
- 1网络安全常见的三层架构(非常详细)零基础入门到精通,收藏这一篇就够了_三层网络架构教程
- 2AI学习:文本生成 chat3.5_chatcompletion message=chatcompletionmessage(conte
- 3avr单片机USART串口通讯初始化配置说明_avr单片机串口初始化
- 410个自动化测试框架,测试工程师用起来
- 5HIVE sparkSQL sum()over()开窗函数的效率问题_spark sql sum() over()
- 6Linux内核编程 消息队列使用案例_消息队列编程
- 7kafka 查看待消费数据_查看kafka消息消费情况
- 8Win10环境下使用Ollama搭建本地AI_ollama 修改下载地址
- 9纯前端导出带样式的excel:exceljs_excel.js
- 10python拟合函数_python拟合函数
【云原生】AI云开发平台——AI Model Foundry介绍(开发者可免费体验AI训练模型)
赞
踩
“本文主要介绍了华为云原生开发GDE AI 下的AI Model Foundry模块, 华为云为开发者提供了丰富的云原生免费体验平台,并发布了众多云原生开发教程,有助于云原生开发者深入学习云开发相关知识,成为高级云原生工程师。”
- (文末附华为云官方云原生开发教程、华为云开发者免费注册体验指南、华为云原生GDE AI开发入口)
前言
本文三大主要板块:
- 华为GDE AI开发平台
- GDE Model Foundry低门槛开发工具
- AI Model Foundry实战演示
一、GDE AI平台介绍
1.平台简介
GDE AI平台是面向GTS AI开发者的一站式开发平台,提供海量数据预处理、样本自动化标注、大规模分布式训练、自动化模型生成及按需部署预测服务的能力;并提供了图像、文字、知识图谱、自然语言处理、预测性维护等多种AI领域通用服务,使企业能快速开发和构建AI业务,并且支持电信网终端制造等行业自动化、智能化解决方案实现。

GDE平台辅助组成元素:
- GDE技术底座——屏蔽GDE平台对基础设施的依赖,使AI平台能够轻松部署到各种硬件资源上。
- GDE数据中台——集成存储、处理数据,使AI平台能够专注于样本库的处理。
- GDE应用开发中心——从界面、数据、服务等层面对其进行编排。
- GDE运维中心——对服务面和数据面进行统一的运维管理。
关键特性:效率高、门槛低、性能优、运维易。

2. 平台功能
2.1 样本处理与数据增强能力
- 样本处理流程:数据上传——自动/人工筛选——人工标注——标注审核——生成数据集——训练模型——数据推理——失败数据回传重新标注
流程图:

优势:
①价值样本数量多,数据复用率高。
②样本标注工具极其丰富。
③能快速克隆样本,并有样本增强的能力,可以优化样本质量。

2.2 模型训练、模型开发
GDE平台提供丰富、一站式的开发工具链,通过Notebook在线开发和PyCharm本地开发、远程调试的方式,能够有效提升AI开发效率,通过导航式开发可以有效降低AI应用开发门槛。
支持的开发方式:Notebook在线开发;PyCharm本地开发、任务远端执行测试;基于模板的导航式开发。

2.3 推理服务
- 推理服务:一键式将服务模型封装部署供上层应用调用。
a.推理服务的基本能力:
①支持预测服务的运行状态监控、日志分析。
②支持滚动升级和灰度发布。
③支持模型监控及重训练。
④支持不同框架模型格式(例如:.pb/.pkl/.h5)。
⑤支持Tensorflow/Pytorch/Spark MLlib框架。
⑥支持深度学习任务GPU加速执行。
b.推理服务与传统自部署模型对比:

c.推理服务的调用方式:
①在线推理(通过API接口调用)
特点:高并发、低延时、自动弹性伸缩、推理效率高、支持多模型灰度发布。
②批量推理
特点:高效率分布式计算、可处理大量数据推理、支持GPU加速。

二、GDE Model Foundry介绍
1.知识导读
什么是AI?——能够“自主学习到一个函数”的程序。
示例:
在语音识别领域,给定一段语音波形,AI能够自主学习到一个函数将语音波形转化为文字。
在图像识别领域,给定一张图片,AI能够自主学习到一个函数将图像识别。

Model Foundry——解决AI开发的主要痛点
AI开发痛点一:专业门槛高、技术栈多
传统AI开发所需部分技能:高等数学基础、AI相关理论知识、编程技术能力

AI开发痛点二:开发流程长、集成难度高、无资产复用和沉淀
AI开发流程概览:

2.GDE Model Foundry
2.1 GDE Model Foundry是什么?
- 定义:Model Foundry寓意模型精炼工厂,打造高质量模型规模生产、批量交付。
- 目标:降低AI建模门槛,支持低代码开发;沉淀AI资产,提升AI建模效率,缩短开发周期。
- 核心:模块化、流程化AI开发的中间过程。
2.2 AI Model Foundry开发优点:
①能力可复用、高效建模、节省人力。
②向导式开发,可视化建模、准入门槛低。
③AI模型全生命周期管理,可持续监控、持续训练。

附:传统AI开发模式开发人力资源 VS AI Model Foundry 开发人力资源

附:传统AI开发现实体验 VS AI Model Foundry 开发现实体验

2.3 AI Model Foundry架构
①基础设施:兼容主流基础设施,如:docker、私有云、公有云等。
②基础框架:兼容丰富的基础框架,如:PyTorch等.
③Model Foundry:提供模板引擎以及针对不同应用场景的AI模板库。
④应用领域:支持电信领域、工业领域、通用业务等多领域的应用。

2.4 AI Model Foundry模板开发
特点:
①基于Jupyter Notebook的开发环境(对接ADC编排)。
②提供可视化开发调试插件(例如:PyTorch)。

③提供丰富的SDK开发组件和预置算子支持。
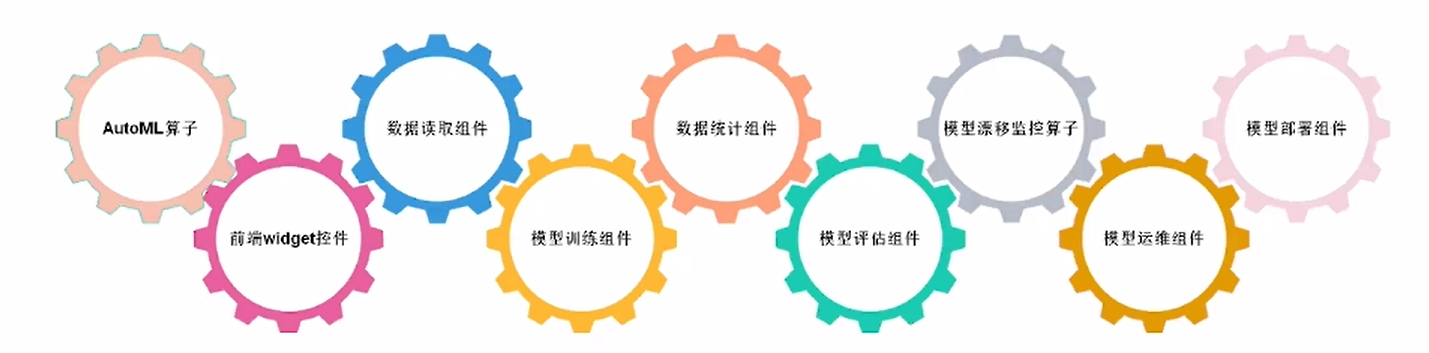
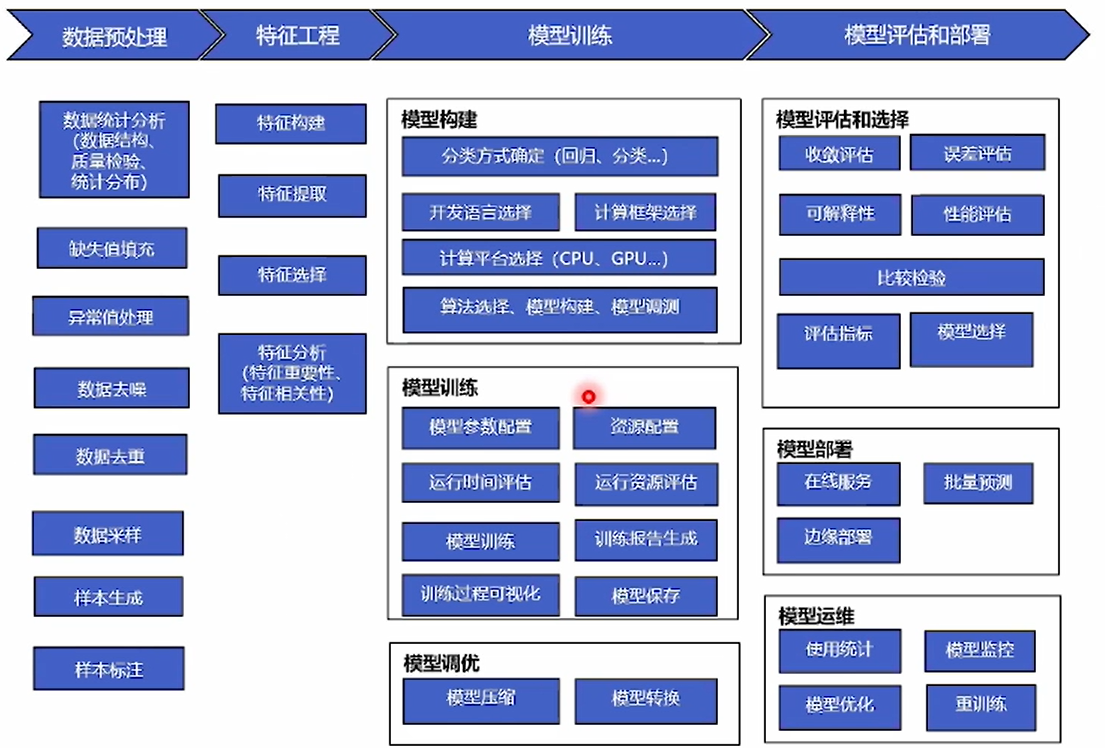
模板开发:通过模板引擎提供的流水线(Pipeline),实现各个模块的功能,进行基于模板的从零开发。
模板开发的六个子流程:
开发态:
①数据:进行数据源的配置,数据模型定义,特征工程的处理等(如:数据标注)。
②算法:算法配置,设定训练的目标,算法结果评估等。
③模型:工作流程的编排,模型安全的制定等。
运行态:
④服务:模型部署(上线、离线),安全验证,模型包解析加载,服务管理等。
⑤评估:模型监控,精度跟踪,模型验证评估等。
⑥调优:模型优化,优化对比等。(可选)

2.5 AI Model Foundry开发模板
开发模板的基本概念:(层次从高到低)模板 → Pipeline → Stage → Component

①Pipeline:指机器学习开发应用过程中从数据读取到数据预处理、特征工程、模型训练和模型评估和部署监控的一个完整的机器学习过程。模型生命周期过程中涉及多个独立的处理流程,每个流程抽象为一个Pipeline。比如:模型训练、模型评估优化和模型推理。Pipeline由一系列的步骤(Stage)顺序组成。

②Stage:Stage步骤是机器学习工作流中各个阶段的抽象,是最小的调度执行单元(不同步骤可运行在不同的计算引擎上),对应导航式中的操作步骤页,将复杂的DAG图转换为导航式步骤页面。每个Stage包含若干组件(component)。

③Component:Component组件是满足一定功能的最小逻辑单元,整个ML Pipeline由一系列的component组成一个DAG。
每个component包含三部分:输入——运行参数和前一个component的输出,运行参数通过在界面UI组件配置;输出——是后一个component的输入,也可以指定UI组件进行结果的可视化呈现;执行逻辑——业务处理逻辑。
④实例:模板实例简称实例,是模板实例化运行的结果,模板与实例的关系类似于面向对象编程中类的实例化过程。
⑤Job: 指Pipeline执行(每个AI处理过程)的实例化结果,支持手动和周期性触发运行。
⑥Run: 指Job的每一次执行的实例化结果,包括周期性作业的每次执行。
实例化:

2.6 模板二次开发方案
模板二次开发:若当前模板无法通过数据集增强及超参数调整的优化方式满足业务需求,可使用Notebook提供的模板二次开发功能,对当前模板进行二次开发,引入新的算法。
二次开发步骤:(以图像分割模板为例)
新建Notebook——配置Notebook参数——下载预置模板——修改模块包的代码——生成新模板包——发布模板包——二次开发完成
流程图:


正在上传…重新上传取消
三、使用Model Foundry进行建模与实战(以AI自动检测工厂黑烟为例)

1.建模步骤
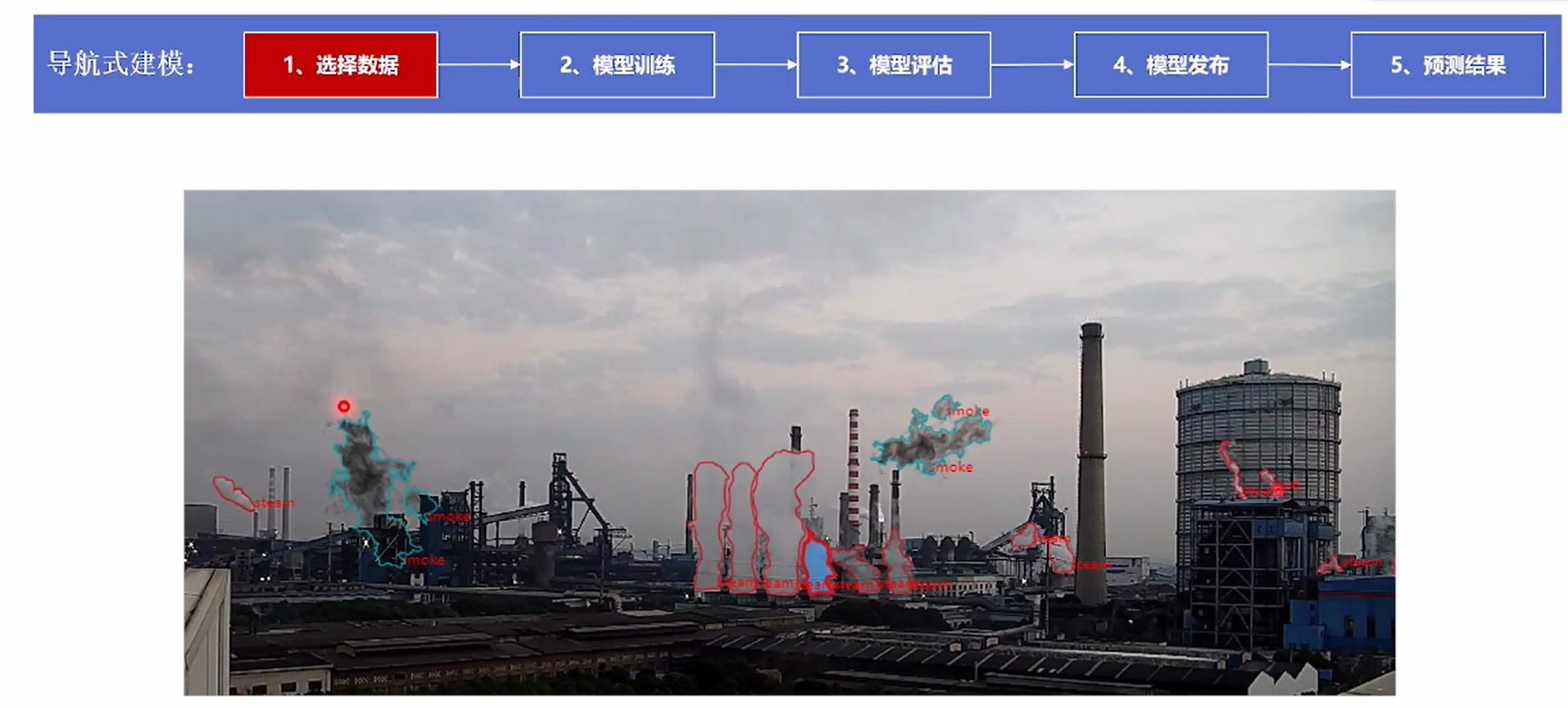
①数据集采集、数据选择:业务人员基于在工厂中采集的数据图片,使用样本库提供的在线标注功能,标注目标(黑烟),作为训练数据集。
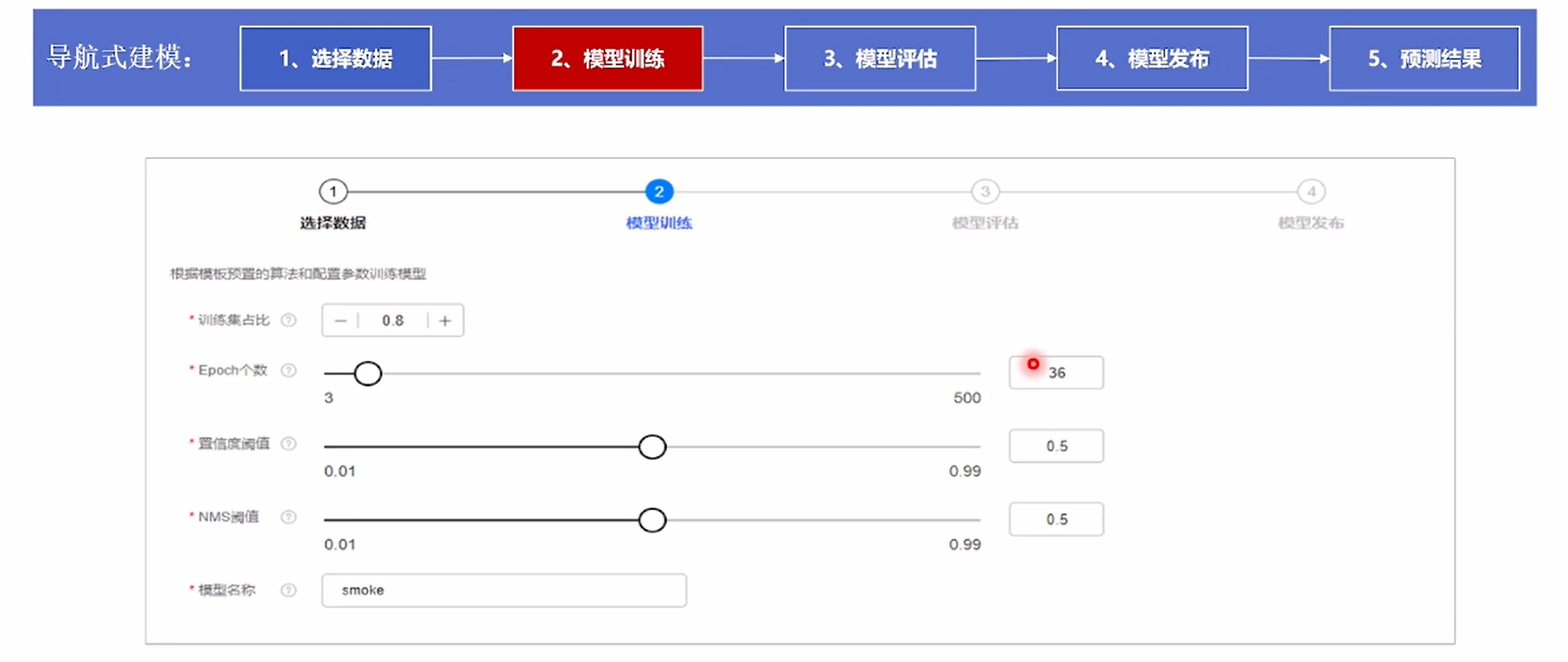
②模型训练:使用采集的数据集合,设置训练参数对模型进行训练。
③模型评估:根据平台提供的可视化界面对模型进行相应的评估。

④模型发布:配置相关资源参数即可完成发布。
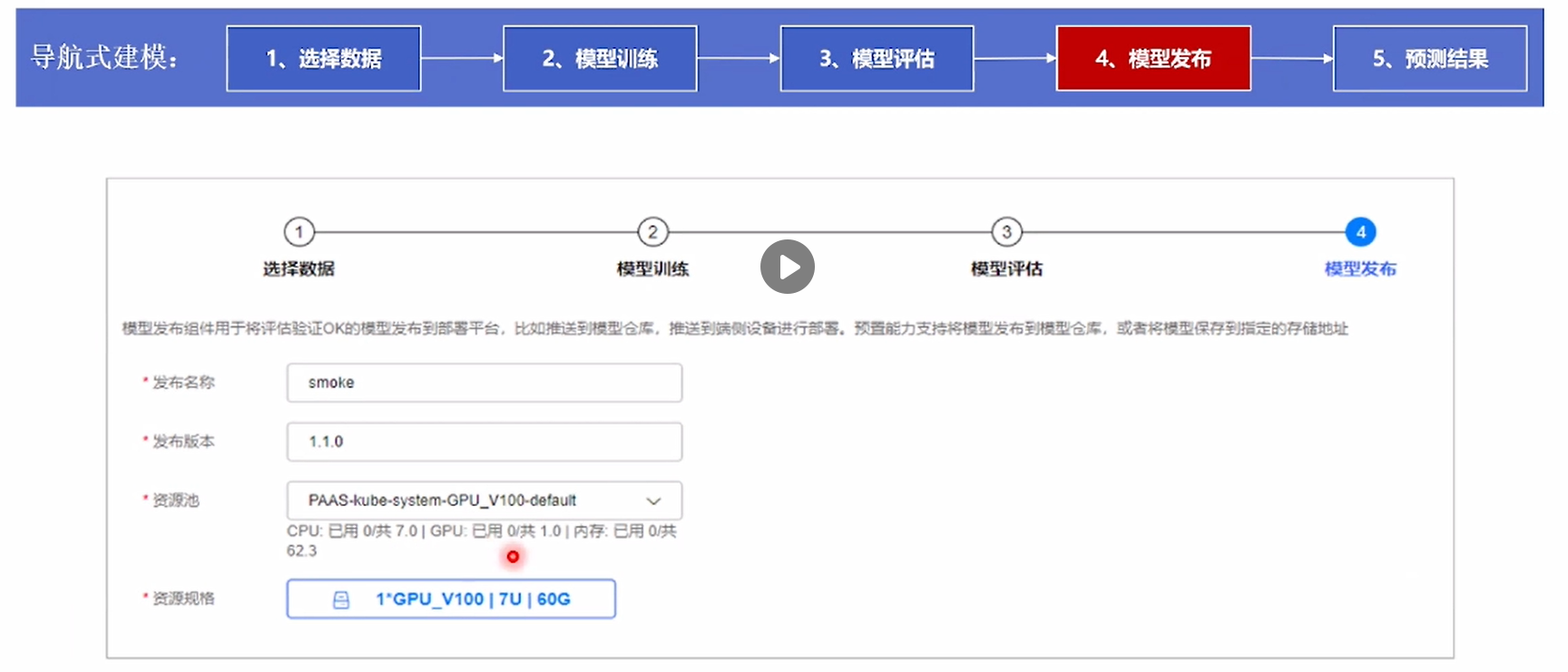
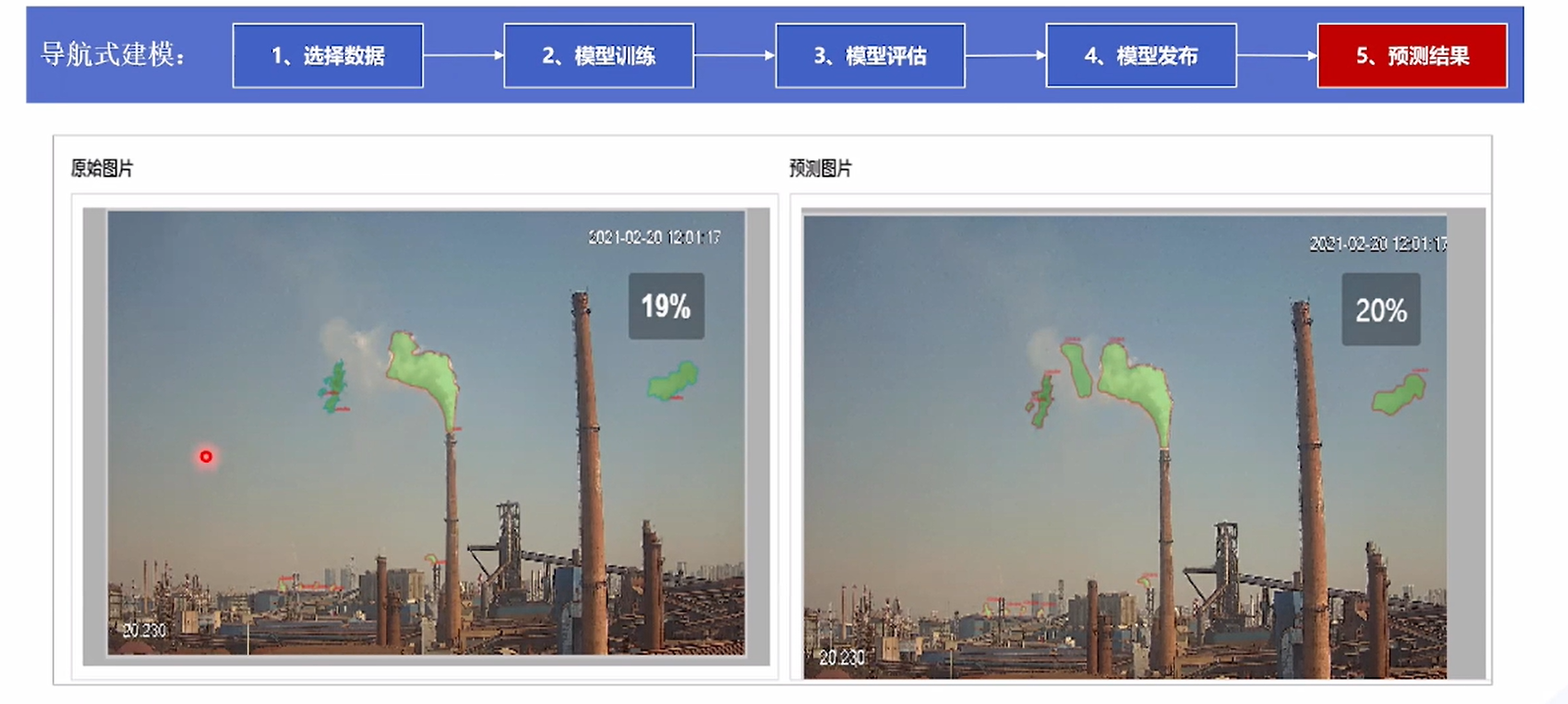
⑤预测结果:原始图片结果是19%,训练后的模型判断为20%
2.Model Foundry实例
2.1 实战案例:训练一个结构化分类模型
开发平台前端页面:

流程:创建实例——选择数据集——设置模型训练参数——设置模型评估参数——配置资源配置——训练模型——结果验证
以创建花卉结构分类模型为例:

①创建实例

②设置实例自定义参数,点击确定

③选择数据集,这里我们选择已有的iris数据集
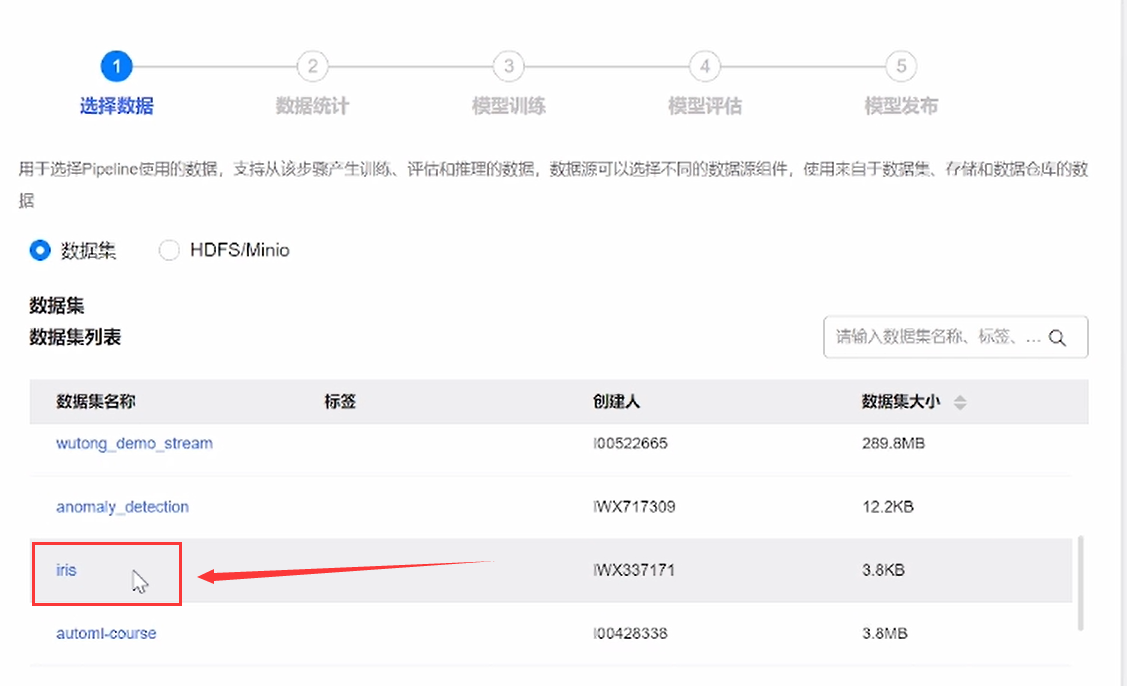
④此时显示已选数据iris,点击下一步

⑤设置模型训练参数

⑥设置模型评估参数,并选择验证用的数据集
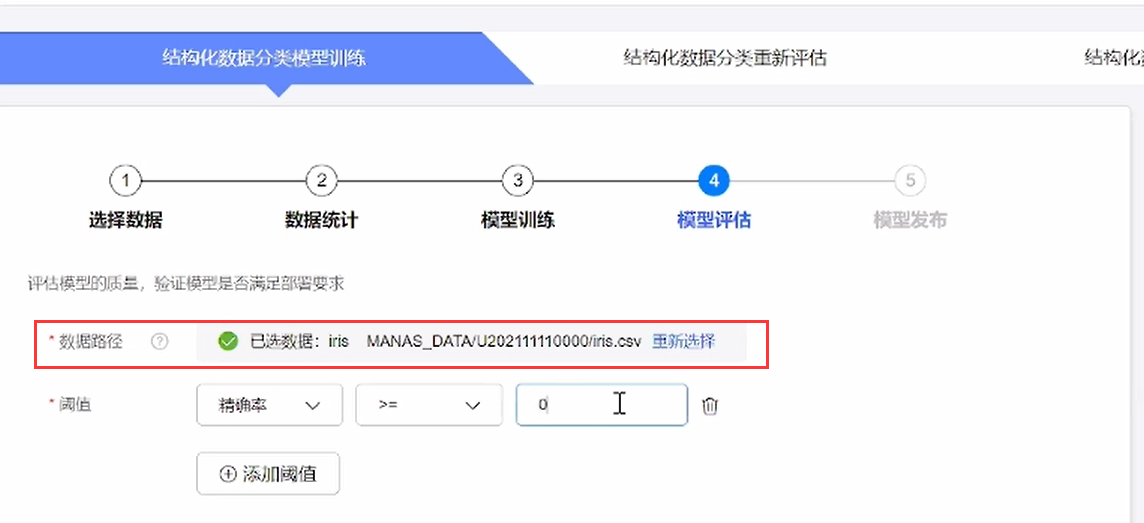
⑦配置发布信息,选择资源规格,即可开始训练
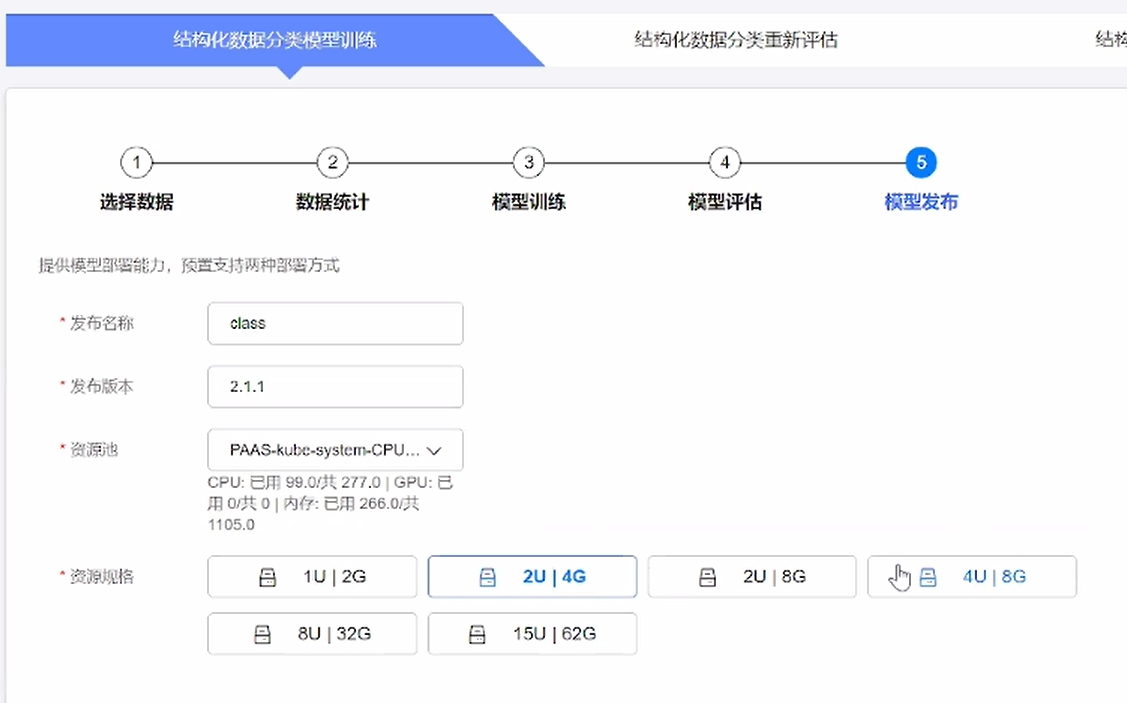
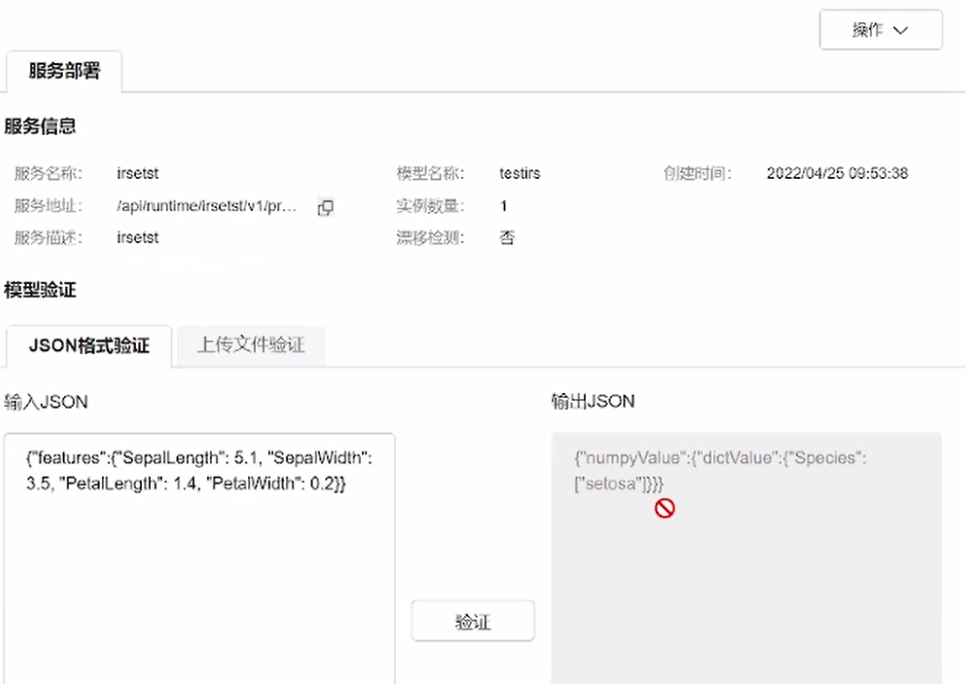
⑧结果验证——输入测试参数,即可得到通过AI训练模型得到的判断结果
2.2 开箱即用的服务:物体检测
- 运用已有模块快速检测并识别目标物体,部分支持业务示例:

2.3 开箱即用的服务:文字识别
- OCR(Optical Character Recognition)指光学字符识别,是对包含文本的图像进行分析处理,获取文字及版面信息的过程,服务支持多种业务场景(如:GTS业务、通用文档识别等)

总结
1.什么是GDE AI平台?
面向AI开发者的一站式开发平台,提供样本自动化标注、大规模分布式训练、自动化模型生成等能力;提供图像、文字、知识图谱、自然语言处理、预测性维护等多种AI领域通用服务,使企业能快速开发和构建AI业务,支持电信网络、制造等行业自动化、智能化解决方案实现。
2.使用Model Foundry模板进行AI建模优势
向导式、可视化进行AI建模,低建模门槛。
3.实战演练
- 华为云平台提供演练环境及丰富的演练案例,欢迎各位开发者体验。
- 开发者根据需要可自由选择网站学习华为云原生开发。
其他相关链接:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/649602
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

