
热门标签
热门文章
- 1雷达恒虚警处理matlab_雷达信号处理基础之【恒虚警处理】
- 2AIGC提示词(Prompt)网站_aigc提示词网站
- 3华为OD机试真题-围棋的气-2023年OD统一考试(C卷)---python代码_华为题"围棋的气"python答案
- 4Ubuntu22.04 安装显卡驱动+CUDA_ubuntu22.04安装cuda
- 5android manifest.xml中的meta-data属性
- 6【六种方案】【idea】最全解决IntelliJ IDEA控制台输出中文乱码问题_idea控制台输出中文乱码怎么解决
- 7【研发日记】Matlab/Simulink技能解锁(八)——分布式仿真
- 8AIGC 010-CLIP第一个文本和图像对齐的大模型!
- 9裁员来临前有什么征兆,如何应对被裁员?_有预感被裁该准备些什么
- 10以gitee码云和vscode为例进行多人协作开发_vscode多人协作
当前位置: article > 正文
sklearn调包侠之K-Means
作者:小丑西瓜9 | 2024-06-07 02:53:53
赞
踩
cytoscape里面kmeans聚类怎么设置

K-Means算法
k-均值算法(K-Means算法)是一种典型的无监督机器学习算法,用来解决聚类问题。
算法流程
K-Means聚类首先随机确定 K 个初始点作为质心(这也是K-Means聚类的一个问题,这个K值的不合理选择会使得模型不适应和解释性差)。然后将数据集中的每个点分配到一个簇中, 具体来讲,就是为每个点找到距其最近的质心(这里算的为欧式距离,当然也可以使用其他距离), 并将其分配该质心所对应的簇;这一步完成之后,每个簇的质心更新为该簇所有点的平均值;重复上述过程直到数据集中的所有点都距离它所对应的质心最近时结束。
算法伪代码
- 创建 k 个点作为起始质心(随机选择)
- 当任意一个点的簇分配结果发生改变时(不改变时算法结束)
- 对数据集中的每个数据点
- 对每个质心
- 计算质心与数据点之间的距离
- 将数据点分配到距其最近的簇
- 对每一个簇, 计算簇中所有点的均值并将均值作为质心
实战
构造数据
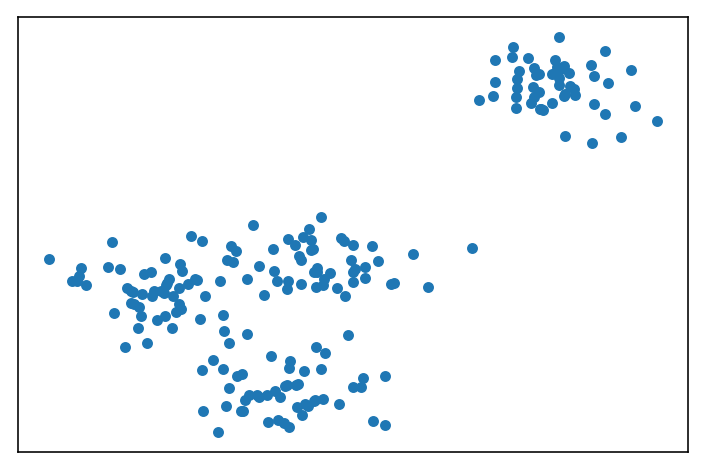
首先,我们用make_blobs创建数据集,如图所示。
- %matplotlib inline
- import matplotlib.pyplot as plt
- import numpy as np
- from sklearn.datasets import make_blobs
-
- X, y = make_blobs(n_samples=200,
- n_features=2,
- centers=4,
- cluster_std=1,
- center_box=(-10.0, 10.0),
- shuffle=True,
- random_state=1)
-
- plt.figure(figsize=(6,4), dpi=144)
- plt.xticks(())
- plt.yticks(())
- plt.scatter(X[:, 0], X[:, 1], s=20, marker='o')

训练模型与评估
该算法使用 sklearn.cluster 模块中的KMeans函数。
- from sklearn.cluster import KMeans
-
- n_clusters = 3
- kmean = KMeans(n_clusters=n_clusters)
- kmean.fit(X);
- print("kmean: k={}, cost={}".format(n_clusters, int(kmean.score(X))))
-
- # result
- # kmean: k=3, cost=-668
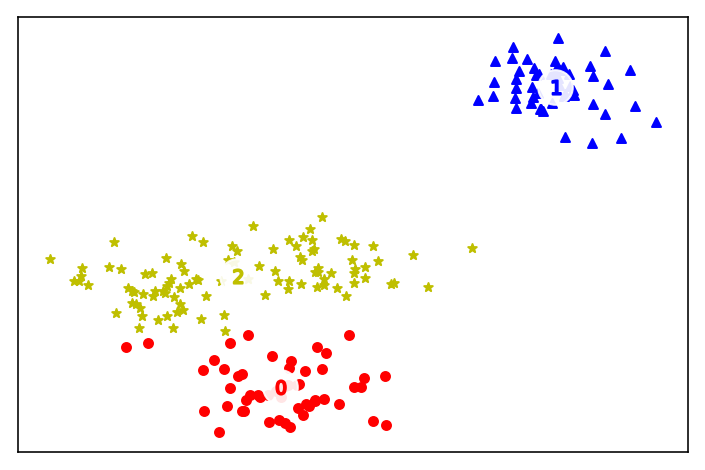
绘制聚类结果
最后,我们通过matplotlib绘制聚类的结果,如图所示:
- labels = kmean.labels_
- centers = kmean.cluster_centers_
- markers = ['o', '^', '*']
- colors = ['r', 'b', 'y']
-
- plt.figure(figsize=(6,4), dpi=144)
- plt.xticks(())
- plt.yticks(())
-
- # 画样本
- for c in range(n_clusters):
- cluster = X[labels == c]
- plt.scatter(cluster[:, 0], cluster[:, 1],
- marker=markers[c], s=20, c=colors[c])
- # 画出中心点
- plt.scatter(centers[:, 0], centers[:, 1],
- marker='o', c="white", alpha=0.9, s=300)
- for i, c in enumerate(centers):
- plt.scatter(c[0], c[1], marker='$%d$' % i, s=50, c=colors[i])
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/683642
推荐阅读
相关标签

