
- 1华为OD机试 - 最小调整顺序次数、特异性双端队列(Java & JS & Python)_最小调整次数
- 2【Elasticsearch 未授权访问漏洞复现】_elasticsearch未授权访问漏洞复现
- 3小米开源便签Notes-源码研究(1)-导出功能整体思路
- 4从零开始配深度学习服务器2023.04.01_从零开始配一个深度学习服务器
- 5欧科云链研究院:如何降低Web3风险,提升虚拟资产创新的安全合规
- 6TCP 和 UDP的区别
- 7基于chatgpt-on-wechat的微信个人对话机器人搭建
- 8python、C# 写企业微信机器人推送【图文消息】_python 企业微信机器人推送图文
- 9Python 分治法求最大最小元
- 10某城商银行生产容器云平台详细设计方案分享及经验总结_银行容器云平台项目计划书
操作系统习题集_操作系统引论题库
赞
踩
第一章 操作系统引论
1.多道批处理系统中引入了多道程序设计技术。 为充分提高各种资源的利用率,作业的类型最好是(D)。
A、短作业型
B、计算型,即其计算的工作量重于I/O的工作量
C、I/O型,即其I/O的工作量重于计算的工作量
D、计算型和I/O型均衡
解析:为充分利用各种资源,运行的程序应具备的条件应该是计算和输入/输出均衡的类型,这样资源利用更加充分。
2.批处理系统中最重要的程序是(C)。
A、数据库程序
B、文件操作程序
C、监督程序
D、计时程序
解析:为实现对作业的连续处理,需要先把一批作业以脱机方式输入到磁带上,并在系统中配上监督程序(Monitor),在它的控制下,使这批作业能一个接一个地连续处理。
其处理过程是:首先由监督程序将磁带上的第一个作业装入内存,并把运行控制权交给该作业;当该作业处理完成时,又把控制权交还给监督程序,再由监督程序把磁带上的第二个作业调入内存。计算机系统就这样自动地一个作业紧接一个作业地进行处理,直至磁带上的所有作业全部完成,这样便形成了早期的批处理系统。
虽然系统对作业的处理是成批进行的,但在内存中始终只保持一道作业,故称为单道批处理系统 。
监督程序:相当于早期操作系统,负责将磁盘中程序调入内存,以及将内存中的程序交给CPU处理。
3.在下面的选项中,(A)不属于操作系统提供给用户的可用资源。
A、中断机制
B、处理机
C、存储器
D、I/O设备
解析:中断(Interruption)也称外中断,指来自CPU执行指令以外的事件的发生,如设备发出的I/O结束中断,表示设备输入/输出处理已经完成,希望处理机能够向设备发下一个输入输出请求,同时让完成输入/输出后的程序继续运行。时钟中断,表示一个固定的时间片已到,让处理机处理计时、启动定时运行的任务等。这一类中断通常是与当前指令执行无关的事件,即它们与当前处理机运行的程序无关。也就是说中断是处于核心态下发生的,而非用户态。
处理机:处理机是最重要的资源,现代操作系统允许多个程序共享处理机,按照某种算法(分时、优先级)交替地使用处理机。
处理机管理包括以下几方面:
⑴ 进程控制
当用户作业要运行时,应为之建立一个或多个进程,并为它分配除处理机以外的所有资源,将它放入进程就绪队列。当进程运行完成时,立即撤消该进程,以便及时释放其所占有的资源。
⑵ 进程同步
所谓进程同步是指系统对并发执行的进程进行协调。有两种协调方式:
进程互斥方式 进程同步方式
方式1.是最基本的进程同步方式,是使诸进程以互斥方式访问临界资源。
方式2.对彼此相互合作去完成共同任务的诸进程,由同步机制对它们的执行次序加以协调。
⑶ 进程通信
对于相互合作的进程,在它们运行时,相互之间往往要交换一定的信息,这种进程间所进行的信息交换称为进程通信。
⑷ 调度
包括作业调度、进程调度两步。作业调度是按一定算法从后备队列中选出若干个作业,为它们分配资源,建立进程,使之成为就绪进程,并把它们按一定算法插入就绪队列。进程调度是指按一定算法,如最高优先算法,从进程就绪队列中选出一进程,把处理机分配给它,为该进程设置运行现场,并使之投入运行
存储器主要任务:
⑴ 为多道程序的并发运行提供良好环境。
⑵ 便于用户使用存储器。
⑶ 提高存储器的利用率。
⑷ 能从逻辑上来扩充内存。
存储器管理应具有以下功能:
⑴ 内存分配
多道程序能并发执行的首要条件是,各道程序都有自己的内存空间,因此,为每道程序分配内存空间是存储器管理的最基本功能。OS实现内存分配可采取以下两种方式:
静态分配方式 动态分配方式
⑵ 内存保护
为保证各道程序都能在自己的内存空间运行而互不干扰,要求每道程序在执行时能随时检查对内存的所有访问是否合法。
⑶ 地址映射
在多道程序的系统中,操作系统必须提供把程序地址空间中的逻辑地址转换为内存空间对应的物理地址的功能。
⑷ 内存扩充
由于物理内存的大小可能限制了大型作业或多个作业的并发执行,为了满足用户的要求并改善系统性能,必须对内存加以扩充。
设备管理(I/O)
主要任务有以下五个:
⑴ 完成用户提出的I/O请求。
⑵ 为用户分配I/O设备。
⑶ 提高CPU和I/O设备的利用率。
⑷ 提高I/O速度。
⑸ 方便用户使用I/O设备
为实现上述任务,设备管理应具有下述四种功能:
⑴ 缓冲管理
基本任务是管理好各种类型的缓冲区。几乎所有的外围设备与处理机交换信息时,都要利用缓冲区来缓和CPU与I/O设备间速度不匹配的矛盾,提高CPU与I/O设备、设备与设备间操作的并行程度,以提高CPU和I/O设备的利用率。
⑵ 设备分配
基本任务是根据用户的I/O请求和所采用的分配算法对设备进行分配,并将未获得所需设备的进程放进相应设备的等待队列。
⑶ 设备处理
基本任务是实现CPU和设备控制器之间的通信,即启动指定的I/O设备,完成用户规定的I/O操作,并对由设备发来的中断请求进行及时响应,根据中断类型进行相应的处理。
⑷ 虚拟设备
系统可通过某种技术使该设备成为能被多个用户共享的设备,以提高设备利用率及加速程序的执行过程。可使每个用户都感觉到自己在独占该设备。
4.分时系统响应时间与(D)有关。
A、每个应用进程分配的时间片长度
B、进程大小
C、等待队列中的就绪进程数目
D、等待队列中的就绪进程数目和时间片长度
解析:分时系统的相应时间是指用户从终端发出一个命令到系统处理完这个命令并做出回答所需要的时间。这个时间受时间片长度、终端用户个数、命令本身功能、硬件特性、主存与辅存的交换速度等影响。
5.操作系统在计算机系统中处于( B)的位置。
A、计算机硬件和软件之间
B、计算机硬件和用户之间
C、处理机和用户程序之间
D、外部设备与处理机之间
解析: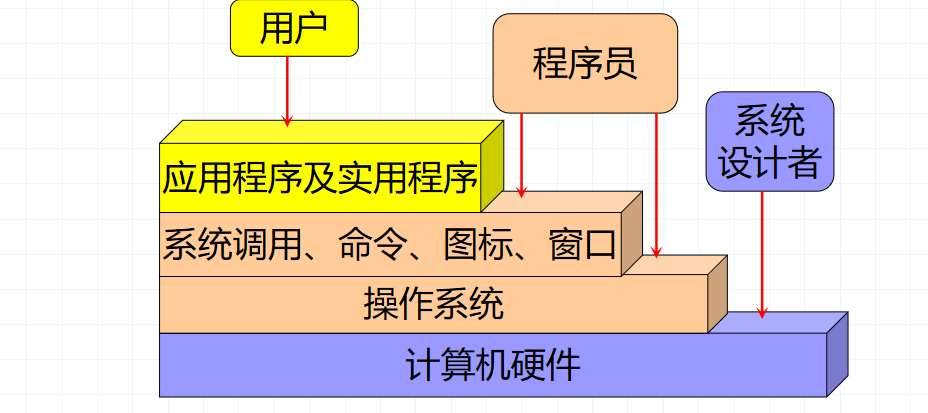
由图可见操作系统连接着用户和硬件。
6.为使操作系统具有很好的可扩充性,(B)是一种可执行的方法。
A、简化设计
B、模块化设计
C、采用虚拟技术
D、采用分布式技术
解析:模块化结构OS:基于20世纪60年代出现的一种结构化程序设计技术开发的。
模块由众多服务过程(模块接口)组成,可以随意调用其他模块中的服务过程。实现了可扩充性
优点:具有一定灵活性,在运行中的高效率。
缺点:
功能划分和模块接口难保正确和合理。
模块之间的依赖关系(功能调用关系)复杂(调用深度和方向),降低了模块之间的相对独立性--不利于修改。
7.通常在分时系统中运行的作业称为(C)。
A、前台作业
B、后台作业
C、终端型作业
D、批量型作业
解析:终端型作业是在 多道程序系统 中,一个作业被提交后,必须经过 处理机调度 后方能获得处理机。
通常在分时系统中运行的作业称为终端型作业。
8.在操作系统中,(D)部分属于微内核。
A、输入输出井的管理程序,及作业调度软件
B、用户命令解释程序
C、磁盘文件目录管理软件
D、进程通信服务例程
解析:把操作系统分成若干分别完成一组特定功能的服务进程,等待客户提出请求;而系统内核只实现操作系统的基本功能(如:虚拟存储、消息传递),微内核所提供的功能,通常都是一些最基本的功能,如进程管理、存储器管理、进程间通信、 低级I/O功能。
9.实时操作系统必须在(B)的时间内响应一个新任务。
A、一个机器时间
B、被控对象规定
C、任意周期
D、时间片
解析:实时系统要求能实时处理外部事件,即在规定的时间内完成对外部事件的处理。
10.批处理系统的主要缺点是(C)。
A、CPU利用率低
B、不能并发执行
C、缺少交互性
D、以上都不是
解析:批处理系统中,作业执行时用户无法干预其运行,只能通过事先编制作业控制说明书来间接干预,缺少交互能力,也因此才有了分时系统的出现。
11.操作系统提供给程序员的接口是(B )。
A、进程
B、系统调用
C、库函数
D、B和C
解析:操作系统接口主要有命令接口和程序接口(也称系统调用)。库函数是高级语言中提供的与系统调用对应的函数(也有些库函数与系统调用无关),目的是隐藏“访管”指令的细节,使系统调用更为方便、抽象。但是,库函数属于用户程序而非系统调用,是系统调用的上层。为了让用户方便、快捷、可靠地操纵计算机硬件并运行自己的程序,操作系统还提供了用户接口。操作系统提供的接口主要分为两类:一类是命令接口,用户利用这些操作命令来组织和控制作业的执行;另一类是程序接口,编程人员可以使用它们来请求操作系统服务。操作系统为编程人员提供的接口是程序接口,即系统调用。
12.对于普通用户而言,OS的(B )是最重要。
A、开放性
B、方便性
C、有效性
D、可扩充性
解析:操作系统的目标 :方便性(用户的观点):提供良好的、一致的用户接口,弥补硬件系统的类型和数量差别,使计算机更容易使用。
有效性(系统管理人员的观点):提高资源的利用率:使CPU、I/O设备和存储空间得到有效利用;提高系统的吞吐量:管理和分配硬件、软件资源,合理地组织计算机的工作流程。
可扩充性:OS应采用层次化结构,以便于增加新的功能层次和模块,并能修改老的功能层次和模块。
开放性:遵循标准规范,方便地实现互连,实现应用的可移植性和互操作性。
但是对用户而言方便是最重要的。
13.与计算机硬件关系最密切的软件是(D )。
A、编译程序
B、数据库管理系统
C、游戏程序
D、OS
解析: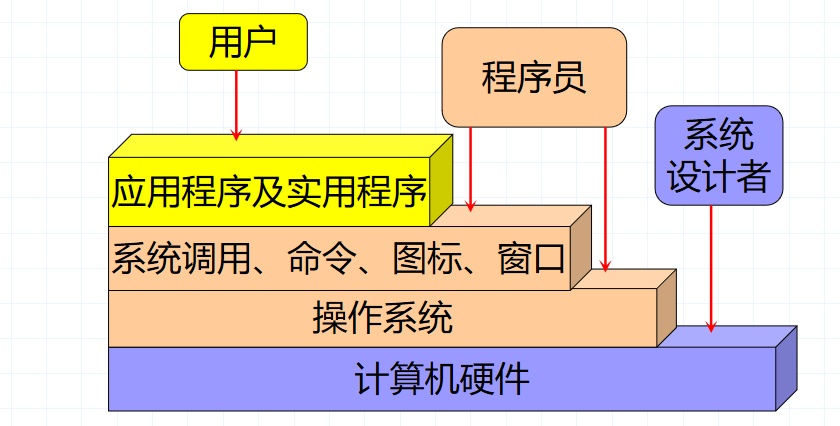
由此可见。硬件之上即是OS(操作系统)
14.系统调用是由操作系统提供的内部调用,它(B)。
A、直接通过键盘交互方式使用
B、只能通过用户程序间接使用
C、是命令接口中的命令
D、与系统的命令一样
解析:系统调用是操作系统为应用程序使用内核功能所提供的接口。程序接口由一组系统调用(也称广义指令)组成。用户通过在程序中使用这些系统调用来请求操作系统为其提供服务,如使用各种外部设备、申请分配和回收内存及其他各种要求。
当前最为流行的是图形用户界面(GUI),即图形接口。GUI最终是通过调用程序接口实现的,用户通过鼠标和键盘在图形界面上单击或使用快捷键,就能很方便地使用操作系统。严格来说,图形接口不是操作系统的一部分,但图形接口所调用的系统调用命令是操作系统的一部分。
命令接口:使用命令接口进行作业控制的主要方式有两种,即联机控制方式和脱机控制方式。按作业控制方式的不同,可将命令接口分为联机命令接口和脱机命令接口。
联机命令接口又称交互式命令接口,适用于分时或实时系统的接口。它由一组键盘操作命令组成。用户通过控制台或终端输入操作命令,向系统提出各种服务要求。用户每输入一条命令,控制权就转给操作系统的命令解释程序,然后由命令解释程序解释并执行输入的命令,完成指定的功能。之后,控制权转回控制台或终端,此时用户又可输入下一条命令。联机命令接口可以这
样理解:“雇主”说一句话,“工人”做一件事,并做出反馈,这就强调了交互性。
脱机命令接口又称批处理命令接口,适用于批处理系统,它由一组作业控制命令组成。脱机用户不能直接干预作业的运行,而应事先用相应的作业控制命令写成一份作业操作说明书,连同作业一起提交给系统。系统调度到该作业时,由系统中的命令解释程序逐条解释执行作业说明书上的命令,从而间接地控制作业的运行。脱机命令接口可以这样理解:“雇主”把要“工人”做的事写在清单上,“工人”按照清单命令逐条完成这些事,这就是批处理。
15.在下列性质中,(B)不是分时系统的特征。待定
A、交互性
B、同时性
C、及时性
D、独立性
解析:同时性:同时性也称多路性,指允许多个终端用户同时使用一台计算机,即一台计算机与若干台终端相连接,终端上的这些用户可以同时或基本同时使用计算机。
交互性:用户能够方便地与系统进行人机对话,即用户通过终端采用人机对话的方式直接控制程序运行,与同程序进行交互。
独立性:系统中多个用户可以彼此独立地进行操作,互不干扰,单个用户感觉不到别人也在使用这台计算机,好像只有自己单独使用这台计算机一样。
及时性:用户请求能在很短时间内获得响应。分时系统采用时间片轮转方式使一台计算机同时为多个终端服务,使用户能够对系统的及时响应感到满意。
16.下列选项中,(A)不属于操作系统提供给用户的可用资源。
A、中断机制
B、处理机
C、存储器
D、I/O设备
解析:3题
17.批处理操作系统的目的是(B)
A、提高系统与用户的交互性
B、提高系统资源的利用率
C、降低用户作业的周转时间
D、提高系统的可靠性
解析:为了解决人机矛盾及CPU和I/O设备之间速度不匹配的矛盾,出现了批处理系统。它按发展历程又分为单道批处理系统、多道批处理系统(多道程序设计技术出现以后)。
批处理操作系统的目的是为了提高CPU的利用率。
批处理操作系统由操作系统控制它们自动运行。这种采用批量处理作业技术的操作系统称为批处理操作系统。
批处理操作系统分为单道批处理系统和多道批处理系统。批处理操作系统不具有交互性,它是为了提高CPU的利用率而提出的一种操作系统。
18.下列选项中,(D)不是操作系统关心的主要问题。
A、管理计算机裸机
B、设计、提供用户程序与计算机硬件系统的界面
C、管理计算机系统资源
D、高级程序设计语言的编译器
解析:操作系统有两个重要的功能:一是通过资源管理,提高计算机系统的效率;二是改善人机界面向用户提供友好的工作环境。
19.实时操作系统追求的目标是(C)。
A、高吞吐率
B、充分利用内存
C、快速响应
D、减少系统开销
解析:实时系统(Real-Time System)是指系统能及时(或即时)响应外部事件的请求,在规定的时间内完成对该事件的处理,并控制所有实时任务协调一致地运行。为了能在某个时间限制内完成某些紧急任务而不需要时间片排队,诞生了实时操作系统。这里的时间限制可以分为两种情况:若某个动作必须绝对地在规定的时刻(或规定的时间范围)发生,则称为硬实时系统,如飞行器的飞行自动控制系统,这类系统必须提供绝对保证,让某个特定的动作在规定的时间内完成。若能够接受偶尔违反时间规定且不会引起任何永久性的损害,则
称为软实时系统,如飞机订票系统、银行管理系统。
在实时操作系统的控制下,计算机系统接收到外部信号后及时进行处理,并在严格的时限内处理完接收的事件。实时操作系统的主要特点是及时性和可靠性。
20.如用户要利用计算机系统直接调试和控制程序的执行,则应在其上配置(C)操作系统。
A、批处理
B、实时
C、分时
D、单用户
解析:分时系统是指在一台主机上连接多个带有显示器和键盘的终端,同时允许多个用户通过自己的键盘,以交互的方式使用计算机,共享主机中的资源。 "分时"的含义分时是指多个用户分享使用同一台计算机;多个程序分时共享硬件和软件资源,推动多道批处理系统形成和发展的动力是提高资源利用率和系统吞吐量,推动分时系统形成和发展的主要动力是用户的需要:
21.实时操作系统必须在(B)的时间内响应一个新任务。
A、一个机器周期
B、被控对象规定
C、任一周期
D、时间片
解析:9题
22.(C)操作系统允许在一台主机上同时连接多台终端,多个用户可以通过各自的终端同时交互地使用计算机。
A、网络
B、分布式
C、分时
D、实时
解析:20题
23.如果分时操作系统的时间片一定,那么(B),则响应时间越长。
A、用户数越少
B、用户数越多
C、内存越少
D、内存越多
解析:分时系统中,当时间片固定时,用户数越多,每个用户分到的时间片就越少,响应时间自然就变长,注意,分时系统的响应时间T的比例关系可表达为T≈QN,其中Q是时间片,而N是用户数。
24.操作系统的基本类型主要有(B)。
A、批处理系统、分时系统及多任务系统
B、实时操作系统、批处理操作系统及分时操作系统
C、单用户系统、多用户系统及批处理系统
D、实时系统、分时系统和多用户系统
解析:操作系统的基本类型主要有批处理系统、分时系统和实时系统。
25.(C)操作系统允许在一台主机上同时连接多台终端,多个用户可以通过各自的终端同时交互地使用计算机。
A、网络
B、分布式
C、分时
D、实时
解析:22题
分布式具有各个计算机间相互通讯,无主从关系;
分布式系统资源为所有用户共享;
分布式系统中若干个计算机可相互协作共同完成一项任务。
26.操作系统的基本功能包括( 全选)。
A、处理机管理功能
B、存储器管理功能
C、I/O设备管理功能
D、文件管理功能
解析:操作系统的主要功能 :处理机管理功能 、存储器管理功能、设备管理功能、文件系统管理、用户接口等
27.操作系统的基本特性是指(全选)。
A、并发
B、共享
C、虚拟
D、异步性
解析:操作系统的基本特性 :并发、共享、虚拟、异步性其中最基本特性是并发与共享。
28.各种类型的操作系统各有所长,它们追求的设计目标也不同,下述说法正确的是(全选)。
A、多道批处理系统是为了提高系统的资源利用率
B、分时系统允许用户直接与计算机系统交互
C、实时系统首先要考虑实时性和可靠性
D、网络操作系统必须实现计算机之间的通信及资源共享
E、分布式操作系统要让多台计算机协作完成一个共同的任务
29.数据库管理程序需要调用操作系统程序,操作系统程序的实现也需要数据库系统的支持。错误
解析:数据库管理程序需要调用操作系统程序,但是操作系统程序的实现不需要数据库系统的支持
30.批处理系统提高了系统各种资源的利用率和系统吞吐率,因而缩短了作业的周转时间。这种描述对吗?错误
第二章 进程的描述与控制
1.由于等待某些事件发生,进程主动进入阻塞状态。 正确
2.设与某资源关联的信号量初值为3,当前值为-1。若M表示该资源的可用个数,N表示等待该资源的进程数,则M、N分别是( A)。
A、0、1
B、1、2
C、2、0
D、1、0
解析:信号量的初值为3,说明有3个这样的资源可供使用。但其当前值为-1,表示有1个进程正在等待该资源。即M=0,N=1。信号量表示资源的可用个数。
根据信号量的物理含义:S.value>0时表示有S.value个资源可用;S.value==0表示无资源可用;S.value<0则|S.value|表示等待队列中的进程个数。
3.当已有进程进入自己对应于某临界资源的临界区时,所有企图进入该临界资源所对应临界区的进程必须等待,这称之为( C)。
A、空闲让进
B、让权等待
C、忙则等待
D、有限等待
解析:空闲让进:当没有进程处于临界区时,可以允许一个请求进入临界区的进程立即进入自己的临界区。
忙则等待:当已有进程进入其临界区时,其他试图进入临界区的进程必须等待。
有限等待:对要求访问临界资源的进程,应该保证能在有限时间内进入自己的临界区。
让权等待:当进程不能进入自己的临界区时,应释放处理机。
4.下列关于线程的叙述中,正确的是( B)。
A、每个线程有自己独立的地址空间
B、线程可以独立执行
C、进程只能包含一个线程
D、线程之间的通信必须使用系统调用函数
解析:每个进程都有自己的地址空间,但线程没有自己独立的地址空间,而是运行在一个进程里的所有线程共享该进程的整个虚拟地址空间。
线程可以包含CPU现场,并且可以独立执行程序。
线程之间通信方式:
1.是通过共享变量,线程之间通过该变量进行协作通信;
2.通过队列(本质上也是线程间共享同一块内存)来实现消费者和生产者的模式来进行通信;
5.进程之间的同步,主要源于进程之间的资源竞争,是指对多个相关进程在执行次序上的协调。错误
解析:进程同步是指对多个相关进程在执行次序上进行协调。主要源于进程合作
6.用户级线程执行时,同一进程不同线程的切换不需要内核支持。正确

7.在引入线程的系统中,进程仍是资源分配和调度的基本单位。正确
解析:进程表示单个运行活动集的计算机程序,是系统的资源分配和调度的基本单元,是操作系统结构的基础。
8.下列选项中不属于进程高级通信的是(D )。
A、管道通信
B、共享存储器系统
C、消息传递系统
D、信号量机制
解析:进程通信是指在进程间传输数据(交换信息)。 进程通信根据交换信息量的多少和效率的高低,分为低级通信(只能传递状态和整数值)和高级通信(提高信号通信的效率,传递大量数据,减轻程序编制的复杂度)。其中高级进程通信分为三种方式:共享内存模式、消息传递模式、共享文件模式
进程间通信的方式很多,包括:
- 信号(signal )通信机制;
- 信号量及其原语操作(PV、读写锁、管程)控制的共享存储区(shared memory )通信机制;
- 管道(pipeline)提供的共享文件(shared file)通信机制;
- 信箱和发信/ 收信原语的消息传递(message passing )通信机制。
其中前两种通信方式由于交换的信息量少且效率低下,故称为低级通信机制,相应地可把发信号/ 收信号及PV之类操作称为低级通信原语,仅适用于集中式操作系统。消息传递机制属于高级通信机制,共享文件通信机制是消息传递机制的变种,这两种通信机制,既适用于集中式操作系统,又适用于分布式操作系统。
共享存储系统(有的地方称作共享内存区)、消息传递系统(有的地方称作消息队列)、管道。
进程通信博客:https://www.cnblogs.com/youngforever/p/3250270.html
9.进程的运行具有异步性,因此进程执行的速度不能由进程自己控制。正确
10.在多个用户级线程对应一个内核支持线程的模型中,当一个多线程进程中的某个线程被阻塞后,( B)。
A、该进程的其他线程仍可继续运行
B、整个进程都将阻塞
C、该阻塞线程将被撤销
D、该阻塞线程将永远不可能再执行
解析:在同时支持用户级线程和内核级线程的系统中,由几个用户级线程映射到几个内核级线程的问题引出了“多线程模型”问题。
多线程模型分为:多对一模型、一对一模型和多对多模型。
多对一模型
多个用户级线程映射到一个内核级线程。每个用户进程只对应一个内核级线程。
优点:用户级线程的切换在用户空间即可完成,不需要切换到核心态,线程管理的系统开销小,效率高。
缺点:当一个用户级线程被阻塞后,整个进程都会被阻塞,并发度不高。多个线程不可在多核处理机上并行运行(因为此时只有一个内核级线程)。
一对一模型
一个用户级线程映射到一个内核级线程。每个用户进程有着与用户级线程同数量的内核级线程。
优点:当一个用户级线程被阻塞后,别的用户级线程还可以继续执行,并发能力强。多线程可在多核处理机上并行执行。
缺点:一个用户进程会占用多个内核级线程,而内核级线程的切换由操作系统内核完成,需要切换到核心态,因此线程管理成本高、开销大。
多对多模型
n个用户级线程映射到m个内核级线程 ( n >= m )。每个用户进程对应m个内核级线程。
这种模型克服了多对一模型并发度不高的缺点,又克服了一对一模型中一个用户进程占用太多内核级线程,开销太大的缺点,是上述两种模型的折中方案。
11.信号量是解决进程同步与互斥问题的唯一手段。错误
解析:信号量机制是一种可以实现进程互斥、同步的有效方法。非唯一
12.(D )不是在创建进程中所完成的工作。
A、为被创建进程建立一个PCB
B、获取初始状态参数填入PCB
C、把PCB分别插入就绪队列和进程家族中
D、为进程调度CPU使用权
解析:创建进程:
- 申请空白PCB (2) 为新进程分配资源 (3) 初始化进程控制块 (4) 将新进程插入就绪队列
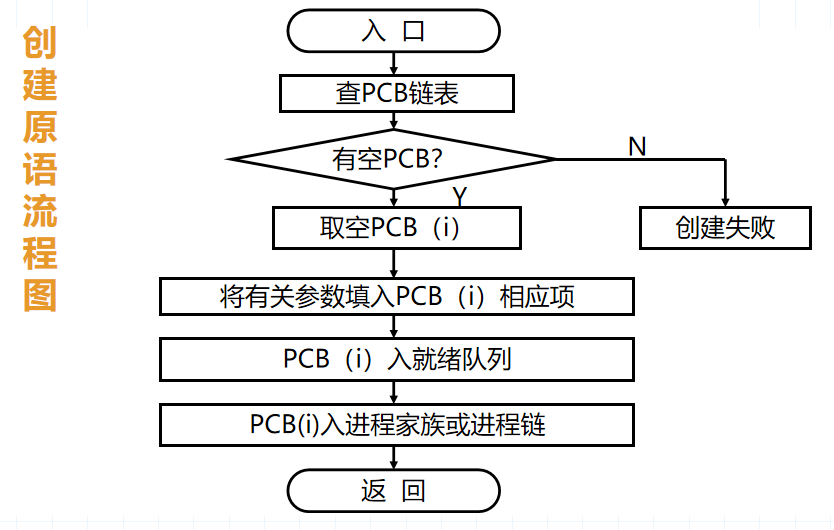
13.进程和程序最根本的区别是( B)
A、对资源的占有类型和数量
B、进程是动态的,程序是静态的
C、是否能够并发地在处理机上运行
D、进程规模小,程序规模较大
14.(A )操作不是wait操作可完成的。
A、为进程分配处理机
B、使信号量的值变小
C、可用于进程的同步
D、使进程进入阻塞状态
解析:P操作分配的是我们申请的资源,并不是处理机
PV 操作改变信号量的值,信号量是实现进程同步与互斥的机制,所以PV操作可以实现进程同步与互斥。
信号量是最早出现的用来解决进程同步与互斥问题的机制。
信号量(Saphore)值表示相应资源的使用情况。信号量S>=0时,S表示可用资源的数量。**执行一次P操作意味着请求分配一个资源,因此S的值减1;当S<0时,表示已经没有可用资源,S的绝对值表示当前等待该资源的进程数。请求者必须等待其他进程释放该类资源,才能继续运行。**而执行一个V操作意味着释放一个资源,因此S的值加1;若S<0,表示有某些进程正在等待该资源,因此要唤醒一个等待状态的进程,使之运行下去。
注意,信号量的值只能由PV操作来改变。
15.关于记录型信号量机制,如下说法不准确的是(D )。
A、记录型信号量的队列分量用来表示因申请对应资源失败而受阻的进程阻塞队列
B、记录型信号量的signal操作不仅执行资源的释放,还会唤醒相应进程阻塞队列的队首进程
C、记录型信号量的wait操作在进程申请对应资源未果的情况下,将把当前进程插入到相应的进程阻塞队列
D、记录型信号量的整型分量用来表示系统当前可用对应资源的数量
解析:整型信号量被定义为一个用于表示资源数目的整型量S
16.一段时间内仅允许一个进程访问的空间称为临界区。错误
解析:进程中访问临界资源的那段代码称为临界区。
在一段时间内只允许一个进程访问的资源,称为是临界资源
17.中断是OS内核最基本的功能。正确
18.下面关于PCB的说法中,错误的是( D)
A、每个进程只有1个PCB
B、1个PCB只对应1个进程
C、PCB位于内存中
D、PCB的索引组织方式比链式组织方式好
解析:进程与PCB是一一对应的。 PCB应常驻内存。
1)线性表方式:不论进程的状态如何,将所有的PCB连续地存放在内存的系统区。这种方式适用于系统中进程数目不多的情况,不适合频繁的进程调度
2)索引表方式:该方式是线性表方式的改进,系统按照进程的状态分别建立就绪索引表、阻塞索引表等。其中进程阻塞可能由于I/O请求、申请缓冲区失败、等待解锁、获取数据失败等原因造成,将其组成一张表忽略了进程的优先级,不利于进程的唤醒。
不存在谁好谁坏
19.关于整型信号量机制,下列说法不正确的是(B )。
A、整型信号量用来表示系统当前可用对应资源的数量
B、整型信号量机制无法满足空闲让进的准则
C、整型信号量机制无法满足让权等待的准则
D、整型信号量机制提供有资源申请操作和资源释放操作,也即PV操作
解析:整型信号量机制无法满足让权等待的准则wait过程中,如果不满足则一直在询问,直到满足了才跳出循环,执行后续操作。执行过程中不可中断。
20.下列特性中,哪一个不是进程的特性( C)
A、异步性
B、并发性
C、静态性
D、动态性
解析:进程的特征:
结构特征:由程序段、数据段、进程控制块三部分组成(进程实体);
动态性:进程的实质是程序的一次执行过程;
并发性:多个进程可同存于内存中,能在一段时间内同时运行;
独立性:独立运行的基本单位,独立获得资源和调度的基本单位;异步性:各进程按各自独立的不可预知的速度向前推进。
21.为使进程由静止就绪变为活动就绪,应利用( C)原语。
A、wakeup
B、suspend
C、active
D、block
解析:
活动就绪------suspend------>静止就绪
活动就绪<------active------静止就绪
活动阻塞------suspend------>静止阻塞
活动阻塞<------active------静止阻塞
22.PV操作是对信号量执行减1操作,意味着释放一个单位资源,加1后如果信号量的值小于等于零,则从等待队列中唤醒一个进程。 正确
V操作是对信号量执行加1操作,意味着释放一个单位资源,加1后如果信号量的值小于等于零,则从等待队列中唤醒一个进程,并将它变为就绪状态,而现进程继续进行。
23.对于管程而言,为区别不同的等待原因而引入了( C)的概念,并分别为之设立相应的进程等待队列。
A、信号量
B、互斥锁
C、条件变量
D、线程
24.下列进程状态的转换中,哪一个是不正确的( C)
A、就绪->运行
B、运行->就绪
C、就绪->阻塞
D、阻塞->就绪
解析:活动就绪静止就绪 活动阻塞静止阻塞 静止就绪活动就绪 静止阻塞活动阻塞
阻塞—>运行 就绪—>阻塞是不存在的
25.某个运行中的进程要申请打印机,它将变为(B )
A、就绪态
B、阻塞态
C、创建态
D、撤销态
解析:
其实处理机同一时刻只能执行一个进程。而要让处理机同时去执行多个进程,怎么办?
进程调度程序会把处理机划分成长短相同且很小的时间块,每个时间块执行一个进程,某个进程时间块用完后,回到就绪状态,换到下一个进程执行。这样轮流来执行,实现了处理机能一起一起执行多个进程。
当某个进程申请资源被占用或者启动I/O传输未完成,就处于等待状态。(此时它和其它进程不一样,它不再去争夺时间块,就相当于睡着了一样)当它所请求的资源被释放,或者启动I/O传输完成,那么就会由继续进行就绪状态,(这就好比它被唤醒了,回到就绪状态里,同其它里程争夺处理机的时间块。你的问题就是这个进程从睡着了,然后又被唤醒了。被唤醒后你不能马上就要求执行啊,因为处理机还要执行其它进程,而这个进程就要回到就绪状态,和其它进程一样却争夺处理机的执行时间块)
当前正在执行的进程由于时间片用完而暂停执行时,该进程应转变为就绪状态;若因发生某种事件而不能继续执行时,应转为阻塞状态;若终端用户的请求而暂停执行时,它应转变为静止就绪状态。
26.并发进程是指(D )
A、不可中断的进程
B、可并发执行的进程
C、可同一时刻执行的进程
D、可同时执行的进程
27.如果某一进程在运行时,因等待数据输入,此时将脱离运行状态,进入(B )
A、就绪状态
B、阻塞状态
C、挂起状态
D、终止状态
解析:
当前正在执行的进程由于时间片用完而暂停执行时,该进程应转变为就绪状态;若因发生某种事件而不能继续执行时,应转为阻塞状态;若终端用户的请求而暂停执行时,它应转变为静止就绪状态。
28.进程同步机制应遵循让权等待准则,故当一个进程不能进入自己的临界区时,应当释放( B)。
A、内存空间
B、处理器
C、I/O设备
D、外存空间
29.操作系统中有一组常称为特殊系统调用的程序(B ),它不能被系统中断。
A、初始化程序
B、原语
C、信号量
D、控制模块
30.一个程序对应一个进程。错误
解析:一个程序可以对应多个进程
第三章 进程的调度与死锁
1.既考虑作业等待时间,又考虑作业执行时间的调度算法是( D)。
A、先来先服务
B、短作业优先
C、优先级调度
D、高响应比优先
解析:
2.作业从进入后备队列到被调度程序选中的时间间隔称为( C)。
A、周转时间
B、响应时间
C、等待时间
D、触发时间
3.时间片轮转调度算法是为了(A )。
A、多个终端能够得到系统及时响应
B、使系统更高效
C、优先级较高的进程得到及时响应
D、需要CPU时间最少的进程最先运行
解析:时间片轮转的主要目的是使得多个交互的用户能够得到及时响应,使得用户以为“独占”计算机的使用。因此它并没有偏好,也不会对特殊进程做特殊服务。时间片轮转增加了系统开销,所以不会使得系统高效运转,吞吐量和周转时间均不如批处理。但是其较快速的响应时间使得用户能够与计算机进行交互,改善了人机环境,满足用户需求。
4.下面有关选择进程调度算法的准则中不正确的是(D )。
A、尽快响应交互式用户的请求
B、尽量提高处理机利用率
C、尽可能提高系统吞吐量
D、适当增长进程就绪队列的等待时间
解析:减少进程就绪队列的等待时间
① 处理器利用率;② 吞吐量;③ 等待时间;④ 响应时间。
5.进程调度算法采用时间片轮转调度算法,当时间片过大时,就会使时间片轮转算法转化为(A )调度算法。
A、先来先服务
B、短进程优先
C、高响应比优先
D、以上选项都不对
解析:时间片轮转调度算法在实际运行中也是按先后顺序使用时间片,当时间片过大时,我们可以认为其大于进程需要的运行时间,即转变为先来先服务调度算法
6.下列选项中,满足短作业优先且不会发生饥饿现象的是(D )调度算法。
A、先来先服务
B、非抢占式短作业优先
C、时间片轮转
D、高响应比优先
解析:
高响应比优先算法:
响应比 =(等待时间+要求服务时间)/ 要求服务时间,即RR=(w+s)/s=1+w/s。因此响应比一定是大于1的。
这种算法的思想是综合了 短作业优先调度算法 + 动态优先权机制 的优点,既考虑作业的执行时间也考虑作业的等待时间,综合了先来先服务和最短作业优先两种算法的特点。
当一个作业的要求服务时间很短,那么响应比就会很大,有短作业优先的特点;但是当一个作业等待时间太长了,它的响应比又提升了,解决了短作业优先算法容易发生 饥饿 的毛病,
7.进程调度又称低级调度,其主要功能是(D )。
A、选择一个作业调入内存
B、选择一个内存中的进程调出到外存
C、选择一个外存中的进程调入内存
D、将一个就绪的进程投入运行
解析:
低级调度用于决定就绪队列中的哪个进程应获得处理机,然后再由分派程序执行把处理机分配给该进程的具体操作。
低级调度的主要功能如下:
-
保存处理机的现场信息
在进程调度进行调度时,首先需要保存当前进程的处理机的现场信息,如程序计数器、多个通用寄存器中的内容等,将它们送入该进程的进程控制块(PCB)中的相应单元。
-
按某种算法选取进程
低级调度程序按某种算法如优先数算法、轮转法等,从就绪队列中选取一个进程,把它的状态改为运行状态,并准备把处理机分配给它。
-
把处理器分配给进程
由分派程序(Dispatcher)把处理器分配给进程。
此时需为选中的进程恢复处理机现场,即把选中进程的进程控制块内有关处理机现场的信息装入处理器相应的各个寄存器中,把处理器的控制权交给该进程,让它从取出的断点处开始继续运行
8.分时系统中,若当前运行的进程连续获得两个时间片,原因可能是(B )。
A、该进程的优先级最高
B、就绪队列为空
C、该进程最早进入就绪队列
D、该进程是一个短进程
9.三种主要类型的OS中都必须配置的调度是( C)。
A、作业调度
B、中级调度
C、低级调度
D、高级调度
10.死锁问题的讨论是针对(D )进行。
A、某个进程申请系统中不存在的资源
B、某个进程申请资源数超过了系统拥有的最大资源数
C、硬件故障
D、多个并发进程竞争独占型资源
11.有关资源分配图中存在环路和死锁关系,正确的说法是( D)。
A、图中无环路则系统可能存在死锁
B、图中无环路则系统肯定存在死锁
C、图中有环路则系统肯定存在死锁
D、图中有环路则系统可能不存在死锁
解析:图中无环路系统无死锁,图中有环路则系统可能存在死锁
12.死锁的预防方法中,不太可能的一种方法是( A)。
A、破环互斥条件
B、破坏请求和保持条件
C、破坏不剥夺条件
D、破坏循环等待条件
解析:产生死锁必须同时具备下面四个必要条件,只要其中任一个条件不成立,死锁就不会发生: (1) 互斥条件 (2) 请求和保持条件 (3) 不可抢占条件 (4) 循环等待条件
互斥:互斥条件是共享资源必须的,不仅不能改变,还应加以保证请求和保持:必须保证进程申请资源的时候没有占有其他资源要求进程在执行前一次性申请全部的资源,只有没有占有资源时才可以分配资源资源利用率低,可能出现饥饿改进:进程只获得运行初期所需的资源后,便开始运行;其后在运行过程中逐步释放已分配的且用毕的全部资源,然后再请求新资源
非抢占:如果一个进程的申请没有实现,它要释放所有占有的资源;先占的资源放入进程等待资源列表中;进程在重新得到旧的资源的时候可以重新开始。循环等待:对所有的资源类型排序进行线性排序,并赋予不同的序号,要求进程按照递增顺序申请资源。如何规定每种资源的序号是十分重要的;限制新类型设备的增加;作业使用资源的顺序与系统规定的顺序不同;限制用户简单、自主的编程。
13.产生死锁的原因可能是因为(C )。
A、进程释放资源
B、一个进程进入死循环
C、多个进程竞争资源出现了循环等待
D、多个进程竞争共享型设备
解析:竞争不可抢占性资源引起死锁;竞争可消耗资源引起死锁;进程推进顺序不当引起死锁;
14.对资源采用按序分配策略能达到( A)的目的。
A、预防死锁
B、避免死锁
C、检测死锁
D、解除死锁
15.多个进程共享的系统资源不足时可能产生死锁,但是不适当的(C )也可能产生死锁。
A、进程优先权
B、资源的静态分配
C、进程的推进顺序
D、分配队列优先权
16.通常不采用( D)方法来解除死锁。
A、终止一个死锁进程
B、终止所有的死锁进程
C、从死锁进程处抢夺资源
D、从非死锁进程处抢夺资源
17.下列进程调度算法中,( A)可能会出现饥饿现象。
A、静态优先权算法
B、抢占式调度中采用动态优先权算法
C、分时处理中的时间片论战调度算法
D、非抢占式调度中采用FIFO算法
解析:因为静态优先算法,不管是可抢占的还是不可抢占的,都会发生饥饿的现象,因为优先级低得进程会长时间得不到运行。
18.两个进程争夺同一个资源(B )。
A、一定死锁
B、不一定死锁
C、只要互斥就不会死锁
D、以上说法都不对
19.在处理死锁的方法中,属于“避免死锁”的策略是(B )。
A、资源的有序分配
B、银行家算法
C、优先级调度
D、高响应比优先
解析:资源有序分配策略在于打破死锁条件中的循环等待条件。
优先级调度:就绪态的实时任务立即抢占非实时任务
20.当进程调度采用优先级调度算法时,从保证系统效率的角度来看,应提高(B )进程的优先级。
A、连续占用处理器时间长的
B、在就绪队列中等待时间长的
C、以计算为主的
D、用户
21.一个作业8:00到达系统,估计运行时间为1h.若10:00开始执行该作业,其响应比是(C )。
A、2
B、1
C、3
D、0.5
解析:
等待时长2h,要求服务时间1h,那么1+2/1=3
22.假设有5个批处理作业几乎同时到达系统,它们估计运行时间为10,6,2,4,8分钟,优先级分别为3,5,2,1,4(5为最高优先级)。若采用优先级调度算法,则平均周转时间为( C)分钟。
A、6
B、10
C、20
D、24
在题目中指出5个作业几乎同时到达一个计算中心,其含义是任何调度算法(除了FCFS算法外)都可以认为这5个作业是同时到达的,在调度过程中不需考虑其到达的顺序。
| 0(分钟) | 作业A,B,C,D,E到达 |
|---|---|
| 作业B优先级最高,被调入系统运行 | |
| 作业A,C,D,E等待系统调度 | |
| 6(分钟) | 作业B运行完成 |
| 作业E优先级最高,被调入系统运行 | |
| 作业A,C,D等待系统调度 | |
| 14(分钟) | 作业E运行完成 |
| 作业A优先级最高,被调入系统运行 | |
| 作业C,D等待系统调度 | |
| 24(分钟) | 作业A运行完成 |
| 作业C优先级最高,被调入系统运行 | |
| 作业D等待系统调度 | |
| 26(分钟) | 作业C运行完成 |
| 作业D优先级最高,被调入系统运行 | |
| 30(分钟) | 作业D运行完成 |
最高优先级优先:各作业的执行结束时间分别为:24,6,26,30,14
作业的平均周转时间为:
T
=
∑
T
i
/
n
=
(
24
+
6
+
26
+
30
+
14
)
/
5
=
20
T=\sum_{}^{}T_i/n=(24+6+26+30+14)/5=20
T=∑Ti/n=(24+6+26+30+14)/5=20
23.设系统中有n个并发进程,共同竞争资源X,且每个进程都需要m个X资源,为使该系统不会发生死锁,资源X最少要有( C)个。
A、n*m+1
B、n*m+n
C、n*m+1-n
D、无法预计
解析:
最极端的情况是每个进城有m-1个资源,而总资源一共就有n*(m-1)个,那么这个时候也会发生死锁,这个时候只需要再多出一个资源,就可以保证某一个进城执行成功,然后执行成功以后,就会有更多的资源释放,后面的进城也可以执行。所以最终的结果就是n*(m-1)+1
24.若进程P一旦被唤醒就能够投入运行,系统可能为( D)。
A、分时系统,进程P的优先级最高
B、抢占调度方式,就绪队列上的所有进程的优先级都比进程P低
C、就绪队列为空队列
D、抢占调度方式,进程P的优先级高于当前运行的进程
25.某系统采用银行家算法,则下列叙述正确的是(B )。
A、系统处于不安全状态时一定会发生死锁
B、系统处于不安全状态时可能会发生死锁
C、系统处于安全状态时一定会发生死锁
D、系统处于安全状态时可能会发生死锁
解析:系统处于安全状态时,一定不会发生死锁;系统处于不安全状态时,不一定会发生死锁;
26.系统中有四个进程P1、P2、P3、P4,有四种类型的资源:A、B、C、D。系统最初四类资源总数为(5,7,7,2)。P1、P2、P3、P4的对各类资源的最大需求分别为(3 ,2, 1 ,2)(4, 5 ,3, 2)(2 ,3 ,4, 1)(1 ,2, 2,1)。在T0时刻P1、P2、P3、P4已经分配到的资源分别为:(0, 2, 0, 1)(2 ,2, 3, 0)(1, 1, 2, 0)(1 ,2 ,0, 1)。问TO时刻系统的可用资源向量是( C)。
A、(1,1,2,2)
B、(1,2,2,1)
C、(1,0,2,0)
D、(2,1,2,1)
解析:
| 最大资源需求量 | 已分配资源数量 | available | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | R1 | R2 | R3 | R4 | R1 | R2 | R3 | R4 | |
| P1 | 3 | 2 | 1 | 2 | 0 | 2 | 0 | 1 | 1 | 0 | 2 | 0 |
| P2 | 4 | 5 | 3 | 2 | 2 | 2 | 3 | 0 | ||||
| P3 | 2 | 3 | 4 | 1 | 1 | 1 | 2 | 0 | ||||
| P4 | 1 | 2 | 2 | 1 | 1 | 2 | 0 | 1 |
系统中资源总量为某时刻系统中可用资源量与各进程已分配资源量之和,各进程对资源的需求量为各进程对资源的最大需求量与进程已分配资源量之差
(5,7,7,2)-(0,2,0,1)-(2,2,3,0)-(1,1,2,0)-(1,2,0,1)=(1,0,2,0)
27.系统中有四个进程P1、P2、P3、P4,有四种类型的资源:A、B、C、D。系统最初四类资源总数为(5,7,7,2)。P1、P2、P3、P4的对各类资源的最大需求分别为(3 ,2, 1 ,2)(4, 5 ,3, 2)(2 ,3 .4, 1)(1 ,2, 2,1)。在T0时刻P1、P2、P3、P4已经分配到的资源分别为:(0, 2, 0, 1)(2 ,2, 3, 0)(1, 1, 2, 0)(1 ,2 ,0, 1)。问TO时刻P3的需求矩阵是(B )。
A、(1,2,3,1)
B、(1,2,2,1)
C、(1,2,3,2)
D、(2,2,3,1)
解析:P3的需求矩阵=(2,3,4,1)-(1,1,2,0)=(1,2,2,1)
P1=(3,2,1,2)-(0,2,0,1)=(3,0,1,1)
P2=(4,5,3,2)-(2,2,3,0)=(2,3,0,2)
P4=(1,2,2,1)-(1,2,0,1)=(0,0,2,0)
28.系统中有四个进程P1、P2、P3、P4,有四种类型的资源:A、B、C、D。系统最初四类资源总数为(5,7,7,2)。P1、P2、P3、P4的对各类资源的最大需求分别为(3 ,2, 1 ,2)(4, 5 ,3, 2)(2 ,3 .4, 1)(1 ,2, 2,1)。在T0时刻P1、P2、P3、P4已经分配到的资源分别为:(0, 2, 0, 1)(2 ,2, 3, 0)(1, 1, 2, 0)(1 ,2 ,0, 1)。问TO时刻的安全序列是(D )。
A、{P3,P4,P1,P2}
B、{P1,P4,P3,P2}
C、{P2,P4,P3,P1}
D、{P4,P3,P1,P2}
解析:available(1,0,2,0)NEED矩阵见上题
P4够先释放
29.系统中有四个进程P1、P2、P3、P4,有四种类型的资源:A、B、C、D。系统最初四类资源总数为(5,7,7,2)。P1、P2、P3、P4的对各类资源的最大需求分别为(3 ,2, 1 ,2)(4, 5 ,3, 2)(2 ,3 .4, 1)(1 ,2, 2,1)。在T0时刻P1、P2、P3、P4已经分配到的资源分别为:(0, 2, 0, 1)(2 ,2, 3, 0)(1, 1, 2, 0)(1 ,2 ,0, 1)。问TO时刻P1请求资源(0,0,2,0),是否能实施资源分配?( B )。
A、是
B、否
解析:(0,0,2,0)>(3,0,1,1)不满足Request i[j]≤Need[i, j],出错
30.在系统中有5个作业A,B,C,D,E,他们的到达时间分别为0,2,4,6,8。运行时间分别为3,6,4,5,2。系统采用FCFS调度算法的平均带权周转时间是(A)
A、2.56
B、3.4
C、6
D、8.6
解析:先来先服务(first-come first-served,FCFS)调度算法
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|---|
| A | 0 | 3 | 0 | 0 | 3 | 3 | 1 |
| B | 2 | 6 | 3 | 1 | 9 | 7 | 1.167 |
| C | 4 | 4 | 9 | 5 | 13 | 9 | 2.25 |
| D | 6 | 5 | 13 | 7 | 18 | 12 | 2.4 |
| E | 8 | 2 | 18 | 10 | 20 | 12 | 6 |

平均带权周转时间 W=(1+1.167+2.25+2.4+6)/5=2.56
31.在系统中有5个作业A,B,C,D,E,他们的到达时间分别为0,2,4,6,8。运行时间分别为3,6,4,5,2。系统采用SJF调度算法的平均带权周转时间是(D)
A、7.6
B、4
C、3.5
D、1.84
解析:抢占式
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|---|
| A | 0 | 3 | 0 | 0 | 3 | 3 | 1 |
| B | 2 | 6 | 9 | 7 | 15 | 13 | 2.17 |
| C | 4 | 4 | 4 | 0 | 8 | 4 | 1 |
| D | 6 | 5 | 15 | 9 | 20 | 14 | 2.8 |
| E | 8 | 2 | 8 | 6 | 10 | 2 | 1 |
平均带权周转时间W=(1+2.17+1+2.8+1)/5=1.594
表格解释:A 结束之后,B 要开始,执行到第四个时间点的时候,C 到达,那么B 这个时候已经执行了1个时间,还剩下5个服务时间,C 需要4个服务时间,所以C 抢占B ,C 结束以后,E 开始执行,结束以后,发现B 和D 需要服务时间一样,那么应该让先到的进程B 继续执行,最后进行E 的执行
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|---|
| A | 0 | 3 | 0 | 0 | 3 | 3 | 1 |
| B | 2 | 6 | 3 | 1 | 9 | 7 | 1.17 |
| C | 4 | 4 | 11 | 7 | 15 | 11 | 2.75 |
| D | 6 | 5 | 15 | 9 | 20 | 14 | 2.8 |
| E | 8 | 2 | 9 | 1 | 11 | 3 | 1.5 |
简单说一下,A 完成的时候,B 已经到达,这个时候显然需要B 开始,由于不是非抢占式,每个进程如果开始就必须持续做直到做完,所以B 结束的时候也就是第9 个时间点,这时,C D E 都已经到达,那么应该开始谁的服务呢?因为E 的服务时间最短,所以应该让E 继续,剩下同理
平均带权周转时间W=(1+1.17+2.75+2.8+1.5)/5=1.844
32.在系统中有5个作业A,B,C,D,E,他们的到达时间分别为0,2,4,6,8。运行时间分别为3,6,4,5,2。系统采用高响应比调度算法的平均带权周转时间是(C)
A、3
B、8
C、2.14
D、5
解析:
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|---|
| A | 0 | 3 | 0 | 0 | 3 | 3 | 1 |
| B | 2 | 6 | 3 | 1 | 9 | 7 | 1.17 |
| C | 4 | 4 | 9 | 5 | 13 | 9 | 2.25 |
| D | 6 | 5 | 15 | 9 | 20 | 14 | 2.8 |
| E | 8 | 2 | 13 | 5 | 15 | 7 | 3.5 |
高响应比调度算法的平均带权周转时间W=(1+1.17+2.25+2.8+3.5)/5=2.144
响应比:A:1 B:(1+6)/6=1.167 C:(5+4)/4=2.25 D:(9+5)/5=2.8 E:(5+2)/2=3.5
A:1 B:2 C:3 D:5 E:4

注意一点,此算法并非抢占,只要不是抢占调度,就必须一个一个的来,这个执行完毕才能执行下一个
第四章 进程同步
1.某页式存储管理系统中,地址寄存器长度为24位,其中页号占14位, 则主存的分块大小应该是( A )字节。
A、 2^10
B、2^14
C、2^24
D、14
解析:在分页存储管理系统中,其地址结构如下:页号P位移量W其中,页号P占了14位,地址总长度为24位,那么位移量W的长度就应如下计算:位移量W的长度=地址总长度-页号P长度=24-14=10位所以,在每个主存分块的大小是2^10字节。
2.在固定分区分配中,每个分区的大小是(C)。
A、相同
B、随作业长度变化
C、可以不同但预先固定
D、可以不同但根据作业长度固定
解析:固定分区分配,是满足多道程序设计的存储技术,可以将内存划分成多个区,每个区运行一个作业,从而达到多道程序设计的多个作业同时在内存中的设计。 但是固定分区分配是提前将内存划分成多个区,区的大小可以不同,但是划分好后,个数和大小都不能发生改变。 作业到来,选择一个合适大小的区放置,但是作业长度不一,不会有太合适的区恰好满足其大小,从而会造成区空间的浪费,并且此浪费非常严重。
3.在可变式分区分配方案中,某一作业完成后系统收回其主存空间,并与相邻空闲区合并,造成空闲数减1的情况是(D )。
A、无上邻空闲区,也无下邻空闲区
B、有上邻空闲区,但无下邻空闲区
C、有下邻空闲区,但无上邻空闲区
D、有上邻空闲区,也有下邻空闲区
解析:选项A的情况,回收区作为单独的空闲分区记入空闲区说明表;选项B和选项C类似,回收区与相邻的一个空闲分区合并后,修改相应的空闲区说明表项,空闲分区数不会改变;只有当上、下都要邻接空闲分区时,系统将它们与回收区合并成一个空闲分区,从而空闲分区数会减少。因此本题选择D。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5PAa98p-1652544427119)(/…/…/…/…/…/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E4%B9%A0%E9%A2%98%E9%9B%86.assets/image-20220430165216054.png)]
4.动态重定位技术依赖于(B)。
A、重定位装入程序
B、重定位寄存器
C、地址机构
D、目标程序
解析:重定位即地址变换,动态重定位依赖硬件,也就是基址寄存器,也就是重定位寄存器
5.很好地解决了“零头”问题的存储管理方法是(A)。
A、页式存储管理
B、段式存储管理
C、多重分区管理
D、可变式分区管理
解析:。内零头是指分配给作业的存储空间中未被利用的部分,外零头是指系统中无法利用的小存储块。在各种存储器管理方法中固定分区的分配方式会产生内零头,因为是找出一个满足作业要求的空闲分区分配给作业,大小不一定刚好合适,分区中有一部分存储空间会被浪费。在可变式分区分配中,是按照作业的大小找出一个分区来分配如果大于作业申请的空间,则一分为二,剩下的一分部作为系统的空闲分区.有可能很小无法利用而成为外零头。为了解决外零头的问题,提出了离散的分配方式,在分页式存储管理中,存储空间被分面与页大小相等的物理块,作业的大小不可能都是物理块的整数倍,因此在作业的最后一页中有可能有部分空间未被利用,属于内零头。分段式存储管理中,其内存分配方式类似于动态分区的分配,因此会产生外零头。段页式存储管理中,其内存分配方式类似于页式的分配.因此会产生内零头。
6.某系统采用固定分区分配存储管理,内存空间为640K,其中地址0到40K被系统占用,其他空间按分区大小相等的方法划分为4个分区,则当有大小分别为7KB、90KB、30KB、20KB的作业进入内存时,浪费的内存为( C )。
A、3KB
B、450KB
C、453KB
D、147KB
解析:固定分区:用户程序需要装入时,内存分配程序检索该表,找出一个能满足要求尚未分配的分区,分配给该程序,并将其表项中的状态置为“已分配”。若未找到大小足够的分区,则拒绝为用户程序分配内存。
| 分区号 | 大小(K) | 起址(K) | 状态 | 作业 | 作业大小() |
|---|---|---|---|---|---|
| 1 | 150 | 190 | A | 7 | |
| 2 | 150 | 340 | B | 90 | |
| 3 | 150 | 490 | C | 30 | |
| 4 | 150 | 640 | D | 20 |
7+90+30+20=147
600-147=453
7.作业在执行中发生了缺页中断,经操作系统处理后,应让其执行(B )指令。
A、被中断的前一条
B、被中断的
C、被中断的后一条
D、启动时的第一条
解析:缺页中断是因为要访问的指令所在的页面不在内存中,需要先将相关页面带入内存才能执行。因此,在带入相关页面后,需要执行刚才被中断的指令。
8.某基于动态分区存储管理的计算机,其主存容量为55MB(初始为空),采用最佳适配(Best Fit)算法,分配和释放的顺序为:分配15MB,分配30MB,释放15MB,分配8MB,分配6MB,此时主存中最大空闲分区的大小是(B ).
A、7MB
B、9MB
C、10MB
D、15MB
解析:最佳适应(best fit,BF)算法
算法思想:由于动态分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。一次为保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即优先使用更小的空闲区。
如何实现:要求按空闲区大小从小到大的次序组成空闲区表(队列)。当进程申请一个存储区时,系统从表头开始查找,当找到第一个满足要求的空闲区时,停止查找,并且这个空闲区是最佳的空闲区。所谓最佳即选中的空闲区是满足要求的最小空闲区。
其主存容量为55mb(初试为空间),第一步分配15MB以后还有55MB-15MB=40MB,第二步分配30MB以后还有 40MB-30MB=10MB,第三步释放15MB以后有两个空闲区15MB,和10MB,第四步分配8MB,则空闲区为15MB,2MB,第五步分配 6MB,则空闲区为9MB,2MB
9.在页式存储管理中选择页面的大小,需要考虑下列(C)因素。 I.页面大的好处是页表比较少 II.页面小的好处是可以减少由内碎片引起的内存浪费 Ⅲ.影响磁盘访问时间的主要因素通常不是页面大小,所以使用时优先考虑较大的页面
A、I和Ⅲ
B、II和Ⅲ
C、Ⅰ和Ⅱ
D、I、Ⅱ和Ⅲ
解析:页面大,用于管理页面的页表就少,但是页内碎片会比较大;页面小,用于管理页面的页表就大,但是页内碎片少。通过适当的计算可以获得较佳的页面大小和较小的系统开销。
10.在分页系统环境下,程序员编制的程序,其地址空间是连续的,分页是由(D)完成的。
A、程序员
B、编译地址
C、用户
D、系统
11.把逻辑地址转换成物理地址的工作称为重定位。 正确
12.采用动态重定位技术的系统,可执行程序可以不经任何改动,而装入物理内存 正确
13.在现代操作系统中,不允许用户干预内存的分配。 正确
14.存储保护的目的是限制内存的分配。 错误
解析:是为了保护进程之间相互不受影响
15.存储管理的主要目的是扩大内存空间。 错误
解析:储存管理的目的是实现扩充主存容量,并提高主存利用效率。
第五章 存储器管理
1.虚拟存储器的最大容量是(C )。
A、由作业的地址空间决定
B、是任意的
C、由计算机的地址结构决定
D、为内外存容量之和
解析:虚存的最大容量由CPU的地址长度决定。
虚存的实际容量为内存和外存容量之和;
2.实现虚拟存储器的目的是( D ) 。
A、实现存储保护
B、实现程序浮动
C、扩充辅存容量
D、扩充主存容量
3.下列诸项中,( A )不是影响缺页中断率的主要因素。
A、缺页中断服务速度
B、分配给作业(进程)的物理块数
C、系统规定页面的大小
D、页面调度算法
解析:影响因素 :
(1)页面大小。 页面划分比较大,则缺页率较低;反之,缺页率较高。 (2)进程分配的物理块数。 所分配的物理块越多,缺页率越低;反之,越高。 (3)页面置换算法。 算法的优劣决定了进程执行过程中缺页中断的次数,因此缺页率是衡量页面置换算法的重要指标。 (4)程序固有特性。 程序本身的编制方法对缺页中断次数有影响,根据程序执行的 局部性原理 ,程序编制的局部化程度越高相应执行时的缺页程度越低。
4.下面选项中哪一个不是请求分段存储管理方式所需要的硬件支持( B ) 。
A、段表机制
B、缺段中断机构
C、缺页中断机构
D、动态地址变换机制
解析:请求分段中的硬件支持
- 请求段表机制
- 字段说明
- 缺页中断机构
- 地址变换机构
5.下面关于存储管理的叙述中,正确的是(D).
A、存储保护的目的是限制内存的分配
B、在内存为M、有N个用户的分时系统中,每个用户占用M/N的内存空间
C、在虚拟内存系统中,只要磁盘空间无限大,作业就能拥有任意大的编址空间
D、实现虚拟内存管理必须有相应硬件的支持
解析:A:是为了保护进程之间相互不受影响
B:内存可以共同调用
C:虚拟内存大小=主存+辅存,地址总线宽度) 所以,64位系统,最多2^64的地址空间。不是无上限
D:实现虚拟存储器需要三方面的硬件支持:
1、请求分页/段的页表或段表机制;
请求分页存储管理是建立在分页存储管埋的基础上,并结合虚拟存储系统原理实现的,是目前常用的一种实现虚拟存储器的方式
2、缺页/段中断机构;
作用就是就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。在这个时候,被内存映射的文件实际上成了一个分页交换文件。
3、地址变换机构。
当进程要访问某个逻辑地址中的数据时,分页地址变换机构会自动地将有效地址(相对地址)分为页号页内地址两部分,再以页号为索引去检索页表。查找操作由硬件执行。在执行检索之前,先将页号与页表长度进行比较,如果页号大于或等于页表长度,则表示本次所访问的地址已超越进程的地址空间。于是,这一错误将被系统发现并产生一地址越界中断。若未出现越界错误,则将页表始址与页号和页表项长度的乘积相加,便得到该表项在页表中的位置,于是可从中得到该页的物理块号,将之装入物理地址寄存器中。与此同时,再将有效地址寄存器中的页内地址送入物理地址寄存器的块内地址字段中。这样便完成了从逻辑地址到物理地址的变换。
6.下列关于虚拟存储器的叙述中,正确的是(B)
A、虚拟存储只能基于连续分配技术
B、虚拟存储只能基于非连续分配技术
C、虚拟存储容量只受外存容量的限制
D、虚拟存储容量只受内存容量的限制
解析:虚拟内存的容量是受到内外存容量和计算机地址位数限制的。
虚拟内存技术的核心就是建立虚拟地址和物理地址的映射关系, 其能够表现出比实际内存更大的内存的原因是因为存在页面置换, 通过置换,可以把一部分磁盘空间当作内存使用。 可见,虚拟内存包括两大部分,一部分磁盘空间和实际内存 这两者显然只能是不连续分配的。 另外如果连续分配的话,也没必要用虚拟内存了,都不用逻辑地址,直接用物理地址就好了, 当然也就没法建立一个映射去自由分配内存了。
7.进程在执行中发生了缺页中断,经操作系统处理后,应让其执行(B)指令。
A、被中断的前一条
B、被中断的那一条
C、被中断的后一条
D、启动时的第一条
8.若用户进程访问内存时产生缺页,则下列选项中,操作系统可能执行的操作是(B). I.处理越界错 II.置换页 Ⅲ.分配内存
A、仅I、Ⅱ
B、仅Ⅱ、Ⅲ
C、仅I、Ⅲ
D、I、II和IⅢ
解析:当CPU发现所请求的内存地址中没有指令,就会发出缺页中断。
1:处理越界,很显然只有已经加载到内存的数组或其他单元才可能出现访问越界的情况,而发生缺页中断,说明还没有把数据装载到内存
2:发生缺页后,首先检查内存单元是否有空闲页,如果没有,操作系统会根据页面置换算法将一部分页面置换出去,然后将缺页数据置换进来。
如果有,就会发生答案3的情况,直接将数据置换到内存
但是如果调页时逻辑地址中的页号超过页表的范围会产生越界中断,改过程由硬件完成。并不是操作系统的任务。在判断缺页前首先就会判断是否越界
在处理逻辑地址,先对逻辑地址求页号,若页号大于用户空间的最大页号,则发生越界中断,就此结束不会判断是否缺页。若页号合理,则会进行对是否缺页按照相应的调度算法,置换页面或者分配内存。综上,发生缺页时,说明地址合法,不存在越界,当然就不会了去越界处理了
9.为使虚存系统有效地发挥其预期的作用,所运行的程序应具有的特性是©.
A、该程序不应含有过多的I/O操作
B、该程序的大小不应超过实际的内存容量
C、该程序应具有较好的局部性
D、该程序的指令相关性不应过多
解析:虚拟存储技术是基于程序的局部性原理。局部性越好虚拟存储系统越能更好地发挥其作用。
10.下面关于请求页式系统的页面调度算法中,说法错误的是(D)
A、一个好的页面调度算法应减少和避免抖动现象
B、FIFO算法实现简单,选择最先进入主存储器的页面调出
C、LRU算法基于局部性原理,首先调出最近一段时间内最长时间未被访问过的页面
D、CLOCK算法首先调出一段时间内被访问次数多的页面
解析:先进先出(FIFO)页面置换算法:
基本思想:总是先淘汰那些驻留在内存时间最长的页面,即先进入内存的页面先被置换掉。理由是:最先进入内存的页面不再被访问的可能性最大。引入指针将进入内存的页面按时间的先后次序链成队列,新进入的页面从队尾入队,淘汰总是从队列头进行。
最近最久未使用和最少使用置换算法(LRU):
LRU(Least Recently Used)置换算法的描述:选择内存中最近一段时间里较久未被访问的页面予以淘汰。性能接近最佳置换算法。根据程序局部性原理,那些刚被使用过的页面,可能马上还要被使用,而在较长时间里未被使用的页面,可能不会马上使用到。由于需要记录页面使用时间的先后关系,硬件开销太大。
最近最少使用,简单来说就是将数据块中,每次使用过的数据放在数据块的最前端,然后将存在的时间最长的,也就是数据块的末端的数据剔除掉这就是LRU算法
Clock置换算法:
简单的Clock置换算法 :每页有一个使用访问位,将内存中的所有页面通过链接指针链接成一个循环队列。 当页面被装入内存,或被访问,则置访问位=1。 寻找访问位=0的页面作为被置换页。指针经过的访问位=1的页都修改为0。当淘汰一个页面时,只需检查页的访问位。如果是0,就选择该页换出;如果是1,则将它置为0,暂不换出,继续扫描下一个页面。若第一轮扫描中所有页面都是1,则将这些页面的访问位依次置为0后,再进行第二轮扫描。(第二轮扫描中一定会有访问位为0的页面,因此简单的CLOCK算法选择一个淘汰页面最多会经过两次扫描)
CLOCK算法是一种近似于LRU(Least Recently Used,最近最少使用)算法的页面调度算法。它使用一个类似于时钟的数据结构来记录每个页面的访问情况。在CLOCK算法中,页面被分为两个类别:被访问过和未被访问过。当需要替换页面时,CLOCK算法会选择第一个未被访问过的页面进行替换,如果所有页面都被访问过,那么它会继续选择第一个未被访问过的页面。CLOCK算法并不关注页面被访问的次数,所以说D选项是错误的。
11.在页面置换策略中,(A)策略可能引起抖动。
A、FIFO
B、LRU
C、没有一种
D、所有
解析:堆栈型页面置换策略不会引起抖动,LRU属于堆栈型页面置换策略。而FIFO基于队列实现,不属于堆栈型页面置换策略。
12.在虚拟分页存储管理系统中,若进程访问的页面不在主存中,且主存中没有可用的空闲帧时,系统正确的处理顺序为(C).
A、决定淘汰页→页面调出→缺页中断→页面调入
B、决定淘汰页→页面调入→缺页中断→页面调出
C、缺页中断→决定淘汰页→页面调出→页面调入
D、缺页中断→决定淘汰页→页面调入→页面调出
解析:缺页中断→決定淘汰页→页面调出→页面调入
13.下列措施中,能加快虚实地址转换的是(C). Ⅰ.增大快表( TLB)容量 Ⅱ.让页表常驻内存 Ⅲ.增大交换区( swap )
A、仅Ⅰ
B、仅Ⅱ
C、仅I、Ⅱ
D、仅Ⅱ、Ⅲ
解析:快表存放在高速缓存中,增大快表相当于增大了高速缓存。会增速
页表从硬盘搬到内存中,内存的访问速度高于硬盘。也会增速
14.虚地址就是程序执行时所要访问的内存物理地址。该说法对还是错(A)
A、错
B、对
解析:虚地址通常指的是逻辑地址,而程序执行所要访问的内存地址指的是物理地址。
15.采用虚拟存储器的前提是程序的两个特点,—是程序执行时某些部分是互斥的、二是程序的执行往往具有( C )。
A、顺序性
B、并发性
C、局部性
D、并行性
16.系统“抖动”现象的发生是由(A )引起的。
A、置换算法选择不当
B、交换的信息量过大
C、内存容量充足
D、请求页式管理方案
17.虚拟存储技术不能以(A )为基础。
A、分区存储管理
B、段式存储管理
C、页式存储管理
D、段页式存储管理
解析:虚拟存储技术的出现,是建立在程序具有局部性的原理上的,虚拟内存只有在非连续存储管理中才存在:页式存储、段式存储、段页式存储。而分区管理,是一种连续存储管理的方案。
18.当系统发生抖动时,可以采取的有效措施是(A)。Ⅰ.撤销部分进程 Ⅱ.增加磁盘交换区的容量 Ⅲ.提高用户进程的优先级
A、仅Ⅰ
B、仅Ⅱ
C、仅I、Ⅱ
D、仅Ⅲ
解析:发生“抖动”的根本原因是:同时在系统中运行的进程太多 ,由此分配给每一个进程的物理块太少,不能满足进程正常运行的基本要求,致使每个进程在运行时,频繁地出现缺页,必须请求系统将所缺之页调入内 存。太多的话, 最直接有效的方法当然是撤销部分进程
19.在虚拟内存管理中,地址变换机构将逻辑地址转换为物理地址,形成逻辑地址的阶段是(B)。
A、编辑
B、编译
C、链接
D、装载
20.考虑页面置换算法,系统有m个物理块供调度,初始时全空,页面引用串长度为p,包 含了n个不同的页号,无论用什么算法,缺页次数不会少于(C).
A、m
B、p
C、n
D、min(m,n)
解析:无论采用什么页面置换算法,每种页面第一次访问时不可能再内存中,必然发生缺页,所以缺页次数大于等于n
21.设主存容量为1MB,外存容量为400MB,计算机系统的地址寄存器有32位,那么虚拟存储器的最大容量是(D).
A、1MB
B、401MB
C、1MB+4GB
D、4GB
解析:虚拟存储器的最大容量是由计算机的地址结构决定的,与主存容量和外存容量没有必然的联系,其虚拟地址空间为2^32B
22.在虚拟存储系统中,若进程在内存中占4块(开始时为空),采用最佳页面淘汰算法,当执行访问页号序列为1、2、3、4、5、3、4、1、6、7、8、7、8、9、7、8、9、5、4、5、4、2,时,将产生(A )次缺页中断。
A、11
B、8
C、9
D、10
解析:最佳置换算法(OPT)(理想置换算法):从主存中移出永远不再需要的页面;如无这样的页面存在,则选择最长时间不需要访问的页面。于所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。
最佳(Optimal)置换算法Belady于1966年提出的一种理论上的算法。选择“未来不再使用的”或“在最长时间内不再被访问的”页面被置换。通常可以获得最低的缺页率。这是一种理想情况,是实际执行中无法预知的,因而不能实现。可用作性能评价的依据。
| 1 |
|---|
| 1 2 |
| 1 2 3 |
| 1 2 3 4 |
| 1 5 3 4//2最长时间内不使用(下一次在末尾)||5 |
| 1 5 3 4//3 4 1存在不缺 |
| 6 5 3 4//1使用完毕 |||6 |
| 7 5 3 4//6使用完毕 ||7 |
| 7 5 8 4//3使用完毕 ||8 |
| 7 5 8 9//4最长时间内不使用 || 9 || 7 8不缺 ||7 8 9 5不缺 |
| 4 5 8 9//7使用完毕 ||4 || 5 4 不缺 |
| 2 5 8 9//完成||2 |
| 11次 |
23.在虚拟存储系统中,若进程在内存中占3块(开始时为空),采用最佳页面淘汰算法,当执行访问页号序列为1、2、3、4、1、2、5、1、2、3、4、5、6时,将产生(B )次缺页中断。
A、7
B、8
C、9
D、10
解析:
| 1 |
|---|
| 1 2 |
| 1 2 3 |
| 1 2 4//3最长时间内不使用 ||4 || 1 2不缺 |
| 1 2 5//4最长时间内不使用|| 5 ||1 2不缺 |
| 3 2 5//1使用完毕||3 |
| 4 2 5//3使用完毕||4||5不缺 |
| 6 2 5//4使用完毕||6 |
| 8次 |
24.在虚拟存储系统中,若进程在内存中占3块(开始时为空),采用最近最久未使用页面淘汰算法,当执行访问页号序列为1、2、3、4、1、2、5、1、2、3、4、5、6时,将产生(A )次缺页中断。
A、11
B、8
C、9
D、10
解析:最近最久未使用页面淘汰算法(LRU)选择内存中最近一段时间里较久未被访问的页面予以淘汰
| 1 |
|---|
| 1 2 |
| 1 2 3 |
| 4 2 3//1最近一段时间里较久未被访问||4 |
| 4 1 3//2最近一段时间里较久未被访问||1 |
| 4 1 2//3最近一段时间里较久未被访问||2 |
| 5 1 2//4最近一段时间里较久未被访问||5||1 2不缺 |
| 3 1 2//5最近一段时间里较久未被访问,1 2上面刚刚访问过||3 |
| 3 4 2//1最近一段时间里较久未被访问||4 |
| 3 4 5//2最近一段时间里较久未被访问||5 |
| 6 4 5//3最近一段时间里较久未被访问||6 |
| 11次 |
25.在虚拟存储系统中,若进程在内存中占4块(开始时为空),采用LRU页面淘汰算法,当执行访问页号序列为1、2、3、4、5、3、4、1、6、7、8、7、8、9、7、8、9、5、4、5、4、2,时,将产生(D )次缺页中断。
A、10
B、11
C、12
D、13
解析:
| 1 |
|---|
| 1 2 |
| 1 2 3 |
| 1 2 3 4 |
| 5 2 3 4//1最近一段时间里较久未被访问||5||3 4不缺 |
| 5 1 3 4//2最近一段时间里较久未被访问||1 |
| 6 1 3 4//3 4 1上面访问的||5最近一段时间里较久未被访问||6 |
| 6 1 7 4//4在3后访问的,1在4后访问的||4最近一段时间里较久未被访问||7 |
| 6 1 7 8//4最近一段时间里较久未被访问||8||7 8不缺 |
| 6 9 7 8//6与1相比先1后6||1最近一段时间里较久未被访问||9||7 8 9不缺 |
| 5 9 7 8//6最近一段时间里较久未被访问||7 8 9上面刚刚访问的||5 |
| 5 9 4 8//7最近一段时间里较久未被访问||7先被访问的||4||5 4不缺 |
| 5 9 4 2//8最近一段时间里较久未被访问||8与9,8先访问的||2 |
| 13次缺页 |
26.在请求分页存储管理中,若采用FIFO页面淘汰算法,则当分配的页面数增加时,缺页中断的次数( D ) 。
A、减少
B、增加
C、无影响
D、可能增加也可能减少
解析:随着内存的增大:缺页次数增加的现象:称之为 Belady 现象(异常现象);我们都知道常用的页面淘汰算法有五种:
| 1: | FIFO | 先进先出 |
|---|---|---|
| 2: | LRU | 最近最久未用置换算法 |
| 3: | LFU | 最近访问频率最低的 |
| 4: | NUR | 最近没有使用页面淘汰算法(NUR) |
| 5: | OPT | 理想的淘汰算法 |
这五种算法可见简单的将其分为两类,堆栈型算法和非堆栈型算法;
注意:堆栈型算法:最新压入到堆栈中的永远在栈顶;栈顶是刚刚访问过的,栈底是最久没有访问过的;
LRU和LFU都是堆栈型算法, OPT 也是堆栈算法; 但是FIFO非堆栈型算法 ;非堆栈式算法可能出现 Belady问题,是栈式算法不会出现类似问题;
27.虚拟存储管理系统的基础是程序的( A )原理。
A、局部性
B、全局性
C、动态性
D、虚拟性
28.请求分页存储管理中,若把页面尺寸增大一倍而且可容纳的最大页数不变,则在程序顺序执行时缺页中断次数会(D).
A、增加
B、减少
C、不变
D、可能增加也可能减少
解析:缺页中断的次数取决于操作系统内核的相关结构以及实际运行情况。因为系统中,缺页中断次数和页面大小有些关系,但并不只取决于页面大小,还跟系统总内存总量等很多因素有关,当系统内存不足时,会发生页面交换,此时也会产生很多次缺页中断,但与页面大小就没有太大关系了。
29.测得某个采用按需调页策略的计算机系统的部分状态数据为:CPU利用率为20%,用于交换空间的磁盘利用率为97.7%,其他设备的利用率为5%。由此判断系统出现异常,这种情况下(D)能提高系统性能。
A、安装一个更快的硬盘
B、通过扩大硬盘容量增加交换空间
C、增加运行进程数
D、加内存条来增加物理空间容量
解析:用于交换空间的磁盘利用率为97.7%,其他设备的利用率为5%
CPU利用率低,对换空间的磁盘利用率高,说明程序进出内存频率高,很可能是内存抖动,此时需要增大物理内存空间,或者降低运行进程数。
大部分的运行时间都耗费在交换操作上,也就是说物理内存太小导致数据经常需要换入换出,因此需要提高内存大小,此外CPU和IO的的占用率都很低表示CPU一次读取的太多的程序放入内存中,因此需要降低多道程序的度数(个数)
CPU利用率:运行的程序占用的CPU资源,表示机器在某个时间点的运行程序的情况。使用率越高,说明机器在这个时间上运行了很多程序,反之较少。
CPU是负责运算和处理的,内存是交换数据的。
1.可以看出CPU利用率低;3.I/O设备利用率低(减少多道程序的度数)
CPU一次读取的太多的程序放入内存中,因此需要降低多道程序的度数
2.交换空间的磁盘利用率高(增大内存的容量)
交换空间利用率高,因此需要扩大数据交换空间(增大内存的容量)
30.在页面调度中,有一种调度算法采用堆栈方法选择(B )
A、最先装入主页的页
B、最近最少用的页
C、最近最不常用的页
D、最晚装入的页
解析: LRU和LFU都是堆栈型算法, OPT 也是堆栈算法;最近最久未用置换算法 , 最近访问频率最低的 , 最近没有使用页面淘汰算法
第六章 虚拟存储器管理
1.通常I/O软件的层次结构的模型是什么?A
A、用户层软件,设备独立性软件,设备驱动程序,中断处理程序
B、用户层软件,设备驱动程序,硬件,操作系统
C、应用层,网络层,传输层,数据链路层
D、以上答案都不对
解析:I/O软件的层次可分为用户层软件、设备独立性软件、设备驱动程序、中断处理程序和硬件。其中设备独立性软件、设备驱动程序、中断处理程序属于操作系统的内核部分,即“I/O系统”或“I/O核心子系统”。
2.关于SPOOLing技术说法错误的是?D
A、SPOOLing技术是Simutaneaus Periphernal operations On-line 或假脱机操作
B、SPOOLing技术是对脱机输入、输出操作的模拟
C、将独享设备转变为具有共享特征的虚拟设备
D、以上答案均不对
解析;ABC都对
3.I/O控制方式中哪种传输效率最高?B
A、轮询的可编程I/O控制方式
B、中断驱动的I/O控制方式
C、DMA的I/O控制方式
D、其他
解析:CPU的I/O传送控制方式中,效率高、实时性强的方式是 中断传送
CPU的I/O传送控制方式中,传送速度最快的方式为 DMA传送
4.在下列磁性材料组成的存储器件中,(D)不属于辅助存储器
A、磁盘
B、磁带
C、光盘
D、磁芯
解析:计算机的存储系统可以分为:
辅存: 辅助存储器,也叫外存储器,读取速度最慢,容量最大,价格最低。其实辅存可以被看作外设。
主存: 也叫内存,位于主板上,CPU可以直接从内存中读取数据。(实际操作中其实是CPU先去缓存cache中找数据,找不到再去内存读,一般找到的概率高于90%,但这一过程对于用户是透明的。)主存的读写速度高于辅存(能达到1000倍),但容量小于辅存。
缓存: cache,位于CPU内部,速度很快,是主存读取速度的10倍,但容量很小,价格贵。
CPU内部寄存器: CPU包括运算器和控制器,其中的寄存器有数据寄存器DR,地址寄存器AR,程序计数器PC,指令寄存器IR等。
辅存可分为以下三类:磁表面存储器、光存储器、半导体存储器辅助储存器提供一个更大的空间来储存数据, 如硬盘,磁盘、光盘等.
5.下列说法不正确的是(A)。
A、语音合成器作为输入/输出设备可将人的语言声音转成计算机能够识别的信息
B、点阵式打印机点阵的点越多,印字质量越高
C、非击打式打印设备速度快、噪声低、印字质量高,但价格较高
D、行式打印机的速度比串行打印机快
解析:语音合成器并不是将语言声音转成计算机识别的信息。
6.若磁盘的转速提高一倍,则(D)
A、平均存储时间减半
B、平均等待时间减半
C、存储密度可以提高一倍
D、平均定位时间不变
解析:首先要明白,磁盘的盘面被分成多各同心圆,这些圆称为磁道,磁道之间留有空隙。磁道被分成一段一段,称为扇区,大小相当于一个盘块。 磁盘启动时,磁头首先处于0磁道,磁盘从接到命令到向目标扇区读取或写入数据完毕共经历三个阶段: 第一阶段,磁头沿径向移动,移到目标扇区所在磁道的上方(注意,不是目标扇区,而是目标扇区所在的磁道),这段时间称为寻道时间,目标扇区所在磁道跟0磁道的远近不同寻道时间也不一样。这个时间是随机变化的,因此用平均值来表示。最大寻道时间和最小寻道时间的平均值称为平均寻道时间,有的书上称为平均定位时间,约为10毫秒。 第二阶段,找到目标磁道后通过盘片的旋转,使得要目标扇区转到磁头的下方,这段时间称为旋转延迟时间,取最大最小的平均值即旋转半周的时间作为平均旋转延迟时间,有的书上称为平均等待时间。比如,一个7200(转/每分钟)的硬盘,每旋转一周所需时间为60×1000÷7200=8.33毫秒,则平均旋转延迟时间为8.33÷2=4.17毫秒。 第三阶段,向目标扇区读取或写入数据,时间约为零点几个毫秒。 由此可见,第三阶段所耗时间相对第一、二阶段可以忽略不记。于是将平均寻道时间与平均旋转延迟时间之和称为平均存取时间。决定一个磁盘读写速度的是它的平均存取时间。 可见,当磁盘的转速改变时,由于平均寻道时间与磁盘转速无关,所以它不变。磁盘的转速提高一倍,只是平均旋转延迟时间减半。寻道速度和读写(数据传输)速度不是一个概念,寻道是指磁头从一个磁道到另一个磁道,相当于磁头做圆的径向运动,而读写磁道是沿圆周运动。 因此磁盘转速提高只是提高了读写(数据传输)速度,而磁头的摆动速度并没有提高。
7.活动头磁盘存储器的找道时间通常是指(C)
A、最大找道时间
B、最小找道时间
C、最大找道时间和最小找道时间的平均值
D、最大找道时间和最小找道时间的和
8.软盘驱动器采用的磁头是(B)
A、浮动式磁头
B、接触式磁头
C、固定式磁头
D、以上都不对
9.在存储单元和I/O设备统一编址的方式下,存储单元和I/O设备是依据(A)来区分的。
A、不同的地址码
B、不同的地址线
C、不同的数据线
D、不同的控制线
10.中断系统是由(C)实现的
A、硬件
B、软件
C、硬件和软件结合
D、以上都不对
解析:中断装置和中断处理程序统称为中断系统。中断系统是计算机的重要组成部分,由硬件与软件结合实现的。中断分为硬件中断与软件中断。
11.为实现多重中断,保护断点和现场使用(D)
A、ROM
B、中断向量表
C、设备内的存储器
D、堆栈
解析;断点可以保存在堆栈中,由于堆栈先进后出的特点,依次将程序的断点压入堆栈中。出栈时,按相反顺序便可准确返回到程序间断处。
12.中断允许触发器用来(D)
A、表示外设是否提出了中断请求
B、CPU是否响应了中断请求
C、CPU是否正在进行中断处理
D、开放或关闭可屏蔽中断
解析:允许中断触发器是系统内部的一个自动化的器件,用于更改状态量,即开中断表示当前可以中断,关中断表示当前正在中断中。
13.外围设备提出中断请求的条件是(C)
A、一个CPU周期结束
B、总线空闲
C、外围准备就绪且系统允许中断
D、CPU开放中断系统
14.中断向量可提供(D)
A、被选中的设备的地址
B、传送数据的起始地址
C、主程序的断点地址
D、中断服务程序入口地址
解析:中断向量就是中断服务子程序的入口地址
15.带有处理机的终端一般称为(C)
A、交互式终端
B、远程终端
C、智能终端
D、以上都不是
16.通道程序是由(B)组成
A、I/O指令
B、通道控制字
C、通道状态字
D、以上都不对
解析:通道的功能是 通过解释并执行 由它特有的 通道指令 组成的通道程序 实现对外部设备的控制。
17.若一个8位组成的字符至少需要10位来传送,这是(B)传送方式
A、同步
B、异步
C、并联
D、混合
解析:异步:在异步传输方式中,每传送一个字符(7或8位)都要在每个字符码前加1个起始位,以表示字符代码的开始;在字符代码和效验码后面加1或2个停止位,表示字符结束。接收方根据起始位和停止位来判断一个新字符的开始和结束,从而起到通信双方的同步作用。
同步:同步传输方式是以数据块为传输单位。每个数据块的头部和尾部都要附加一个特殊的字符或比特序列,标记一个数据块的开始和结束,一般还要附加一个校验序列(如16位或32位CRC校验码),以便对数据块进行差错控制。所谓同步传输是指数据块与数据块之间的时间间隔是固定的,必须严格地规定它们的时间关系。
18.计算机的外围设备是指(D)
A、输入/输出设备
B、外存储器
C、输入/输出设备及外存储器
D、除了CPU和内存以外的其他设备
19.磁盘设备的I/O控制主要是采取( D )方式。
A、位
B、帧
C、字节
D、DMA
解析:磁盘是高速外设,以块为单位传送数据,需要DMA控制传输
DMA方式是一种完全由硬件执行I/O数据交换的工作方式。
20.为了便于上层软件的编制,设备控制器通常需要提供(A )。
A、控制寄存器、状态寄存器和控制命令
B、I/O地址寄存器、工作方式状态寄存器和控制命令
C、中断寄存器、控制寄存器和控制命令
D、控制寄存器、编程空间和控制逻辑寄存器
21.在设备控制器中用于实现设备控制功能的是(C)
A、CPU
B、设备控制器与处理器的接口
C、I/O逻辑
D、设备控制器与设备的接口
22.在设备管理中,设备映射表的作用是(D)
A、管理物理设备
B、管理逻辑设备
C、实现输入/输出
D、建立逻辑设备与物理设备的对应关系
23.DMA方式是在(C)之间建立一条直接数据通路
A、CPU与外设
B、CPU与主存
C、主存与外设
D、外设与外设
24.通道又称I/O处理机,它用于实现(A)之前的信息传输。
A、内存与外设
B、CPU与外设
C、内存与外存
D、CPU与外存
解析:通道是为了绕过CPU,让主存和I/O设备直接经行信息传输。
25.在操作系统中,(A)是指的一种硬件机制
A、通道技术
B、缓冲区
C、Spooling技术
D、内存覆盖技术
解析:通道相当于I/O处理机,是由通道处理机执行通道程序实现的
缓冲池是操作系统划分出来的用于数据缓冲的存储器,是由软件实现的
同样SPOOLING技术也是由操作系统软件实现的机制,当中最主要的是模拟输入/输出进程
内存覆盖也由操作系统实现
26.若I/O设备与存储设备进行数据交换不经过CPU来完成,则这种数据交换方式是(C)
A、中断控制方式
B、程序I/O方式
C、DMA控制方式
D、无条件存取方式
解析:DMA不同于中断,不经过CPU
27.在下列问题中,(A)不是设备分配中应考虑的问题
A、及时性
B、设备的固有属性
C、设备的无关性
D、安全性
28.I/O系统与高层之间的接口中,根据设备类型的不同,可分为哪些接口?BCD
A、用户接口
B、块设备接口
C、流设备接口
D、网络通信接口
解析:在I/O系统与高层之间的接口中,根据设备类型的不同,又进一步分为若干个接口。比如块设备接口、流设备接口和网络接口。
29.I/O接口访问控制的方式有哪些?ABCD
A、轮询的编程I/O控制方式
B、基于中断的I/O控制方式
C、DMAI/O控制方式
D、I/O通道的控制方式
30.I/O传输中引入缓冲区的目的是:ABC
A、提高CPU和I/O设备之间的并行性
B、减少对CPU的中断频率,放宽对CPU中断响应时间的限制
C、缓和CPU和I/O设备速度不匹配的的矛盾
D、为了提高CPU的速度
解析:引入缓冲技术的主要目的是为了缓和CPU和I/O设备的不匹配,减少对CPU的中断频率,提高CPU和I/O设备的并行性。
为了缓和CPU和I/O设备速度不匹配的矛盾,提高CPU和I/O设备的并行性,在现代操作系统中,几乎所有的I/O设备在与处理机交换数据时都用了缓冲区,并提供获得和释放缓冲区的手段。
1、改善CPU与I/O设备间速度不匹配的矛盾
例如一个程序,它时而进行长时间的计算而没有输出,时而又阵发性把输出送到打印机。由于打印机的速度跟不上CPU,而使得CPU长时间的等待。如果设置了缓冲区,程序输出的数据先送到缓冲区暂存,然后由打印机慢慢地输出。
这时,CPU不必等待,可以继续执行程序。实现了CPU与I/O设备之间的并行工作。事实上,凡在数据的到达速率与其离去速率不同的地方,都可设置缓冲,以缓和它们之间速度不匹配的矛盾。众所周知,通常的程序都是时而计算,时而输出的。
2、 可以减少对 CPU的中断频率,放宽对中断响应时间的限制
如果I/O操作每传送一个字节就要产生一次中断,那么设置了n个字节的缓冲区后,则可以等到缓冲区满才产生中断,这样中断次数就减少到1/n,而且中断响应的时间也可以相应的放宽。
第七章 输入输出系统
1.文件系统是指( D )。
A、文件的集合
B、文件的目录集合
C、实现文件管理的一组软件
D、文件、管理文件的软件及数据结构的总体
2.文件系统的主要目的是( D )。
A、用于存储系统文件
B、实现虚拟存储
C、实现对文件的随机存取
D、实现对文件的按名存取
3.文件管理实际上是对( B )的管理。
A、主存空间
B、辅存空间
C、逻辑地址空间
D、物理地址空间
解析:辅存空间(也称为二级存储)是计算机系统中用于存储文件和数据的非易失性存储介质,如硬盘驱动器。文件管理涉及到对文件的创建、组织、存储、检索、删除等操作,这些操作都是在辅存空间上进行的。
4.下列文件的物理结构中,不利于文件长度动态增长的文件物理结构是( A )。
A、顺序文件
B、链接文件
C、索引文件
D、系统文件
解析;顺序结构的优点是访问速度快,缺点是文件长度增加困难。
链式结构的优点是文件长度容易动态变化,其缺点是不适合随机存取访问。
索引结构的优点是访问速度快,文件长度可以动态变化。缺点是存储开销大,限制了文件的最大长度。
Hash结构:只适用于定长记录文件和按记录键随机查找的访问方式
Hash结构的思想是:通过计算来确定一个记录在存储设备上的存储位置,依次先后存入的两个记录在物理设备上不一定相邻。
5.面向用户的文件组织机构属于( C)。
A、虚拟结构
B、实际结构
C、逻辑结构
D、物理结构
6.文件目录的主要作用是(A )。
A、实现文件按名存取
B、提高查找文件速度
C、节省文件存储空间
D、提高外存利用率
7.文件系统采用树型目录结构后,对于不同用户的文件,其文件名(C )。
A、应该相同
B、应该不同
C、可以不同,也可以相同
D、受系统约束
解析:树形目录的引入提高了检索的效率,解决了文件的重名问题,即允许不同的用户使用相同的文件名。因此,对于不同用户文件而言其文件名既可以相同也可以不同。
8.下列描述不是文件系统功能的是( C )。
A、建立文件目录
B、提供一组文件操作
C、实现对磁盘的驱动调度
D、实现从逻辑文件到物理文件间的转换
解析:文件系统是操作系统中负责管理和存取文件信息的软件机构。它负责文件操作和管理的程序模块、所需的数据结构(如目录表、文件控制块、存储分配表)以及访问文件的一组操作所组成。
主要功能:
从用户角度来看
1、 用户可以执行创建、修改、删除、读写文件命令。
2、 用户能以合适的方式构造自己的文件。
3、 用户能在系统的控制下,共享其他用户的文件。
4、 允许用户用符号名访问文件。
从系统角度看
1、 系统转存和恢复文件的能力,以防止意外事故的发生。
2、 提供可靠的保护以及保密措施。
3、 负责文件的存储并对存入的文件进行保护、检索
4、 负责对文件存储空间的组织和分配。
文件系统的功能包括:管理和调度文件的存储空间,提供文件的逻辑结构、物理结构和存储方法;实现文件从标识到实际地址的映射,实现文件的控制操作和存取操作,实现文件信息的共享并提供可靠的文件保密和保护措施,提供文件的安全措施。
9.按文件用途来分,编译程序属于( C )。
A、用户文件
B、档案文件
C、系统文件
D、库文件
10.文件代表了计算机系统中的(C )。
A、硬件
B、软件
C、软件资源
D、硬件资源
11.文件系统采用二级文件目录可以(D )。
A、缩短访问存储器的时间
B、实现文件共享
C、节省内存空间
D、解决不同用户间的文件命名冲突
解析:在二级文件目录中,各文件的说明信息被组织成目录文件,且以用户为单位把各自的文件说明划分为不同的组。这样,不同的用户可以使用相同的文件名,从而解决了文件的重名问题。
12.在UNIX系统中,用户程序经过编译之后得到的可执行文件属于(B )。
A、ASCII文件
B、普通文件
C、目录文件
D、特别文件
13.特殊文件是与( D)有关的文件。
A、文本
B、图像
C、硬件设备
D、二进制数据
14.文件的存储方法依赖于( C )。
A、文件的物理结构
B、存放文件的存储设备的特性
C、A和B
D、文件的逻辑结构
解析:文件的结构就是文件的组织形式,从用户观点所看到的文件组织形式成为文件的 逻辑结构,从实现观点看到的的文件在外存上的存放形式称为文件的物理结构,文件的逻辑结构与存储设备特性无关,但文件的物理结构与存储设备的特性有很大关系。
15.多级目录结构形式为(D )。
A、线形结构
B、散列结构
C、网状结构
D、树型结构
16.树型目录结构的主文件目录称为(B )。
A、父目录
B、根目录
C、子目录
D、用户文件目录
17.使用绝对路径名访问文件是从( C )开始按目录结构访问某个文件。
A、当前目录
B、用户主目录
C、根目录
D、父目录
18.由字符序列组成,文件内的信息不再划分结构,这是指( A )。
A、流式文件
B、记录式文件
C、顺序文件
D、有序文件
解析:根据文件的逻辑结构可分为记录式文件和流式文件。流式文件的记录是以字节或字符为单位,其输入输出的数据流的开始和结束仅受程序控制而不受物理符号(如回车换行符等)控制,简单来说,流文件就是没有结构的文件;记录式文件由若干逻辑记录组成,每条逻辑记录又有相同的数据项组成。
19.数据库文件的逻辑结构形式是( C )。
A、字符流式文件
B、档案文件
C、记录式文件
D、只读文件
20.逻辑文件是(B)文件的组织形式。
A、在外部设备上
B、从用户观点看
C、虚拟存储
D、目录
21.可顺序存取的文件不一定能随机存取。 正确
解析:可顺序存取的文件不一定能随机存取,但是,凡可随机存取的文件都可以顺序存取。
22.在文件系统管理中,可以用串联文件存储结构来实现直接存取。 正确
23.采用树形目录结构的文件系统中,各用户的文件名必须互不相同。错误
解析;树形目录结构已解决重名问题
24.顺序文件适合于建立在顺序存储设备上,而不适合建立在磁盘上。 错误
解析:题干中磁盘也属于顺序存储设备
顺序文件和随机文件是说的文件的读取方式,不是说文件的类型。 比如按行存入的文本文件可以按行进行顺序文件读写,也可以进行随机文件读写 但是随机文件读写会出问题,你解析出来的字符串是错的。 和顺序存储设备相对的是随机存储设备,顺序存储设备比如说磁带,你只能把前面的存满了再存后面的,而常用的硬盘你可以这个扇区存一点那个扇区存一点,这叫做随机存储设备。顺序文件也可以存储在随机存储设备上,因为文件系统会屏蔽掉你访问时的差异
1.文件按逻辑结构分为,无结构文件(流式文件即二进制文件)和有结构文件(记录式文件) 2.有结构文件又可分为,①顺序文件(顺序文件可分为串结构和顺序结构),②索引文件(原来的记录可以无序),③索引顺序文件(原来的记录必须有序),④直接文件或者叫hash文件,与索引文件的区别是,索引文件需要建立索引表,hash文件直接使用hash函数计算出存储位置 3.文件按物理结构分为,①连续文件结构(连续分配方式),②串联文件结构(链接分配方式)③索引文件结构(索引分配方式) 4.可以看到逻辑结构讲究怎么使用,物理结构讲究怎么存储,怎么分配
25.在文件系统的支持下,用户操作文件不需要知道文件存放的物理地址。 正确
26.在磁盘上的顺序文件中插入新的记录时,必须复制整个文件。 正确
27.文件的具体实现是操作系统考虑的范畴,因而用户不必关心。 错误
28.随机访问文件也能顺序访问,但一般效率较差。 正确
29.UNIX的i节点是文件内容的一部分。 错误
解析;每个 文件系统 分为3部分:超级块,i-节点表,数据区 。
超级块 :存放文件系统本身的信息,比如记录了每个区域的大小,或未被使用的磁盘块的信息。(不同版本稍有差别)
i-节点表 :每个文件都有其属性,大小,最近修改时间等等,这些被存储在ino_t 的结构体中,所有的i-节点都有一样的大小,i-节点表就是这样一些节点的列表。
(表中的每个i-节点都通过位置来标志,例如标志为2的i-节点位于文件系统i-节点表中的第3个位置 )
数据块 :存放文件内容,因为块的大小一定,所以有时一个文件会分布在多个磁盘上。
30.在Windows系统中,是采用单空闲块链接法实施存储空间的分配与回收。
31.目前操作系统常采用的文件的物理结构有()、()和()。ABC
A、顺序结构
B、链接结构
C、索引结构
D、索引顺序结构
32.一级文件目录结构不能解决(B )的问题。多用户系统所用的文件目录结构至少应是(C )。
A、文件存取
B、文件重名
C、二级目录文件
D、树形目录结构
33.文件的结构就是文件的组织形式。从用户观点出发所看到的文件组织形式称为文件的( B),从实现观点出发,文件在外存上存放的组织形式称为文件的(D )。
A、逻辑文件
B、逻辑结构
C、物理文件
D、物理结构
34.按文件的逻辑存储结构分,文件分为(A )文件和(B )文件,又称为(C )文件和(D )文件。
A、有结构文件
B、无结构文件
C、记录式文件
D、流式文件
35.按保护级别分类,文件可分为(A)、(B)和(C)三种。
A、可执行文件
B、读写文件
C、只读文件
D、只写文件
第八章 文件管理
1.在下列磁盘调度算法中,只有(D ) 考虑I/O请求到达的先后次序。
A、最短查找时间优先调度算法
B、电梯调度算法
C、单向扫描调度算法
D、先来先服务调度算法
2.管理空闲磁盘空间可以用(C ),它利用二进制的一位来表示一个磁盘块的使用情况。
A、空闲块表
B、空闲快链
C、位示图
D、分组链接
3.位示图用于( D )。
A、文件目录的查找
B、文件的保护和保密
C、主存空间的共享
D、磁盘空间的管理
解析:位示图主要用于磁盘空间的管理,用二进制表示磁盘的使用的使用情况,0 表示对应的磁盘块空闲,1表示对应的磁盘块已经分配!
4.在对磁盘进行读/写操作时,下面给出的地址参数中,(C ) 是不正确的。
A、柱面号
B、磁头号
C、设备号
D、扇区号
5.Windows系统的FAT文件系统支持(B )结构。
A、顺序文件
B、链接文件
C、索引文件
D、散列文件
6.下面的( A)不是文件的存储结构。
A、记录式文件
B、连续文件
C、串联文件
D、索引文件
解析:文件的物理结构(又称文件的存储结构)
1)顺序结构文件
2)链接结构文件
3)链接结构文件
\4) Hash文件
7.在UNIX系统中,磁盘存储空间空闲块的链接方式是(D )。
A、单块链接
B、位示图法
C、顺序结构
D、成组链接
解析:成组链接法是Unix系统中常见的管理空闲盘区的方法。
在UNIX系统中,将空闲块分成若干组,每100个空闲块为一组,每组的第一空闲块登记了下一组空闲块的物理盘块号和空闲块总数。如果一个组的第二个空闲块号等于0,则有特殊的含义,意味着该组是最后一组,即无下一个空闲块。
1.分配空闲块的时候,从前往后分配,先从第一组开始分配,第一组空闲的100块分完了,才进入第二组。
2.释放空闲块的时候正好相反,从后往前分配,先将释放的空闲块放到第一组,第一组满了,在第一组前再开辟一组,之前的第一组变成第二组。
8.设磁盘的每块可以存放512个字节。现有一长度为3000个字节的流式文件要存储在磁盘上,该文件至少用(C)块。
A、4
B、5
C、6
D、8
解析:3000/512=5.8
9.在文件管理中,采用位示图主要是实现(B )。
A、磁盘的驱动调度
B、磁盘空间的分配和回收
C、文件目录的查找
D、页面置换
10.EXT2文件系统支持(C)结构
A、顺序文件
B、链接文件
C、索引文件
D、目录文件
解析;https://blog.51cto.com/u_15346415/3671742
11.最适合顺序存取的文件是(B)
A、索引文件
B、顺序文件
C、链接文件
D、记录式文件
解析:顺序文件 (Sequential File)是记录按其在文件中的逻辑顺序依次进入存储介质而建立的,即顺序文件中物理记录的顺序和逻辑记录的顺序是一致的。
12.最适合随机存取的文件是(A)。
A、索引文件
B、 顺序文件
C、链接文件
D、记录式文件
解析:索引文件由数据文件组成,它是带索引的顺序文件。索引本身非常小,只占两个字段;顺序文件的键和在磁盘上相应记录的地址。
13.(C )的物理结构对文件随机存取时必须按指针进行,但效率较低。
A、索引文件
B、连续文件
C、链接文件
D、多级索引文件
解析:顺序不需要指针,索引和多级索引虽然需要指针,但是速度要比链式快一些
14.设某系统磁盘共有500块,块编号为0-499,若用位示图法管理这500块的盘空间,则当字长为32位时,位示图需要多少个字? A
A、16
B、32
C、64
D、8
解析:一个字有32位,可以管理32个物理块。500除以32=15.625,向上取整,所以是16个字;
15.在以下文件的物理结构中,不利于文件长度动态增长的是(A)。
A、连续结构
B、链接结构
C、索引结构
D、散列结构
解析:顺序(连续)结构的优点是访问速度快,缺点是文件长度增加困难。
链式结构的优点是文件长度容易动态变化,其缺点是不适合随机存取访问。
索引结构的优点是访问速度快,文件长度可以动态变化。缺点是存储开销大,限制了文件的最大长度。
Hash结构:只适用于定长记录文件和按记录键随机查找的访问方式
Hash结构的思想是:通过计算来确定一个记录在存储设备上的存储位置,依次先后存入的两个记录在物理设备上不一定相邻。
16.文件系统中若文件的物理结构采用连续结构,则FCB中有关文件的物理位置的信息应包括(B)。 I.首块地址 II.文件长度 III.索引表地址
A、I
B、I和II
C、II和III
D、I和III
解析:文件的顺序结构是一种最简单的物理结构,只要知道文件在存储设备上的起始地址(首块号)和文件长度(总块数)就能很快地进行存取。
17.位示图可用于(B)。
A、文件目录的查找
B、磁盘空间的管理
C、主存空间的管理
D、文件的保密
18.物理文件的组织方式是由(D)确定的。
A、应用程序
B、主存容量
C、外存容量
D、操作系统
19.假定磁盘的旋转速度是10ms/周,每个磁道被划分成大小相等的4块,那么,传送一个信息块的所需时间为(D)
A、4ms
B、5ms
C、10ms
D、2.5ms
解析:存取时间 = 寻道时间 + 等待时间(平均定位时间+旋转延迟时间,又称为旋转延迟时间)
磁盘旋转是一个不会停下来的匀速旋转的过程,所以周期为 10ms时,平均每个物理块的读取时间为10/4=2.5ms. 这 2.5ms 即为平均定位时间。
20.有4个按时间次序排列的磁道请求,序列如下:
(1)95,185,5,25,50,10,82,70,90,15
(2)35,65,70,185,100,125,130,95,20,15
(3)5,15,35,125,50,130,60,70,80,20
(4)90,15,25,125,10,130,82,70,100,20
如果磁头的初始位置在85号磁道上,最短寻道优先算法和电梯调度算法得到的服务序列完全一致的是(B)。
解析:最短寻道优先算法
根据最短寻道时间优先磁盘调度算法,每次在寻找下一个磁道时,都要选择离自己最近的,所以当前磁头位于85号,下一道选择与85绝对值最小的
即
| 被访问的下一个磁道号 | 移动距离(磁道数) |
|---|---|
| 82 | 3 |
| 90 | 8 |
| 95 | 5 |
| 70 | 75 |
| 50 | 20 |
| 25 | 25 |
| 15 | 10 |
| 10 | 5 |
| 5 | 5 |
| 185 | 180 |
电梯调度算法
优先考虑磁头的当前移动方向,并且考虑当前磁道与下一磁道之间的距离。例如,当磁头正在自里向外移动时,扫描算法所选择的下一个访问对象应该是,即在当前磁道之外,又距离最近。这样自里向外的访问,直到再无更外的磁道需要访问才将磁臂换向,自外向里移动。移动原则同前一致。下面贴出这一段的来源浅谈磁盘调度算法
由于这种算法中磁头移动的规律与电梯的运行相似,因此又称为电梯调度算法。
| 从85向磁道号增加的方向 | 反方向 |
|---|---|
| 90 | 82 |
| 95 | 70 |
| 185 | 50 |
| 25 | |
| 15 | |
| 10 | |
| 5 |
2)
| 95 | |
|---|---|
| 100 | |
| 125 | |
| 130 | |
| 185 | |
| 70 | |
| 65 | |
| 35 | |
| 20 | |
| 15 |
| 从85向磁道号增加的方向 | 反方向 |
|---|---|
| 95 | 70 |
| 100 | 65 |
| 125 | 35 |
| 130 | 20 |
| 185 | 15 |
3)
| 80 | |
|---|---|
| 70 | |
| 60 | |
| 50 | |
| 35 | |
| 20 | |
| 15 | |
| 5 | |
| 125 | |
| 130 |
| 从85向磁道号增加的方向 | 反方向 |
|---|---|
| 125 | 80 |
| 130 | 70 |
| 60 | |
| 50 | |
| 35 | |
| 20 | |
| 15 | |
| 5 |
4)
| 82 | |
|---|---|
| 90 | |
| 100 | |
| 125 | |
| 130 | |
| 70 | |
| 25 | |
| 20 | |
| 15 | |
| 10 |
| 从85向磁道号增加的方向 | 反方向 |
|---|---|
| 90 | 82 |
| 100 | 70 |
| 125 | 25 |
| 130 | 20 |
| 15 | |
| 10 | |
#define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> #include<time.h> #include<Windows.h> /*先来先服务 (FCFS)*/ void FCFS(int a[], int n) { int sum = 0, i, j, now; printf("请输入当前磁道号:\n"); scanf("%d", &now); sum += abs(a[0] - now); printf("从当前位置到第1个磁道移动的磁道数:\t%d\n", sum); for (i = 0, j = 1; j < n; j++, i++){ sum += abs(a[j] - a[i]); printf("从第%d磁道到第%d磁道移动的磁道数:\t%d\n", i + 1, j + 1, abs(a[j] - a[i])); } printf("移动的总磁道数:%d\n", sum); printf("移动的平均磁道数:%.2lf\n", 1.0*sum / n); printf("请再次输入你想使用的方法:\n"); } /*最短寻道时间函数SSTF*/ void SSTF(int a[], int n){ int temp; int now; int sum = 0, i, j, k=0; printf("排序后的磁道分布:\n"); //冒泡排序法对磁道号进行排序 for (i = 0; i < n; i++){ for (j = i + 1; j < n; j++){ if (a[i]>a[j]){ temp = a[i]; a[i] = a[j]; a[j] = temp; } } printf("%d \t", a[i]); if (i % 10 == 9){ printf("\n"); } } printf("\n"); printf("请输入当前磁道号:\n"); scanf("%d", &now); if (a[0] >=now){ printf("当前访问的磁道%d\n", a[0]); for (i = 0; i < n-1; i++){ printf("当前访问的磁道:\t%d\n",a[i+1]); } sum = a[n - 1] - now; printf("移动的总磁道数:%d\n", sum); } else if (a[n - 1] <= now){ printf("当前访问的磁道:%d\n", a[n-1]); for (j=n-1; i<n-1;j--){ printf("当前访问的磁道:\t%d\n",a[j-1]); } sum = now-a[0]; printf("移动的总磁道数:%d\n", sum); } else{ while (a[k] < now){ k++; } j = k-1; i = 0; while ((j>=0)&&(k<n)){ i++; if (now - a[j] >= a[k] - now){ printf("当前访问的磁道:\t%d\n", a[k]); sum += a[k] - now; now = a[k]; k++; } else{ printf("当前访问的磁道:\t%d\n", a[j]); sum += now - a[j]; now = a[j]; j--; } } if (k > n-1){ for (int t = j; t > 0; t--){ i++; if (t == j){ printf("当前访问的磁道:\t%d\n",a[j]); } else{ printf("当前访问的磁道:\t%d\n", a[t+1]); } } sum += a[n - 1] - a[0]; } if (j <0){ for (int t = k; t < n; t++){ i++; if (t == k){ printf("当前访问的磁道:\t%d\n",a[k]); } else{ printf("当前访问的磁道:\t%d\n",a[t]); } } sum += a[n - 1] - a[0]; } } printf("经过的总磁道数为:%d\n", sum); printf("移动的平均磁道数:%.2lf\n", 1.0*sum / n); printf("请再次输入你想使用的方法:\n"); } /*扫描算法*/ void SCAN(int a[], int n){ int temp; int now; int sum = 0, i, j, k = 0; printf("排序后的磁道分布:\n"); //冒泡排序法对磁道号进行排序 for (i = 0; i < n; i++){ for (j = i + 1; j < n; j++){ if (a[i]>a[j]){ temp = a[i]; a[i] = a[j]; a[j] = temp; } } printf("%d \t", a[i]); if (i % 10 == 9){ printf("\n"); } } printf("\n请输入当前磁道号:\n"); scanf("%d", &now); if (a[0] >= now){ printf("当前访问的磁道:%d\n", a[0]); for (i = 0; i < n - 1; i++){ printf("当前访问的磁道:\t%d\n", a[i + 1]); } sum = a[n - 1] - now; printf("移动的总磁道数:%d\n", sum); } else if (a[n - 1] <= now){ printf("当前访问的磁道:%d\n", a[n - 1]); for ( j = n - 1; i<n - 1; j--){ printf("当前访问的磁道:\t%d\n", a[j - 1]); } sum = now - a[0]; printf("移动的总磁道数:%d\n", sum); } else{ int d; int t; while (a[k] < now){ k++; } j = k - 1; printf("请输入当前磁头移动的方向(0向内,1向外):\n"); scanf("%d", &d); if (d == 1){ for (t = k; t < n; t++){ printf("当前访问的磁道:\t%d\n",a[t]); sum += a[t] - now; now = a[t]; } for (t = j; t >=0; t--){ printf("当前访问的磁道:\t%d\n",a[t]); } sum += a[n - 1] - a[0]; } else if (d == 0){ for (t = j; t >= 0; t--){ printf("当前访问的磁道:\t%d\n", a[t]); sum += now - a[t]; now = a[t]; } for (t = k; t < n; t++){ printf("当前访问的磁道:\t%d\n",a[t]); } sum += a[n - 1] - a[0]; } else{ printf("输入错误,重新回到选择算法界面!\n"); } } printf("经过的总磁道数为:%d\n", sum); printf("移动的平均磁道数:%.2lf\n", 1.0*sum/n); printf("请再次输入你想使用的方法:\n"); } /*循环扫描算法*/ void CSCAN(int a[], int n){ int temp; int now; int sum = 0, i, j, k = 0; printf("排序后的磁道分布:\n"); //冒泡排序法对磁道号进行排序 for (i = 0; i < n; i++){ for (j = i + 1; j < n; j++){ if (a[i]>a[j]){ temp = a[i]; a[i] = a[j]; a[j] = temp; } } printf("%d \t", a[i]); if (i % 10 == 9){ printf("\n"); } } printf("\n请输入当前磁道号:\n"); scanf("%d", &now); if (a[0] >= now){ printf("当前访问的磁道:%d\n", a[0]); for (i = 0; i < n - 1; i++){ printf("当前访问的磁道:\t%d\n", a[i + 1]); } sum = a[n - 1] - now; printf("移动的总磁道数:%d\n", sum); } else if (a[n - 1] <= now){ printf("当前访问的磁道:%d\n", a[n - 1]); for ( j = n - 1; i>=0; j--){ printf("当前访问的磁道:\t%d\n",a[j - 1]); } sum = now - a[0]; printf("移动的总磁道数:%d\n", sum); } else{ int d; int t; while (a[k] < now){ k++; } j = k - 1; printf("请输入当前磁头移动的方向(0向内,1向外):\n"); scanf("%d", &d); if (d == 1){ int i = 0; for (t = k; t < n; t++){ printf("当前访问的磁道:\t%d\n", a[t]); sum += a[t] - now; now = a[t]; } for (t = 0; t < k; t++){ printf("当前访问的磁道:\t%d\n", a[t]); } sum += a[n-1] - a[0]+a[j]-a[0]; } else if (d == 0){ for (t = j; t >= 0; t--){ printf("当前访问的磁道:\t%d\n", a[t]); sum += now - a[t]; now = a[t]; } for (t = n-1; t >=k; t--){ printf("当前访问的磁道:\t%d\n", a[t]); } sum += a[n - 1] - a[0]+a[n-1]-a[k]; } else{ printf("输入错误,重新回到选择算法界面!\n"); } } printf("经过的总磁道数为:%d\n", sum); printf("移动的平均磁道数:%.2lf\n", 1.0*sum / n); printf("请再次输入你想使用的方法:\n"); } /* 主函数*/ int main(){ int n; //磁道数 int control=1; //控制处理的方式 printf("请输入要处理的磁道数:\n"); scanf("%d",&n); int c[1000]; printf("请按求先后顺序依次输入磁道号:\n"); for (int i = 0; i < n; i++){ scanf("%d",&c[i]); } printf("\n 数据输入完毕! 已有进程提出磁盘I/O请求!\n"); printf("**************************************************\n"); printf("* *\n"); printf("******************* 算法选择 *********************\n"); printf("* *\n"); printf("* 1.先来先服务算法 *\n"); printf("* 2.最短寻道时间算法 *\n"); printf("* 3.扫描算法 *\n"); printf("* 4.循环扫描算法 *\n"); printf("* 0.退出程序 *\n"); printf("* *\n"); printf("**************************************************\n"); printf("\n"); /*算法选择*/ printf("请输入要执行的方法:\n"); while (control){ scanf("%d", &control); switch (control){ case 0: control=0; break; case 1: FCFS(c, n); break; case 2: SSTF(c, n); break; case 3: SCAN(c, n); break; case 4: CSCAN(c, n); break; default: printf("选项错误!重新选择!"); break; } } printf("程序退出成功,谢谢使用!"); system("pause"); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
#include <stdio.h> #include <iostream> #include <queue> #include <stack> #include <set> #include <string> #include <cstring> #include <cmath> #include <algorithm> #include <list> #define MAX 1111 #define INF 0x3f3f3f3f using namespace std; typedef struct Disk_Scheduling { double Trackhao; double Trackshu; }DKSG; DKSG ds[MAX]; double track[MAX]; int mark[MAX]; int input(int &n,double &now) { int im; int Min = INF; printf("请输入所求磁道号个数和开始磁道号(用空格隔开!):\n"); scanf("%d%lf",&n,&now); printf("请输入%d个磁道号(各磁道号之间用空格隔开!):\n",n); for(int i=0;i<n; i++){ scanf("%lf",&track[i]); double temp= fabs(track[i]-now); if(temp< Min){ Min =temp; im = i; } } return im; } void output(int n) { printf("%s %s\n","被访问的下一个磁道号","横跨磁道数"); for(int i=0;i<n; i++){ printf("%12.2f %16.2f\n",ds[i].Trackhao,ds[i].Trackshu); } } void FCFS() { int n; double now; input(n,now); for(int i=0;i<n; i++){ ds[i].Trackhao = track[i]; ds[i].Trackshu = fabs(track[i]-now); now =track[i]; } printf("\n先来先服务:\n"); output(n); } void SSTF() { memset(mark,0,sizeof(mark)); int n; double now; int im =input(n,now); int cnt1,cnt2; double t1,t2; for(int i=0;i<n; i++){ int Min =INF; ds[i].Trackhao = track[im]; ds[i].Trackshu = fabs(track[im]-now); now =track[im]; mark[im] =1; for(int j=0; j<n; j++){ if(!mark[j]){ double temp = fabs(track[j]-now); if(temp < Min){ Min = temp; im = j; } } } } printf("\n最短寻道时间优先:\n"); output(n); } void SCAN() { double retrack[MAX]; int n; double now; input(n,now); sort(track,track+n); int locate =upper_bound(track,track+n,now) - track; int t = locate; int k,r; for(k=0;k<n-locate; k++){ retrack[k]= track[k+locate]; } for(r=k; r<n;r++){ retrack[r]= track[--t]; } for(int i=0;i<n; i++){ ds[i].Trackhao = retrack[i]; ds[i].Trackshu = fabs(retrack[i]-now); now =retrack[i]; } printf("\n扫描调度算法:\n"); output(n); } void C_SCAN() { int n; double now; input(n,now); sort(track,track+n); int locate =upper_bound(track,track+n,now) - track; int im; for(int i=0;i<n; i++){ im =(i+locate)%n; ds[i].Trackhao = track[im]; ds[i].Trackshu = fabs(track[im]-now); now =track[im]; } printf("\n循环扫描调度算法:\n"); output(n); } int main() { printf("%*s\n",80,"欢迎您!"); int ca = 0; do{ printf("\n%*s\n",80,"请选择磁盘调度算法或结束程序:"); printf("0、结束程序\n1、先来先服务\n2、最短寻道时间优先\n3、扫描\n4、循环扫描\n"); scanf("%d",&ca); if(ca == 1)FCFS(); if(ca == 2)SSTF(); if(ca == 3)SCAN(); if(ca == 4)C_SCAN(); printf("\n\n"); }while(ca); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
21.某系统中,一个FCB占用64B,盘块大小1KB,文件目录中有3200个FCB,故查找一个文件平均启动磁盘次数为(C )
A、50
B、64
C、100
D、200
解析:3200个目录项需要占用的盘块数=3200×64B/1KB=200个。采用一级目录,平均访问盘块次数=(0+200)/2=100,
22.操作系统为每一个文件开辟一个存储区,在它的里面记录着该文件的有关信息。这就是( B )。
A、进程控制块
B、文件控制块
C、设备控制块
D、作业控制块
23.一个文件的绝对路径名总是以(A )打头。
A、磁盘名
B、字符串
C、分隔符
D、文件名
24.一个文件的绝对路径名是从( B )开始,逐步沿着每一级子目录向下,最后到达指定文件的整个通路上所有子目录名组成的一个字符串。
A、当前目录
B、根目录
C、多级目录
D、二级目录
25.设某系统磁盘共有1600块,块号从0到1599,若用位示图管理此磁盘空间当字长为32位时,位示图需要(50)个字,第20个字的第10位对应的块号是(B)。
A、16i+j
B、32i+j
C、i+32j
D、i+16j
解析:字:1600/32=50
块号b=32i+j
26.假设磁头当前位于第105道,正在向磁道序号增加的方向移动。现有一个磁道访问请求序列为35,45,12,68,110,180,170,195,采用SCAN调度(电梯调度)算法得到的磁道访问序列是 (B )。
A、68 45 35 12 110 170 180 195
B、110 170 180 195 68 45 35 12
C、110 170 180 195 12 35 45 68
D、12 35 45 68 110 170 180 195
解析:
| 110 | 68 |
|---|---|
| 170 | 45 |
| 180 | 35 |
| 195 | 12 |
27.在驱动调度算法中,(BD )算法可能会随时改变移动臂的移动方向。
A、电梯调度
B、先来先服务
C、单向扫描
D、最短寻道时间优先
解析:
带有“SCAN”的都属于扫描类算法,从一头扫到另一头,然后返回,再循环这个过程。
SSTF最最短寻道优先,随时可能改变移动臂的运动方向。
- 1
- 2
先来先服务,是按到达时间顺序,一个服务完了,磁头回去去找第二个,找到马上执行,类推,不知道下一个什么时候到,不能确定回到哪个点
最短寻道,是一个服务完,找离磁头最近的那个进程,也不固定
电梯调度,磁头固定的在两个点之间运动,哪个进程能搭上就运行掉
单项扫描,磁头从一边扫到另一边,完了立刻跳回到开头,回来过程中不处理进程
28.磁盘访问时间由哪几部分组成 (ABC )
A、寻道时间 Ts
B、旋转延迟时间 Tr
C、传输时间 Tt
D、数据访问时间 Td
解析:磁盘访问时间由寻道时间 Ts、旋转延迟时间 Tr、传输时间 Tt 三部分组成。 (1)Ts 是启动磁臂时间 s 与磁头移动 n 条磁道的时间和,即 Ts = m × n + s。 (2) Tr 是指定扇区移动到磁头下面所经历的时间。 硬盘 15000r/min 时 Tr 为 2ms;软盘 300 或 600r/min 时 Tr 为 50~100ms。 (3)Tt 是指数据从磁盘读出或向磁盘写入经历的时间。Tt 的大小与每次读/写的字节 数 b 和旋转速度有关:Tt = b/rN。
29.提高磁盘可靠性的技术有(ABCD)
A、第一级容错技术SFT-Ⅰ
B、第二级容错技术SFT- Ⅱ
C、基于集群技术的容错功能
D、后备系统
30.关于RAID技术,下面表述正确的有(ABCD )。
A、RAID在刚被推出时,是分成6级的,后来又增加了RAID 6级和RAID 7级。
B、可靠性高,除了RAID 0级外,其余各级都采用了容错技术。当阵列中某一磁盘损坏时,并不会造成数据的丢失。此时可根据其它未损坏磁盘中的信息来恢复已损坏的盘中的信息。其可靠性比单台磁盘机高出一个数量级。
C、磁盘I/O速度高,由于采取了并行交叉存取方式,可使磁盘I/O速度提高N-1倍。
D、性能/价格比高,RAID的体积与具有相同容量和速度的大型磁盘系统相比,只是后者的1/3,价格也只是后者的1/3,且可靠性高。换言之,它仅以牺牲1/N的容量为代价,换取了高可靠性。
第一次阶段测试
一.填空题(共9题,100.0分)
1.(填空题11.1分)
在一个使用交换技术的系统中,按地址从低到高排列的内存空间长度是:10KB、4KB、20KB、18KB、7KB、9KB、12KB、15KB。
对于下列顺序的段请求
(1)12KB(2)10KB(3)15KB(4)18KB(5)12KB
使用首次适应算法能否满足以上所有请求:不能
(填“能”或“不能”)
使用最佳适应算法能否满足以上所有请求:能
(填“能”或“不能”);
使用循环首次适应算法能否满足以上所有请求:不能
(填“能或不能)
解析:首次适应算法(FF):将所有空闲分区按照地址递增的次序链接,在申请内存分配时,从链首开始查找,将满足需求的第一个空闲分区分配给作业。
| 分去序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 分区大小 | 10 | 4 | 20 | 18 | 7 | 9 | 12 | 15 |
| 剩余大小 | 10 | 4 | 8(A) | 8(B) | 7 | 9 | 12 | 0© |
未完成
最佳适应算法(BF): 将所有空闲分区按照从小到大的顺序形成空闲分区链,在申请内存分配时,总是把满足需求的、最小的空闲分区分配给作业。
| 分去序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 分区大小 | 4 | 7 | 9 | 10 | 12 | 15 | 18 | 20 |
| 剩余大小 | 4 | 7 | 9 | 0(B) | 0(A) | 3(E) | 3© | 2(D) |
循环首次适应算法(NF):将所有空闲分区按照地址递增的次序链接,在申请内存分配时,总是从上次找到的空闲分区的下一个空闲分区开始查找,将满足需求的第一个空闲分区分配给作业
| 分去序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 分区大小 | 10 | 4 | 20 | 18 | 7 | 9 | 12 | 15 |
| 剩余大小 | 10 | 4 | 8(A) | 8(B) | 7 | 9 | 12 | 0© |
明显找不到了
#include <iostream> #include <fstream> #include <iomanip> using namespace std; #define MAXNUMBER 100 static int PartitionNum; //内存中空闲分区的个数 static int ProcessNum; //需要分配的进程个数 static int FreePartition[MAXNUMBER]; //空闲分区对应的内存 static int ProcessNeed[MAXNUMBER]; //需要分配的进程大小 static int LeftFreePartition[MAXNUMBER]; static int LeftProcessNeed[MAXNUMBER]; static char ProcessName[MAXNUMBER]; static char NameProcessToPartition[MAXNUMBER][MAXNUMBER]; typedef struct { int partitionSize; int id; }sortNeed; void readDataFunction(); void input(); void display(); void FirstFit(); void NextFit(); void BestFit(); void WorstFit(); void selectAlgorithm(int chooceAlgorithm); void display(); void readDataFunction() { cout<<"请输入空闲分区数"<<endl; cin >> PartitionNum; cout << "请输入空闲分区大小" << endl; for (int i = 0; i<PartitionNum; i++) { cin >> FreePartition[i]; } cout<<"请输入进程个数"<<endl; cin >> ProcessNum; cout<<"请输入进程名称"<<endl; for (int i = 0; i<ProcessNum; i++) { cin >> ProcessName[i]; } cout<<"请输入进程需要分配大小"<<endl; for (int i = 0; i<ProcessNum; i++) { cin >> ProcessNeed[i]; } } void input() { int chooseAlgorithm = 5; do { //readDataFunction(); cout << "请选择实现的算法:" << endl; cout << "***** 1 - 首次适应算法 *****" << endl; cout << "***** 2 - 循环首次适应算法 *****" << endl; cout << "***** 3 - 最佳适应算法 *****" << endl; cout << "***** 4 - 最坏适应算法 *****" << endl; cout << "***** 0 - 结束 *****" << endl; cout << "chooseAlgorithm = "; cin >> chooseAlgorithm; selectAlgorithm(chooseAlgorithm); //display(); } while (chooseAlgorithm); } void initial() { readDataFunction(); //读取原始数据 for (int i = 0; i<PartitionNum; i++) { LeftFreePartition[i] = FreePartition[i]; for (int j = 0; j<ProcessNum; j++) { NameProcessToPartition[i][j] = NULL; } } for (int i = 0; i<ProcessNum; i++) { LeftProcessNeed[i] = ProcessNeed[i]; } } void FirstFit() { cout << "***********首次适应算法***********" << endl; initial(); int i, j; for (i = 0; i<ProcessNum; i++) //逐个遍历每个进程 { for (j = 0; j<PartitionNum; j++) { if (LeftProcessNeed[i] <= LeftFreePartition[j] && LeftFreePartition != 0) //当系统内存分区足够大的时候,即分配给进程资源 { LeftFreePartition[j] -= LeftProcessNeed[i]; //扣除分配给进程的资源 LeftProcessNeed[i] = 0; //当且仅当系统内存分区足够时才执行,即当前进程大小置0 NameProcessToPartition[i][j] = ProcessName[i]; //存储各个进程所在的分区位置 break; //!!!很重要,一个进程分区完后,应该立即break,进行下一个进程的判断 } } } display(); } void NextFit() { cout << "***********循环首次适应算法***********" << endl; initial(); int i, nextPoint = 0; bool isWhile; for (i = 0; i<ProcessNum; i++) { isWhile = true; while (isWhile) { if (LeftFreePartition[nextPoint] >= LeftProcessNeed[i]) { LeftFreePartition[nextPoint] -= LeftProcessNeed[i]; LeftProcessNeed[i] = 0; NameProcessToPartition[i][nextPoint] = ProcessName[i]; nextPoint++; if (nextPoint > PartitionNum - 1) { nextPoint = 0; //当j遍历到分区末尾的时候,返回首位置 } isWhile = false; } else nextPoint++; } } display(); } void BestFit() { //思想:利用冒泡排序对分区大小进行排序,但不改变原分区的位置 //创建一个结构体,包括分区大小和所对应的id,排序过程中,每改变顺序一次,id随着改变 //关键:每次分配完一个进程的内存大小后,都要重新排序 cout << "***********最佳适应算法***********" << endl; initial(); int i, j, temp, tempID; sortNeed best[MAXNUMBER]; for (i = 0; i<PartitionNum; i++) { //初始化结构体 best[i].partitionSize = FreePartition[i]; best[i].id = i; } for (i = 0; i<ProcessNum; i++) { for (int s = PartitionNum - 1; s > 0; s--) //冒泡排序(每次分配完一个进程后,都需要重新排序) { for (int t = 0; t < s; t++) { if (best[s].partitionSize < best[t].partitionSize) { temp = best[s].partitionSize; best[s].partitionSize = best[t].partitionSize; best[t].partitionSize = temp; tempID = best[s].id; best[s].id = best[t].id; best[t].id = tempID; } } } for (j = 0; j<PartitionNum; j++) { if (LeftProcessNeed[i] <= best[j].partitionSize) { best[j].partitionSize -= LeftProcessNeed[i]; LeftProcessNeed[i] = 0; NameProcessToPartition[i][best[j].id] = ProcessName[i]; break; } } LeftFreePartition[best[j].id] = best[j].partitionSize; } display(); } void WorstFit() { cout << "***********最坏适应算法***********" << endl; initial(); int i, j, s, t, tempSize, tempID; sortNeed Worst[MAXNUMBER]; for (i = 0; i<PartitionNum; i++) { Worst[i].partitionSize = FreePartition[i]; Worst[i].id = i; } for (i = 0; i<ProcessNum; i++) { for (s = PartitionNum - 1; s>0; s--) { for (t = 0; t<s; t++) { if (Worst[s].partitionSize > Worst[t].partitionSize) { tempSize = Worst[s].partitionSize; Worst[s].partitionSize = Worst[t].partitionSize; Worst[t].partitionSize = tempSize; tempID = Worst[s].id; Worst[s].id = Worst[t].id; Worst[t].id = tempID; } } } for (j = 0; j<PartitionNum; j++) { if (LeftProcessNeed[i] <= Worst[j].partitionSize) { Worst[j].partitionSize -= LeftProcessNeed[i]; LeftProcessNeed[j] = 0; NameProcessToPartition[i][Worst[j].id] = ProcessName[i]; break; } } LeftFreePartition[Worst[j].id] = Worst[j].partitionSize; } display(); } void selectAlgorithm(int chooseAlgorithm) { switch (chooseAlgorithm) { case 0:break; case 1:FirstFit(); break; case 2:NextFit(); break; case 3:BestFit(); break; case 4:WorstFit(); break; default:cout << "请输入正确的序号:" << endl; } } void display() { int i; cout << "需要分配内存的进程名:" << setw(10); for (i = 0; i<ProcessNum; i++) { cout << ProcessName[i] << setw(6); } cout << endl; cout << "需要分配内存的进程分区大小:" << setw(4); for (i = 0; i<ProcessNum; i++) { cout << ProcessNeed[i] << setw(6); } cout << endl; cout << "分配结果:" << endl; cout << "分区序号:"; for (i = 0; i<PartitionNum; i++) { cout << "分区" << i + 1 << " "; } cout << endl << "分区大小:"; for (i = 0; i<PartitionNum; i++) { cout << FreePartition[i] << " "; } cout << endl << "剩余大小: "; for (i = 0; i<PartitionNum; i++) { cout << LeftFreePartition[i] << " "; } cout << endl << "分配进程情况:" << endl; for (i = 0; i<PartitionNum; i++) { for (int j = 0; j<ProcessNum; j++) { if (NameProcessToPartition[j][i] != NULL) { cout << NameProcessToPartition[j][i] << ": (分区" << i + 1 << ")" << endl; } } //cout<<" "; } cout << endl << "********结束**********" << endl; } int main() { input(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
2.(填空题,11.1分)
假设某虚存的用户空间为1024KB,页面大小为4KB,内存空间为1MB。已知用户的虚页10、11、12、13页分得内存物理块号为62、12、25、36,求出虚地址0BEBC(16进制)的实地址(16进制)是 0CEBC(只填写16进制数,中间不能有空格)。
解析:0BEBC(16进制)转换为二进制为0000 1011 1110 1011 1100,由于页面大小为4kb,页面大小 = 2^(页内地址位数),所以页面大小为4KB,有12位,所以后12位是位移,低位部分是位移量,⾼位部分是页号。虚地址页号:0000 1011转成10进制即为11,所以查页表分得内存对应页框号为:12.已知内存空间为1024KB,页的大小=页框大小(进程中的块和内存中的块大小相同),故内存共有1024kb/4kb=256个页框,12是合法物理块。把12化为16进制是0c,虚地址0BEBC(16进制)的实地址(16进制)是:0cEBC。
3.(填空题,11.1分)
有n个进程A1,…An将字符读入到一个容量为80字节的缓冲区中(n>1),当缓冲区满后,由另一个进程B负责一次性取走这80个字符,这种过程循环往复。试用信号量及wait()、signal()操作写出n个读入进程和取数进程同步操作的程序。
定义信号量mutex表示对缓冲区的互斥访问;empty表示空缓冲区数目,ful表示满缓冲区数目。
代码如下,请补全:
var mutex, empty, full:semaphore; count,in:integer buffer:array[0..79]of char; mutex=1;empty=80;full=0; count=0;in=0; cobegir process A;(i=1,....n) begin L:读入一字符到x; (1)P(empty);参考格式:P(empty);或V(mutex);无空格、所有均为字符英文。下同。 (2)P(mutex); Buffer[in]=X; in=(in+1)%80; count++; if(count==80) { count=0; (3)V(mutex); (4)V(full);} else (5)V(mutex); goto L; end; process B begin (6)P(full); (7)P(mutex); for(intj=0;j<80;j++) read buffer[j]; in:=0; (8)V(mutex); for(intj=0;j<80;j++) (9)V(empty); end; coend.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
(1)P(empty);
(2)P(mutex);
(3)V(mutex);
(4)V(full);
(5)V(mutex);
(6)P(full);
(7)P(mutex);
(8)V(mutex);
(9)V(empty);
4.(填空题,11.1分)
在银行家算法中,若出现下述4类资源的分配情况。
| Allocation | Need | Available | |
|---|---|---|---|
| P0 | 0032 | 0012 | 1622 |
| P1 | 1000 | 1750 | |
| P2 | 1354 | 2356 | |
| P3 | 0332 | 0652 | |
| P4 | 0014 | 0656 |
试问:该状态是否安全?【1】填“安全”或“不安全”安全
安全序列是_【2】若无安全序列填“无”
(2){P0,P3,P1,P4,P2};{P0,P3,P4,P1,P2}
如果进程P2提出请求Request2(1,2,2,2)后,系统是否能将资源分配给它?【3】填“分配”或“不分配”
不分配
原因是【4】若“分配”填安全序列;若“不分配”填原因序号(只写字母):a.需求错误。b.剩余资源不够任何进
程执行。C.剩余资源只够部分进程执行。
b
解析:
| Process | Work | Need | Allocation | Work+Allocation | Finish |
|---|---|---|---|---|---|
| A B C D | A B C D | A B C D | A B C D | ||
| P0 | 1 6 2 2 | 0 0 1 2 | 0 0 3 2 | 1 6 5 4 | TRUE |
| P3 | 1 6 5 4 | 0 6 5 2 | 0 3 3 2 | 1 9 8 6 | TRUE |
| P1 | 1 9 8 6 | 1 7 5 0 | 1 0 0 0 | 2 9 8 6 | TRUE |
| P4 | 2 9 8 6 | 0 6 5 6 | 0 0 1 4 | 2 9 9 10 | TRUE |
| P2 | 2 9 9 10 | 2 3 5 6 | 1 3 5 4 | 3 12 14 14 | TRUE |
由安全性检查得知,可以找到一个安全序列{P0、P3、P1、P4、P2},因此系统是安全的。
(2)P2提出Request(1,2,2,2),系统按银行家算法进行检查:Request(1,2,2,2) ≤ Need(2,3,5,6),P2请求是合理的;Request(1,2,2,2)≤Available(1,6,2,2),P2请求是可以满足的;
所以先假定分配这个P2请求的资源,资源变化情况如下所示
| Process | Allocation | Need | Available |
| P0 | 0032 | 0012 | 0400 |
| P1 | 1000 | 1750 | |
| P2 | 2576 | 1134 | |
| P3 | 0332 | 0652 | |
| P4 | 0014 | 0656 |
Available=Available-Request=(0,4,0,0)
Need=Need-Request=(1,1,3,4)
Allocation=Allocation+Request=(2,5,7,6)
此时不存在一个安全序列,所以不能将P2请求的资源分配给它,让P2等待。
#include <iostream> using namespace std; #define MAXPROCESS 50 //最大进程数 #define MAXRESOURCE 100 //最大资源数 int AVAILABLE[MAXRESOURCE]; //可用资源数组 int MAX[MAXPROCESS][MAXRESOURCE]; //最大需求矩阵 int ALLOCATION[MAXPROCESS][MAXRESOURCE]; //分配矩阵 int NEED[MAXPROCESS][MAXRESOURCE]; //需求矩阵 int REQUEST[MAXPROCESS][MAXRESOURCE]; //进程需要资源数 bool FINISH[MAXPROCESS]; //系统是否有足够的资源分配 int p[MAXPROCESS]; //记录序列 int m,n; //m个进程,n个资源 void Init(); //初始化变量 bool Safe(); //安全检测 void Bank(); //银行家算法 void showdata(int,int); //显示输出系统信息 int main() { Init(); Safe(); Bank(); } /*初始化变量*/ void Init() { int i,j;//输入进程 cout << "请输入进程的数目:"; cin >> m;//m为进程数目 cout << "请输入资源的种类:"; cin >> n;//有n中资源 cout << "请输入每个进程最多所需的各资源数,按照" << m << "x" << n << "矩阵输入" << endl; for(i=0;i<m;i++)//通过循环,输入了每个进程的各类资源最大需求量MAX for(j=0;j<n;j++) cin >> MAX[i][j]; cout << "请输入每个进程已分配的各资源数,也按照" << m << "x" << n << "矩阵输入" << endl; for(i = 0; i < m; i++)//输入每个进程的各类资源已分配量 for(j = 0; j < n; j++) { cin >> ALLOCATION[i][j]; NEED[i][j] = MAX[i][j] - ALLOCATION[i][j];//还需要的各类资源数目=最大需求-已经获得的 if(NEED[i][j] < 0)//若已经获得的>最大需求量,则需要重新输入,Allocation { cout << "您输入的第" << i+1 << "个进程所拥有的第" << j+1 << "个资源数错误,请重新输入:" << endl; j--; continue; } } cout << "请输入各个资源现有的数目:" << endl; for(i = 0; i < n; i++)//现有的各类资源数目 cin >> AVAILABLE[i]; } /*银行家算法*/ void Bank() { int i,cusneed,flag = 0; //cousneed资源进程号 char again; //键盘录入一个字符用于判断是否继续请求资源 while(1) { showdata(n,m);//得到n和m cout << endl; /*请求资源*/ while(true) { cout << "请输入要申请资源的进程号(注:第1个进程号为0,依次类推)" << endl; cin >> cusneed;//输入哪个进程需要请求资源 if (cusneed > m)//如果编程号>现有的进程数 ,则是输入的进程编号错误 { cout << "没有该进程,请重新输入" << endl; continue; } cout << "请输入进程所请求的各资源的数量" << endl; for(i = 0; i < n; i++)//输入请求的各类资源数 cin >> REQUEST[cusneed][i]; for(i = 0; i < n; i++) { if(REQUEST[cusneed][i] > NEED[cusneed][i]) //如果用户选择的线程的第i个资源请求数>该线程该资源所需的数量 { cout << "您输入的请求数超过进程的需求量!请重新输入!" << endl; continue; } if(REQUEST[cusneed][i] > AVAILABLE[i]) //如果用户选择的线程的第i个资源请求数>系统现有的第i个资源的数量 { cout << "您输入的请求数超过系统有的资源数!请重新输入!" << endl; continue; } } break; } /*如果请求合理,那么开始银行家算法计算*/ /*先将申请的资源进行分配*/ for(i = 0; i < n; i++) { AVAILABLE[i] -= REQUEST[cusneed][i]; //系统可用资源减去申请了的 ALLOCATION[cusneed][i] += REQUEST[cusneed][i]; //线程被分配的资源加上已申请了的 NEED[cusneed][i] -= REQUEST[cusneed][i]; //线程还需要的资源减去已申请得到的 } /*判断分配申请资源后的系统是否安全;如果不安全则将分配的申请资源还回系统*/ if(Safe()) //AVAILABLE ALLOCATION NEED变动之后,是否会导致不安全 cout << "同意分配请求!" << endl; else { cout << "您的请求被拒绝!" << endl; /*资源还回系统*/ for(i = 0; i < n; i++)//拒绝后,已获得资源,需求和现有各类资源情况变化 { AVAILABLE[i] += REQUEST[cusneed][i]; ALLOCATION[cusneed][i] -= REQUEST[cusneed][i]; NEED[cusneed][i] += REQUEST[cusneed][i]; } } /*对进程的需求资源进行判断;是否还需要资源;即NEED数组是否为0*/ for (i = 0; i < n; i++)//计算已经不需要资源的进程有多少个 if (NEED[cusneed][i] <= 0) flag++; if (flag == n) //如果该进程各资源都已满足条件,则释放资源 { for (i = 0; i < n; i++)//释放资源 { AVAILABLE[i] += ALLOCATION[cusneed][i]; ALLOCATION[cusneed][i] = 0; NEED[cusneed][i] = 0; } cout << "线程" << cusneed << " 占有的资源被释放!" << endl; flag = 0; } for(i = 0; i < m; i++) //分配好了以后将进程的标识FINISH改成false FINISH[i] = false; /*判断是否继续申请*/ cout << "您还想再次请求分配吗?是请按y/Y,否请按其它键" << endl; cin >> again; if(again == 'y' || again == 'Y') continue; break; } } /*安全性算法*/ //要找到一个安全序列 bool Safe() { int i, j, k, l = 0; int Work[MAXRESOURCE]; //工作数组 /*工作数组赋值,与AVAILABLE数组相同*/ for (i = 0; i < n; i++)//将Available的值赋给work Work[i] = AVAILABLE[i]; /*FINISH数组赋值,初始为全部false*/ for (i = 0; i < m; i++) FINISH[i] = false; //FINISH记录每个进程是否安全 while (l < m) //正常的话,共执行m次 { int init_index = l; for (i = 0; i < m; i++) { if (FINISH[i] == true) //如果这个进程安全则继续下一个循环 continue; for (j = 0; j < n; j++) if (NEED[i][j] > Work[j])//若需求>work,则现在不能是这个进程 break; if (j == n) { FINISH[i] = true; for (k = 0; k < n; k++) Work[k] += ALLOCATION[i][k]; p[l++] = i;//记录进程号 } else //如果超过继续循环下一个进程 continue; } if (l==init_index) { cout << "系统是不安全的" << endl; return false; } } cout << "系统是安全的" << endl; cout << "安全序列:" << endl; for (i = 0; i < l; i++) { cout << p[i]; if (i != l - 1) cout << "-->"; } cout << endl; return true; } /*显示*/ void showdata(int n,int m) { int i,j; cout << endl << "-------------------------------------------------------------" << endl; cout << "系统可用的资源数为: "; for (j = 0; j < n; j++) cout << " " << AVAILABLE[j]; cout << endl << "各进程还需要的资源量:" << endl; for(i = 0; i < m; i++) { cout << " 进程" << i << ":"; for(j = 0; j < n; j++) cout << " " << NEED[i][j]; cout << endl; } cout << endl << "各进程已经得到的资源量: " << endl << endl; for (i = 0; i < m; i++) { cout << " 进程" << i << ":"; for (j = 0; j < n; j++) cout << " " << ALLOCATION[i][j]; cout << endl; } cout << endl; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
5.(填空题,11.1分)
假定磁盘有200个柱面,编号0~199,当前存取臂的位置在100号柱面上,并刚刚完成了80号柱面的服务请求,如果请求队列的先后顺序是:
88、58、93、18、90、160、110、48、146
如果采用SCAN算法完成上述请求,其存取臂移动的总量是【1】(只填写最终结果,数字)。
磁头臂移动的序列_【2】(参考格式:88-58-93-18-90-160-110-48-146,中间无空格,间隔符为减号)。
如果采用FCFS算法完成上述请求,其存取臂移动的总量是【3】(只填写最终结果,数字)
磁头臂移动的序列【4】(参考格式:88-58-93-18-90-160-110-48-146,中间无空格,间隔符为减号)。
如果采用SSTF算法完成上述请求,其存取臂移动的总量是【5】(只填写最终结果,数字)
磁头臂移动的序列_【6】(参考格式:88-58-93-18-90-160-110-48-146,中间无空格,间隔符为减号)。
正确答案:
(1)202
(2)110-146-160-93-90-88-58-48-18
(3)504
(4)88-58-93-18-90-160-110-48-146
(5)226
(6)93-90-88-110-146-160-58-48-18
解析:SCAN算法
电梯调度算法
优先考虑磁头的当前移动方向,并且考虑当前磁道与下一磁道之间的距离。例如,当磁头正在自里向外移动时,扫描算法所选择的下一个访问对象应该是,即在当前磁道之外,又距离最近。这样自里向外的访问,直到再无更外的磁道需要访问才将磁臂换向,自外向里移动。移动原则同前一致。下面贴出这一段的来源浅谈磁盘调度算法
由于这种算法中磁头移动的规律与电梯的运行相似,因此又称为电梯调度算法。
| 从100向磁道号增加的方向 | 反方向 | 移动量 |
|---|---|---|
| 110 | 93 | 10 |
| 146 | 90 | 36 |
| 160 | 88 | 14 |
| 58 | 67 | |
| 48 | 3 | |
| 18 | 2 | |
| 30 | ||
| 10 | ||
| 30 |
10+36+14+67+3+2+30+10+30=202
FCFS算法
按顺序访问
| 被访问的下一个磁道号 | 移动量 |
|---|---|
| 88 | 12 |
| 58 | 30 |
| 93 | 35 |
| 18 | 75 |
| 90 | 72 |
| 160 | 70 |
| 110 | 50 |
| 48 | 62 |
| 146 | 98 |
12+30+35+75+72+70+50+62+98=504
SSTF算法
最短寻道优先算法
根据最短寻道时间优先磁盘调度算法,每次在寻找下一个磁道时,都要选择离自己最近的,所以当前磁头位于85号,下一道选择与85绝对值最小的
| 被访问的下一个磁道号 | 移动量 |
|---|---|
| 93 | 7 |
| 90 | 3 |
| 88 | 2 |
| 110 | 22 |
| 146 | 36 |
| 160 | 14 |
| 58 | 102 |
| 48 | 10 |
| 18 | 30 |
7+3+2+22+36+14+102+10+30=226
6.(填空题,11.1分)
对应如下所示的段表:
| 段号 | 内存始址 | 段长 |
|---|---|---|
| 0 | 50k | 10k |
| 1 | 60k | 3k |
| 2 | 70k | 5k |
| 3 | 120k | 8k |
| 4 | 150k | 4k |
逻辑地址(0,137)对应的物理地址是【_1】(填写十进制数,或段长越界”,或段号越界”);
逻辑地址(1,4000)对应的物理地址是【2】(填写十进制数,或“段长越界”,或“段号越界”);
逻辑地址(2,3600)对应的物理地址是【3】(填写十进制数,或“段长越界”,或“段号越界”);
逻辑地址(5,230)对应的物理地址是【4】(填写十进制数,或段长越界”,或“段号越界”)。
正确答案:
(1)51337
(2)段长越界
(3)75280
(4)段号越界
解析:先找到段号0处,物理地址=起始地址+位移量,即物理地址=50K+137=50X1024+137=51337.(说明1K=1024)
对于(1,4000),由于位移量4000>3X1024,所以越界,产生中断信号
对于(2,3600),找到段号2处,物理地址=70K+3600=70X1024+3600=75280
对于(5,230),逻辑地址的段号5>段表长度4,发生越界,产生中断信号。
7.(填空题,11.2分)
某博物馆允许500人同时参观,有一个出入口。该出入口一次仅允许一个人通过,完成下面的进程同步问题。
请对信号量赋初值,并将选项A~D填入恰当的位置。
选项:
A:wait(empty);
B:signal(empty);
C:wait(mutex);
D:signal(mutex);
semaphore empty=_[1]只填数字;
semaphore mutex=_[2]只填数字;
cobegin
参观者进程i:
_[3]填选项字母A~D;
_[4]填选项字母A~D);
进门
[5]填选项字母A~D;
参观
_[6]填选项字母A~D;
出门
_[7]填选项字母A~D
[8]填选项字母A~D
coend
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
正确答案:
(1)500
(2)1
(3)A;a
(4)C;C
(5)D;d
(6)C;C
(7)D;d
(8)B;b
8.(填空题,11.1分)
设有四个进程PI,P2,P3,P4,它们到达就绪队列的时间,运行时间及优先级如下所示(数值越大优先级越高)。
| 进程 | 到达就绪队列的时间(s) | 运行时间(s) | 优先级 |
|---|---|---|---|
| P1 | 0 | 9 | 1 |
| P2 | 1 | 4 | 3 |
| P3 | 2 | 8 | 2 |
| P4 | 3 | 10 | 4 |
问:(1)若采用可抢占的优先级调度算法,各个进程的调度次序为【1】参考格式:P1>P2>P3>P4>P1>P2、进程的平均周转时间为2]只写数字、平均等待时间为3]只写数字
(2)若采用不可抢占的短作业优先调度算法,各个进程的调度次序为【4】参考格式:P1>P2>P3>P4>P1>P2、进程的平均周转时间_【5】只写数字、平均等待时间_【6】只写数字。
正确答案:
(1)P1>P2>P4>P2>P3>P1
(2)19
(3)11.25
(4)P1>P2>P3>P4
(5)17
(6)9.25
若采用不可抢占的短作业优先调度算法
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 |
|---|---|---|---|---|---|---|
| A | 0 | 9 | 0 | 0 | 9 | 9 |
| B | 1 | 4 | 9 | 8 | 13 | 12 |
| C | 2 | 8 | 13 | 11 | 21 | 19 |
| D | 3 | 10 | 21 | 18 | 31 | 29 |
9+12+19+29/4=17.25
8+11+18/4=9.25
若采用可抢占的优先级调度算法
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 优先级 |
|---|---|---|---|---|---|---|---|
| A1 | 0 | 9(8) | 0 | 0 | 1 | 31 | 1 |
| B1 | 1 | 4(2) | 1 | 0 | 3 | 14 | 3 |
| C | 2 | 8 | 15 | 13 | 23 | 21 | 2 |
| D | 3 | 10 | 3 | 0 | 13 | 10 | 4 |
| B2 | 13 | 2 | 13 | 0 | 15 | ||
| A2 | 23 | 8 | 23 | 0 | 31 |
A先执行1后,D的优先级高于B,B执行2后执行D,然后执行B,B完成后,执行C,最后再来A
31+14+21+10/4=19
22+10+13/4=11.25
9.(填空题,11.1分)
一个进程在磁盘上包含8个虚拟页(0号~7号),在主存中固定分配给3个物理块,发生如下顺序的页访问:
4,3,2,1,4,3,5,4,3,2,1,5
假设这些物理块最初是空的。
如果使用LRU算法,缺页次数为1](只填数字)次。
如果使用FIFO算法,缺页次数为【2】_(只填数字)次。
如果使用OPT算法,缺页次数为_3](只填数字)_次。**
正确答案:
(1)10
(2)9
(3)7
解析:LRU算法
| 4 | |
|---|---|
| 4 3 | |
| 4 3 2 | |
| 1 3 2//4最近一段时间里较久未被访问||1 | |
| 1 4 2//3最近一段时间里较久未被访问||4 | |
| 1 4 3//2最近一段时间里较久未被访问||3 | |
| 5 4 3//1最近一段时间里较久未被访问||5||4不缺||3不缺 | |
| 2 4 3//5最近一段时间里较久未被访问||2 | |
| 2 1 3//4最近一段时间里较久未被访问||1 | |
| 2 1 5//3最近一段时间里较久未被访问||5 |
10次
FIFO算法
| 4 | |
|---|---|
| 4 3 | |
| 4 3 2 | |
| 1 3 2//4先进先出||1 | |
| 1 4 2//3先进先出||4 | |
| 1 4 3//2先进先出||3 | |
| 5 4 3//1先进先出||5||4不缺||3不缺 | |
| 5 2 3//4先进先出5,3刚被访问过||2|| | |
| 5 2 1//3先进先出3,2访问||1||5不缺 |
9次
OPT算法
| 4 | |
|---|---|
| 4 3 | |
| 4 3 2 | |
| 4 3 1//2最长时间内不使用(倒三)||1||4,3不缺 | |
| 4 3 5//1最长时间内不使用(倒二)||5||4,3不缺 | |
| 2 3 5 //4最长时间内不使用(使用完毕)||2 | |
| 1 3 5//2最长时间内不使用(使用完毕)||1||5不缺 |
7次

