新目录 C. 报错并终止任务 D. 以上都不是
下一章将介绍MapReduce编程入门 ^_^ 。


