
- 1首个ICLR时间检验奖出炉!3万被引论文奠定图像生成范式,DALL-E 3/SD背后都靠它...
- 2计算机毕业设计php+thinkphp的网上书店购物商城系统(源码+系统+mysql数据库+Lw文档)_thinkphp 毕业设计 商城 源码
- 3探索创新:Keyboard Quantizer - 演奏未来的音乐键盘工具
- 4docker之Dockerfile的编写及Dockerfile 样例_在workspace目录中编写一个dockerfile输出指定数据
- 5jquery拼接选择id的写法_jquery 里面拼接id 这样对吗 id="'in1'+$index
- 6大数据和云计算有什么关系?_大数据和云计算的关系
- 7怎么用ai作图?简单几步教会你ai绘画_ai画图
- 8智慧校园移动端小程序源码,电子班牌人脸识别系统源码_小程序 智慧校园代码
- 9Spark朴素贝叶斯(naiveBayes)_spark使用朴素贝叶斯
- 10linux tomcat java home_Ubuntu下安装Tomcat找不到JAVA_HOME参数解决方法
AI大模型探索之路-训练篇1:大语言模型微调基础认知_大模型自我认知微调
赞
踩
前言
在人工智能的广阔研究领域内,大型预训练语言模型(Large Language Models, LLMs)已经成为推动技术革新的关键因素。这些模型通过在大规模数据集上的预训练过程获得了强大的语言理解和生成能力,使其能够在多种自然语言处理任务中表现出色。然而,由于预训练过程所产生的模型通常具有泛化特性,它们往往无法直接适配到特定的应用场景和细化需求中。为了弥补这一差距,研究人员提出了微调(Fine-tuning)技术。该技术允许模型通过学习额外的、与特定任务相关的数据,从而增强其在特定领域的表现力。本文旨在从专业角度深入探讨大型AI模型微调的概念框架、方法学及其在实际应用中的重要性。

一、微调技术概述
微调是在预先训练的模型基础上实施的一种有监督的训练策略。为了充分理解微调的应用背景,首先需了解AI大模型的关键使用阶段。以下为AI大模型应用的核心步骤概览:
1)Prompt工程:利用精心设计的自然语言提示指导大模型执行具体任务或解决特定问题。
2)Agent开发:结合大模型的强大能力,构筑各类应用程序,如智能知识库、自助查询系统等。
3)微调:采用有监督学习的方式,基于特定任务的数据对模型进行训练,以优化其预测效果。
4)预训练:通过无监督学习,使模型在大量文本数据上学习语言表示,以便用于后续的任务,如文本续写或分类。

二、微调的必要性
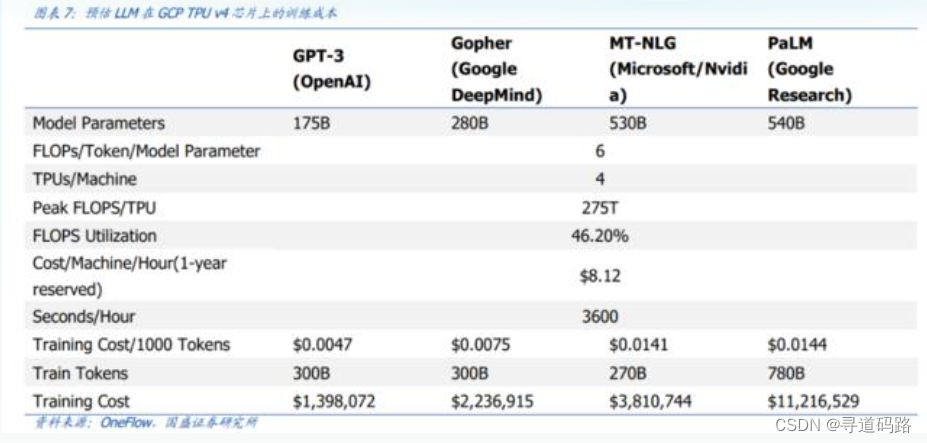
GPT-3训练一次的成本约为139.8万美元,而PaLM需要一千多万美元
尽管AI大模型在许多任务中取得了显著的成果,但它们仍然存在一些应用上的缺陷。这些缺陷主要表现在以下几个方面:
1)预训练成本巨大:大规模的模型预训练不仅需要大量的计算资源,同时耗费巨额的资金和时间。
2)行业数据分布的多样性:不同领域的数据分布有着根本的差异性,这导致通用预训练模型难以在所有任务中都达到理想的表现。
3)企业数据安全性:处理敏感的企业私有数据时,如何确保数据的安全性成为了必须解决的问题。
4)Prompt Engineering的高成本:设计有效的Prompt指导大模型完成特定任务过程既耗时又耗力。
5)外部知识的依赖性:大模型需要借助向量数据库等外部知识源来增强其知识储备和应用能力。
针对以上挑战,微调技术提供了一种高效的解决方案。通过对预训练模型进行针对性的微调,可以显著提升其在特定任务上的性能,降低推理成本,并在一定程度上确保企业数据的安全。
三、大模型的微调方法
目前,主流的大模型微调方法主要包含以下几种策略:
**1)全量微调FFT(Full Fine Tuning):**这种方法涉及调整整个模型的所有参数。虽然它可以在一定程度上提高模型性能,但同时也可能带来较高的训练成本和灾难性遗忘的风险。
2)部分参数微调PEFT(Parameter-Efficient Fine Tuning):这种方法仅调整部分参数,从而降低了训练成本。这包括在线模型和离线模型的微调。
在线模型:例如OpenAI发布的模型,可通过标准的微调流程进行调整。
离线模型:采用LoRA、QLoRA、Adapter、Prefix-tuning、P-tuning2、Prompt-tuning等技术进行更高效的微调

简单代码样例:
# 导入相关库 import torch from transformers import AutoModelForSequenceClassification, AutoTokenizer # 加载预训练模型和分词器 model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased") tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") # 准备数据 inputs = tokenizer("Hello, I am a fine-tuned model.", return_tensors="pt") labels = torch.tensor([1]).unsqueeze(0) # 进行部分参数微调 for name, param in model.named_parameters(): if "layer" in name: # 只调整特定层数的参数 param.requires_grad = True else: param.requires_grad = False # 进行训练 outputs = model(**inputs, labels=labels) loss = outputs.loss loss.backward() optimizer.step()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
四、微调过程中的技术细节
在进行大模型的微调过程中,以下技术细节不容忽视:
1)数据预处理:根据特定任务的需求进行数据清洗与格式化,以确保输入数据的质量和适配性。
2)损失函数设计:根据不同任务的特点选择合适的损失函数,以指导模型优化正确的目标。
3)正则化策略:应用适当的正则化技术如权重衰减、Dropout等,防止过拟合,增强模型的泛化能力。
4)学习率调整:通过精心设计的学习率计划或自适应学习率算法,平衡训练过程中的收敛速度和稳定性。
五、微调后的模型评估与应用
经过微调的模型需要在多个层面进行评估,以保证其在实际环境中的有效性和鲁棒性:
1)性能指标:使用精确度、召回率、F1分数等标准度量来评价模型在特定任务上的表现。
2)实际应用场景测试:将模型部署到真实的应用环境中,检验其在实际操作中的可行性和效率。
3)对抗性测试:评估模型在面对对抗样本时的稳定性,确保其在潜在攻击下仍能保持正确和稳定的输出。
总结
AI大模型的微调作为一项核心技术,已在多个应用场景中证明了其不可或缺的价值。经过微调的预训练模型能够更加精准地适应特定任务,提升性能的同时降低成本。此外,微调后的模型在保护企业数据的隐私性和安全性方面也显示出其优势。随着技术的不断演进和深化,我们有理由相信,AI大模型的微调将在未来的发展中扮演更为关键的角色,并在更广泛的领域内实现其潜在的应用价值。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

