
- 1Executors.newCachedThreadPool的底层源码浅析
- 2秀儿,组里新来了个00后,真卷不过....
- 3Scalable diffusion models with transformers
- 4【图像处理】基于matlab互信息图像配准_matlab 图像配准两个图像的互信息
- 5图像分类传统算法和深度学习算法简单介绍_图像分类算法
- 6Latex---IEEE论文写作_ieee letex写作
- 7undefined reference to `ANativeWindow_fromSurface'
- 8人工智能搜索技术_未来世界畅想丨人工智能和机器人
- 9已解决 Error inflating class com.google.android.material.appbar.AppBarLayout
- 10解决kali虚拟机无法连接网络的问题_为什么kali输入dhclient eth0卡住
【论文整理】自动驾驶场景中Collaborative Methods多智能体协同感知文章创新点整理
赞
踩
这篇文章主要想整理一下,根据时间顺序这些文章是怎么说明自己的创新点的,又是怎么说明自己的文章比别的文章优越的。显然似乎很多文章只是简单阐述了其他文章的思路,关于优点与不足之处,仍然很难讲得清楚。(那些用数字代表的文章,都是当前文章下的引文,大伙可以自行查找)
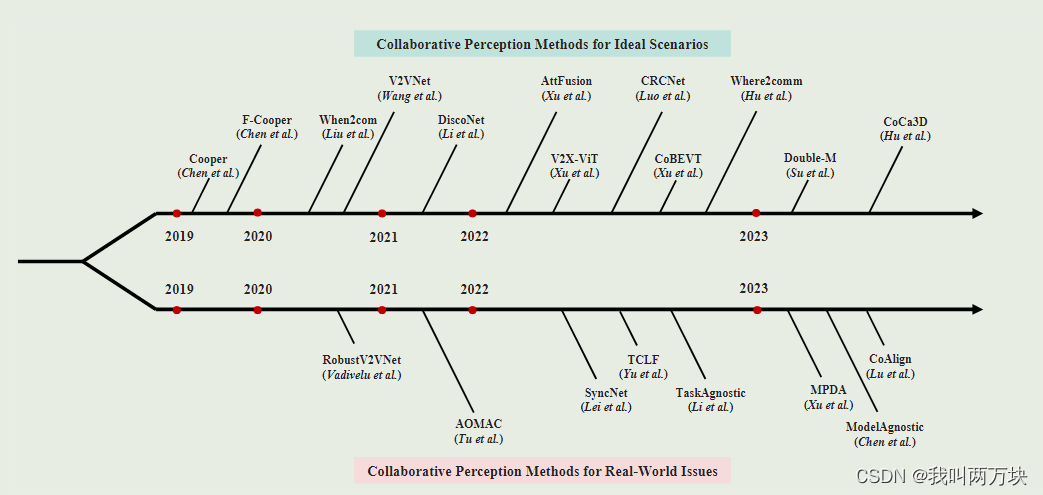
F-Cooper
在关于自动驾驶汽车协同感知的相关工作中[6,26],我们发现他们的主要关注点是提高单个车辆的精度,而忽略了协同感知的好处。合作感知中涉及的潜在问题,如本地感知结果的准确性、对网络的影响、要交换的数据格式以及边缘服务器上的数据融合,都没有得到解决。在3D物体检测方面,激光雷达是自动驾驶汽车最重要的组成部分之一,因为它可以生成3D点云来捕捉场景的3D结构。
这些数据提供了激光雷达以及汽车在3D空间中的精确位置。基于我们的最佳认知,基于单目激光雷达(光检测和测距)数据的最先进的3D物体检测精度来自VoxelNet[37]、SECOND[36]和PointRCNN[31]等。例如,PointRCNN在KITTI中等基准[8]上实现了75.76%的mAP(平均精度),在简单基准和硬基准上分别实现了85.94%和68.32%。这意味着来自不同汽车的物体检测结果的简单融合(late fusion)将产生误差。尽管融合两辆车的原始激光雷达数据可以提高汽车检测精度[3],但实时发送自动驾驶汽车生成的大量激光雷达数据(early fusion)具有挑战性。提高车辆感知精度以及保持或减少计算复杂性和周转时间的解决方案在文献中很少见。
本文利用卷积神经网络提取特征,通过特征融合来实现自动驾驶车辆之间的数据共享,从而提高物体检测精度和实现实时边缘计算(intermediate fusion)
V2VNet
[34,38]将接收到的V2V消息与本地传感器的输出相关联。
[8] 聚集来自其他车辆的激光雷达点云,然后是用于检测的深度网络。
[35,44]通过深度网络处理传感器测量,然后生成感知输出,用于跨车辆数据共享。
相比之下,我们通过传输压缩的中间表示来利用深度网络的力量。
此外,虽然之前的工作在有限的简单和不现实的场景中展示了结果,但我们在不同的大规模自动驾驶V2V数据集上展示了我们模型的有效性。
我们导出了一种新的P&P模型,称为V2VNet,它利用空间感知图神经网络(GNN)聚合从附近所有SDV接收的信息,使我们能够智能地组合来自场景中不同时间点和视点的信息。
When2comm
先前关于学习沟通的工作[34,8]主要涉及简单感知环境下的决策任务(而不是改善感知)。此外,这些方法也不考虑带宽限制:它们学习在完全连接的图上进行通信(即,所有代理通过广播相互通信)。这种方法不能随着代理数量的增加而扩展。类似地,由于所有信息都是广播的,所以没有根据需要来决定何时进行通信。当局部观测足以用于预测时,代理不需要消耗带宽。当其他代理发送的消息降级或不相关时,通信可能会对感知任务不利。
文章首先介绍了一个三阶段的通信机制,包括请求、匹配和选择,然后通过实验证明了该方法在协作语义分割和多视角3D形状识别等感知任务上的优越性。
DiscoNet
为了处理性能-带宽权衡,已经提出了中间协作[19,34,20]来聚合跨代理的中间特征,由于我们可以将代表性信息压缩为紧凑的特征,这种方法既有可能实现通信带宽效率,又有可能提升感知能力;然而,糟糕的协作策略设计可能会导致特征提取和融合过程中的信息丢失,从而限制感知能力的提高。
作为多智能体系统的核心组件,智能体之间的通信策略在以前的工作中得到了积极的研究[30,7,31]。例如,
CommNet[32]采用平均运算来实现多智能体系统中的连续通信;
VAIN[11]考虑了一种注意力机制来确定哪些代理将共享信息;
ATOC[12]利用注意力单元来确定与其他代理共享什么信息;
TarMAC[5]隐式地学习了一种基于签名的软注意机制,以让代理主动选择哪些代理应该接收消息。
Learning to Communicate and Correct Pose Errors[33]提出了一种姿态误差回归模块,用于在来自其他代理的姿态信息有噪声时学习校正姿态误差。
本文介绍了一种新的多智能体知觉方法,称为蒸馏协作图(DiscoGraph),DiscoGraph可以通过知识蒸馏来训练,并具有矩阵值边缘权重,使每个智能体可以自适应地突出显示信息
- 首先,以前的协同感知只依赖于最终的检测监督;而DiscoNet同时利用检测监督和中间特征监督,获得更明确的指导。
- 其次,以往方法中的协作注意力是一个标量,不能反映每个区域的重要性;而DiscoNet使用矩阵,从而在各个空间区域实现更灵活的协作。
- 第三,以前的方法使用多轮协作:When2com在第一次握手后至少需要再进行一轮通信,V2VNet声称需要三轮通信以确保可靠的性能;而DiscoNet只需要一轮,延迟更少。
诚然,DiscoNet假设每个代理的姿势都是准确的,这是有局限性的,可以通过[33]这样的方法来改进。
AttFusion
由于来自不同连接车辆的传感器观测可能携带不同的噪声水平(例如,由于车辆之间的距离),因此一种能够关注重要观测而忽略干扰观测的方法对于稳健检测至关重要。因此,我们提出了一个关注中间融合管道来捕捉相邻连接车辆特征之间的相互作用,帮助网络关注关键观测结果。所提出的注意力中间融合管道由6个模块组成:元数据共享、特征提取、压缩、特征共享、注意力融合和预测。
V2X-ViT
尽管V2V技术有可能彻底改变移动行业,但它忽略了一个关键的合作者——路边基础设施。AV的存在通常是不可预测的,而一旦安装在十字路口和人行横道等关键场景中,基础设施总是可以提供支持。此外,在高架位置配备传感器的基础设施视野更开阔,遮挡可能更小。与所有代理都是同质的V2V协作不同,V2X系统通常涉及由基础设施和AV形成的异构图。基础设施和车辆传感器之间的配置差异,如类型、噪音水平、安装高度,甚至传感器属性和模态,使V2X感知系统的设计具有挑战性。此外,GPS定位噪声以及AV和基础设施的异步传感器测量可能会引入不准确的坐标变换和滞后的传感信息。
未能妥善处理这些挑战将使系统变得脆弱。
在本文中,我们将V2X感知视为一个异构的多智能体感知系统,不同类型的智能体(即智能基础设施和AV)感知周围环境并相互通信。为了模拟真实世界的场景,我们假设所有代理都具有不完美的定位,并且在特征传输过程中存在时间延迟。该模型通过交替使用异构多智能体自注意力和多尺度窗口自注意力模块,有效地融合了道路上的智能体(即车辆和基础设施)之间的信息。
CRCNet
据我们所知,如何在增强协作感知的互补性的同时最大限度地减少信息冗余是没有涉及的。为了实现冗余最小化和互补最大化之间的平衡,我们引入了一种互补增强和冗余最小化的协作网络(CRCNet)。CRCNet结合了渠道和空间关注,贪婪地融合来自其他代理的特征,旨在选择最互补和最不冗余的特征。具体来说,融合特征由两个标准来指导和监督。第一个标准声称每个融合特征都有边际性能增益,即有额外融合特征的检测性能可能比没有融合的检测性能更好。另一个标准要求两个融合特征之间的独立性,即应用互信息来捕捉非线性统计独立性,并最小化互信息上界以消除融合特征对之间的信息冗余。
CoBERT
先前的几项工作已经证明了利用激光雷达传感器进行协作感知的有效性[10,11,12,13]。然而,这种V2V合作是否、何时以及如何有利于基于相机的感知系统,目前尚未探索。与以前的多智能体算法相比,我们的CoBEVT是第一个使用稀疏变换器来高效、详尽地探索车辆之间的相关性的算法。此外,以前的方法主要关注与激光雷达的协同感知,而我们的目标是提出一种低成本的基于相机的无激光雷达设备的协同感知解决方案。
本文主要介绍了一种名为CoBEVT的多智能体多摄像头感知框架,可以协作性地生成鸟瞰图(BEV)地图预测,采用了一种名为FAX的稀疏注意力机制,可以在视野和智能体之间捕捉局部和全局的空间交互作用,实现高效融合多视角和多代理数据。
Where2comm
所有以前的工作都做出了一个合理的假设:一旦两个代理协作,它们就有义务平等地共享所有空间区域的感知信息。这种不必要的假设可以极大地浪费带宽,因为很大一部分空间区域可能包含与感知任务无关的信息。
为了填补这一空白,我们考虑了一种新颖的空间置信度感知通信策略。其核心思想是为每个代理启用空间置信度图,其中每个元素反映相应空间区域的感知临界水平。基于这个地图,代理决定要传达哪个空间区域(在哪里)。
Double-M
最近的研究表明,协同检测的早期、晚期和中期融合是有效的,分别传输原始数据、输出边界框和中间特征[2]、[3]、[4]、[5]、[6],改进的协同目标检测结果将有利于联网和自动驾驶汽车的自驾决策[7]。然而,由于物体分布不均匀、传感器测量噪声或恶劣天气[8]、[9]、[10],CAV在物体检测方面仍可能存在不确定性。即使是轻微的错误检测也会导致自动驾驶汽车的驾驶策略发生完全不同的行为[11],[12]。例如,未检测到路面上的油漆可能会混淆车道跟随政策,并导致潜在事故[13]。因此,量化CAV等安全关键系统的目标检测的不确定性至关重要。
Double-M该方法可以在一个推理过程中同时捕捉到认知不确定性和随机不确定性,利用离线的Double-M训练过程并可以与不同的协作目标检测器一起使用。
CoCa3D
在大多数情况下,仅摄像头的3D检测明显且始终不如基于激光雷达的检测
但是在本文中,我们提出了通过引入多智能体协作来提高仅相机的3D检测性能。假设,在先进的通信系统的支持下,只配备摄像头的多个代理可以彼此共享视觉信息。这将带来三个显著的好处。
- 首先,来自多个agent的不同视角可以在很大程度上解决仅摄像头3D检测中的深度模糊问题,弥补了与昂贵的激光雷达在深度估计方面的差距
- 其次,多智能体协作避免了单智能体3D检测中不可避免的局限性,如遮挡和远程问题,并有可能实现更全面的3D检测;即检测3D场景中存在的所有物体,包括超出视觉范围的物体。由于激光雷达的视野有限,因此协作相机的性能可能会超过激光雷达。
- 第三,由于相机数量多,大大降低了大型车队的总费用,比激光雷达便宜。
根据这一设计原理,我们提出了一种新型的协同相机3D检测框架CoCa3D。它包括三个部分:i)单智能体相机三维检测,实现每个智能体的基本深度估计和三维检测;Ii)协同深度估计,通过提高多个智能体视点的空间一致性来消除估计深度的歧义;iii)协同检测特征学习,通过相互共享关键检测消息来补充检测特征。

