
- 1教你如何在vue项目中封装通用的axios_vue 封装axios code
- 2EXCEL 2016 冻结窗口(首行首列,多行多列)_冻结窗口怎么冻结多行多列
- 3句子迷,语录,苏引华
- 4使用wget批量下载geo数据集的全部文件 linux下载geo数据 geo处理的数据不是下载原始数据 Linux如何下载ftp文件 geo ftp geo ftp下载 geo下载_linux系统下载geo的数据
- 5thingsboard从搭建环境到安装部署,给安装出错,或者安装失败的小伙伴现场写一遍(修正版)_找不到lwm2m-registry
- 6快应用开发初体验_快应用 webview
- 7详解边缘计算系统逻辑架构:云、边、端协同
- 8Dynamic Web Module facet version问题_dynamic web module facet version (5.0), was not fo
- 9Linux小项目-倒车影像功能设计_linux车机 项目
- 10Gradle的下载与安装教程
深度学习实战——模型推理优化(模型压缩与加速)
赞
踩
忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录
系列文章目录
本系列博客重点在深度学习相关实践(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 深度学习实战——不同方式的模型部署(CNN、Yolo)_如何部署cnn_@李忆如的博客
第二章 深度学习实战——卷积神经网络/CNN实践(LeNet、Resnet)_@李忆如的博客-CSDN博客
第三章 深度学习实战——循环神经网络(RNN、LSTM、GRU)_@李忆如的博客-CSDN博客
第四章 深度学习实战——模型推理优化(模型压缩与加速)
梗概
本篇博客主要介绍几种模型推理优化方法的原理,并进行了代码实践与优化(内含代码与数据集)。
一、实验思路综述
本章主要对实验思路、环境、步骤进行综述,梳理整个实验报告架构与思路,方便定位。
1.实验工具及内容
本次实验主要使用Pycharm与部分主流机器学习平台完成几种模型压缩理论研究及其代码实现与优化,并通过不同模型压缩及其压缩前后的消融实验采集数据分析后进行性能对比。另外,在实训文档的基础上通过论文与资料研读了其他模型优化工具包,进一步优化模型推理性能,并给出了一定改进思路。
2.实验数据
本次实验大部分数据来自模型官方数据集或自生成测试数据集,部分数据来源于网络。
3.实验目标
本次实验目标主要是深度剖析几种模型压缩与推理优化的方法,包括其原理、实践,并了解不同参数的意义与对模型的贡献度(性能影响),通过实践完成不同方法、参数情况的性能对比与优化对比,指导真实项目开发中应用。
4.实验步骤
本次实验大致流程如表1所示:
表1 实验4流程
| 1.实验思路综述 |
| 2.模型压缩与加速综述 |
| 3.模型压缩实践 |
二、模型压缩与加速综述
随着移动端设备计算能力的不断提升,移动端AI落地也成为了可能。相比于服务端,移动端模型的优势如下:
- 减轻服务端计算压力,并利用云端一体化实现负载均衡。特别是在双11等大促场景,服务端需要部署很多高性能机器,才能应对用户流量洪峰。平时用户访问又没那么集中,存在巨大的流量不均衡问题。直接将模型部署到移动端,并在置信度较高情况下直接返回结果,而不需要请求服务端,可以大大节省服务端计算资源。同时在大促期间降低置信度阈值,平时又调高,可以充分实现云端一体负载均衡。
- 实时性好,响应速度快。在feed流推荐和物体实时检测等场景,需要根据用户数据的变化,进行实时计算推理。如果是采用服务端方案,则响应速度得不到保障,且易造成请求过于密集的问题。利用端计算能力,则可以实现实时计算。
- 稳定性高,可靠性好。在断网或者弱网情况下,请求服务端会出现失败。而采用端计算,则不会出现这种情况。在无人车和自动驾驶等可靠性要求很高的场景下,这一点尤为关键,可以保证在隧道、山区等场景下仍能稳定运行。
- 安全性高,用户隐私保护好。由于直接在端上做推理,不需要将用户数据传输到服务端,免去了网络通信中用户隐私泄露风险,也规避了服务端隐私泄露问题
移动端部署深度学习模型也有很大的挑战。主要表现在,移动端等嵌入式设备,在计算能力、存储资源、电池电量等方面均是受限的。故移动端模型必须满足模型尺寸小、计算复杂度低、电池耗电量低、下发更新部署灵活等条件。因此模型压缩和加速就成为了目前移动端AI的一个热门话题。
模型压缩和加速不仅仅可以提升移动端模型性能,在服务端也可以大大加快推理响应速度,并减少服务器资源消耗,大大降低成本。结合移动端AI模型和服务端模型,实现云端一体化,是目前越来越广泛采用的方案。
Tips:参数过大/网络过深导致的时间复杂度也是模型压缩与加速的必要性背景。
模型压缩和加速是两个不同的话题,有时候压缩并不一定能带来加速的效果,有时候又是相辅相成的。压缩重点在于减少网络参数量,加速则侧重在降低计算复杂度、提升并行能力等。模型压缩和加速可以从多个角度来优化。总体来看,个人认为主要分为三个层次:
- 算法层压缩加速。这个维度主要在算法应用层,也是大多数算法工程师的工作范畴。主要包括结构优化(如矩阵分解、分组卷积、小卷积核等)、量化与定点化、模型剪枝、模型蒸馏等。
- 框架层加速。这个维度主要在算法框架层,比如tf-lite、NCNN、MNN等。主要包括编译优化、缓存优化、稀疏存储和计算、NEON指令应用、算子优化等
- 硬件层加速。这个维度主要在AI硬件芯片层,目前有GPU、FPGA、ASIC等多种方案,各种TPU、NPU就是ASIC这种方案,通过专门为深度学习进行芯片定制,大大加速模型运行速度。
本章将针对模型压缩与加速两个维度进行综述解析,以便平滑过渡到第二章实践部分。

图1 经典网络模型参数与计算量对比
1.模型压缩
深度神经网络在人工智能的应用中,包括语音识别、计算机视觉、自然语言处理等各方面,在取得巨大成功的同时,这些深度神经网络需要巨大的计算开销和内存开销,严重阻碍了资源受限下的使用。模型压缩是对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在受限的硬件环境中。
许多网络结构中,如VGG-16网络,参数数量1亿3千多万,占用500MB空间,需要进行309亿次浮点运算才能完成一次图像识别任务。相关研究表明,并不是所有的参数都在模型中发挥作用,存在着大量冗余地节点,仅仅只有少部分(5-10%)权值参与着主要的计算,也就是说,仅仅训练小部分的权值参数就可以达到和原来网络相近的性能。
模型压缩问题的定义可以从3角度出发:
Ⅰ、模型压缩的收益:
⚪ 计算: 减少浮点运算量(FLOPs),降低延迟(Latency)
⚪ 存储: 减少内存占用,提高 GPU/NPU 计算利用率
Ⅱ、公式定义模型压缩问题:
Ⅲ、模型压缩问题的约束:
模型压缩方法主要有:紧凑模型设计、剪枝、量化、低秩近似/分解、知识蒸馏,简介汇总于表2:
表2 模型压缩方法简介汇总
| 模型压缩方法 | 描述 | 应用场景 | 方法细节 |
| 紧凑模型设计 | 设计特别的卷积和来保存参数 | 只有卷积层 | 设计了特殊的结构卷积滤波器来降低存储和计算复杂度,只能从零开始训练 |
| 剪枝 | 删除对准确率影响不大的参数 | 卷积和全连接层 | 针对模型参数的冗余性,试图去除冗余和不重要的项,支持从零训练和预训练 |
| 量化 | 指将神经网络的浮点算法转换为定点算法 | 卷积、全连接、激活、BN层等 | 以低于浮点精度的位宽执行计算和存储张量的技术。允许更紧凑的模型表示和在许多硬件平台上使用高性能矢量化操作 |
| 低秩近似/分解 | 使用矩阵对参数进行分解估计 | 卷积和全连接层 | 使用矩阵/张量分解来估计深度学习模型的信息参数,支持从零训练和预训练 |
| 知识蒸馏 | 训练一个更紧凑的神经网络来从大的模型蒸馏知识 | 卷积和全连接层 | 通过学习一个蒸馏模型,训练更紧凑的神经网络来重现更大的网络输出,只能从零开始训练 |
从一个角度来说,按照压缩过程对网络结构的破坏程度,《解析卷积神经网络》一书中将模型压缩技术分为“前端压缩”和“后端压缩”两部分,
- 前端压缩:是指在不改变原网络结构的压缩技术,主要包括知识蒸馏、轻量级网络(紧凑的模型结构设计)以及滤波器(filter)层面的剪枝(结构化剪枝)等;
- 后端压缩:是指包括低秩近似、未加限制的剪枝(非结构化剪枝/稀疏)、参数量化以及二值网络等,目标在于尽可能减少模型大小,会对原始网络结构造成极大程度的改造。
1.1 紧凑(轻量化)模型设计
轻量级网络的核心是在尽量保持精度的前提下,从体积和速度两方面对网络进行轻量化改造。关于如何手动设计轻量级网络的研究,目前还没有广泛通用的准则,只有一些指导思想,和针对不同芯片平台(不同芯片架构)的一些设计总结,建议大家从经典论文中吸取指导思想和建议,然后自己实际做各个硬件平台的部署和模型性能测试。
以卷积神经网络为例,典型工作有Mobilenet系列网络、ShuffleNet系列网络、RepVGG、CSPNet、VoVNet等论文,主要思想是利用计算量更小、更分散的卷积操作代替标准卷积。也有将5x5卷积替换为两个3x3卷积、深度可分离卷积(3x3卷积替换为1*1卷积(降维作用)+3*3卷积)等轻量化设计。其他论文解析可见cv_note/7-model_compression at master · GitHub。而对设计高效CNN的一些结论与建议如下:
- 一些结论
Ⅰ、分析模型的推理性能得结合具体的推理平台(常见如:英伟达 GPU、移动端 ARM CPU、端侧 NPU 芯片等);目前已知影响 CNN 模型推理性能的因素包括: 算子计算量 FLOPs(参数量 Params)、卷积 block 的内存访问代价(访存带宽)、网络并行度等。但相同硬件平台、相同网络架构条件下, FLOPs 加速比与推理时间加速比成正比。
Ⅱ、建议对于轻量级网络设计应该考虑直接 metric(例如速度 speed),而不是间接 metric(例如 FLOPs)。
Ⅲ、FLOPs 低不等于 latency 低,尤其是在有加速功能的硬体 (GPU、DSP 与 TPU)上不成立,得结合具硬件架构具体分析。
Ⅳ、不同网络架构的 CNN 模型,即使是 FLOPs 相同,但其 MAC 也可能差异巨大。
Ⅴ、Depthwise 卷积操作对于流水线型 CPU、ARM 等移动设备更友好,对于并行计算能力强的 GPU 和具有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。Depthwise 卷积算子实际上是使用了大量的低 FLOPs、高数据读写量的操作。因为这些具有高数据读写量的操作,再加上多数时候 GPU 芯片算力的瓶颈在于访存带宽,使得模型把大量的时间浪费在了从显存中读写数据上,从而导致 GPU 的算力没有得到“充分利用”。
- 一些建议
Ⅰ、在大多数的硬件上,channel 数为 16 的倍数比较有利高效计算。如海思 351x 系列芯片,当输入通道为 4 倍数和输出通道数为16倍数,时间加速比会近似等于 FLOPs 加速比,有利于提供 NNIE 硬件计算利用率。
Ⅱ、低 channel 数的情况下 (如网路的前几层),在有加速功能的硬件使用普通 convolution 通常会比 separable convolution 有效率。
Ⅲ、四个高效网络设计的实用指导思想: G1同样大小的通道数可以最小化 MAC、G2-分组数太多的卷积会增加 MAC、G3-网络碎片化会降低并行度、G4-逐元素的操作不可忽视。
Ⅳ、GPU 芯片上 3x3卷积非常快,其计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
Ⅴ、从解决梯度信息冗余问题入手,提高模型推理效率。比如CSPNet网络。
Ⅵ、从解决 DenseNet 的密集连接带来的高内存访问成本和能耗问题入手,如 VoVNet 网络,其由 OSA(One-Shot Aggregation,一次聚合)模块组成。
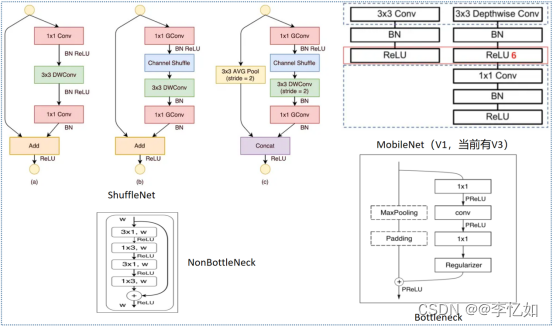
图3 经典/常见的紧凑(轻量化)模型设计架构
补充:紧凑(轻量化)模型结构设计也有分为分组卷积(ShuffleNet、MobileNet)、分解卷积(Bottleneck)等不同方式,还有SqueezeNet、神经网络搜索等设计图3没有提到。
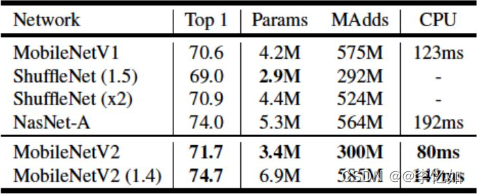
图4 几种紧凑(轻量化)模型设计效果比较
同样一般紧凑(轻量化)模型设计会搭配轻量化部署,在这里简单介绍,在阅读和理解经典的轻量级网络 mobilenet 系列、MobileDets、shufflenet 系列、cspnet、vovnet、repvgg 等论文的基础上,做了以下总结:
- 低算力设备-手机移动端 cpu 硬件,考虑 mobilenetv1(深度可分离卷机架构-低 FLOPs)、低 FLOPs 和 低MAC的shuffletnetv2(channel_shuffle 算子在推理框架上可能不支持)
- 专用 asic 硬件设备-npu 芯片(地平线 x3/x4 等、海思 3519、安霸cv22 等),分类、目标检测问题考虑 cspnet 网络(减少重复梯度信息)、repvgg2(即 RepOptimizer: vgg 型直连架构、部署简单)
- 英伟达 gpu 硬件-t4 芯片,考虑 repvgg 网络(类 vgg 卷积架构-高并行度有利于发挥 gpu 算力、单路架构省显存/内存,问题: INT8 PTQ 掉点严重)
MobileNet block (深度可分离卷积 block, depthwise separable convolution block)在有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。
下图5是 MobileNetv2 和 ResNet50 在一些常见 NPU 芯片平台上做的性能测试结果。
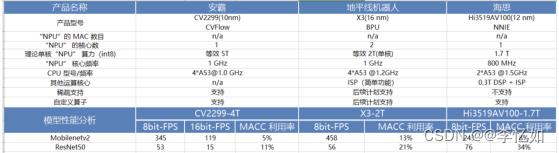
图5 MobileNetv2 和 ResNet50 在一些常见 NPU 芯片平台上性能效果比较
Tips:以上均是根据轻量级网络论文总结出来的一些不同硬件平台部署轻量级模型的经验,实际结果还需要自己手动运行测试。
1.2 低秩近似/分解
低秩分解的基本(核心)思想: 将原来大的权重矩阵分解成多个小的矩阵,用低秩矩阵近似原有权重矩阵,如图6。这样可以大大降低模型分解之后的计算量,常常用于神经网络模型分解。常见方法有奇异值(SVD)分解与张量分解(CP、TD、BTD),优缺点汇总于表3,架构展示如图7所示:
表3 低秩近似/分解优缺点
| 优点 | 缺点 |
| 可以降低存储和计算消耗 | 利用低秩近似重构参数矩阵不能保证模型的性能 |
| 一般可以压缩2-3倍 | 随着模型复杂度的提升,搜索空间急剧增大 |
| 精度几乎没有损失 |
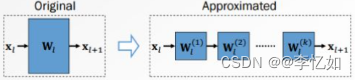
图6 低秩近似/分解核心原理
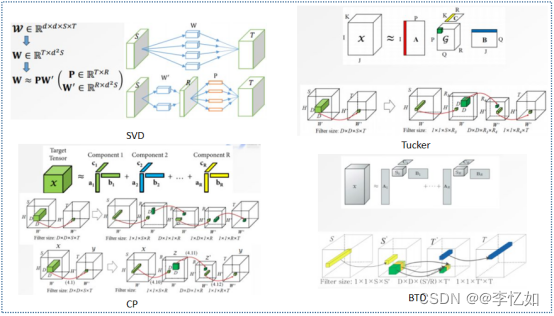
图7 低秩近似/分解常见方法核心原理/架构
一些低秩近似/分解的经典论文如下:
2014-Jaderberg M, Vedaldi A, Zisserman A. Speeding up convolutional neural networks with low rank expansions
2014-Exploiting Linear StructureWithin Convolutional Networks for Efficient Evaluation
2015-NPIS-Structured transforms for small footprint deep learning
2015-Accelerating Very Deep Convolutional Networks for Classification and Detection
2014-Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition
2015-Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications
2017-High performance ultra-low-precision convolutions on mobile devices
实际上,Low-Rank在目前的实际应用中不再流行了,除了上文提及的分解方法显而易见、比较容易实现之外,另外一个比较重要的原因是现在越来越多网络中小的卷积,使用矩阵分解的方法很难实现网络加速和压缩。
1.3 知识蒸馏
知识蒸馏(knowledge distillation),属于迁移学习的一种,核心就是训练一个大模型(teacher 模型)和一个小模型(student 模型),将庞大而复杂的大模型学习到的知识,通过一定技术手段迁移到精简的小模型上,从而使小模型能够获得与大模型相近的性能。也可说让小模型去拟合大模型,从而让小模型学到与大模型相似的函数映射。使其保持其快速的计算速度前提下,同时拥有复杂模型的性能,达到模型压缩的目的。
知识蒸馏的关键在于监督特征的设计,这个领域的开篇之作-Distilling the Knowledge in a Neural Network使用Soft Target所提供的类间相似性作为依据去指导小模型训练(软标签蒸馏 KD)。后续工作也有使用大模型的中间层特征图或attention map(features KD 方法)作为监督特征,对小模型进行指导训练。
以经典的知识蒸馏实验为例,我们先训练好一个 teacher 网络,然后将 teacher 的输出结果q 作为 student 网络的目标训练,使得 student 网络的结果 p 接近 q ,因此,student 的损失函数为L = CE(y,p) + αE(q,p) 。这里 CE 是交叉熵,y 是真实标签 onehot 编码。
但是,直接使用 teacher 网络的 softmax 的输出结果 q ,可能不大合适。因为,一个网络训练好之后,对于正确的答案会有一个很高的置信度而错误答案的置信度会很小。这样的话,teacher 网络学到数据的相似信息很难传达给 student 网络,因为它们的概率值接近0。因此,论文提出了 softmax-T(软标签计算公式),如式1所示:
式1 softmax-T(软标签计算公式)
Tips:这里qi是student网络学习的对象,zi是teacher模型softmax前一层的输出logit。如果将T取1,上述公式等同于softmax,根据logit输出各个类别的概率。如果T接近于 0,则最大值会越近1,其它值会接近0,近似于onehot编码。
所以,可以知道student模型最终的损失函数由两部分组成:
- 第一项是由小模型的预测结果与大模型的“软标签”所构成的交叉熵
- 第二项为预测结果与普通类别标签的交叉熵
这两个损失函数的重要程度可通过一定的权重进行调节,在实际应用中,T的取值会影响最终的结果,一般而言,较大的T能够获得较高的准确度。T(蒸馏温度参数)属于知识蒸馏模型训练超参数的一种。T是一个可调节的超参数、T 值越大、概率分布越软(论文中的描述),曲线便越平滑,相当于在迁移学习的过程中添加了扰动,从而使得学生网络在借鉴学习的时候更有效、泛化能力更强,这其实就是一种抑制过拟合的策略。
知识蒸馏算法整体的框架图如图8所示,核心架构如图9所示:
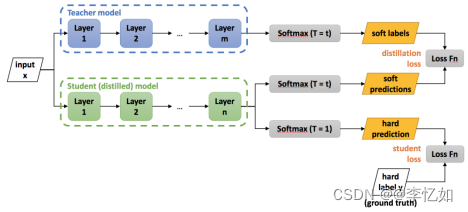
图8 知识蒸馏整体框架
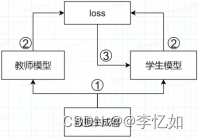
图9 知识蒸馏核心架构
1.4 剪枝
深度学习模型中一般存在着大量冗余的参数,将权重矩阵中相对“不重要”的权值剔除(即置为 0),可达到降低计算资源消耗和提高实时性的效果,而对应的技术则被称为模型剪枝,或称模型疏松化,核心如图10所示:
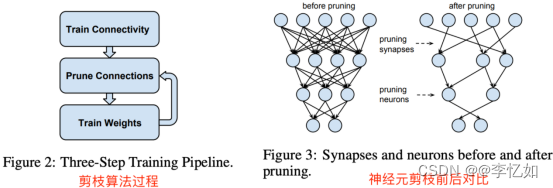
图10 剪枝过程与前后对比
上图是典型的三段式剪枝算法 pipeline,主要是 3 个步骤:(1)正常训练模型、(2)模型剪枝、(3)重新训练模型,以上三个步骤反复迭代进行,直到模型精度达到目标,则停止训练。
模型剪枝算法根据粒度的不同,可以粗分为细粒度剪枝和粗粒度剪枝,如下所示:
1、细粒度剪枝:对连接或者神经元进行剪枝,它是粒度最小的剪枝。
2、向量剪枝:它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
3、核剪枝:去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
4、滤波器剪枝:也叫通道剪枝,对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变,滤波器剪枝的工作是目前研究最多的。
按照剪枝是否规则,剪枝算法也可分为:
- 非结构化剪枝,其实就是前面的 1,具有更高的模型压缩率和准确性,对硬件支持不友好,需要设定特定硬件加速器,典型代表作是韩松 2016 年的论文。
- 结构化剪枝,如 2、3、4,对硬件支持友好,典型代表作如 Learning Efficient Convolutional Networks through Network Slimming 等。
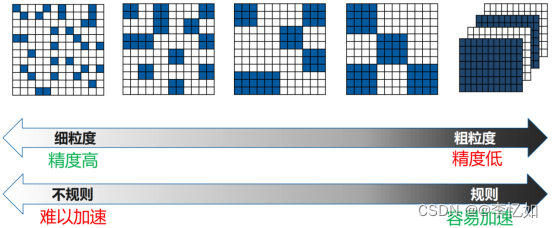
图11 剪枝分类与比较
综上所述,深度神经网络的权值稀疏应该在模型有效性和计算高效性之间做权衡。
1.5 量化
相比于剪枝操作,参数量化则是一种常用的后端压缩技术。所谓量化,其实可以等同于低精度运算概念,常规模型精度一般使用FP32(32 位浮点数,单精度)存储模型权重参数,低精度则表示使用INT8、FP16等权重数值格式。
模型量化(网络量化)过程分为两部分:(1)将模型的单精度参数转化为低精度参数、(2)模型推理过程中的浮点运算转化为定点运算,这个需要推理框架支持。
模型量化可以降低模型的存储空间、内存占用和计算资源需求,从而提高模型的推理速度,也是为了更好的适配移动端/端侧 NPU 加速器。
最后,现在工业界主流思路是模型训练使用高精度-FP32参数模型,模型推理使用低精度-INT8参数模型: 将模型从 FP32 转换为 INT8(量化算术过程),以及使用INT8推理。
1.5.1 模型量化的方案
在实践中将浮点模型转为量化模型的方法有以下三种方法:
1、data free:不使用校准集,传统的方法直接将浮点参数转化成量化数,使用上非常简单,但一般会带来很大精度损失。
2、calibration:基于校准集方案,通过输入少量真实数据进行统计分析。
3、finetune:基于训练 finetune 的方案,将量化误差在训练时仿真建模,调整权重使其更适合量化。好处是能带来更大的精度提升,缺点是要修改模型训练代码,开发周期较长。
按照量化阶段的不同,量化方法分为以下两种:
- Post-training quantization PTQ(训练后量化、离线量化);
- Quantization-aware training QAT(训练时量化,伪量化,在线量化)。
1.5.2 量化的分类
目前已知的加快推理速度概率较大的量化方法主要有:
1、二值化,其可以用简单的位运算来同时计算大量的数。对比从nvdia gpu到x86平台,1bit计算分别有5到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到 SIMD(单指令多数据流)的加速收益。
2、线性量化(最常见),又可细分为非对称,对称和ristretto几种。在nvdia gpu,x86、arm和部分 AI 芯片平台上,均支持8bit的计算,效率提升从 1 倍到 16 倍不等,其中 tensor core甚至支持4bit计算,这也是非常有潜力的方向。线性量化引入的额外量化/反量化计算都是标准的向量操作,因此也可以使用SIMD进行加速,带来的额外计算耗时不大。
3、对数量化,一种比较特殊的量化方法。两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。
1.6 混合方式
以上这些压缩与加速方法单独使用时能够获得很好的效果,但也都存在各自的局限性,组合使用可使它们互为补充,称为混合方式。参数剪枝、参数量化、低秩分解和参数共享经常组合使用,极大地降低了模型的内存需求和存储需求,方便模型部署到计算资源有限的移动平台。知识蒸馏可以与紧凑网络组合使用,为学生模型选择紧凑的网络结构,在保证压缩比的同时,可提升学生模型的性能。混合方式能够综合各类压缩与加速方法的优势,进一步加强了压缩与加速效果。
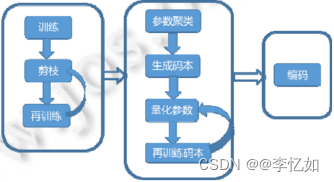
图12 混合方式样例
1.7 综述与比较
前六部分基本将主流的压缩方案进行了简介,本部分针对不同方案进行对比综述。首先我们先引入常见的压缩效果评价指标,包括运行效率、参数压缩率、准确率。与基准模型比较衡量性能提升时,可以使用提升倍数或提升比例,对比样例上文图4有提到,具体如下:
- 准确率:目前,大部分研究工作均会测量 Top-1 准确率,只有在ImageNet这类大型数据集上才会只用 Top-5 准确率。
- 参数压缩率:统计网络中所有可训练的参数,根据机器浮点精度转换为字节(byte)量纲,通常保留两位有效数字以作近似估计。
- 运行效率:可以从网络所含浮点运算次数(FLOP)、网络所含乘法运算次数(MULTS)或随机实验测得的网络平均前向传播所需时间这 3 个角度来评价。
同样,我们再补充一些不同压缩方法对同一深度网络的效果对比,如图13所示:
参考论文:高晗, 田育龙, 许封元, 等. 深度学习模型压缩与加速综述[J]. 软件学报, 2020, 32(1): 68-92.
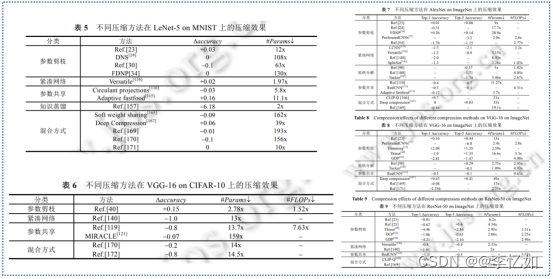
图13 不同压缩方法对同一模型的效果对比
根据上述解析与实训文档,我们总结一下模型压缩的主要方向与流程(本实验)如图14所示,简介如下:
- 架构设计:使用轻量型卷积核替代原有卷积核,或采用非标准卷积方式。包括手工设计方式或神经架构搜索方法。
- 知识蒸馏:用大模型参数引导小模型训练,使其萃取到大模型的知识。一般采用教师-学生训练,通常是已训好的教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识。它可以以轻微的性能损失为代价将复杂教师模型的知识迁移到简单的学生模型中。
- 网络剪枝:去除模型中贡献度较小的冗余信息,使模型参数变少。
- 参数量化:用更小的数据类型表达原来的数值,以降低运算量和消耗容量
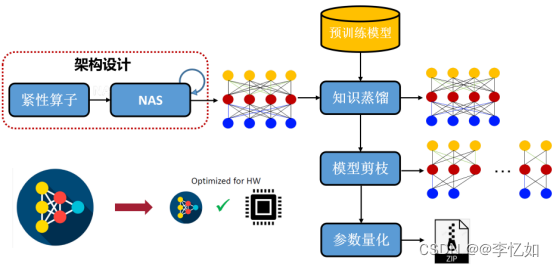
图14 模型压缩优化基本/主要流程
2.模型加速
上一节从不同的方案对比解析了不同模型压缩方法,在本节针对加速方法做一定介绍。加速/系统优化是指在特定系统平台上,通过Runtime层面性能优化,以提升AI模型的计算效率,与压缩方法有一定交集部分。
一般来说,常用的加速/系统优化方案可分为以下四点:
1、Op-level的算子优化:FFT Conv2d (7x7, 9x9), Winograd Conv2d (3x3, 5x5) 等;
2、Layer-level的快速算法:Sparse-block net [1] 等;
3、Graph-level的图优化:BN fold、Constant fold、Op fusion和计算图等价变换等;
4、优化工具与库(手工库、自动编译):TensorRT (Nvidia), MNN (Alibaba), TVM (Tensor Virtual Machine), Tensor Comprehension (Facebook) 和OpenVINO (Intel) 等;
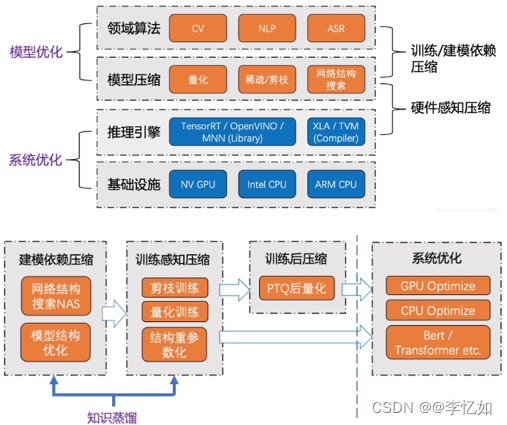
图15 推理加速整体架构(包含加速-压缩交集)
我们在本节主要介绍高性能推理引擎——TensorRT/TVM/MNN等(以TensorRT为例),是模型加速的主要方案之一。
TensorRT参考:NVIDIA TensorRT | NVIDIA Developer
TensorRT是NVIDIA推出的面向GPU应用部署的深度学习优化加速工具,即是推理优化引擎、亦是运行时执行引擎。TensorRT采用的原理如下图16所示,可分别在图优化、算子优化、Memory优化与INT8 Calibration等层面提供推理优化支持。
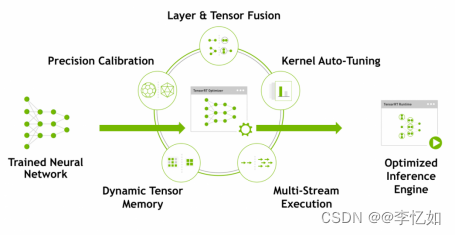
图16 TensorRT核心原理
TensorRT能够优化重构由不同深度学习框架训练的深度学习模型,可为深度学习推理应用提供低延迟和高吞吐量,优化详解如下:
- 全图自动优化:首先,对于Caffe、TensorFlow、MXNet或PyTorch训练的模型,若包含的操作都是TensorRT支持的,则可以直接通过TensorRT生成推理优化引擎;并且,对于PyTorch模型,亦可采用Trtorch执行推理优化;此外,亦可借助ONNX中间格式,通过(TF, PyTorch) -> ONNX -> TensorRT方式,执行优化转换等等。
- 全图手工优化:对于MXnet,PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接实现推理优化;
- 手工/自动分图:若训练的网络模型包含TensorRT不支持的Op:
1、手工分图:将深度网络手工划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部分可采用其他框架实现,如MXnet或PyTorch,并建议使用C++ API实现,以确保更高效的Runtime执行;
2、Custom Plugin:不支持的Op可通过Plugin API实现自定义,并添加进TensorRT计算图,以支持算子的Auto-tuning,从而丰富TensorRT的Op-set完备性,例如Faster Transformer的自定义扩展,Faster Transformer是较为完善的系统工程,能够实现标准Bert/Transformer的高性能计算;
3、TFTRT自动分图:TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点;FP32 TF TRT优化流程如下:
- from tensorflow.contrib import tensorrt as trt
- def transfer_trt_graph(pb_graph_def, outputs, precision_mode, max_batch_size):
- trt_graph_def = trt.create_inference_graph(
- input_graph_def = pb_graph_def,
- outputs = outputs,
- max_batch_size = max_batch_size,
- max_workspace_size_bytes = 1 << 25,
- precision_mode = precision_mode,
- minimum_segment_size = 2)
- return trt_graph_def
- trt_gdef = transfer_trt_graph(graph_def, output_name_list,'FP32', batch_size)
- input_node, output_node = tf.import_graph_def(trt_gdef, return_elements=[input_name, output_name])
-
- with tf.Session(config=config) as sess:
- out = sess.run(output_node, feed_dict={input_node: batch_data})
4、PyTorch自动分图:基于Torchscript自动分图,避免custom plugin或手工分图的低效支持,提升模型优化的支持效率;并降低用户使用TensorRT的门槛,自动完成计算图转换与优化tuning;对于不支持的Op或Sub-graph,采用Libtorch作为Runtime兜底(参考NVIDIA官方提供的优化加速工具pytorch/TensorRT,作为PyTorch编程范式的扩展):
INT8 Calibration:TensorRT的INT8量化需要校准数据集,能够反映真实应用场景,样本数量少则3~5个即可满足校准需求;且要求GPU的计算功能集sm >= 6.1;
当我们详细解构TensorRT的加速原理,即“三步论”如图17所示:
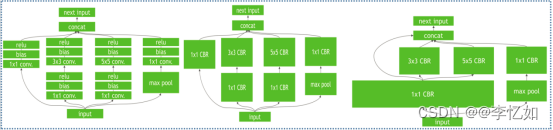
图17 TensorRT加速原理详解
而对于TensorRT的优化效果,我引入两个实验案例来说明:
(1)在1080ti平台上,基于TensorRT4.0.1,Resnet101-v2的优化加速效果如表4:
表4 TensorRT加速对比 - 实验1
| Network | Precision | Framework | Avg. Time | Top1 Val. Acc. |
| Resnet101 | FP32 | TensorFlow | 36.7 | 0.7612 |
| Resnet101 | FP32 | MXnet | 25.8 | 0.7612 |
| Resnet101 | FP32 | TRT4.0.1 | 19.3 | 0.7612 |
| Resnet101 | INT8 | TRT4.0.1 | 9 | 0.7574 |
(2)在1080ti/2080ti平台上,基于TensorRT5.1.5,Resnet101-v1d的FP16加速效果如表5(由于2080ti包含Tensor Core,因此FP16加速效果较为明显):
表5 TensorRT加速对比 - 实验2
| 网络 | 平台 | 数值精度 | Batch=8 | Batch=4 | Batch=2 | Batch=1 |
| Resnet101-v1d | 1080ti | FP32 | 19.4ms | 12.4ms | 8.4ms | 7.4ms |
| FP16 | 28.2ms | 16.9ms | 10.9ms | 8.1ms | ||
| INT8 | 8.1ms | 6.7ms | 4.6ms | 4ms | ||
| 2080ti | FP32 | 16.6ms | 10.8ms | 8.0ms | 7.2ms | |
| FP16 | 14.6ms | 9.6ms | 5.5ms | 4.3ms | ||
| INT8 | 7.2ms | 3.8ms | 3.0ms | 2.6ms |
分析:如表4与表5,可以明显看出加入TensorRT后的加速效果,验证了其加速能力。
最后根据官方描述补充TensorRT 优化与性能如图18所示:
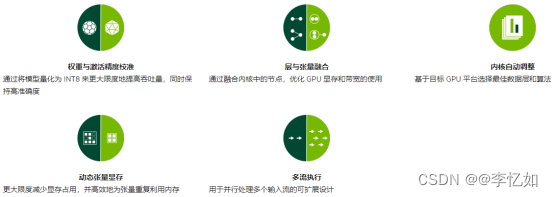
图18 TensorRT 优化与性能(官方描述)
Tips:还有很多常见的高性能引擎与加速方法,限于篇幅在这里不展开。
补充:对于压缩和加速方法的选择,在这里提供几点思路:
- 1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝方法,特别是二值量化权值和激活、结构化剪枝。其他方法虽然能够有效的压缩模型中的权值参数,但无法减小计算中隐藏的内存大小(如特征图)。
- 2)如果在应用中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要考虑的方法。相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法。
- 3)若需要一次性端对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法。
- 4)一般情况下,参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度。对于需要稳定的模型分类的应用,非结构化剪枝成为首要选择。
- 5)若采用的数据集较小时,可以考虑知识蒸馏方法。对于小样本的数据集,学生网络能够很好地迁移教师模型的知识,提高学生网络的判别性。
- 6)主流的5个深度神经网络压缩与加速算法相互之间是正交的,可以结合不同技术进行进一步的压缩与加速。如:韩松等人结合了参数剪枝和参数共享;温伟等人以及Alvarez等人结合了参数剪枝和低秩分解。此外对于特定的应用场景,如目标检测,可以对卷积层和全连接层使用不同的压缩与加速技术分别处理。
当然我们刚刚提到的方案主要是在算法设计或运行中进行压缩与加速,实际上硬件层的优化也是非常重要且常用的,以AI芯片为例,目前各大厂的方案及汇总如图19所示:
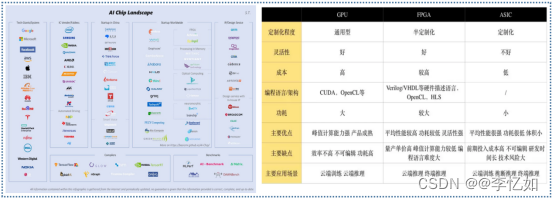
图19 AI芯片方案汇总与简介
二、模型压缩与加速实践
上一章从不同角度、不同方案对比综述了模型压缩与加速的核心知识,在本章将会根据实训文档、网络资料、过往真实项目对模型压缩与加速进行不同实践,并并通过不同模型压缩及其压缩前后的消融实验采集数据分析后进行性能对比。另外,在实训文档的基础上通过论文与资料研读了其他模型优化工具包,进一步优化模型推理性能,并给出了一定改进思路。
Tips:本章主要是实践、对比、优化,原理在上一章有解析,本章不做赘述。
1.模型压缩实践
首先在第一节先进行模型压缩的实践,主要参考实训文档的步骤,并在实训文档的基础上,从理论测与实践侧进一步尝试优化模型推理优化性能。
1.1 架构设计
根据图14,我们知道基于实训文档的压缩首步为构建一个紧凑(轻量化)的架构设计,根据实训文档的代码,我们构建一个用于知识蒸馏的轻量级学生网络的模型结构,代码如下:
- import torch.nn as nn
-
-
- class StudentNet(nn.Module):
- def __init__(self, base=16, width_mult=1):
- super(StudentNet, self).__init__()
-
- multiplier = [1, 2, 4, 8, 16, 16, 16, 16]
- bandwidth = [base * m for m in multiplier] # 每层输出的channel数量
- for i in range(3, 7): # 对3/4/5/6层进行剪枝
- bandwidth[i] = int(bandwidth[i] * width_mult)
- self.cnn = nn.Sequential(
- # 我们通常不会拆解第一个卷积
- nn.Sequential(
- nn.Conv2d(3, bandwidth[0], 3, 1, 1),
- nn.BatchNorm2d(bandwidth[0]),
- nn.ReLU6(),
- nn.MaxPool2d(2, 2, 0)
- ),
- # 接下来的每个Sequential都一样,所以只详细介绍接下来第一个Sequential
- nn.Sequential(
- # Depthwise Convolution
- nn.Conv2d(bandwidth[0], bandwidth[0], 3, 1, 1, groups=bandwidth[0]),
- # Batch Normalization
- nn.BatchNorm2d(bandwidth[0]),
- # 激活函数ReLU6可限制神经元激活值最小为0最大为6
- # MobileNet系列都是使用ReLU6。以便于模型量化。
- nn.ReLU6(),
- # Pointwise Convolution,之后不需要再做ReLU,经验上Pointwise + ReLU效果都会变化。
- nn.Conv2d(bandwidth[0], bandwidth[1], 1),
- # 每过完一个Block就下采样
- nn.MaxPool2d(2, 2, 0),
- ),
- nn.Sequential(
- nn.Conv2d(bandwidth[1], bandwidth[1], 3, 1, 1, groups=bandwidth[1]),
- nn.BatchNorm2d(bandwidth[1]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[1], bandwidth[2], 1),
- nn.MaxPool2d(2, 2, 0),
- ),
- nn.Sequential(
- nn.Conv2d(bandwidth[2], bandwidth[2], 3, 1, 1, groups=bandwidth[2]),
- nn.BatchNorm2d(bandwidth[2]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[2], bandwidth[3], 1),
- nn.MaxPool2d(2, 2, 0),
- ),
- # 目前图片已经进行了多次下采样,所以就不再做MaxPool
- nn.Sequential(
- nn.Conv2d(bandwidth[3], bandwidth[3], 3, 1, 1, groups=bandwidth[3]),
- nn.BatchNorm2d(bandwidth[3]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[3], bandwidth[4], 1),
- ),
- nn.Sequential(
- nn.Conv2d(bandwidth[4], bandwidth[4], 3, 1, 1, groups=bandwidth[4]),
- nn.BatchNorm2d(bandwidth[4]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[4], bandwidth[5], 1),
- ),
- nn.Sequential(
- nn.Conv2d(bandwidth[5], bandwidth[5], 3, 1, 1, groups=bandwidth[5]),
- nn.BatchNorm2d(bandwidth[5]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[5], bandwidth[6], 1),
- ),
- nn.Sequential(
- nn.Conv2d(bandwidth[6], bandwidth[6], 3, 1, 1, groups=bandwidth[6]),
- nn.BatchNorm2d(bandwidth[6]),
- nn.ReLU6(),
- nn.Conv2d(bandwidth[6], bandwidth[7], 1),
- ),
- # 如果输入图片大小不同,Global Average Pooling会把它们压成相同形状,这样接下来全连接层就不会出现输入尺寸不一致的错误
- nn.AdaptiveAvgPool2d((1, 1))
- )
-
- # 直接将CNN的输出映射到11维作为最终输出
- self.fc = nn.Sequential(
- nn.Linear(bandwidth[7], 11)
- )
-
- def forward(self, x):
- x = self.cnn(x)
-
- x = x.view(x.size(0), -1)
- x = self.fc(x)
- return x
- model = StudentNet()
- model.eval()
- from torchsummary import summary
- summary(model.to(), input_size=(3, 128, 128))

输出模型的参数信息如图20所示:
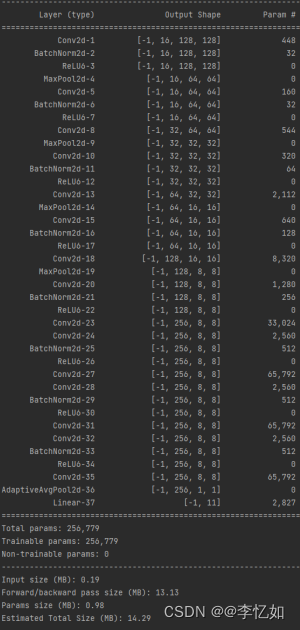
图20 架构设计参数信息输出展示
分析:如图20,与实训文档中给出的范例保持一致,即架构设计合理且正确。
我们对StudentNet的代码进行解析,在不改变架构设计的情况下探究参数对输出的影响(消融实验),本架构中主要参数及其含义简介如下:
- base:模型初始通道channel的数量
- width_mult:剪枝控制因子,为1时表示不剪枝。剪枝后通道数=剪枝前通道*width_mult
故接下来我们来定量分析两个参数对输出的影响。
(1)base
为探究base参数对StudentNet模型输出(参数量)的影响,我们固定width_mult = 1,改变base的值,观察并记录对应的Total params,数据汇总于表6,变化趋势如图21:
表6 StudentNet模型输出(参数量)随base的变化数据汇总
| base | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
| Total params | 1989 | 5,843 | 19,179 | 68,363 | 256,779 | 993,803 | 3,908,619 |
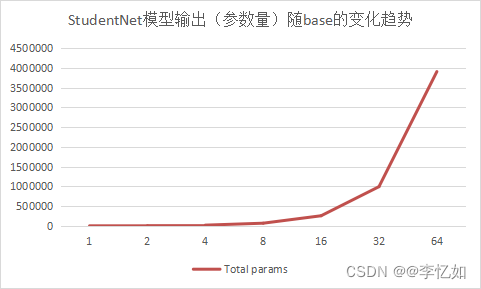
图21 StudentNet模型输出(参数量)随base的变化趋势
分析:如表6与图21所示,在实训文档中定义的StudentNet模型,输出(参数量)随base的增加而增加,且变化率不断提高。
(2)width_mult
与(1)同理,为探究width_mult参数对StudentNet模型输出(参数量)的影响,我们固定base = 16,改变width_mult的值,观察并记录对应的Total params,数据汇总于表7,变化趋势如图22:
表7 StudentNet模型输出(参数量)随width_mult的变化数据汇总
| width_mult | 1 | 2 | 3 | 4 | 5 |
| Total params | 256,779 | 833,675 | 1,738,251 | 2,970,507 | 4,530,443 |
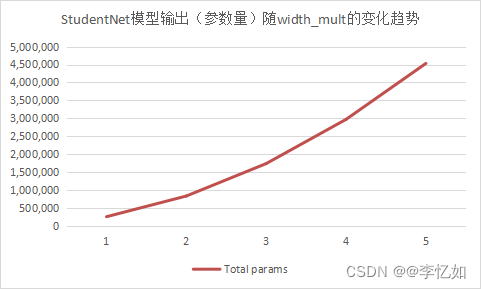
图22 StudentNet模型输出(参数量)随width_mult的变化趋势
分析:如表7与图22所示,在实训文档中定义的StudentNet模型,输出(参数量)随width_mult的增加而增加,且变化率不断降低。
1.2 知识蒸馏
1.1中我们定义了一个较轻量化的学生网络模型,本部分可用于知识蒸馏,核心流程为利用预训练模型作为老师(本实验为resnet18),并通过训练学习(本实验为Kaggle - food11图像数据集),最终使用知识蒸馏(迁移)给学生模型。知识蒸馏过程中的损失函数定义:
- hard loss:定义为预测标签与真实标签之间的交叉熵
- soft loss:让student的logits做log_softmax后对目标概率(teacher的logits/T后softmax)做KL Divergence。
根据实训文档编写代码如下:
- import numpy as np
- import torch
- import os
- import torch.nn as nn
- import torch.optim as optim
- import torch.nn.functional as F
- import torchvision.models as models
- import torchvision.transforms as transforms
- from PIL import Image
- from torch.utils.data import Dataset, DataLoader
- from torchvision.datasets import DatasetFolder
-
- # This is for the progress bar.
- from tqdm.auto import tqdm
-
- from student_model import StudentNet
-
- def loss_fn_kd(outputs, labels, teacher_outputs, T=20, alpha=0.5):
- # 一般的Cross Entropy
- hard_loss = F.cross_entropy(outputs, labels) * (1. - alpha)
-
- soft_loss = nn.KLDivLoss(reduction='batchmean')(F.log_softmax(outputs / T, dim=1),
- F.softmax(teacher_outputs / T, dim=1)) * (alpha * T * T)
- return hard_loss + soft_loss
-
-
- def run_epoch(data_loader, update=True, alpha=0.5):
- total_num, total_hit, total_loss = 0, 0, 0
- for batch_data in tqdm(data_loader):
- # 清空梯度
- optimizer.zero_grad()
- # 获取数据
- inputs, hard_labels = batch_data
- # Teacher不用反向传播,所以使用torch.no_grad()
- with torch.no_grad():
- soft_labels = teacher_net(inputs.to(device))
-
- if update:
- logits = student_net(inputs.to(device))
- # 使用前面定义的融合soft label&hard label的损失函数:loss_fn_kd,T=20是原论文设定的参数值
- loss = loss_fn_kd(logits, hard_labels.to(device), soft_labels, 20, alpha)
- loss.backward()
- optimizer.step()
- else:
- # 只是做validation的话,就不用计算梯度
- with torch.no_grad():
- logits = student_net(inputs.to(device))
- loss = loss_fn_kd(logits, hard_labels.to(device), soft_labels, 20, alpha)
-
- total_hit += torch.sum(torch.argmax(logits, dim=1) == hard_labels.to(device)).item()
- total_num += len(inputs)
-
- total_loss += loss.item() * len(inputs)
- return total_loss / total_num, total_hit / total_num
-
-
- if __name__ == '__main__':
- # config
- batch_size = 32
- cuda = False
- epochs = 30
- # "cuda" only when GPUs are available.
- device = "cuda:0" if torch.cuda.is_available() else "cpu"
-
- # 加载数据
- trainTransform = transforms.Compose([
- transforms.RandomCrop(256, pad_if_needed=True, padding_mode='symmetric'),
- transforms.RandomHorizontalFlip(),
- transforms.RandomRotation(15),
- transforms.ToTensor(),
- ])
-
- testTransform = transforms.Compose([
- transforms.CenterCrop(256),
- transforms.ToTensor(),
- ])
-
- train_set = DatasetFolder("training", loader=lambda x: Image.open(x),
- extensions="jpg", transform=trainTransform)
- valid_set = DatasetFolder("validation", loader=lambda x: Image.open(x), extensions="jpg",
- transform=testTransform)
-
- train_dataloader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
- valid_dataloader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
- print('Data Loaded')
-
- # 加载网络
- teacher_net = models.resnet18(pretrained=False, num_classes=11)
- teacher_net.load_state_dict(torch.load('./teacher_resnet18.bin',map_location="cpu"))
- student_net = StudentNet(base=16)
- # if cuda:
- # teacher_net = teacher_net.cuda(device)
- # student_net = student_net.cuda(device)
- print('Model Loaded')
-
- # 开始训练(Knowledge Distillation)
- print('Training Started')
- optimizer = optim.AdamW(student_net.parameters(), lr=1e-3)
- teacher_net.eval()
- now_best_acc = 0
- for epoch in range(epochs):
- student_net.train()
- train_loss, train_acc = run_epoch(train_dataloader, update=True)
- student_net.eval()
- valid_loss, valid_acc = run_epoch(valid_dataloader, update=False)
-
- # 存下最好的model
- if valid_acc > now_best_acc:
- now_best_acc = valid_acc
- torch.save(student_net.state_dict(), './student_model.bin')
- print('epoch {:>3d}: train loss: {:6.4f}, acc {:6.4f} valid loss: {:6.4f}, acc {:6.4f}'.format(
- epoch, train_loss, train_acc, valid_loss, valid_acc))
-
-
- # 运行一个epoch
- def run_teacher_epoch(data_loader, update=True, alpha=0.5):
- total_num, total_hit, total_loss, teacher_total_hit = 0, 0, 0, 0
- for batch_data in tqdm(data_loader):
- # 清空梯度
- optimizer.zero_grad()
- # 获取数据
- inputs, hard_labels = batch_data
- # Teacher不用反向传播,所以使用torch.no_grad()
- with torch.no_grad():
- soft_labels = teacher_net(inputs.to(device))
-
- if update:
- logits = student_net(inputs.to(device))
- # 使用前面定义的融合soft label&hard label的损失函数:loss_fn_kd,T=20是原论文设定的参数值
- loss = loss_fn_kd(logits, hard_labels, soft_labels, 20, alpha)
- loss.backward()
- optimizer.step()
- else:
- # 只是做validation的话,就不用计算梯度
- with torch.no_grad():
- logits = student_net(inputs.to(device))
- loss = loss_fn_kd(logits, hard_labels.to(device), soft_labels, 20, alpha)
-
- teacher_total_hit += torch.sum(torch.argmax(soft_labels, dim=1) == hard_labels.to(device)).item()
- total_hit += torch.sum(torch.argmax(logits, dim=1) == hard_labels.to(device)).item()
- total_num += len(inputs)
- total_loss += loss.item() * len(inputs)
- return total_loss / total_num, total_hit / total_num, teacher_total_hit / total_num
-
- student_net.eval()
- valid_loss, valid_acc, teacher_acc = run_teacher_epoch(valid_dataloader, update=False)
-
- print(valid_acc, teacher_acc)
测试样例如图23与图24所示:

图23 知识蒸馏实验训练过程

图24 知识蒸馏实验结果样例
Tips:训练结束后会生成student_model.bin用于后续剪枝实验。
分析:如图24,我们可以看到valid_acc,teacher_acc(分别对应学生模型与老师模型的效果,本实验为图像识别率)分别为0.719533527696793与0.8854227405247813。
从此案例中可以看出蒸馏后的student模型相比预训练的teacher模型,在性能上下降很多,以下针对这种情况进行分析:
首先简单回顾一下原理,知识蒸馏是一种通过将一个大模型的知识压缩到一个小模型中来加速和优化深度学习模型的方法,而出现学生差于老师的主要原因如下:
1、模型容量:教师模型通常具有更高的模型容量,可以更好地拟合训练数据。相比之下,学生模型通常具有较小的模型容量,因此在训练数据有限的情况下,很难学习到与教师模型相同的知识表示。
2、数据分布:教师模型通常训练于大规模数据集,因此有更好的数据表示能力。相比之下,学生模型的训练数据通常是有限的,因此难以学习到与教师模型相同的数据表示能力。
3、训练时长:教师模型通常需要花费更长的时间进行训练,以学习到复杂的知识表示。相比之下,学生模型的训练时间较短,难以学习到与教师模型相同的复杂知识表示。
4、模型结构:教师模型通常采用更深的神经网络结构,可以更好地捕捉输入数据的不同层次的特征。相比之下,学生模型的神经网络结构通常更浅,因此难以学习到与教师模型相同的特征表示。
5、损失函数:蒸馏过程中的损失函数通常采用不同的权重分配和超参数设置,会对蒸馏结果产生影响。如果没有选择合适的损失函数,则可能会导致学生模型的效果较差。
接下来让我们回归代码,从参数侧来提出几种可优化的点,本实验的参数如表8:
表8 知识蒸馏参数设置(本实验)
| 参数 | 取值 |
| batch_size | 32 |
| epoch | 30 |
| lr | 1e-3 |
| T | 20 |
类似1.1,我们可以对不同的参数进行消融实验,去探究在本实验中最好效果的参数组合,步骤与上文一致,在此不赘述。
通过参数优化,本实验的学生模型效果可从0.719533527696793提升至0.782166561272711,验证了优化设计的合理性与可行性。
补充:一些从不同层面做的优化详见:学生网络用知识蒸馏损失去逼近教师网络,如何提高学生网络的准确率? - 知乎 (zhihu.com)
1.3 剪枝
1.2中我们使用预训练的老师模型(resnet18)去知识蒸馏(迁移)给1.1中定义的学生模型,并通过不同层面的优化策略提升了学生模型的效果,而根据实训文档,在蒸馏之后我们还需要对模型进行剪枝。
根据实训文档,在本案例的真实剪枝实践之前,我们可以先进行单Module裁剪的尝试,,目前torch.nn.utils.prune中已经支持以下几种:
- RandomUnstructured
- L1Unstructured
- RandomStructured
- LnStructured
- CustomFromMask
除了上面提供的几种剪枝方案,用户还可以通过继承BasePruningMethod来自定义剪枝方法。 在选定相应的剪枝方法后,用户可以指定module以及需要pruning的参数的name,最后使用合适的参数,指定剪枝算法的参数。
在成功完成单Module裁剪的实践后,我们进入实际案例(即对1.2蒸馏后的模型进行剪枝),根据实训文档编写代码如下:
- import numpy as np
- import torch
- import os
- import pickle
- import torch.nn as nn
- import torch.optim as optim
- import torch.nn.functional as F
- import torchvision.models as models
- import torchvision.transforms as transforms
- from PIL import Image
- from torch.utils.data import Dataset, DataLoader
- from torchvision.datasets import DatasetFolder
-
- # This is for the progress bar
- from tqdm.auto import tqdm
-
-
- def encode16(params, save_path):
- """将params压缩到16bit,并保存到save_path"""
- custom_dict = {}
- for name, param in params.items():
- param = np.float64(param.numpy())
- # 有些变量不是ndarray而只是一个数字,这种变量不用压缩
- if type(param) == np.ndarray:
- custom_dict[name] = np.float16(param)
- else:
- custom_dict[name] = param
-
- pickle.dump(custom_dict, open(save_path, 'wb'))
-
- def decode16(fname):
- '''读取16bit的权重,还原到torch.tensor后以state_dict形式存储'''
- params = pickle.load(open(fname, 'rb'))
- custom_dict = {}
- for (name, param) in params.items():
- param = torch.tensor(param)
- custom_dict[name] = param
- return custom_dict
-
- def encode8(params, save_path):
- """将params压缩到8bit,并保存到save_path"""
- custom_dict = {}
- for (name, param) in params.items():
- param = np.float64(param.numpy())
- if type(param) == np.ndarray:
- min_val = np.min(param)
- max_val = np.max(param)
- param = np.round((param - min_val) / (max_val - min_val) * 255)
- param = np.uint8(param)
- custom_dict[name] = (min_val, max_val, param)
- else:
- custom_dict[name] = param
- pickle.dump(custom_dict, open(save_path, 'wb'))
-
- def decode8(fname):
- '''读取8bit的权重,还原到torch.tensor后以state_dict形式存储'''
- params = pickle.load(open(fname, 'rb'))
- custom_dict = {}
- for (name, param) in params.items():
- if type(param) == tuple:
- min_val, max_val, param = param
- param = np.float64(param)
- param = (param / 255 * (max_val - min_val)) + min_val
- param = torch.tensor(param)
- else:
- param = torch.tensor(param)
- custom_dict[name] = param
- return custom_dict
-
-
- if __name__ == '__main__':
- # 加载模型剪枝后的模型文件
- print(f"Original Cost: {os.stat('./student_model.bin').st_size} Bytes.")
- old_params = torch.load('./student_model.bin', map_location='cpu')
-
- encode16(old_params, './student_model_16bit.bin')
- print(f"16-bit Cost: {os.stat('./student_model_16bit.bin').st_size} Bytes.")
-
- encode8(old_params, './student_model_8bit.bin')
- print(f"8-bit Cost: {os.stat('./student_model_8bit.bin').st_size} Bytes.")
-
-
- def run_test_epoch(data_loader, student_net):
- total_num, total_hit = 0, 0
- for batch_data in tqdm(data_loader):
- # for batch_data in enumerate(data_loader):
- # 获取数据
- inputs, hard_labels = batch_data
-
- # 只是做validation的话,就不用计算梯度
- with torch.no_grad():
- logits = student_net(inputs.to(device))
-
- total_hit += torch.sum(torch.argmax(logits, dim=1) == hard_labels.to(device)).item()
- total_num += len(inputs)
-
- return total_hit / total_num
-
- batch_size = 64
- cuda = False
- epochs = 200
- device = "cuda:0" if torch.cuda.is_available() else "cpu"
-
- testTransform = transforms.Compose([
- transforms.CenterCrop(256),
- transforms.ToTensor(),
- ])
-
- valid_set = DatasetFolder("validation", loader=lambda x: Image.open(x), extensions="jpg", transform=testTransform)
-
- valid_dataloader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
- print('Data Loaded')
-
- from student_model import StudentNet
-
-
- student_net = StudentNet(base=16)
- student_net.load_state_dict(torch.load(f'./student_model.bin'))
-
- if cuda:
- student_net = student_net.cuda(device)
- print('Model Loaded')
-
- student_net.eval()
- valid_loss = run_test_epoch(valid_dataloader, student_net)
- print(valid_loss)
-
-
- student_net_16 = StudentNet(base=16)
- student_net_16.load_state_dict(decode16(f'./student_model_16bit.bin'))
-
- if cuda:
- student_net_16 = student_net_16.cuda(device)
- print('Model Loaded')
-
- student_net_16.eval()
- valid_loss = run_test_epoch(valid_dataloader, student_net_16)
- print(valid_loss)
-
-
- student_net_8 = StudentNet(base=16)
- student_net_8.load_state_dict(decode8(f'./student_model_8bit.bin'))
-
- if cuda:
- student_net_8 = student_net_8.cuda(device)
- print('Model Loaded')
-
- student_net_8.eval()
- valid_loss = run_test_epoch(valid_dataloader, student_net_8)
- print(valid_loss)
剪枝过程样例如图25,剪枝前后模型参数如图26与27,生成模型文件如图28所示:
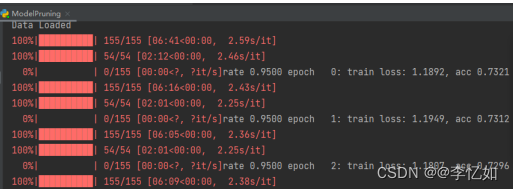
图25 模型剪枝过程样例
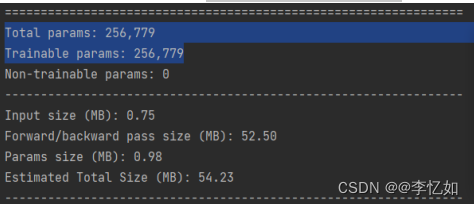
图26 模型剪枝前参数输出
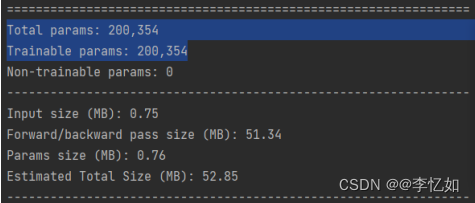
图27 模型剪枝后参数输出

图28 模型剪枝生成模型
分析:结合实训文档,根据图26与27,可以看出剪枝后模型参数输出量从256,779降到200,354,验证了剪枝对参数量优化的合理性与正确性。同时生成了三个对应比例模型(图28),与预期一致,故剪枝实验成功。
同样我们可以探究参数对于剪枝实验的影响,首先回归代码,相关参数设置如表9:
表9 模型剪枝参数设置(本实验)
| 参数 | 取值 |
| batch_size | 64 |
| prune_count | 3 |
| prune_rate | 0.95 |
| finetune_epochs | 20 |
| lr | 1e-3 |
类似1.1与1.2,我们可以对不同的参数进行消融实验,去探究在本实验中最好效果的参数组合,步骤与上文一致,在此不赘述。
1.4 量化
在前三节中我们分别定义了学生模型,并使用预训练的老师模型对其进行知识蒸馏,还对蒸馏后的学生模型进行了剪枝,而根据实训文档,本压缩实践的最后一步即对模型进行量化,即以低于浮点精度的位宽执行计算和存储张量的技术,本实验以16位量化与8位量化为量化例子,代码如下:
- import numpy as np
- import torch
- import os
- import pickle
- import torch.nn as nn
- import torch.optim as optim
- import torch.nn.functional as F
- import torchvision.models as models
- import torchvision.transforms as transforms
- from PIL import Image
- from torch.utils.data import Dataset, DataLoader
- from torchvision.datasets import DatasetFolder
-
- import torch.nn.utils.prune as prune
-
- from tqdm.auto import tqdm
-
-
- def network_slimming(old_model, new_model):
- old_params = old_model.state_dict()
- new_params = new_model.state_dict()
-
- # 只保留每一层中的部分卷积核
- selected_idx = []
- for i in range(8): # 只对模型中CNN部分(8个Sequential)进行剪枝
- gamma = old_params[f'cnn.{i}.1.weight']
- new_dim = len(new_params[f'cnn.{i}.1.weight'])
- ranking = torch.argsort(gamma, descending=True)
- selected_idx.append(ranking[:new_dim])
-
- now_processing = 1 # 当前在处理哪一个Sequential,索引为0的Sequential不需处理
- for param_name, weights in old_params.items():
- # 如果是CNN层,则根据gamma仅复制部分参数;如果是FC层或者该参数只有一个数字(例如batchnorm的tracenum等等)就直接全部复制
- if param_name.startswith('cnn') and weights.size() != torch.Size([]) and now_processing != len(selected_idx):
- # 当处理到Pointwise Convolution时,则代表正在处理的Sequential已处理完毕
- if param_name.startswith(f'cnn.{now_processing}.3'):
- now_processing += 1
-
- # Pointwise Convolution的参数会受前一个Sequential和后一个Sequential剪枝情况的影响,因此需要特别处理
- if param_name.endswith('3.weight'):
- # 不需要删除最后一个Sequential中的Pointwise卷积核
- if len(selected_idx) == now_processing:
- # selected_idx[now_processing-1]指当前Sequential中保留的通道的索引
- new_params[param_name] = weights[:, selected_idx[now_processing - 1]]
- # 除了最后一个Sequential,每个Sequential中卷积核的数量(输出通道数)都要和后一个Sequential匹配。
- else:
- # Pointwise Convolution中Conv2d(x,y,1)的weight的形状是(y,x,1,1)
- # selected_idx[now_processing]指后一个Sequential中保留的通道的索引
- # selected_idx[now_processing-1]指当前Sequential中保留的通道的索引
- new_params[param_name] = weights[selected_idx[now_processing]][:, selected_idx[now_processing - 1]]
- else:
- new_params[param_name] = weights[selected_idx[now_processing]]
- else:
- new_params[param_name] = weights
-
- # 返回新模型
- new_model.load_state_dict(new_params)
- return new_model
-
-
- def run_epoch(data_loader):
- total_num, total_hit, total_loss = 0, 0, 0
- for batch_data in tqdm(data_loader):
- # for now_step, batch_data in enumerate(dataloader):
- # 清空 optimizer
- optimizer.zero_grad()
- # 获取数据
- inputs, labels = batch_data
-
- logits = new_net(inputs.to(device))
- loss = criterion(logits, labels.to(device))
- loss.backward()
- optimizer.step()
-
- total_hit += torch.sum(torch.argmax(logits, dim=1) == labels.to(device)).item()
- total_num += len(inputs)
- total_loss += loss.item() * len(inputs)
-
- return total_loss / total_num, total_hit / total_num
-
-
- batch_size = 64
- cuda = False
- prune_count = 3
- prune_rate = 0.95
- finetune_epochs = 5
- # "cuda" only when GPUs are available.
- device = "cuda:0" if torch.cuda.is_available() else "cpu"
-
- #加载待剪枝模型架构
- from student_model import StudentNet
-
-
- if __name__ == '__main__':
- # 加载数据
- trainTransform = transforms.Compose([
- transforms.RandomCrop(256, pad_if_needed=True, padding_mode='symmetric'),
- transforms.RandomHorizontalFlip(),
- transforms.RandomRotation(15),
- transforms.ToTensor(),
- ])
-
- testTransform = transforms.Compose([
- transforms.CenterCrop(256),
- transforms.ToTensor(),
- ])
- # 注意修改下面的数据集路径
- train_set = DatasetFolder("training", loader=lambda x: Image.open(x),
- extensions="jpg", transform=trainTransform)
- valid_set = DatasetFolder("validation", loader=lambda x: Image.open(x), extensions="jpg",
- transform=testTransform)
-
- train_dataloader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
- valid_dataloader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
-
- print('Data Loaded')
-
- # 加载网络
- old_net = StudentNet(base=16)
- old_net.load_state_dict(torch.load('student_model.bin',map_location="cpu"))
-
- if cuda:
- old_net = old_net.cuda(device)
-
- # 开始剪枝并finetune:独立剪枝prune_count次,每次剪枝的剪枝率按prune_rate逐渐增大,剪枝后微调finetune_epochs个epoch
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.AdamW(old_net.parameters(), lr=1e-3)
-
- now_width_mult = 1
- for i in range(prune_count):
- now_width_mult *= prune_rate # 增大剪枝率
- new_net = StudentNet(width_mult=now_width_mult)
- if cuda:
- new_net = new_net.cuda(device)
- new_net = network_slimming(old_net, new_net)
- now_best_acc = 0
- for epoch in range(finetune_epochs):
- new_net.train()
- train_loss, train_acc = run_epoch(train_dataloader)
- new_net.eval()
- valid_loss, valid_acc = run_epoch(valid_dataloader)
- # 每次剪枝时存下最好的model
- if valid_acc > now_best_acc:
- now_best_acc = valid_acc
- torch.save(new_net.state_dict(), f'./pruned_{now_width_mult}_student_model.bin')
- print('rate {:6.4f} epoch {:>3d}: train loss: {:6.4f}, acc {:6.4f} valid loss: {:6.4f}, acc {:6.4f}'.format(
- now_width_mult,
- epoch, train_loss, train_acc, valid_loss, valid_acc))
-
- from torchsummary import summary
- summary(new_net.to(),input_size=(3, 256, 256))
-
- summary(old_net.to(),input_size=(3, 256, 256))
-
原模型量化结果如图29,蒸馏剪枝后模型量化结果如图30所示:
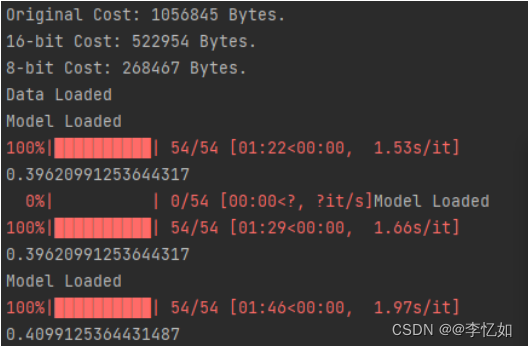
图29 原模型量化结果
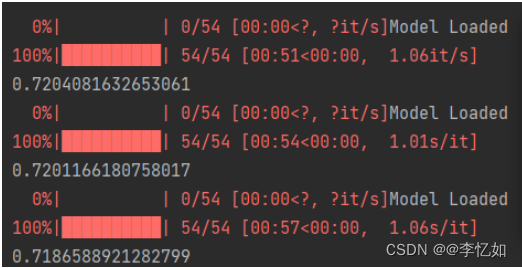
图30 蒸馏剪枝后模型量化结果
分析:根据图29与图30,无论是原模型还是蒸馏剪枝后模型进行量化,16位量化的结果均与原模型相似,而8位量化一般会有更低的loss(更好的效果),与实训文档给出的趋势保持一致,验证了量化对于模型压缩的有效性与合理性。
PyTorch提供Eager Mode Quantization和FX Graph Mode Quantization两种不同的量化模式:
- Eager Mode Quantization是测试版功能,用户需要手动融合和指定量化和反量化发生的位置,并且它只支模块而不支持函数。
- FX Graph Quantization是PyTorch新的自动量化框架,目前是原型功能。它通过添加
对函数的支持和量化过程的自动化来改进Eager Mode Quantization,它不适用于任意模型,用户可能需要重构模型以使模型与FX Graph Quantization兼容。
至此,基于实训文档的模型压缩实践基本完成,且通过消融实验、方案补充提供了不同层面的优化思路,并通过实验验证了其优化的可行性与合理性。
三、参考资料
1.deep_learning_system/深度学习模型压缩方法概述.
2.深度学习模型压缩与加速 - 凌逆战 - 博客园 (cnblogs.com)
3.一文看懂深度学习模型压缩和加速 - 知乎 (zhihu.com)
5.深度学习模型压缩和加速方法综述 - 知乎 (zhihu.com)
6.深度学习模型压缩与优化加速_Law-Yao的博客-CSDN博客
8.神经网络压缩 剪枝 量化 嵌入式计算优化NCNN mobilenet squeezenet shufflenet_hash loss

