
- 1人工智能大模型原理与应用实战:自动驾驶技术的飞跃
- 2普通二重积分计算的难点、易错点_二重积分圆开根号正负
- 3行业模板|DataEase教育行业大屏模板推荐
- 4计算机职称分类汇总,全国职称分类汇总表.doc
- 5Banana Pi BPI-M7 迷你尺寸开源硬件开发板采用瑞芯微RK3588芯片设计
- 6十、Linux多进程编程
- 7windows上连接MYSQL_windows 本地如何连接mysql服务端
- 8PY32F002/PY32F003/PY32F030入门笔记(1)
- 9git使用.gitignore失效_git 没有.gitignore
- 10一步步带你看SpringBoot(2.3.3版本)自动装配原理_spring boot 2.3.3.release 版本对应的依赖
深度理解GRUU-Net_gruu-net: integrated convolutional and gated recur
赞
踩
**
用于细胞分割的集成卷积和门控递归神经网络
GRUU-Net: Integrated convolutional and gated recurrent neural network for cell segmentation
**
近些年来,细胞分割的主要范式是使用卷积神经网络,较少使用递归神经网络。
本文的创新性网络结构是结合了卷积神经网络和门控递归神经网络。
虽说本篇论文的名字叫做GRUU-Net,但只是网络结构长的像U-Net(U-net网络结构参考网址https://blog.csdn.net/mieleizhi0522/article/details/82025509),附带论文原文翻译。
本篇论文的主要亮点:
- 网络结构中分为循环处理流和池化流,即CNNs的多尺度特征聚合和RNNs的迭代细化。
- CNN使用密集连接块,RNN使用门控递归单元(GRU)。
- 新的基于动量的局部损失函数优化算法。
- 数据扩充的框架(分布式数据扩充)。
摘要:
细胞分割在显微镜图像是一个常见的和具有挑战性的任务。近年来,深度神经网络在计算机视觉领域取得了显著的进展。分割的主要范式是使用卷积神经网络,较少使用递归神经网络。在这项工作中,我们提出了一种新的细胞分割的深度学习方法,它集成了卷积神经网络和门控递归神经网络在多个图像尺度上,以利用这两种网络的强度。为了提高训练的鲁棒性和改进分割,我们引入了一种新的焦损失函数。提出了一种集成神经网络优化训练的分布式方案。我们将我们提出的方法应用于挑战胶质母细胞瘤细胞核的数据,并与目前最先进的方法进行了定量比较。
网络框架结构介绍
在论文中介绍了一种新的深度神经网络,它结合了CNNs的多尺度特征聚合和RNNs的迭代细化两种模式。与之前的方法相比,本文的方法将卷积神经网络和递归神经网络结合起来,对不同图像尺度的特征进行聚类。通过在CNN部分使用密集连接块和在RNN部分使用门控递归单元(GRU),我们将可学习参数和特征张量的数量保持在最小。
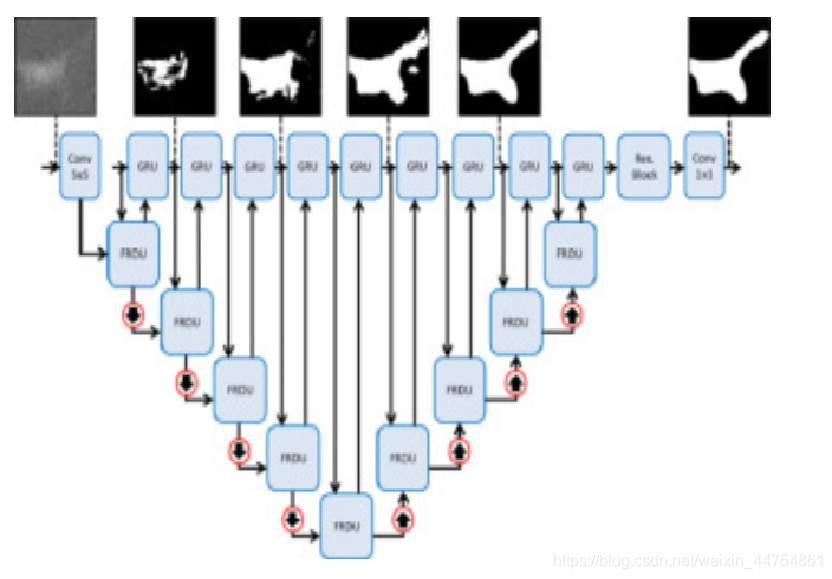
GRUU-Net具有如图所示的全卷积网络架构。

方法:
我们提出了一种新的细胞分割的DNN架构,它结合了门控递归单元(GRU)对特征图的迭代细化(Cho等,2014)和CNN等U-Net对多尺度特征的聚合。因此,我们称这个网络为GRUU-Net。利用归一化像素方向的焦交叉熵损失对网络进行训练,解决了类不平衡问题,实现了目标分离。此外,我们还利用分布式方案进行了大量的数据扩充。
GRUU-Net的体系结构,神经网络将循环处理流与池化流统一起来。两个流基于不同的范例上,循环处理流以全分辨率迭代地细化特征。池流流在一个大的接受域内提取高级特性。这两个流能够在每个解决级别交换信息。另外,为了最大化梯度流,网络中没有使用前馈网络,而是使用残差网络,这也是一个递归网络。

循环流(Recurrent stream)
GRUU-Net每个形式的重复流迭代细化最初提取的特征在全分辨率。我们使用GRU (Cho等人,2014年),并在池流的自底向上和自顶向下路径的所有尺度上展开它。首先介绍一下什么是GRU。
传统的GRU是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。GRU和LSTM在很多情况下实际表现上相差无几,相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
GRU的输入输出结构与普通的RNN是一样的。有一个当前的输入xt,和上一个节点传递下来的隐状态(hidden state) ht-1 ,这个隐状态包含了之前节点的相关信息。结合 和 xt-1,GRU会得到当前隐藏节点的输出yt和传递给下一个节点的隐状态 ht。
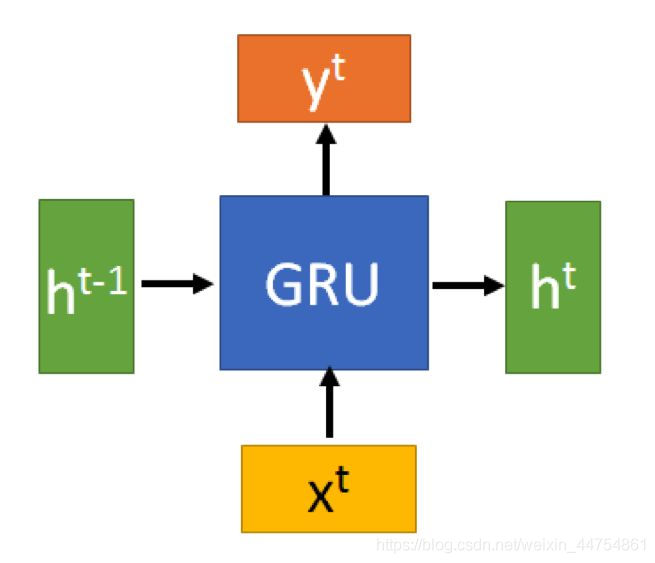
GRU最重要的步骤在于存在控制更新和控制重置的门控单元,重置门可以有选择的遗忘和记忆。
具体GRU知识详解可以参考网址:https://zhuanlan.zhihu.com/p/32481747
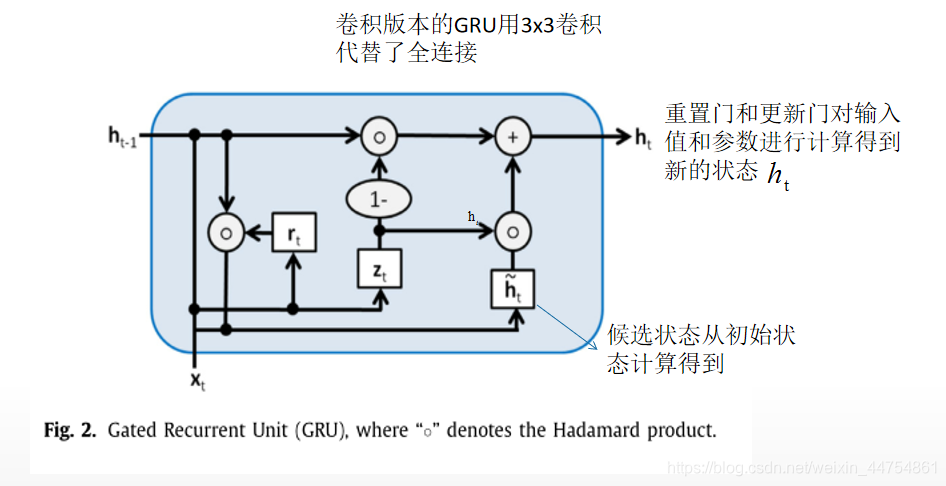
在本文中使用的是一个卷积版本的GRU,而不是一个标准的GRU,它在一个固定的图像大小上以完全连接的方式运行(Ballas et al., 2015)。因此,我们将标准GRU中的所有全连接层替换为3×3个卷积。如图。
迭代细化的效果如下:
池化流(Pooling stream)
池化流由池化块、全分辨率密集单元(FRDUs)和反池化块组成。为了增加接受域的大小和网络特征图的数量,我们加入了一个带有最大池块的自底向上路径。为了恢复原始分辨率并执行自顶向下推理,我们构造了自顶向下路径。在这条路径中,我们使用双线性插值而不是u形网中的置换卷积。Lin等人(2017b)的研究表明,特征提取的bot- tom向上和自顶向下路径对捕获图像的语义信息都很重要。自底向上和自顶向下的路径交替地由池/反池和FRDU块组成。FRDU块将来自循环流的信息与池化流结合起来,并将结果反馈给两个流。因此,FRDU能够集成卷积和门控递归神经网络。因此,高分辨率信息可以存储在循环流中,同时可以在多个分辨率的池流中提取高级特征。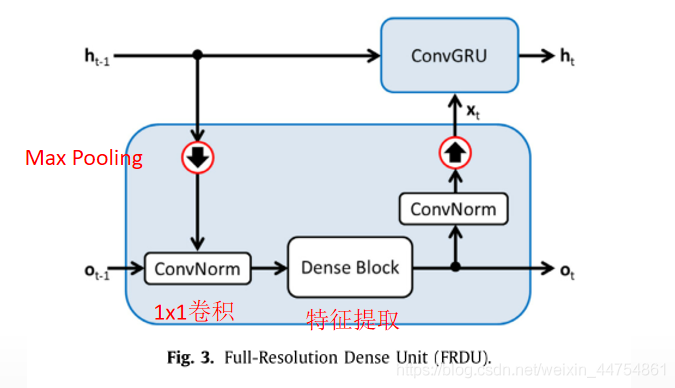
Max Pooling(向下箭头):将ht-1映射到Ot-1的分辨率,并将两个特征连接起来。
Dense Block:使用双线性插值会降低训练的稳定性,K层密集连接块进行特征提取,且在块中的每一层都有可以访问前一层的所有特征的映射,包括跳跃连接,参数的数量可以被减少。
Max Pooling(向上箭头):GRU的输入xt是通过对h的分辨率进行1×1的卷积和最近邻插值从o t中提取出来的。
关于GRUU-Net的层配置的详细信息如表1所示。除了池化和循环流,我们在第一层进行5×5的卷积来提取初始的特征图。已经证明,早期的层得益于过滤器的负激活(Paszke et al., 2016;Woll- mann等,2018a, b)。为了最小化参数的数量,同时保持负激活,我们对所有泄漏系数为0.2的非线性层使用漏整流线性单元(LReLU) (Maas et al., 2013)。所有的过滤器都是使用缩放的随机正态分布初始化。用反射填充代替零填充来提高训练的稳定性。为了计算最终预测,我们对循环流的输出x∈R m×n×g进行残差块和1×1卷积,然后用softmax函数计算像素级的前景和背景概率。我们的网络可以通过为对象边界使用额外的类来扩展。

数据扩充:
在扩充了数据集,不改变语义信息的情况下增加了训练数据的可变性。由于某些数据扩充步骤的计算开销较大,因此我们开发了一种分布式数据扩充方案。数据扩充通常在一台机器上完成(例如,谷歌Brain Team, 2019;Paszke等人,2019年;微软研究院,2019年)。当执行计算要求的增强步骤时,GPU不能被充分利用。相反,使用多个计算节点执行分布式数据扩充,这带来了额外的技术挑战。单个控制节点负责协调数据扩充节点(生成扩充的训练数据)和训练节点(形成实际的训练)。每个数据扩充节点启动sev- eral threads,以快速可读的二进制格式(TFRecord)生成训练数据块。文件通过共享文件系统传输到训练节点,并由多个CPU读线程读取。这些读取器不断地将数据传输到GPU内存中,以防止GPU处于空闲状态。我们使用单独的扩展节点来生成训练数据和验证数据。分布式系统的节点通过高吞吐量Infini带连接,数据存储在最新的ssd上,cpu为第四代Intel Xeon cpu。当使用在线多线程数据增强时,我们观察到GPU的平均利用率约为60%。通过我们的分布式数据扩展方案,我们能够将GPU的平均利用率提高到98%。我们注意到多线程和多机数据扩充的性能在很大程度上依赖于本地硬件基础设施。在我们的例子中,使用的分布式系统有一个微不足道的IO开销,这有利于分布式数据的扩展。
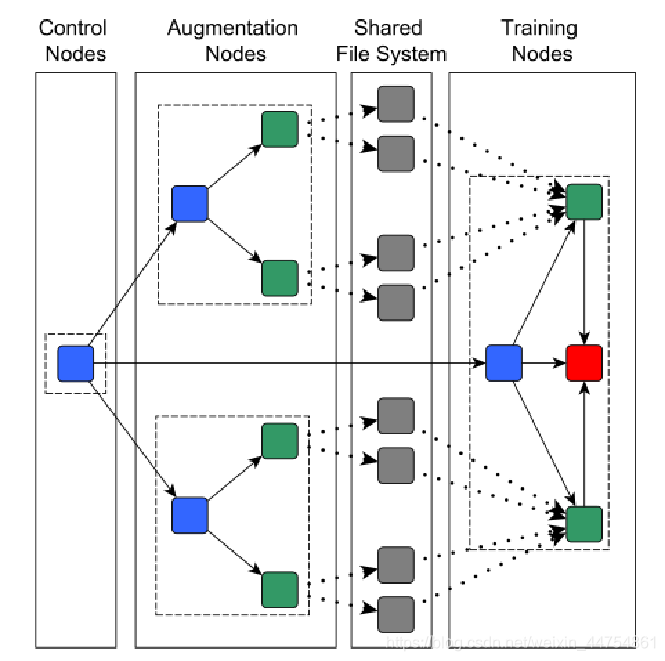
数据增强的消融方法:
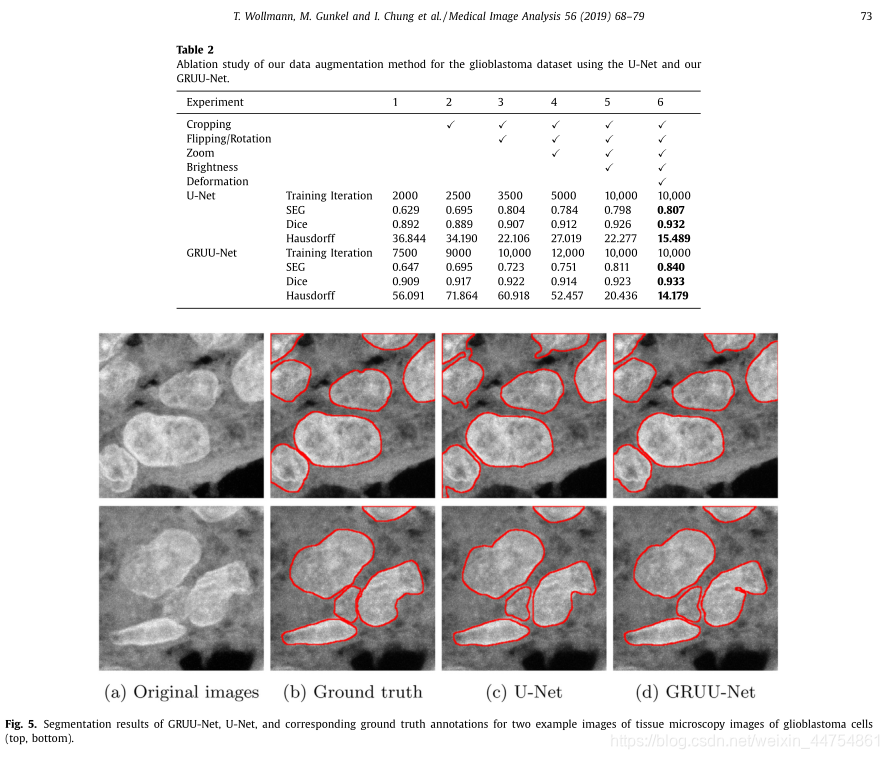
我们进行了消融研究,以调查我们的数据增强方案的有效性。因此,我们禁用了不同的扩展步骤,并评估了我们的方法的性能。我们使用了一个具有挑战性的数据集,包括50张胶质母细胞瘤细胞的最大强度投影组织图像(Baltissen等,2018)。图像大小为2048×2048像素的分辨率0.12μm×0.12μm,并获得使用旋转盘共聚焦显微镜和荧光染色,显示细胞核染色体端粒,centromers, PML蛋白和DNA。该数据集具有较高的图像噪声、强烈的异构强度变化、细胞聚类和重叠、较高的形状变化和较差的轮廓信息。两位专家使用ImageJ绘制了250多个细胞核的轮廓,从而手工确定了地物的真实性。数据集被分为25个训练,5个验证和20个测试图像。我们使用我们的分布式计算方案和不同的禁用扩展步骤来生成训练数据集。这些数据集用于我们GRUU-Net的培训。为了证明我们的CNNs数据扩充方案的泛化能力,我们还使用了一个标准的U- Net (Ronneberger et al., 2015)。通过检查(每10次0次迭代)是否达到平台期,这两个网络都进行了早期停止训练。并对测试图像进行了评价。实验结果如表2所示。可以看出,每一个增强步骤通常都会提高性能。然而,由于数据集的可变性显著增加,因此训练更加困难,一些增强步骤(如缩放)会降低一些度量的性能。GRUU-Net比U-Net产生更好的结果,但不是所有的烧蚀扩增步骤。使用所有数据扩展步骤(最后一列)可获得最佳结果。注意,最大的训练迭代次数随着增加步骤的数量而增加。正如预期的那样,由于训练数据集的可变性增加,在达到丢失的稳定期之前(在使用早期停止时),迭代的次数随着数据的增加而增加。随着训练数据集可变性的增加,泛化能力增强,网络不容易发生过拟合。我们的GRUU-Net与使用所有增强步骤的U-Net的样本图像和分割结果如图5所示。可见,GRUU- Net具有较好的分离效果,能较好地分离细胞核。
讨论和结论:
提出了一种集卷积神经网络和门控递归神经网络于一体的新型深度神经网络GRUU-Net。我们的方法结合了卷积的GRU和密集的沙漏形的U-Net,如CNN架构,用于迭代、多尺度的特征聚合和细化。与U-Net (1.9 M)和反褶积网络(1.1 M)相比,我们的网络具有更少的参数(0.7 M)。为了提高训练的鲁棒性和改进分割,我们引入了一种新的基于动量的归一化焦损优化器。我们的焦损失不仅提高了网络的分割结果,也提高了其他深度神经网络如U-Net的分割结果。使用少量示例图像对网络从头到尾进行训练。与之前的深度学习方法相比,我们的模型中的所有层都可以在全分辨率的公共内存上访问来自之前所有层的特性,这有可能改善信息共享和更好的梯度流。通过学习所有尺度上的公共特征表示,并因此在所有层之间引入跳跃连接,可以在使用有限数量的训练样本时减少过度拟合。提出了一种分布式的数据扩充方案,我们的方法已经在具有挑战性的胶质母细胞瘤细胞核组织显微镜图像上进行了综合评价。我们提出的方法优于以前的方法,并通过引入不同的概念来证明改进的效果。此外,我们使用了来自细胞追踪挑战的所有22个真实的2D和3D显微图像数据集来对我们的方法进行基准测试。我们的方法对22个数据集中的大多数数据集都取得了优异或有竞争力的结果,尽管我们只使用了一些示例图像来训练我们的网络,并且没有使用手工加权的交叉损耗。此外,我们的网络只包含较少的参数。另外,我们评估的经典分割方法不依赖于学习,可能直接针对目标数据集进行了优化,降低了泛化能力。我们将我们的方法应用于显微图像中目标的分割,这有可能改进后续任务的结果,如目标分类、跟踪和聚类。在未来的工作中,我们计划将我们的网络应用于其他真实的显微图像数据。此外,我们计划使用多尺度特征聚合和迭代细化的概念来进行目标检测。

