
- 1为什么今年的Java面试很难呢?和前两年相比,你有感觉吗?_java现在面试越来越难
- 2目前已知摄像头的内参矩阵和外参矩阵,已知摄像头画面宽高,某一物体在该画面中的位置坐标,以及该物体中心距离摄像头的距离,求该物体在现实世界中的坐标,用c++实现...
- 35. Windows安全 —— DNS域名解析及WEB服务_windows 域名解析
- 4正确解决java.lang.NoClassDefFoundException (未找到类定义错误)的有效解决方法_exception:java.lang.noclassdefound error thrown fr
- 5git difftool对比差异,避免推送不相关内容_git difftool 版本
- 6树莓派Pi 3B V1.2学习2——GPIO驱动_树莓派3bv1.2
- 7【数据结构】如何创建一棵红黑树(附动图讲解)_构造红黑树
- 8微信小程序开发学习笔记②组件和API_swiper-item :key
- 9Java后端架构技术面试汇总:基础+设计模式+MySQL+分布式+微服务等_java亿级项目架构设计与落地应
- 10FPGA实现的高效CIC滤波器:内插滤波器与数字信号多采样率处理_高效 数字滤波
经典数据集MNIST(手写数字数据集)详解与可视化
赞
踩
目录
MNIST数据集
MNIST (Modified National Institute of Standards and Technology) 数据集是大型手写数字数据库,常被用于训练各种图像处理系统。数据集由美国的 NIST 机构收集,后来被人们修改和标准化,成为了机器学习领域最广泛使用的数据集之一。
数据集包含 60,000 个训练样本和 10,000 个测试样本。每个样本都是一张 28x28 像素的灰度图像(只有一个通道),包含0 到 9 的一个数字。每张图像都经过中心化和规格化处理,数字的显示在图像居中的位置。
数据集构建的目标是让机器学习模型能够识别和分类手写数字。由于其规模适中且问题定义明确,MNIST 数据集也常被用作基准测试,用来比较不同的机器学习算法。
数据集下载
MNIST数据集提供了代码接口,可以非常方便地通过python进行本地下载。需要导入的库:
- # 数据集下载的库
- from torchvision.datasets import MNIST
-
- # 将MNIST数据可视化的库
- import matplotlib.pyplot as plt
-
- # 数据转换的方式
- from torchvision import transforms
可以通过MNIST语句进行本地的下载:
- # 下载数据集
- train_dataset_no = MNIST('./data/with_notrans',train=True,download=True)
- test_dataset_no = MNIST('./data/with_notrans',train=False,download=True)
代码中,'./data/with_notrans'是文件的下载路径,这里是相对路径(也可以输入绝对路径),表示下载到与运行文件同一级目录文件夹下的data文件夹中with_notrans文件夹,路径中的notrans表示不使用数据转换的方式赋值到变量train_dataset_no中,一般机器学习的任务在这一步会使用ToTensor()的方式将数据转换成张量的形式训练模型,后文会涉及,这里先获得原始的数据进行可视化。
train的参数为True表示下载60,000个训练样本,False表示下载10,000个测试样本;
第一次下载把download的参数设置为True,下载到本地后可以把download的参数设置为False,代码可以直接到路径里读取MNIST数据集。
运行时的提示:
官方描述的目录结构:
- # 解压前
- dataset
- ├── t10k-images-idx3-ubyte.gz #测试集图像压缩包(1648877 bytes)
- ├── t10k-labels-idx1-ubyte.gz #测试集标签压缩包(4542 bytes)
- ├── train-images-idx3-ubyte.gz #训练集图像压缩包(9912422 bytes)
- └── train-labels-idx1-ubyte.gz #训练集标签压缩包(28881 bytes)
-
- # 解压后
- dataset
- ├── t10k-images-idx3-ubyte #测试集图像数据
- ├── t10k-labels-idx1-ubyte #测试集标签数据
- ├── train-images-idx3-ubyte #训练集图像数据
- └── train-labels-idx1-ubyte #训练集标签数据
运行代码后我的文件夹情况:
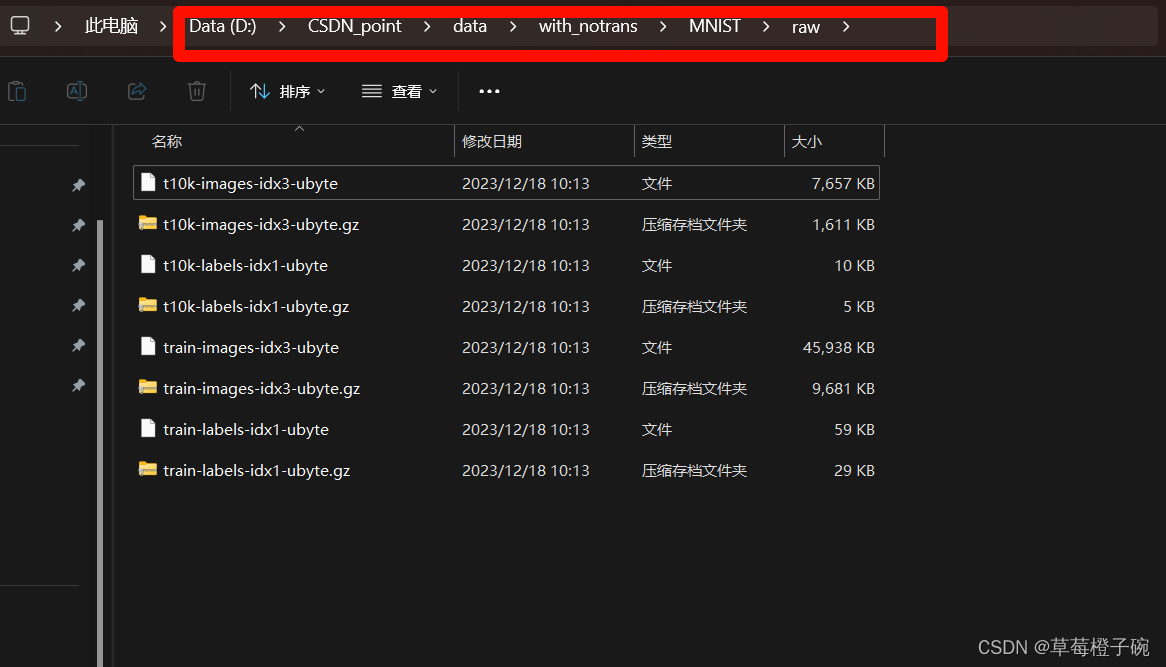 训练集和测试集的压缩包以及对应的解压文件都集中到同一个raw文件夹中,保存的路径可具体看我红色方框中的内容。
训练集和测试集的压缩包以及对应的解压文件都集中到同一个raw文件夹中,保存的路径可具体看我红色方框中的内容。
可视化
数据的类型
我们通过代码下载的MINST数据是以PIL.Image.Image类型的对象保存。PIL.Image.Image是 Python Imaging Library (PIL) 中的一个类,它是所有图像对象的基类。其中,PIL是一个强大的图像处理库,可以用于打开、操作和保存许多不同格式的图像。
直接打印train_dataset_no的数据,结果为
- Dataset MNIST
- Number of datapoints: 60000
- Root location: ./data/with_notrans
- Split: Train
可视化代码
显示单张图片及标签
再次读取MNIST数据集时,将download的参数设置为False:
- train_dataset_no = MNIST('./data/with_notrans',train=True,download=False)
- test_dataset_no = MNIST('./data/with_notrans',train=False,download=False)
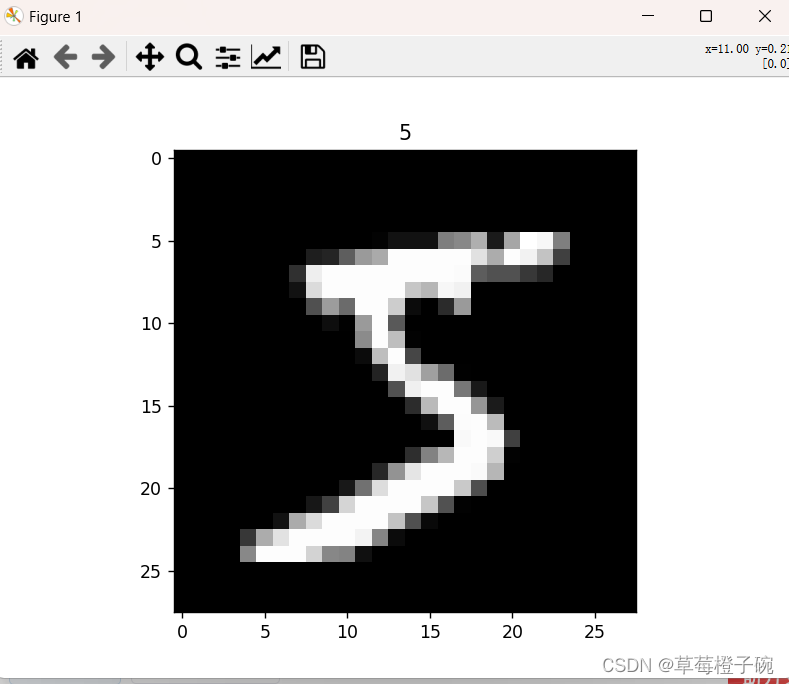
用pyplot显示单张的图片及对应的标签:
- # 显示单张图片
- img,label = train_dataset_no[0]
- print(img)
- plt.imshow(img, cmap='gray')
- plt.title(label)
- plt.show()
train_dataset_no含60000张图片及其对应标签,用train_dataset_no[0]获取第一张图片,返回两个值,img是对应的像素的PIL.Image.Image类型数据,label是img对应的标签,显示如下:
显示多张图片及标签
这里实现一次性显示8张图片,取train_dataset_no的前八张图片,使用plt.subplot()进行图片的分布安排:
- # 显示多张图片及标签
- for i in range(8):
- img,label=train_dataset_no[i]
- plt.subplot(2,4,i+1)
- plt.imshow(img,cmap='gray')
- plt.title(label)
- plt.show()

MNIST的预处理
以上部分都是对MNIST数据的下载和直接显示,所以我们上面定义的变量加上一个后缀_no,代表没有进行预处理,但是要进行模型的训练或者数据的其他处理都需要将这些数据转化成标准的图片张量形式,我们在下载数据集的时候可以通过transforms库提供的工具直接定义转换方式,首先要定义我们的对下载数据的转换方式:
- # 定义下载到 MNIST数据集的转换方式
- my_trans = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
具体的函数参数介绍可以参考我的上一篇博客,自定义数据集预处理的步骤涉及到了这方面的内容https://blog.csdn.net/weixin_57506268/article/details/135031759
然后在进行数据的下载时,将my_trans的方式送入transforms的参数里面:
- # 下载数据集
- train_dataset = MNIST('./data/with_trans',train=True,download=True,transform=my_trans)
- test_dataset = MNIST('./data/with_trans',train=False,download=True,transform=my_trans)
上面的代码将下载数据的保存路径更改了,也就是重新下载数据集,也可以在已经下载的数据集上进行变换:
- # 下载数据集,使用my_trans
- train_dataset = MNIST('./data/with_notrans',train=True,download=False,transform=my_trans)
- test_dataset = MNIST('./data/with_notrans',train=False,download=False,transform=my_trans)
得到的train_dataset数据:
- Dataset MNIST
- Number of datapoints: 60000
- Root location: ./data/with_trans
- Split: Train
- StandardTransform
- Transform: Compose(
- ToTensor()
- Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
- )
这时候数据已经是张量的形式,后续使用Databoarder方法可以直接获得指定训练或测试批次(batch)的生成器,使得迭代训练模型非常方便。
欢迎大家讨论交流~

