
- 1大模型中有一个fp16.safetensor以及一个safetensor,这两个文件有什么区别_pastelmix-fp16.safetensors
- 2node JS 中安全和防范之 sql 注入、XSS攻击 和 密码加密_node.js需要防sql注入吗
- 3Linux systemd-resolve占用53端口的解决方法_ubuntu 53端口占用
- 4PMP认证的作用有哪些?_pmp证书的作用
- 5深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解_roberta预训练模型
- 6MyBatis-plus实现代码自动生成以及简单的增删改查_mybatisplus的代码生成器可以直接生成增删改查
- 7搞量化先搞数(上):A股股票列表免费抓取实战_a股免费数据
- 8Cocos2d-x 实时动态阴影_cocos 阴影 2d 光照
- 9【Git】分支管理--创建新分支、删除分支、恢复分支_git 创建新分支
- 10玩转ChatGPT:Transformer分类模型_transform分类
自然语言处理学习笔记(通俗白话)_自然语言处理考点
赞
踩
1,Transformer
Transformer 经典模型:简单理解 编码器(Encoding)+解码器(Decoding)
编码器:提取特征
解码器:根据得到的特征尽可能的对原物进行还原
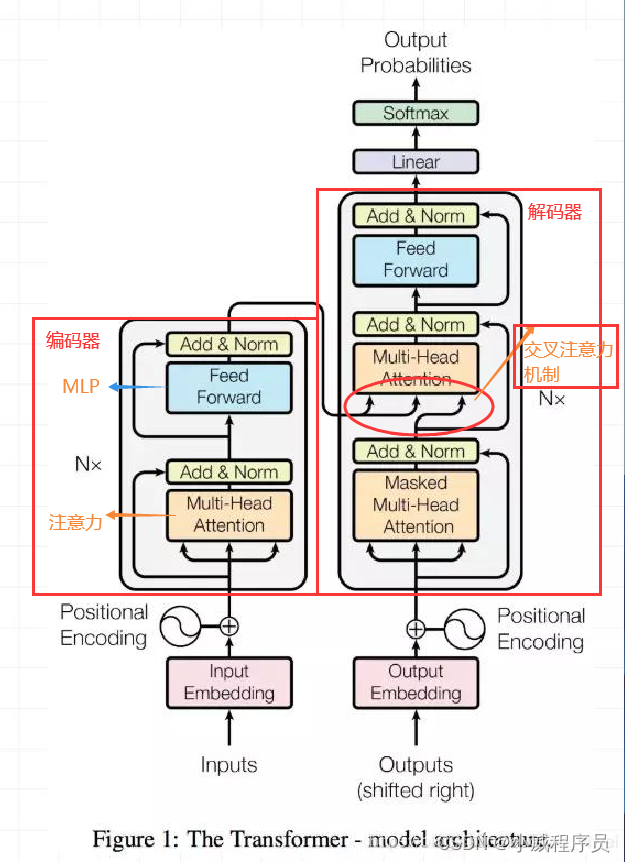
2,注意力机制
直接关注物体更显著的特征,有重点的去提取特征。
自注意力机制: 进入解码器时的数据完全来自编码器。
交叉注意力机制: 进入解码器时的数据一部分来自编码器,一部分由解码器自己生成。
3,卷积网络为什么要用多个卷积核进行图像处理?
不同的卷积核针对的特征不同,比如对一张图像而言,关注的可能有纹理,色泽等。
4,最小二乘法 的一点见解
发明最小二乘法的勒让德认为,让误差的平方和最小估计出来的模型是最接近真实情形的(误差=真实值-理论值)。那么,为什么是误差的平方和呢?
用 真实值-预测值 的问题是:会出现正负相消的情况,从而出现误判。
用 |真实值-预测值| 的问题是:loss并非次次可导。
而**(真实-预测)的平方**很好的规避了这两个问题。
PS:附上本人认为较为详细的理解
最小二乘法的原理理解
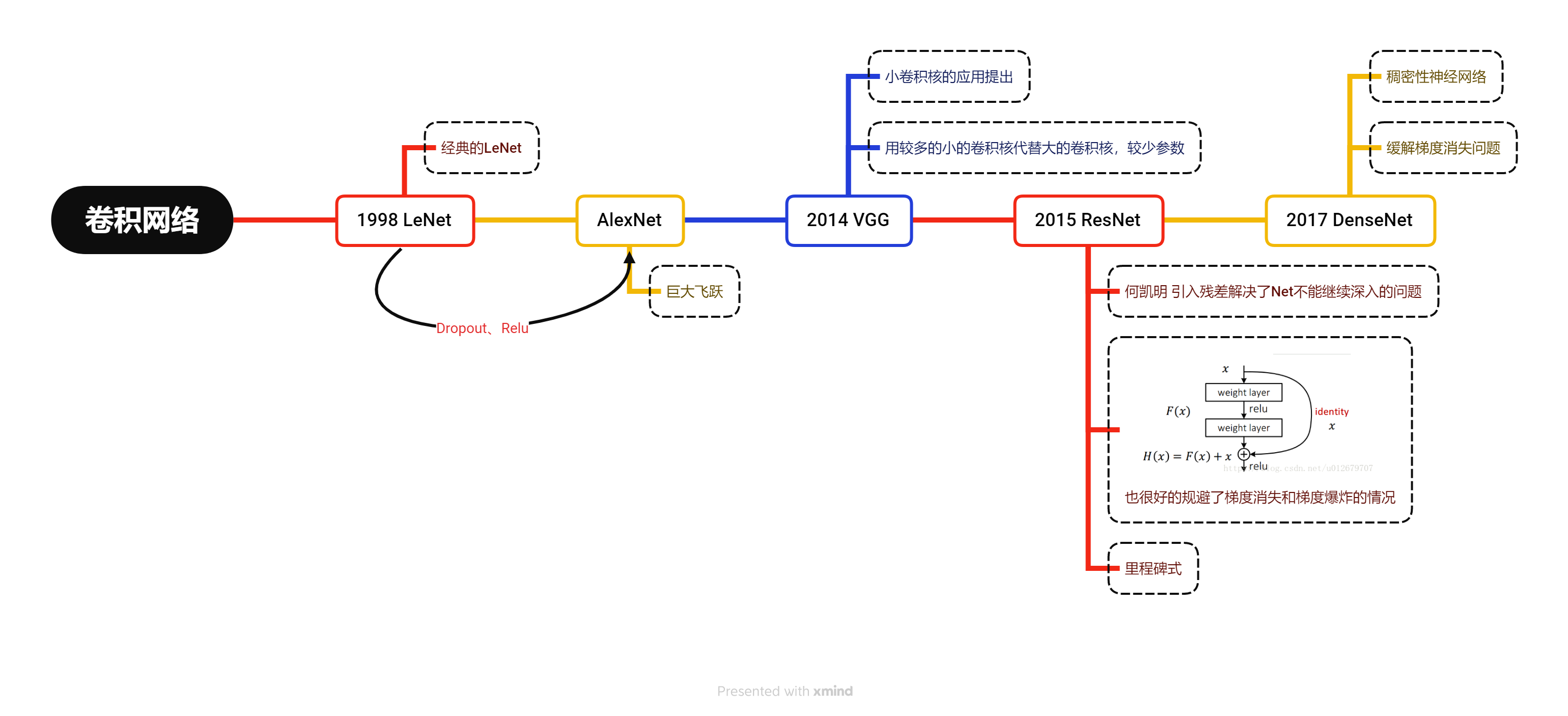
5,卷积网络发展
激活函数
激活函数是神经网络非线性的来源,如果不引入,则神经网络的线性模型的复合仍然为线性模型,不能很好的拟合非线性情况下的模型。
anaconda search -t conda opencv-python
卷积神经网络:
与传统神经网络(参数多)最大的特点权值共享、局部连接 (引入kernel实现)
输入层
卷积层
池化层作用:进一步压缩特征(防止处理的参数过多)常用的池化层有,均值池化层、最大值池化层等
全连接层:整合数值得结果
随机失活:如果模型过于复杂或参数更多,随机取消一些连接来实现。
**Batch Normalization(批归一化)好处:**否前提假定,批数据满足独立同分布;在最后进行批归一化处理,试图把数据拉回原来的分布。
空洞卷积
结合大卷积核的感受范围广的优点和小卷积核训练参数少的优点,空洞卷积核应运而生!
But 会造成部分信息丢失!
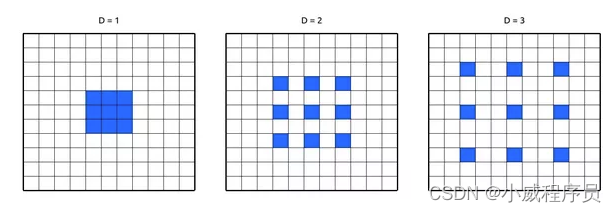
主要应用于语义分割领域。
图像分类、目标检测、图像分割。图像分割分为语义分割和实例分割。
RNN
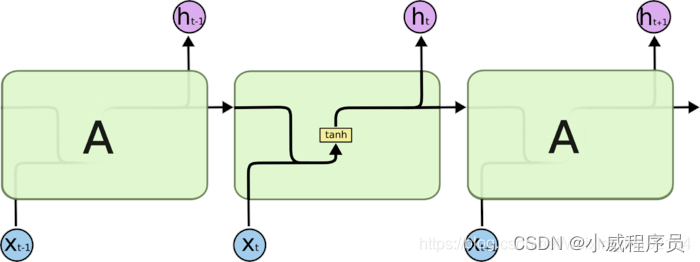
处理(时间)序列数据的必须!
存在短期记忆问题。——解决方法:LSTM
LSTM(长的_短期记忆网络)
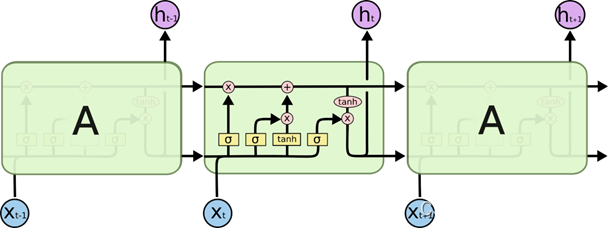
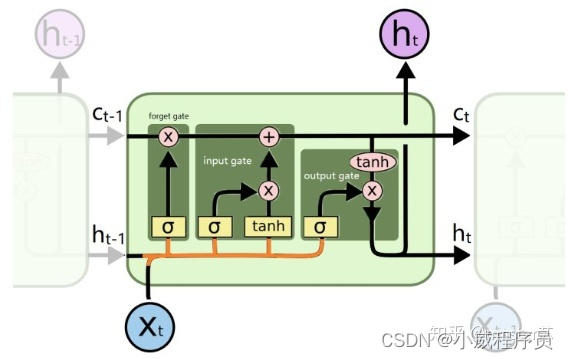
遗忘门:决定丢失的是什么信息
输入门:更新一部分信息,选择接受什么信息
输出门:
考点总结:
1,词频(TF),逆文档频率(IDF)
eg,在包含N个文档的语料库中,随机选择的一个文档总共包含T个词条,词条“hello”出现 K 次。如果词条“hello”出现在全部文档的数量接近三分之一,则TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
词频计算公式:该词数/当前文档总词数
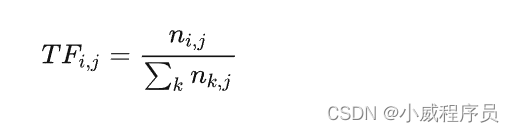
逆文档频率:log(总文档数/包含该词条的文档数) , 分母加1主要是防止包含词条ti的数量为0从而导致运算出错的现象发生。
逆文档频率越大,其类别区分能力越强。
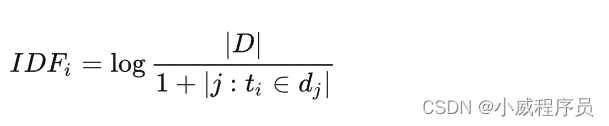
2,Bert
特点:
可以自定义训练特定主题
支持上下文建模
BERT使用token嵌入、段嵌入(Segment Embedding)、位置嵌入(Position Embedding)
对句子中所有词之间的关系进行建模,而与它们的位置无关。
网络结构:transformer的堆叠。
预训练的表征语言模型,以往的预训练模型的结构会受到单向语言模型(从左到右或者从右到左)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。而BERT利用MLM进行预训练并且采用深层的双向Transformer组件(单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。)来构建整个模型,因此最终生成能融合左右上下文信息的深层双向语言表征。
3,ELMo
特点:
实现多个词的嵌入,解决了多义词的问题
ELMo尝试训练两个独立的LSTM语言模型(从左到右和从右到左),并将结果连接起来以产生词嵌入。

