
- 1我的世界java下载慢怎么办_MC国际版的下载教程
- 2Linux dump命令教程:如何安全快速备份你的文件系统(附实例详解和注意事项)_自动执行dump命令
- 3springboot+vue的前后端分离部署(详细)_springboot vue项目写在一起了怎么分离
- 4vmstat 详解
- 5解决: Gradle DSL method not found: 'apt()'_gradle dsl method not found: 'dependencyresolution
- 6Nuxt3打包部署到Linux(node+pm2安装和运行步骤+nginx代理)
- 7Unity Transparent Video | 用 VideoPlayer 或 AVPro 播放透明影片_ffmpeg hap_alpha
- 8动态规划题目_掌握利 最优性原理求解动态规划问题的过程 实验内容 某企业甲、 、丙
- 9ubuntu-18.04.6部署kubelet的步骤及常用命令
- 10tar -zcvf命令_LINUX常用命令全集
使用Python爬取豆瓣电影 Top 250_爬取电影
赞
踩
目录
前言
本博客主要叙述了Python爬虫中xpath解析的实际应用以及如何将解析好的数据保存为.csv格式,这里以豆瓣电影 Top 250
一、大致思路
1.导入第三方库
我这里用了几个比较简单的第三方库,大家环境里没有的话需要下载一下:
点击图片所指的方向,在终端输入这两行命令,就能进行进下来的操作
- pip install requests
- pip install lxml
2.简单需求分析
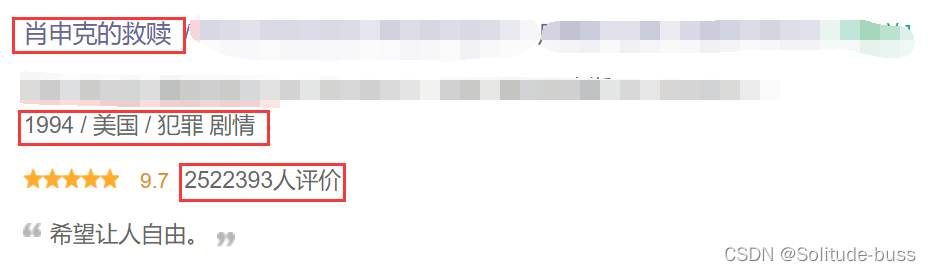
本次数据爬取的是电影名称、基本信息和评价人数,所以基于这些需求我们对于网页源代码进行定位提取并分析。
二、代码解析
本案例在实现的同时也做了比较浅层的封装,主要分为四部分:获取url、保存成.csv文件、基本事件的处理和主函数。
1. 介绍一下get_url()函数,这里在确定请求方式为get后对网页进行访问时会出现提取失败的问题,所以我们首先想到网站或许是做了UA伪装,那么就添加以下请求头的信息,然后再次访问该网站,访问成功(问题解决)。
UA伪装简单来讲就是,网站只是单纯的想让人去访问,而不是机器,那么根据这一点,我们只需要去改变一下请求头的本地信息就可以避免这个问题。
- # 获取url并返回response值
- # 参数1:想要获取的url 参数2:爬取的页数
- def get_url(m_url, m_page_cnt):
- headers = {
- # UA伪装,这里用"xxx"表示
- "User-Agent": "xxx",
- }
- m_resp = requests.get(url=m_url, headers=headers)
- return m_resp
2. save_csv()函数就是对数据进行本地保存的操作,这里简单的调用了csv库进行实现,需要导入第三方库。
import csv至于为什么需要返回值m_f,主要是我们需要在主函数将其关闭,但有人说Python中会自动关闭文件描述符,所以也可以不添加返回值。
- # 将文件保存成.csv形式,并返回文件描述符m_f
- # 参数1:文件路径 参数2:读写类型 参数3:编码格式 参数4:将单次提取的数据放入暂存列表
- def save_csv(m_csv_file, m_rw, m_encoding, m_save_list):
- with open(m_csv_file, m_rw, encoding=m_encoding) as m_f:
- writer = csv.writer(f)
- writer.writerows(m_save_list)
- return m_f
3. 基本事件的封装,要想去对庞大数据进行分析的话,首先要了解子事件的分析过程,这里的子时间就是爬取一个页面中的电影信息,所以就不难理解为什么要循环(1, 26),别问,问就是一个页面就有25条信息。
我这次采用的是xpath解析,不太会xpath解析的可以去抓包工具中直接复制,自己改一改也行。这里注意的就是xpath()函数以列表形式返回,想要做字符串处理操作需要列表转换成字符串,然后就是一些Python基础操作,最后存储返回即可。
- # 对网页数据进行解析
- def deal_events():
- for i in range(1, 26):
-
- info_list = []
-
- # 这些返回值是列表的形式
- mv_name = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div/a/span[1]/text()')
- mv_kind = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div[2]/p[1]/text()[2]')
- mv_people = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div[2]/div/span[4]/text()')
-
- # 我们将列表转换成字符串,再做简单处理
- str_kind = ''.join(mv_kind).replace('\n', '').replace('/', '').lstrip().rstrip()
- str_name = ','.join(mv_name)
- str_people = ''.join(mv_people)
-
- info_list.append(str_name)
- info_list.append(str_kind.replace('\xa0\xa0', ' '))
- info_list.append(str_people.replace('人评价', ''))
-
- save_info_list.append(info_list)

4. 主函数主要是对其他函数的调用、变量的初始化并给予一些提示信息。
可能看到这里有人会疑问为什么有循环操作,因为这里我提取了250个电影的信息,deal_events()函数只提取了一页的信息,至于为什么url会这么写,不理解的小伙伴可以看看拿第一页的网址和第二页的网址比较一下就会得到答案。
- if __name__ == '__main__':
- f = ""
- for page_cnt in range(0, 226, 25):
- url = f"https://movie.douban.com/top250?start={page_cnt}&filter="
- resp = get_url(m_url=url, m_page_cnt=page_cnt)
-
- tree = etree.HTML(resp.text)
-
- save_info_list = []
- deal_events()
-
- # 参数2以追加的形式存储,防止爬取数据被覆盖
- f = save_csv("./movie_info_demo.csv", 'a', 'utf-8', save_info_list)
-
- resp.close()
- print(f'第{page_cnt}页信息提取成功')
- time.sleep(2)
-
- f.close()
- print("提取完毕")
三、代码实现
- import requests
- from lxml import etree
- import csv
- import time
-
-
- # 获取url并返回response值
- # 参数1:想要获取的url 参数2:爬取的页数
- def get_url(m_url, m_page_cnt):
- headers = {
- # UA伪装
- "User-Agent": "xxx",
- }
- m_resp = requests.get(url=m_url, headers=headers)
- return m_resp
-
-
- # 将文件保存成.csv形式,并返回文件描述符m_f
- # 参数1:文件路径 参数2:读写类型 参数3:编码格式 参数4:将单次提取的数据放入暂存列表
- def save_csv(m_csv_file, m_rw, m_encoding, m_save_list):
- with open(m_csv_file, m_rw, encoding=m_encoding) as m_f:
- writer = csv.writer(m_f)
- writer.writerows(m_save_list)
- return m_f
-
-
- # 对网页数据进行解析
- def deal_events():
- for i in range(1, 26):
-
- info_list = []
-
- # 这些返回值是列表的形式
- mv_name = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div/a/span[1]/text()')
- mv_kind = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div[2]/p[1]/text()[2]')
- mv_people = tree.xpath(f'//*[@id="content"]/div/div[1]/ol/li[{i}]/div/div[2]/div[2]/div/span[4]/text()')
-
- # 我们将列表转换成字符串,再做简单处理
- str_kind = ''.join(mv_kind).replace('\n', '').replace('/', '').lstrip().rstrip()
- str_name = ','.join(mv_name)
- str_people = ''.join(mv_people)
-
- info_list.append(str_name)
- info_list.append(str_kind.replace('\xa0\xa0', ' '))
- info_list.append(str_people.replace('人评价', ''))
-
- save_info_list.append(info_list)
-
-
- if __name__ == '__main__':
- f = ""
- for page_cnt in range(0, 226, 25):
- url = f"https://movie.douban.com/top250?start={page_cnt}&filter="
- resp = get_url(m_url=url, m_page_cnt=page_cnt)
-
- tree = etree.HTML(resp.text)
-
- save_info_list = []
- deal_events()
-
- # 参数2以追加的形式存储,防止爬取数据被覆盖
- f = save_csv("./movie_info_demo.csv", 'a', 'utf-8', save_info_list)
-
- resp.close()
- print(f'第{page_cnt}页信息提取成功')
- time.sleep(2)
-
- f.close()
- print("提取完毕")
四、总结一下
实现Python爬虫的基本思路:
1. 确定需求
2. 网站分析
简单分析以下网站的基本信息,主要想去观察就是网站的反扒机制以及网页结构。
3. 单一数据提取
对简单的子子事件的数据进行提取,这当中会有一些比较困难的问题需要解决,比如:数据难定位和反扒机制(UA伪装、防盗链)。接下来就是数据解析和存储格式问题,还有一些数据分析的问题。
4. 提取大量数据
提取到单一数据之后,就开始在外层进行扩展,增大数据量,需要注意的就是数据量量太大时,尽量”少量多次“,容易被封。后续就有些线程池、进程池和协程的知识需要学习,提高效率。
5. 函数封装,简化代码
函数封装也是比较重要的,既可以使代码简洁、规整,还可以提高可利用性。
本人是小白,有错误的地方请大佬们多多指正。

