
- 1快速上手Spring Cloud 九:服务间通信与消息队列
- 2linux下golang开发环境配置+liteidex+第三方库的下载和引用_go linux下,怎么根据go.mod下载第3方库
- 3Python自动抓取网页新闻,轻松实现!_python爬取新闻网站内容
- 4回溯算法设计(2):回溯法解决0/1背包问题_0/1背包回溯法算法设计
- 5升级鸿蒙谷歌框架下载,网友Mate 40 Pro+升级鸿蒙2.0:谷歌服务不受影响
- 6Swin-Transformer网络结构详解_swin transformer
- 7DragGAN:简介,安装,使用!
- 8【工作中问题解决实践 三】深入理解RBAC权限模型_rbac1模型
- 9基于差影法实现基于图像的人体姿态行为识别(附带MATLAB代码)_matlab差影法代码
- 10Ubuntu中使用Nginx将静态网页部署到云服务器_网页如何发布到ubuntu服务器上
【论文阅读】:用于多元时间序列数据异常检测的深度变压器网络(三)
赞
踩
今天接着昨天的博文讲,忘了的伙伴可以返回去看看哦:
【论文阅读】:用于多元时间序列数据异常检测的深度变压器网络(一):https://blog.csdn.net/m0_72317955/article/details/136655621
【论文阅读】:用于多元时间序列数据异常检测的深度变压器网络(二):https://blog.csdn.net/m0_72317955/article/details/136670803
在(二)中,我们了解了Transformer的原理和结构,这对于理解TranAD模型有很大的帮助,因为TranAD模型就是基于Transformer架构。
4.4 TranAD
4.4.1 问题定义
在论文中,作者将一个多变量时间序列用公式定义为:
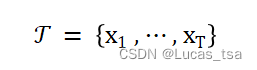
其中,每个数据点是在特定时间戳t收集的,
,即
是一个m维的向量,当
时就变成单变量时间序列。
异常检测(Anomaly Detection):给定一个训练输入时间序列,对于任意长度为
且模态与训练序列
相同的未知测试时间序列
,需要预测
,其中
表示测试集下第t个时间戳的数据点是否异常(1表示异常数据点)。
异常诊断(Anomaly Diagnosis):给定上述训练和测试时间序列,需要预测,其中
表示在第t个时间戳数据点的哪个维度是异常的。
4.4.2 数据预处理
首先对输入数据进行归一化处理,处理方法如下:
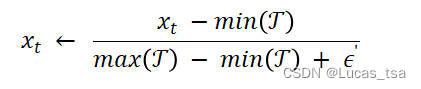
其中,和
是训练时间序列中模式最小和最大向量,
是一个小的常数向量,用于防止零除。在预先知道范围后,对数据进行归一化处理,使其处于 [0, 1] 范围内。
为了模拟数据点与时间戳t的依赖关系,考虑长度为K的局部上下文窗口(滑动窗口),即:
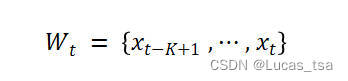
将输入时间序列转换为滑动窗口序列
。若
,则在滑动窗口的后面添加一个长度为
的常数向量
,以确保每个滑动窗口的长度为K。在模型中不使用
来进行训练,而是使用滑动窗口序列W进行模型训练,并使用
(对应)作为测试序列。
模型不再直接预测每个输入窗口的异常标签
,而是先预测该窗口
的异常得分
。利用过去输入窗口的异常得分,计算出一个阈值D,当
时,将当前窗口
标记为异常,即
。为了计算
,将
重构为
,并使用
和
之间的偏差。
4.4.3 TramAD结构
TramAD结构如下图所示:
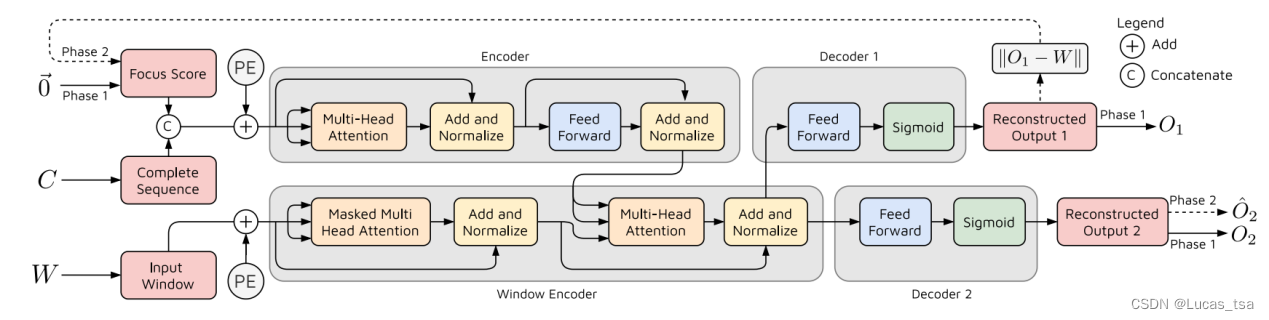
图 14 TramAD结构图
首先,多变量时间序列W和C会被转换成列数为m的矩阵。定义三个矩阵Q(query)、K(key)和V(value)的Self-Attention:
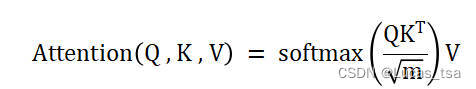
对于输入矩阵Q、K、V,首先应用位置编码(Positional Encoding),然后通过h(头数)个前馈层以获得、
、
,
,再应用缩放点积注意力(scaled-dot product attention),即:
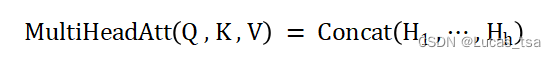
其中,。
由于GAN模型已被证明在输入是否异常的特征任务中表现良好,因此作者利用了一种高效的 GAN 风格的对抗训练方法。TranAD模型由两个Transformer编码器和两个解码器组成,模型训练分为两个阶段。
模型广播F(Focus Score,初始为零矩阵,与W同维度)来匹配W的维度,使用适当的零填充并将两者连接起来,然后应用位置编码得到第一个编码器的输入,记为,第一个编码器执行如下操作:
step1: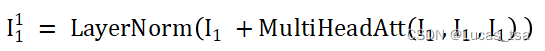
step2: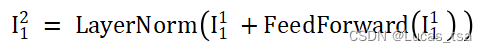
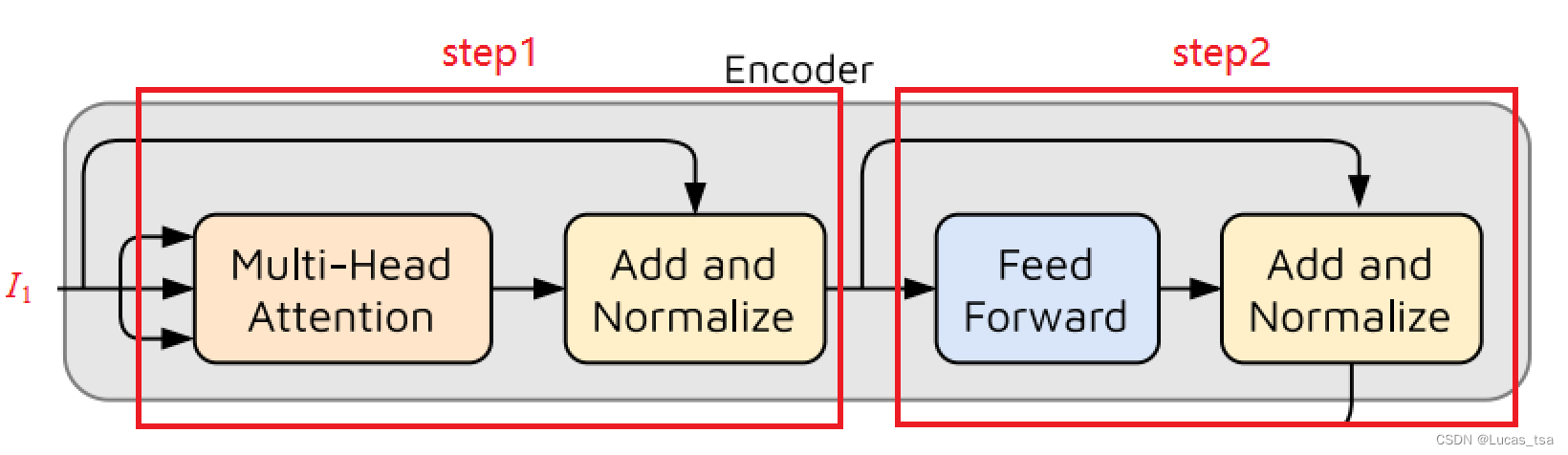
图 15 TramAD模型Encoder操作示意图
上述操作使用输入时间序列窗口W和完整序列C生成注意力权重,以捕捉输入序列中的时间趋势。由于神经网络在每个时间戳都不依赖于前一个时间戳的输出,因此这些操作使模型能够对多批时间序列窗口进行并行推断,从而大大缩短了训练时间。
对于窗口编码器(Window Encoder),模型对滑动窗口序列W进行Positional Encoding得到Window Encoder的输入,然后在Window Encoder进行如下操作:
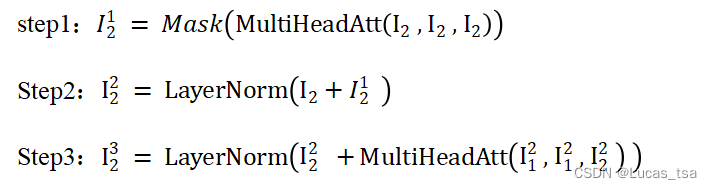

图 16 TramAD模型Window Encoder操作示意图
最后模型使用两个decoder(解码器)来获得两个输出:
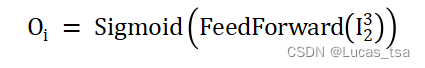
其中分别表示第一个和第二个解码器。
4.4.4 两阶段对抗训练
阶段一:输入重构。Transformer模型能够预测每个输入时间序列窗口的重构,它通过在每个时间戳充当编码器-解码器网络来实现这一功能。然而,传统的编码器-解码器模型往往无法捕捉短期趋势,会错过一些偏差很小的异常。为了解决这一问题,论文作者开发了一种自动回归推理方式,分两个阶段预测重建窗口。在第一阶段,模型旨在生成与输入窗口的近似重构。与这一推理的偏差,也就是前面提到的Focus Score,有助于Transformer Encoder内部的注意力网络提取时间趋势,并将重点放在偏差较大的子序列上。因此,第二阶段的输出取决于第一阶段产生的偏差。在第一阶段,编码器会像普通转换器模型那样,利用基于上下文的注意力将输入窗口的内容(
)转换为
,然后通过两个decoder输出
和
。
阶段二:重点输入重构。在第二阶段,模型使用第一个解码器的重建损失作为Focus Score。有了第二阶段的焦点矩阵(Focus Matrix),重新运行模型得到第二个解码器的输出
。
第一阶段生成的Focus Score显示了重建输出与给定输入的偏差。在第二阶段中,这将作为修改注意力权重的先验,并对特定的输入子序列给予更高的神经网络激活,以提取短期的时间趋势。作者将这种方法称为“自调节”(self-conditioning)。这种两阶段自回归推理方式有三重好处:首先,它放大了偏差,因为重构误差在图14中编码器的注意力部分起到了激活作用,从而产生异常得分,简化了异常标记任务。其次,它通过捕捉图5-14中窗口编码器的短期时间趋势来防止误报。第三,对抗式训练可以提高通用性,使模型对不同的输入序列具有鲁棒性。
4.4.5 不断变化的训练目标
TranAD模型必然会遇到与其他对抗训练框架类似的挑战。其中一个关键挑战是保持训练的稳定性。为了解决这个问题,作者设计了一种对抗训练程序,使用两个独立解码器的输出。最初,两个解码器的目标都是独立重构输入时间序列窗口。利用第一阶段的输出与输入窗口的二范数来定义每个解码器的重构损失:
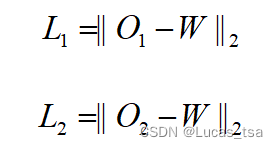
Decoder2旨在通过最大化差异来区分输入窗口和由Decoder1在阶段一(使用Focus Score)中生成的候选重构;Decoder1尽力去通过创建一个接近W的
来迷惑Decoder2,其实就是想让Focus Score接近于0矩阵。即:

可以分解为:
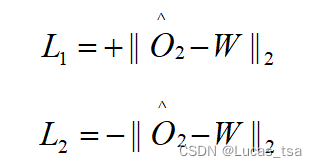
计算每个Decoder的累计损失,该文使用一个进化损失函数,将两个阶段的重构损失和对抗损失函数结合起来,即:
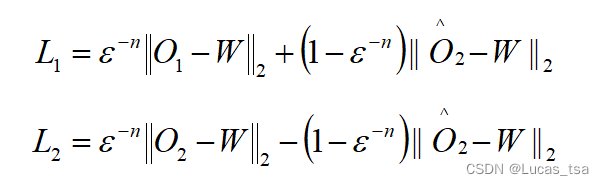
其中,n为训练时期,为接近1的训练参数。最初,重构损失的权重较高。这是为了确保在解码器输出对输入窗口的重构效果不佳时,能进行稳定的训练。如果重构效果不佳,第二阶段中使用的Focus Score就不可靠,因此无法作为先验指标来指示远离输入序列的重构。因此,在初始阶段,对抗损失的权重较低,以避免破坏模型训练的稳定性。随着重建越来越接近输入窗口,Focus Score也越来越精确,对抗损失的权重就会增加。
由于训练过程并不假设数据是按顺序提供的,因此可以将完整的时间序列分割成对,并使用输入批次来训练模型。Masked multi-head attention使模型能够在多个批次中并行运行,加快训练过程。
4.4.6 Meta Learning
模型的训练循环使用了MAML(与模型无关的元学习),这是一种用于快速自适应神经网络的小样本学习模型。这有助于TranAD模型在数据量有限的情况下有效地从输入的时间序列训练数据中捕捉时间趋势。在每次训练迭代过程中,对神经网络权重(假设为,代表神经网络中的任意权重参数,这样是为了避免具体讨论所有可能的权重参数,选择用
作为一个代表性符号来说明整个梯度更新的过程)执行的梯度更新操作可以被简洁地表达为:

其中,表示学习率,
是神经网络的抽象表示,
表示损失函数。在每次迭代结束,都执行Meta Learning,即:

元优化是在模型权重上以元步长
进行的,目标是使用更新后的权重
进行评估。之前的研究表明,这样可以用有限的数据快速训练模型。
4.4.7 异常检测
论文中将异常得分定义为:

测试过程也分两个阶段进行,因此可得到一对重构。在测试时,只考虑当前时间戳之前的数据,因此该操作以在线方式顺序运行。一旦得到某个时间戳在每个维度的异常分数
,如果该分数大于阈值,模型就会给该时间戳贴上异常标签。为了公平比较,模型使用峰值超过阈值(POT)方法动态选择阈值。
每个维度和异常检测结果标签
被定义为:
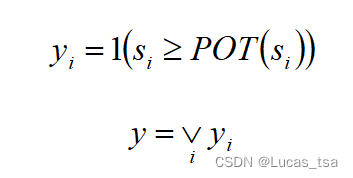
如果任何一个维度是异常的,模型就将当前的时间戳标记为异常。这种本质上还是单变量时间序列的异常检测,没有从根本解决多变量时间序列异常检测的问题。
参考资料
- Tuli S , Casale G , Jennings N R .TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data[J]. 2022.DOI:10.48550/arXiv.2201.07284.
-
【论文阅读】TranAD: Deep Transformer Networks for Anomaly Detection inMultivariate Time Series Data,https://blog.csdn.net/weixin_45141860/article/details/127420913
-
融合transformer和对抗学习的多变量时间序列异常检测算法TranAD论文和代码解读...,https://blog.csdn.net/qq_33431368/article/details/127544218
关于《TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data》这篇论文的精读就分享到这里了,至于论文的代码部分,有时间再说……

