
- 1pycharm创建Django项目_pycharm 新的django项目
- 2ChatGPT写21个程序,16个有漏洞:离取代程序员还远着呢!_人工智能编程效率低,但质量高
- 3大模型时代下的决策范式转变_大模型的统计分析和辅助决策
- 4python函数定义和调用_python函数的定义如下: #定义函数 def fun(a, b, c): print(a, b,
- 5图的深度优先遍历与广度优先遍历以及最小生成树
- 6大一python填空题必考题库,大一pta填空题python答案
- 7GitHub 上都有哪些值得关注学习的 iOS 开源项目?_afnetworking和mantle封装网络解析
- 8尚硅谷大数据技术NiFi教程-笔记02【NiFi(使用案例,同步文件、离线同步mysql数据到hdfs、实时监控kafka数据到hdfs)】_nifi使用除法
- 9闲话电子设计之100条
- 10论文笔记--Deep Residual Learning for Image Recognition(ResNet)_deep residual learning for image recognition笔记
深度剖析集成学习Xgboost_xgboost objective
赞
踩
Xgboost
Xgboost
3.0 原理概述
3.0.1 基本思想和特点
XGBoost中两种非常关键的思想实现的:
-
第一,实现精确性与复杂度之间的平衡
- 1. XGBoost为损失函数 L ( y , y ^ ) L(y,\hat{y}) L(y,y^)加入结构风险项,构成目标函数 O ( y , y ^ ) O(y,\hat{y}) O(y,y^)
- 2. 使用全新不纯度衡量指标,将复杂度纳入分枝规则
-
第二,极大程度地降低模型复杂度、提升模型运行效率,将算法武装成更加适合于大数据的算法
- 1. 使用估计贪婪算法、平行学习、分位数草图算法等方法构建了适用于大数据的全新建树流程
- 2. 使用感知缓存访问技术与核外计算技术,提升算法在硬件上的运算性能
- 3. 引入Dropout技术,为整体建树流程增加更多随机性、让算法适应更大数据
除此之外,XGBoost还保留了部分与梯度提升树类似的属性,包括:
- 无论集成算法整体在执行回归/分类/排序任务,弱评估器一定是回归器
- 拟合负梯度,且当损失函数是0.5倍MSE时,拟合残差
- 抽样思想
3.1 参数概况
3.1.0 参数建议

| 参数相关的流程 | 原生库参数 | skleanAPI参数 |
|---|---|---|
| 损失函数 | objective, lambda ,alpha | objective, reg_alpha, reg_lambda |
| 集成规则 | eta, base_score, eval_metric, subsample, sampling_method, colsample_bytree, colsample_bylevel, colsample_bynode | learning_rate, base_score, eval_metric, subsample, colsample_bytree, colsample_bylevel, colsample_bynode |
| 弱评估器 | num_boost_round, booster, tree_method, sketch_eps, updater, grow_policy | n_estimators, booster, tree_method |
| 弱评估器 (抗过拟合) | num_feature, max_depth, gamma, min_child_weight, max_delta_step, max_leaves, max_bin | max_depth, gamma, min_child_weight, max_delta_step |
| 训练流程 (结果监控) | verbosity | verbosity |
| 训练流程 (提前停止) | early_stopping_rounds | early_stopping_rounds |
| 训练流程 (增量学习) | warm_start | |
| 随机性控制 | seed | random_state |
| 其他流程 | missing, scale_pos_weight, predictor, num_parallel_tree | n_jobs, scale_pos_weight, num_parallel_tree,enable_categorical, importance_type |
3.1.1 Xgboost实现的sklearn接口
import xgboost xgboost.XGBClassifier()合并在回归中说,只有objective不一样 xgboost.XGBRegressor( learning_rate=0.1, # 学习率,和n_estimators树个数相对应 n_estimators=100,# 梯度提升树的数量,一般不超过300 #---------------------------限制过拟合的主要参数值有一下几个------------------------ max_depth=3, # 每棵树的最大深度 gamma=0,#在叶子上进行进一步分区所需的最小损失减少树的节点 colsample_bytree=1,# 构建每棵树时的子特征比率 colsample_bylevel=1,#构建每层的子特征比率 colsample_bynode=1, #构建每个节点能使用的特征比例 subsample=1,#训练实例的子样本比率 # 这两个正则项系数虽然能抗过闭合,不过我们通常使用gamma抗过拟合,默认使用L2范式,系数为1 reg_alpha=0,# L1 权重正则化项系数 reg_lambda=1,# L2 权重正则化项系数 silent=True,# 是否显示过程 objective='reg:squarederror', #objective代表了我们要解决的问题(目标函数)是分类还是回归,或其他问题,以及对应的损失函数。具体可以取的值很多,一般我们只关心在分类和回归的时候使用的参数。 #在回归问题objective一般使用reg:squarederror ,即MSE均方误差。二分类问题一般使用binary:logistic, 多分类问题一般使用multi:softmax booster='gbtree',# 弱学习器基于树模型 gbtree、gblinear 或 dart #booster决定了XGBoost使用的弱学习器类型,可以是默认的gbtree, 也就是CART决策树,还可以是线性弱学习器gblinear以及DART。 #一般来说,我们使用gbtree就可以了,不需要调参 n_jobs=1, min_child_weight=1,# 样本点所以的权重的和若小于1则不分节点 max_delta_step=0,# 允许每棵树的权重估计的最大增量步长 scale_pos_weight=1,# 平衡正负权重 base_score=0.5, random_state=0, verbosity = 0 ,# 0 (silent) - 3 (debug missing=None,# 处理空值,填充什么 importance_type='gain'#特征重要性类型 #树模型 "gain", "weight", "cover", "total_gain" or"total_cover". #线性模型只有"weight",归一化系数,未有偏差 ) eval_metric参数设置模型使用什么评估指标:这个参数在sklearnAPI中要在实例化模型后在fit方法中添加。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
from xgboost import XGBRegressor
xgb_sk = XGBRegressor(max_depth=5,random_state=1412).fit(X,y)
#查看特征重要性
xgb_sk.feature_importances_
#调出其中一棵树,不过无法展示出树的细节,只能够调出建树的Booster对象
xgb_sk.get_booster()[2]
#查看一共建立了多少棵树,相当于是n_estimators的取值
xgb_sk.get_num_boosting_rounds()
#获取每一个参数的取值
xgb_sk.get_params()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.1.2 Xgboost原生库

class xgboost.DMatrix(data, label=None, *, weight=None, base_margin=None, missing=None, silent=False, feature_names=None, feature_types=None, nthread=None, group=None, qid=None, label_lower_bound=None, label_upper_bound=None, feature_weights=None, enable_categorical=False)
function xgboost.train(*params, dtrain, num_boost_round=10, *, evals=None, obj=None, feval=None, maximize=None, early_stopping_rounds=None, evals_result=None, verbose_eval=True, xgb_model=None, callbacks=None, custom_metric=None)
function xgboost.cv(*params, dtrain, num_boost_round=10, nfold=3, stratified=False, folds=None, metrics=(), obj=None, feval=None, maximize=None, early_stopping_rounds=None, fpreproc=None, as_pandas=True, verbose_eval=None, show_stdv=True, seed=0, callbacks=None, shuffle=True, custom_metric=None)
num_boost_round需要设置在cv函数中,不能放在params中,否则出现警告
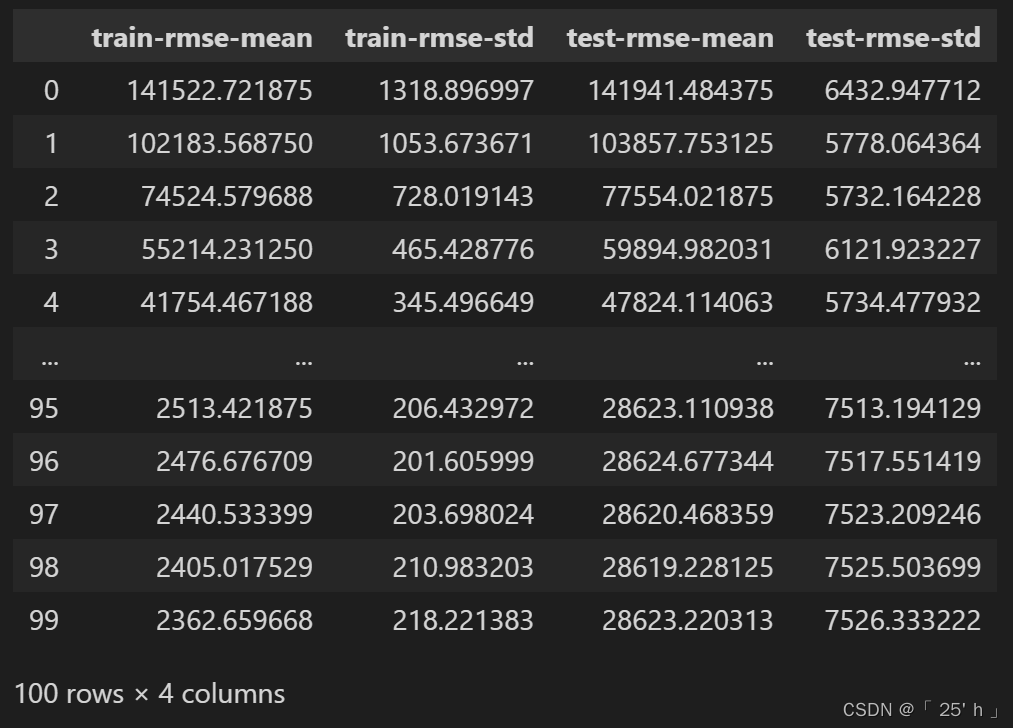
xgboost.cv返回值形如(行数和num_boost_round相同,表示每行建树情况):
| 类型 | 参数 |
|---|---|
| 迭代过程/目标函数 | params: eta, base_score, objective, lambda, gamma, alpha, max_delta_step xgb.train(): num_boost_round |
| 弱评估器结构 | params: max_depth, booster, min_child_weight |
| dart树 | params: sample_type, normalized_type, rate_drop, one_drop, skip_drop |
| 弱评估器的训练数据 | params: subsample, sampling_method, colsamle_bytree, colsample_bylevel, colsample_bynode |
| 提前停止 | xgb.train(): early_stopping_rounds, evals, eval_metric |
| 其他 | params: seed, verbosity, scale_pos_weight, nthread |
objective参数默认binary:logistic params = {"eta": 0.3,# 相当于learning_rate "max_depth": 3, "gamma": 0, "objective": "reg:squarederror",# 同sklearn,不同问题不同参数 "colsample_bytree": 1, "colsample_bylevel": 1, "colsample_bynode": 1, "lambda": 1,# L2范数 "alpha": 0,# L1范数 "subsample": 1, "seed": 100,# random_state "eval_metric":"mae"#重要 """ 这个参数表示用哪个评估指标: rmse: 回归中的均方误差 mae: 回归中的绝对平均误差 logloss:二分类对数损失 mlogloss: 多分类对数损失 error: 多分类误差,相当于 1-准确率 auc:多分类中的AUC面积 """ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.2 objective损失函数
-
用于回归
- reg:squarederror:平方损失,即 1 2 ( y − y ^ ) 2 \frac{1}{2}(y - \hat{y})^2 21(y−y^)2,其中1/2是为了计算简便
- reg:squaredlogerror:平方对数损失,即 1 2 [ l o g ( y ^ + 1 ) − l o g ( y + 1 ) ] 2 \frac{1}{2}[log(\hat{y} + 1) - log(y + 1)]^2 21[log(y^+1)−log(y+1)]2,其中1/2是为了计算简便
-
用于分类
- binary:logistic:二分类交叉熵损失,使用该损失时
predict接口输出概率。 - binary:logitraw:二分类交叉熵损失,使用该损失时
predict接输出执行sigmoid变化之前的值 - multi:softmax:多分类交叉熵损失,使用该损失时
predict接口输出具体的类别。如果你对该损失不熟悉,你需要学习AdaBoost与GBDT。 - multi:softprob:多分类交叉熵,适用该损失时
predict接口输出每个样本每个类别下的概率
- binary:logistic:二分类交叉熵损失,使用该损失时
当不填写任何内容时,参数objective的默认值为reg:squarederror。
调用xgboost.train
# 二分类参数示例
params1 = {"seed":1412, "objective":"binary:logistic"
,"eval_metric":"logloss" #二分类交叉熵损失
}
# 多分类参数示例
params2 = {"seed":1412, "objective":"multi:softmax"
,"eval_metric":"mlogloss" #多分类交叉熵损失 #"merror"
,"num_class":10}
#对多分类算法来说,除了设置损失函数和评估指标,还需要设置参数`num_class`。
#参数`num_class`用于多分类状况下、具体的标签类别数量,例如,如果是三分类,则需设置{"num_calss":3}。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
分类算法与回归算法执行交叉验证的流程基本一致,但需要注意的是,当使用xgb.train时,我们会将评估指标参数eval_matric写在params中,在使用xgb.cv时,我们却需要将评估指标参数写在xgb.cv当中,否则有时候会报出警告。在xgb.cv当中,我们需要将评估指标打包成元组,写在参数metrics内部,如下所示:
params2 = {"seed":1412 , "objective":"multi:softmax" #无论填写什么损失函数都不影响交叉验证的评估指标 , "num_class":10} result = xgb.cv(params2,data_multi,num_boost_round=100 ,metrics = ("mlogloss") #交叉验证的评估指标由cv中的参数metrics决定 ,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证 ,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子 ) 参数`metrics`支持多个评估指标:但是范围值就有len('metrics')*4列 params3 = {"seed":1412 , "objective":"multi:softmax" #无论填写什么损失函数都不影响交叉验证的评估指标 , "num_class":10} result = xgb.cv(params3,data_multi,num_boost_round=100 ,metrics = ("mlogloss","merror") ,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证 ,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.3 迭代过程参数
3.3.1 num_boost_round&eta
具体地来说,对于样本
x
i
x_i
xi,集成算法当中一共有
K
K
K棵树,则参数num_boost_round的取值为K。
在这个一般过程中,每次将本轮建好的决策树加入之前的建树结果时,可以增加参数
η
\color{red}\eta
η,表示为第k棵树加入整体集成算法时的学习率,对标参数eta。
H k ( x i ) = H k − 1 ( x i ) + η f k ( x i ) H_k(x_i) = H_{k-1}(x_i) + {\color{red}\eta} f_k(x_i) Hk(xi)=Hk−1(xi)+ηfk(xi)
该学习率参数控制Boosting集成过程中
H
(
x
i
)
H(x_i)
H(xi)的增长速度,是相当关键的参数。当学习率很大时,
H
(
x
i
)
H(x_i)
H(xi)增长得更快,我们所需的num_boost_round更少,当学习率较小时,
H
(
x
i
)
H(x_i)
H(xi)增长较慢,我们所需的num_boost_round就更多,因此boosting算法往往会需要在num_boost_round与eta中做出权衡。在XGBoost当中,num_boost_round的默认值为10,eta的默认值为0.3。
3.3.2 base_score
在上述过程中,我们建立第一个弱评估器时有:
H 1 ( x i ) = H 0 ( x i ) + η f 1 ( x i ) H_1(x_i) = H_{0}(x_i) + \eta f_1(x_i) H1(xi)=H0(xi)+ηf1(xi)
由于没有第0棵树的存在,因此
H
0
(
x
i
)
H_0(x_i)
H0(xi)的值在数学过程及算法具体实现过程中都需要进行单独的确定,而这个值就由base_score确定。在xgboost中,我们可以对base_score输出任何数值,但并不支持类似于GBDT当中输入评估器的操作。当不填写时,该参数的默认值为0.5,即对所有样本都设置0.5为起始值。当迭代次数足够多、数据量足够大时,调整算法的
H
0
(
x
i
)
H_0(x_i)
H0(xi)意义不大,因此我们基本不会调整这个参数。
3.3.3 max_delta_step
在迭代过程当中,XGBoost有一个独特的参数max_delta_step。这个参数代表了每次迭代时被允许的最大
η
f
k
(
x
i
)
\eta f_k(x_i)
ηfk(xi)。当参数max_delta_step被设置为0,则说明不对每次迭代的
η
f
k
(
x
i
)
\eta f_k(x_i)
ηfk(xi)大小做限制,如果该参数被设置为正数C,则代表
η
f
k
(
x
i
)
≤
C
\eta f_k(x_i) \leq C
ηfk(xi)≤C,否则就让算法执行:
H k ( x i ) = H k − 1 ( x i ) + C H_k(x_i) = H_{k-1}(x_i) + C Hk(xi)=Hk−1(xi)+C
通常来说这个参数是不需要的,但有时候这个参数会对极度不均衡的数据有效。如果样本极度不均衡,那可以尝试在这个参数中设置1~10左右的数。
总结:
| 参数含义 | 原生代码 | sklearn API |
|---|---|---|
| 迭代次数/树的数量 | num_boost_round (xgb.train) | n_estimators |
| 学习率 | eta (params) | learning_rate |
| 初始迭代值 | base_score (params) | base_score |
| 一次迭代中所允许的最大迭代值 | max_delta_step (params) | max_delta_step |
注意,在XGBoost原生论文当中使用 Φ ( x ) \Phi(x) Φ(x)作为树输出结果的表示,并且让 f ( x ) = η Φ ( x ) f(x) = \eta \Phi(x) f(x)=ηΦ(x).
3.4 目标函数
O b j k = ∑ i = 1 M l ( y i , y i ^ ) + Ω ( f k ) Obj_k = \sum_{i=1}^Ml(y_i,\hat{y_i}) + \Omega(f_k) Objk=i=1∑Ml(yi,yi^)+Ω(fk)
其中 M M M表示现在这棵树上一共使用了M个样本, l l l表示单一样本的损失函数。当模型迭代完毕之后,最后一棵树上的目标函数就是整个XGBoost算法的目标函数。
在具体的公式当中,结构风险 Ω ( f k ) \Omega(f_k) Ω(fk)又由两部分组成,一部分是控制树结构的 γ T \gamma T γT,另一部分则是正则项:
Ω
(
f
k
)
=
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
+
α
∑
j
=
1
T
w
j
\Omega(f_k) = {\color{red}\gamma} T + \frac{1}{2}{\color{red}\lambda}\sum_{j=1}^Tw_j^2 + {\color{red}\alpha}\sum_{j=1}^Tw_j
Ω(fk)=γT+21λ∑j=1Twj2+α∑j=1Twj
其中 γ \gamma γ, λ \lambda λ与 α \alpha α都是可以自由设置的系数,而 T T T表示当前第 k k k棵树上的叶子总量, w j w_j wj则代表当前树上第 j j j片叶子的叶子权重(leaf weights)。叶子权重是XGBoost数学体系中非常关键的一个因子,它实际上就是当前叶子 j j j的预测值,这一指标与数据的标签量纲有较大的关系,因此当标签的绝对值较大、 w j w_j wj值也会倾向于越大。因此正则项有两个:使用平方的L2正则项与使用绝对值的L1正则项,因此完整的目标函数表达式为:
O
b
j
k
=
∑
i
=
1
M
l
(
y
i
,
y
i
^
)
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
+
α
∑
j
=
1
T
w
j
Obj_k = \sum_{i=1}^Ml(y_i,\hat{y_i}) + {\color{red}\gamma} T + \frac{1}{2}{\color{red}\lambda}\sum_{j=1}^Tw_j^2 + {\color{red}\alpha}\sum_{j=1}^Tw_j
Objk=i=1∑Ml(yi,yi^)+γT+21λj=1∑Twj2+αj=1∑Twj
T
就是树的叶节点数量,
w
j
就是树中第
j
个叶节点的值。
T 就是树的叶节点数量,w_j就是树中第j个叶节点的值。
T就是树的叶节点数量,wj就是树中第j个叶节点的值。
γ 就是控制信息增益的参数, α 就是 L 1 正则项系数, λ 就是 L 2 正则项系数 \gamma就是控制信息增益的参数,\alpha就是L1正则项系数,\lambda 就是L2正则项系数 γ就是控制信息增益的参数,α就是L1正则项系数,λ就是L2正则项系数
不难发现,所有可以自由设置的系数都与结构风险有关,这三个系数也正对应着xgboost中的三个参数:gamma,alpha与lambda。
- 参数
gamma:乘在一棵树的叶子总量 T T T之前,依照叶子总量对目标函数施加惩罚的系数,默认值为0,可填写任何[0, ∞]之间的数字。当叶子总量固定时,gamma越大,结构风险项越大;同时,当gamma不变时,叶子总量越多、模型复杂度越大,结构风险项也会越大。在以上两种情况下,目标函数受到的惩罚都会越大,因此调大gamma可以控制过拟合。 - 参数
alpha与lambda:乘在正则项之前,依照叶子权重的大小对目标函数施加惩罚的系数,也就是正则项系数。lambda的默认值为1,alpha的默认值为0,因此xgboost默认使用L2正则化。通常来说,我们不会同时使用两个正则化,但我们也可以尝试这么做。 ∑ j = 1 T w j \sum_{j=1}^Tw_j ∑j=1Twj是当前树上所有叶子的输出值之和,因此当树上的叶子越多、模型复杂度越大时, ∑ j = 1 T w j \sum_{j=1}^Tw_j ∑j=1Twj自然的数值自然会更大,因此当正则项系数固定时,模型复杂度越高,对整体目标函数的惩罚就越重。当 w w w固定时,正则项系数越大,整体目标函数越大,因此调大alpha或lambda可以控制过拟合。
| 参数含义 | 原生代码 | sklearn API |
|---|---|---|
| 乘在叶子节点数量前的系数 | gamma (params) | gamma |
| L2正则项系数 | lambda (params) | reg_lambda |
| L1正则项系数 | alpha (params) | reg_alpha |
当树的结构相对复杂时,gamma会比敏感,否则gamma可能非常迟钝。当原始标签数值很大、且叶子数量不多时,lambda和alpha就会敏感,如果原始标签数值很小,这两个参数就不敏感。
参数范围建议:
gamma:np.arange(0,10000000,1000000)
lambda、alpha:np.arange(1,2,0.1)
3.5 三大评估器与DART树(booster)
梯度提升算法当中不只有梯度提升树,也可集成其他模型作为弱评估器,而作为梯度提升树进化版的XGBoost算法,自然也不是只有CART树一种弱评估器。在XGBoost当中,我们还可以选型线性模型,比如线性回归或逻辑回归来集成,同时还可以选择与CART树有区别的另一种树:DART树。在XGBoost当中,我们使用参数booster来控制我们所使用的具体弱评估器。
- 参数
booster:使用哪种弱评估器。
可以输入"gbtree"、“gblinear"或者"dart”。
- 输入"gbtree"表示使用遵循XGBoost规则的CART树,我们之前提到的XGBoost在GBDT上做出的改善基本都是针对这一类型的树。这一类型的树又被称为“XGBoost独有树”,XGBoost Unique Tree。
- 输入"dart"表示使用抛弃提升树,DART是Dropout Multiple Additive Regression Tree的简称。这种建树方式受深度学习中的Dropout技巧启发,在建树过程中会随机抛弃一些树的结果,可以更好地防止过拟合。在数据量巨大、过拟合容易产生时,DART树经常被使用,但由于会随机地抛弃到部分树,可能会伤害模型的学习能力,同时可能会需要更长的迭代时间。
- 输入"gblinear"则表示使用线性模型,当弱评估器类型是"gblinear"而损失函数是MSE时,表示使用xgboost方法来集成线性回归。当弱评估器类型是"gblinear"而损失函数是交叉熵损失时,则代表使用xgboost来集成逻辑回归。
每一种弱评估器都有自己的params列表,例如只有树模型才会有学习率等参数,只有DART树才会有抛弃率等参数。评估器必须与params中的参数相匹配,否则一定会报错。其中,由于DART树是从gbtree的基础上衍生而来,因此gbtree的所有参数DART树都可以使用。
| 参数含义 | 原生代码 | sklearn API |
|---|---|---|
| 选择使用不同的弱评估器 | booster (params) | booster |
关于DART抛弃树的简要说明:
经典的CART树模型:
在第
k
k
k次迭代中建立新的树时,迭代后的结果等于之前所有
k
−
1
{k-1}
k−1棵树的结果加新建立的树的结果:
H k ( x i ) = H k − 1 ( x i ) + η f k ( x i ) H_k(x_i) = H_{k-1}(x_i) + {\color{red}\eta} f_k(x_i) Hk(xi)=Hk−1(xi)+ηfk(xi)
DART树是建立在CART树模型基础之上,在每一次迭代前都会随机地抛弃部份树,即不让这些树参与 H k − 1 ( x i ) H_{k-1}(x_i) Hk−1(xi)的计算,这种随机放弃的方式被叫做“Dropout”(抛弃)。举例说明,假设现在一共有5棵树,结果分别如下:
| k=1 | k=2 | k=3 | k=4 | k=5 | |
|---|---|---|---|---|---|
| η f k ( x i ) \eta f_k(x_i) ηfk(xi) | 1 | 0.8 | 0.6 | 0.5 | 0.3 |
当建立第6棵树时,普通提升树的
H
k
−
1
(
x
i
)
H_{k-1}(x_i)
Hk−1(xi) = 1+0.8+0.6+0.5+0.3 = 3.2。对于DART树来说,我们可以认为设置抛弃率rate_drop,假设抛弃率为0.2,则DART树会随机从5棵树中抽样一棵树进行抛弃。假设抛弃了第二棵树,则DART树的
H
k
−
1
(
x
i
)
H_{k-1}(x_i)
Hk−1(xi) = 1+0.6+0.5+0.3 = 2.4。通过影响
H
k
−
1
(
x
i
)
H_{k-1}(x_i)
Hk−1(xi),DART树影响损失函数、影响整个算法的输出结果
H
(
x
)
H(x)
H(x),以此就可以在每一次迭代中极大程度地影响整个xgboost的方向。
在一般的抗过拟合方法当中,我们只能从单棵树的学习能力角度入手花式对树进行剪枝,但DART树的方法是对整体迭代过程进行控制。在任意以“迭代”为核心的算法当中,我们都面临同样的问题,即最开始的迭代极大程度地影响整个算法的走向,而后续的迭代只能在前面的基础上小修小补。这一点从直觉上来说很好理解,毕竟当我们在绘制损失函数的曲线时,会发现在刚开始迭代时,损失函数急剧下降,但随后就逐渐趋于平缓。在这个抛弃弱评估器的过程中,没有任何过拟合手段可以从流程上影响到那些先建立的、具有巨大影响力的树,但DART树就可以削弱这些前端树的影响力,大幅提升抗过拟合的能力。
关于随机抛弃的过程中,我们涉及到以下的几个参数:
- 参数
rate_drop:每一轮迭代时抛弃树的比例
设置为0.3,则表示有30%的树会被抛弃。只有当参数
booster="dart"时能够使用,只能填写[0.0,1.0]之间的浮点数,默认值为0。
- 参数
one_drop:每一轮迭代时至少有one_drop棵树会被抛弃
可以设置为任意正整数,例如
one_drop= 10,则意味着每轮迭代中至少有10棵树会被抛弃。
当参数one_drop的值高于rate_drop中计算的结果时,则按照one_drop中的设置执行Dropout。例如,总共有30棵树,rate_drop设置为0.3,则需要抛弃9棵树。但one_drop中设置为10,则一定会抛弃10棵树。当one_drop的值低于rate_drop的计算结果时,则按rate_drop的计算结果执行Dropout。
- 参数
skip_drop:每一轮迭代时可以不执行dropout的概率
即便参数
booster=‘dart’,每轮迭代也有skip_drop的概率可以不执行Dropout,是所有设置的概率值中拥有最高权限的参数。该参数只能填写[0.0,1.0]之间的浮点数,默认值为0。当该参数为0时,则表示每一轮迭代都一定会抛弃树。如果该参数不为0,则有可能不执行Dropout,直接按照普通提升树的规则建立新的提升树。
需要注意的是,skip_drop的权限高于one_drop。即便one_drop中有所设置,例如每次迭代必须抛弃至少10棵树,但只要skip_drop不为0,每轮迭代则必须经过skip_drop的概率筛选。如果skip_drop说本次迭代不执行Dropout,则忽略one_drop中的设置。
- 参数
sample_type:抛弃时所使用的抽样方法
填写字符串"uniform":表示均匀不放回抽样。
填写字符串"weighted":表示按照每棵树的权重进行有权重的不放回抽样。
注意,该不放回是指在一次迭代中不放回。每一次迭代中的抛弃是相互独立的,因此每一次抛弃都是从所有树中进行抛弃。上一轮迭代中被抛弃的树在下一轮迭代中可能被包括。
- 参数
normalize_type:增加新树时,赋予新树的权重(树模型抽中的概率)
当随机抛弃已经建好的树时,可能会让模型结果大幅度偏移,因此往往需要给与后续的树更大的权重,让新增的、后续的树在整体算法中变得更加重要。所以DART树在建立新树时,会有意地给与后续的树更大的权重。我们有两种选择:
填写字符串"tree",表示新生成的树的权重等于所有被抛弃的树的权重的均值。
填写字符串"forest",表示新生成的树的权重等于所有被抛弃的树的权重之和。
算法默认为"tree",当我们的dropout比例较大,且我们相信希望给与后续树更大的权重时,会选择"forest"模式。
你是否注意到,我们的两个参数sample_type与normalize_type都使用了概念“树的权重”,但我们在之前讲解XGBoost的基本流程时提到过,XGBoost并不会针对每一棵树计算特定的权重。这个树的权重其实指的是整棵树上所有叶子权重之和。那究竟是怎样让新增加的树的权重刚好就等于原本被抛弃的树的权重的均值或和呢?这就需要一个相对复杂的数学过程来进行解答了,如果你感兴趣,可以查看这一篇说明:https://xgboost.readthedocs.io/en/stable/tutorials/dart.html
当我们在应用的时候,这个点并不会对我们造成影响,只要知道参数如何使用即可。同时,所有dart树相关的参数在原生代码与sklearn代码中都完全一致。
关于DART抛弃树带来的缺陷:
当模型容易过拟合时,我们可以尝试让模型使用DART树来减轻过拟合。不过DART树也会带来相应的问题,最明显的缺点就是:
- 用于微调模型的一些树可能被抛弃,微调可能失效
- 由于存在随机性,模型可能变得不稳定,因此提前停止等功能可能也会变得不稳定
- 由于要随机抛弃一些树的结果,在工程上来说就无法使用每一轮之前计算出的 H k − 1 H_{k-1} Hk−1,而必须重新对选中的树结果进行加权求和,可能导致模型迭代变得略微缓慢
dart树带来的抗过拟合效果比
gamma、lambda等参数更强,不过在提升模型的测试集表现上,dart树还是略逊一筹,毕竟dart树会伤害模型的学习能力。
3.6 不纯度衡量指标criterion结构分数
需要注意的是,XGBoost不接受其他指标作为分枝指标,因此你会发现在众多的xgboost的参数中,并不存在criterion参数
现在,我们来了解结构分数的相关公式:
假设现在目标函数使用L2正则化,控制叶子数量的参数gamma为0。现在存在一个叶子节点
j
j
j,对该节点来说结构分数的公式为:
S c o r e j = ( ∑ i ∈ j g i ) 2 ∑ i ∈ j h i + λ Score_j = \frac{(\sum_{i \in j}g_i)^2}{\sum_{i \in j}h_i + \lambda} Scorej=∑i∈jhi+λ(∑i∈jgi)2
其中, g i g_i gi是样本 i i i在损失函数 L L L上对预测标签求的一阶导数, h i h_i hi是样本 i i i在损失函数 L L L上对预测标签求的二阶导数, i ∈ j i \in j i∈j表示对叶子 j j j上的所有样本进行计算, λ \lambda λ就是L2正则化的正则化系数。所以不难发现,结构分数实际上就是:
S c o r e j = 节点 j 上所有样本的一阶导数之和的平方 节点 j 上所有样本的二阶导数之和 + λ Score_j = \frac{节点j上所有样本的一阶导数之和的平方}{节点j上所有样本的二阶导数之和 + \lambda} Scorej=节点j上所有样本的二阶导数之和+λ节点j上所有样本的一阶导数之和的平方
需要注意结构分数是针对节点计算的,我们以前学习的不纯度衡量指标如基尼系数、信息熵等也是如此。在此基础上,我们依赖于结构分数增益进行分枝,结构分数增益表现为:
G
a
i
n
=
S
c
o
r
e
L
+
S
c
o
r
e
R
−
S
c
o
r
e
P
=
(
∑
i
∈
L
g
i
)
2
∑
i
∈
L
h
i
+
λ
+
(
∑
i
∈
R
g
i
)
2
∑
i
∈
R
h
i
+
λ
−
(
∑
i
∈
P
g
i
)
2
∑
i
∈
P
h
i
+
λ
(见原论文
7
号公式)
这即是说,结构分数增益实际上就是:
G a i n = 左节点的结构分数 + 右节点的结构分数 − 父节点的结构分数 Gain = 左节点的结构分数 + 右节点的结构分数 - 父节点的结构分数 Gain=左节点的结构分数+右节点的结构分数−父节点的结构分数
我们选择增益 G a i n Gain Gain最大的点进行分枝。
你是否注意到,XGBoost中的分枝规则与经典CART树的分枝规则在细节上有所不同?CART树中所使用的信息增益是:
C A R T 树中的信息增益 = 父节点的不纯度 − (左节点的不纯度 + 右节点的不纯度) CART树中的信息增益 = 父节点的不纯度 - (左节点的不纯度 + 右节点的不纯度) CART树中的信息增益=父节点的不纯度−(左节点的不纯度+右节点的不纯度)
我们追求的是最大的信息增益,这意味着随着CART树的建立整体不纯度是在逐渐降低的。无论不纯度衡量指标是基尼系数还是信息熵,不纯度是越小越好。然而在XGBoost当中,增益的计算公式与CART树相反,但我们依然追求最大增益,所以这意味着随着XGBoost树的建立,整体结构分数是逐渐上升的。因此我们可以认为结构分数越大越好。
3.7 弱评估器的控制参数
控制树模型复杂度的方式有两种:一种是对树进行剪枝,一种是从训练数据上下功夫。本节我们先来看弱评估器的剪枝。
XGBoost只有三个剪枝参数和一个侧面影响树生长的参数,其中最为我们熟知的剪枝参数是max_depth,在XGBoost中默认值为6,因此在对抗过拟合方面影响力不是很大,往往我们增大max_depth提高学习能力,使用随机性参数以及
λ
,
γ
,
α
\lambda,\gamma,\alpha
λ,γ,α控制过拟合,需要重点来说明的是以下三个参数:
-
参数
min_child_weight:可以被广义理解为任意节点上所允许的样本量(样本权重)。
更严谨的说法是,min_child_weight是在任意节点 j j j上所允许的最小的 ∑ i ∈ j h i \sum_{i \in j}h_i ∑i∈jhi值。如果一个节点上的 ∑ i ∈ j h i \sum_{i \in j}h_i ∑i∈jhi小于该参数中设置的值,该节点被剪枝。
∑ i ∈ j h i \sum_{i \in j}h_i ∑i∈jhi其实就是结构分数的分母:
S c o r e j = ( ∑ i ∈ j g i ) 2 ∑ i ∈ j h i + λ Score_j = \frac{(\sum_{i \in j}g_i)^2}{\sum_{i \in j}h_i + \lambda} Scorej=∑i∈jhi+λ(∑i∈jgi)2
其中, h i h_i hi是样本 i i i的损失函数 l l l在预测值 f ( x i ) f(x_i) f(xi)上的二阶导数, ∑ i ∈ j h i \sum_{i \in j}h_i ∑i∈jhi就是该节点上所有样本的 h i h_i hi之和。
假设损失函数为 1 2 M S E \frac{1}{2}MSE 21MSE,我们推导出任意样本的 h i = 1 h_i = 1 hi=1,因此 ∑ i ∈ j h i \sum_{i \in j}h_i ∑i∈jhi应该等于该叶子节点上的总样本量。因为这个原因, h i h_i hi在XGBoost原始论文和官方说明中有时被称为“样本权重”(instance weight)。因此,当MSE为损失函数时,参数min_child_weight很类似于sklearn中的min_sample_leaf,即一个节点上所允许的最小样本量。
然而,如果我们使用的损失函数不是MSE,那 h i h_i hi也就不会等于1了。不过官方依然将 h i h_i hi称之为样本权重,当损失函数更换时,样本的权重也随之变化。当损失函数不为MSE时,参数min_child_weight时一个节点上所允许的最小样本权重量。
很显然,参数min_child_weight越大,模型越不容易过拟合,同时学习能力也越弱。 -
参数
gamma:目标函数中叶子数量 T T T前的系数,同时也是允许分枝的最低结构分数增益。当分枝时结构增益不足gamma中设置的值,该节点被剪枝。
在目标函数当中,gamma是叶子数量 T T T前的系数,放大gamma可以将目标函数的重点转移至结构风险,从而控制过拟合:
O b j k = ∑ i = 1 M l ( y i , y i ^ ) + γ T + 1 2 λ ∑ j = 1 T w j 2 + α ∑ j = 1 T w j Obj_k = \sum_{i=1}^Ml(y_i,\hat{y_i}) + \boldsymbol{\color{red}\gamma} T + \frac{1}{2}\boldsymbol{\color{red}\lambda}\sum_{j=1}^Tw_j^2 + \boldsymbol{\color{red}\alpha}\sum_{j=1}^Tw_j Objk=i=1∑Ml(yi,yi^)+γT+21λj=1∑Twj2+αj=1∑Twj
当gamma不为0时,结构分数增益的公式如下:
G a i n = 1 2 ( S c o r e L + S c o r e R − S c o r e P ) − γ = 1 2 ( ( ∑ i ∈ L g i ) 2 ∑ i ∈ L h i + λ + ( ∑ i ∈ R g i ) 2 ∑ i ∈ R h i + λ − ( ∑ i ∈ P g i ) 2 ∑ i ∈ P h i + λ ) − γGain=21(ScoreL+ScoreR−ScoreP)−γ=21(∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑i∈Phi+λ(∑i∈Pgi)2)−γGain=12(ScoreL+ScoreR−ScoreP)−γ=12((∑i∈Lgi)2∑i∈Lhi+λ+(∑i∈Rgi)2∑i∈Rhi+λ−(∑i∈Pgi)2∑i∈Phi+λ)−γ
在XGBoost中,我们追求一棵树整体的结构分数最大,因此XGBoost规定任意结构的分数增益不能为负,任意增益为负的节点都会被剪枝,因此可以默认有:
1 2 ( ( ∑ i ∈ L g i ) 2 ∑ i ∈ L h i + λ + ( ∑ i ∈ R g i ) 2 ∑ i ∈ R h i + λ − ( ∑ i ∈ P g i ) 2 ∑ i ∈ P h i + λ ) − γ > 0 \frac{1}{2} \left( \frac{(\sum_{i \in L}g_i)^2}{\sum_{i \in L}h_i + \lambda} + \frac{(\sum_{i \in R}g_i)^2}{\sum_{i \in R}h_i + \lambda} - \frac{(\sum_{i \in P}g_i)^2}{\sum_{i \in P}h_i + \lambda} \right) - \gamma > 0 21(∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑i∈Phi+λ(∑i∈Pgi)2)−γ>0
因此: 1 2 ( ( ∑ i ∈ L g i ) 2 ∑ i ∈ L h i + λ + ( ∑ i ∈ R g i ) 2 ∑ i ∈ R h i + λ − ( ∑ i ∈ P g i ) 2 ∑ i ∈ P h i + λ ) > γ \frac{1}{2} \left( \frac{(\sum_{i \in L}g_i)^2}{\sum_{i \in L}h_i + \lambda} + \frac{(\sum_{i \in R}g_i)^2}{\sum_{i \in R}h_i + \lambda} - \frac{(\sum_{i \in P}g_i)^2}{\sum_{i \in P}h_i + \lambda} \right) > \gamma 21(∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑i∈Phi+λ(∑i∈Pgi)2)>γ
这是说,当参数gamma为0时,任意增益为负的节点都会被剪枝。当gamma为任意正数时,任意增益小于gamma设定值的节点都会被剪枝。不难发现,gamma在剪枝中的作用就相当于sklearn中的min_impurity_decrease。
很显然,
gamma值越大,算法越不容易过拟合,同时学习能力也越弱。
- 参数
lambda和alpha:正则化系数,同时也位于结构分数中间接影响树的生长和分枝。
当使用L2正则化时,结构分数为:
S c o r e j = ( ∑ i ∈ j g i ) 2 ∑ i ∈ j h i + λ Score_j = \frac{(\sum_{i \in j}g_i)^2}{\sum_{i \in j}h_i + \lambda} Scorej=∑i∈jhi+λ(∑i∈jgi)2
然而,当使用L1正则化时,结构分数为:
S c o r e j = ( ∑ i ∈ j g i ) 2 + α ∑ i ∈ j h i Score_j = \frac{(\sum_{i \in j}g_i)^2 + \alpha}{\sum_{i \in j}h_i} Scorej=∑i∈jhi(∑i∈jgi)2+α
因此,当lambda越大,结构分数会越小,参数gamma的力量会被放大,模型整体的剪枝会变得更加严格,同时,由于lambda还可以通过目标函数将模型学习的重点拉向结构风险,因此lambda具有双重扛过拟合能力。
然而,当alpha越大时,结构分数会越大,参数gamma的力量会被缩小,模型整体的剪枝会变得更宽松。然而,alpha还可以通过目标函数将模型学习的重点拉向结构风险,因此alpha会通过放大结构分数抵消一部分扛过拟合的能力。整体来看,alpha是比lambda更宽松的剪枝方式。
在XGBoost当中,我们可以同时使用两种正则化,则结构分数为:
S c o r e j = ( ∑ i ∈ j g i ) 2 + α ∑ i ∈ j h i + λ Score_j = \frac{(\sum_{i \in j}g_i)^2 + \alpha}{\sum_{i \in j}h_i + \lambda} Scorej=∑i∈jhi+λ(∑i∈jgi)2+α
此时,影响模型变化的因子会变得过多,我们难以再从中找到规律,调参会因此变得略有困难。但是当你感觉到L2正则化本身不足以抵抗过拟合的时候,可以使用L1+L2正则化的方式尝试调参。
3.8 控制复杂度(抽样控制)
除了通过剪枝来控制模型复杂度之外,XGBoost也继承了GBDT和随机森林的优良传统:可以通过对样本和特征进行抽样来增加弱评估器多样性、从而控制过拟合。在这一部分所使用的参数都是我们曾经见过的,只不过在XGBoost当中,我们可以进行更丰富的数据抽样。具体来看:
样本的抽样
- 参数
subsample:对样本进行抽样的比例,默认为1,可输入(0,1]之间的任何浮点数。例如,输入0.5,则表示随机抽样50%的样本进行建树。
当该参数设置为1时,表示使用原始数据进行建模,不进行抽样。同时,XGBoost中的样本抽样是不放回抽样,因此不像GBDT或者随机森林那样存在袋外数据的问题,同时也无法抽样比原始数据更多的样本量。因此,抽样之后样本量只能维持不变或变少,如果样本量较少,建议保持
subsample=1。random_state不影响subsample抽样
- 参数
sampling_method:对样本进行抽样时所使用的抽样方法,默认均匀抽样。
输入"uniform":表示使用均匀抽样,每个样本被抽到的概率一致。如果使用均匀抽样,建议
subsample的比例最好在0.5或以上。
需要注意的是,该参数还包含另一种可能的输入"gradient_based":表示使用有权重的抽样,并且每个样本的权重等于该样本的 g i 2 + λ h i 2 \sqrt{g_i^2 +\lambda h_i^2} gi2+λhi2 。但该输入目前还不支持XGBoost当中主流的gbtree等建树方法,因此一般我们不会用到。
特征的抽样
- 参数
colsample_bytree,colsample_bylevel,colsample_bynode,这几个参数工沟通控制对特征所进行的抽样。
所有形似
colsample_by*的参数都是抽样比例,可输入(0,1]之间的任何浮点数,默认值都为1。
对于GBDT、随机森林来说,特征抽样是发生在每一次建树之前。但对XGBoost来说,特征的抽样可以发生在建树之前(由colsample_bytree控制)、生长出新的一层树之前(由colsample_bylevel控制)、或者每个节点分枝之前(由colsample_bynode控制)。
三个参数之间会互相影响,全特征集 >= 建树所用的特征子集 >= 建立每一层所用的特征子集 >= 每个节点分枝时所使用的特征子集。
举例说明:假设原本有64个特征,参数colsample_bytree等于0.5,则用于建树的特征就只有32个。此时,如果colsample_bylevel不为1,也为0.5,那新建层所用的特征只能由16个,并且这16个特征只能从当前树已经抽样出的32特征中选择。同样的,如果colsample_bynode也不为1,为0.5,那每次分枝之前所用的特征就只有8个,并且这8个特征只能从当前层已经抽样出的16个特征中选择。
在实际使用时,我们可以让任意抽样参数的比例为1,可以在某一环节不进行抽样。一般如果特征量太少(例如,10个以下),不建议同时使用三个参数。
现在我们已经详细介绍了XGBoost当中最简单的弱评估器,按照CART树规则或DART树规则、使用结构分数增益进行分枝的树在XGBoost的系统中被称为“贪婪树”(Greedy Tree)。大部分时候我们都会使用贪婪树来运行XGBoost算法,但在XGBoost当中还有其他几种不同的建树模式,包括基于直方图的估计贪婪树(approx greedy tree)、快速直方图贪婪树(Fast Histogram Approximate Greedy Tree)、以及基于GPU运行的快速直方图贪婪树等内容。这些算法在XGBoost原始论文中占了较大篇幅,并且在后续的LightGBM算法中被发扬光大,将在LGBM算法中详细讲解直方图方法。在使用XGBoost时,我们将专注于贪婪树本身。
3.9 其他参数
目前为止,我们已经将与XGBoost的训练、建树相关的参数全部讲解完毕了,剩余的参数是一些功能性的参数,如果你已经熟悉课程中其他算法,那这些参数对你来说应该非常容易,包括:
- 提前停止
参数
early_stopping_rounds:位于xgb.train方法当中。如果规定的评估指标不能连续early_stopping_rounds次迭代提升,那就触发提前停止。
- 模型监控与评估
参数
evals:位于xgb.train方法当中,用于规定训练当中所使用的评估指标,一般都与损失函数保持一致,也可选择与损失函数不同的指标。该指标也用于提前停止。
参数verbosity:用于打印训练流程和训练结果的参数。在最早的版本中该参数为silent,后来经过更新变成了今天的verbosity。然而,经过改进之后的verbosity更倾向于帮助我们打印建树相关的信息,而不像原来的silent一样帮助我们展示训练过程中的模型评估信息,因此verbosity现在不那么实用了。我们可以在verbosity中设置数字[0,1,2,3],参数默认值为1。
- 0:不打印任何内容
- 1:表示如果有警告,请打印警告
- 2:请打印建树的全部信息
- 3:我正在debug,请帮我打印更多的信息。
- 样本不均衡
参数
scale_pos_weight:调节样本不均衡问题,类似于sklearn中的class_weight,仅在算法执行分类任务时有效。参数scale_pos_weight的值时负样本比正样本的比例,默认为1,因此XGBoost时默认调节样本不均衡的。同时,如果你需要手动设置这个参数,可以输入(负样本总量)/(正样本总量)这样的值。
探究scale_pos_weight对数据的影响(sklearn库实现的)
from sklearn.datasets import make_blobs from sklearn.metrics import confusion_matrix as cm, recall_score as recall, roc_auc_score as auc import xgboost as xgb class_1 = 500 class_2 = 50 centers = [[0.0, 0.0], [2.0, 2.0]] clusters_std = [1.5, 0.5] [X, y] = make_blobs(n_samples=[class_1, class_2], n_features=2, centers=centers, cluster_std=clusters_std, shuffle=True, random_state=0, return_centers=False, ) X_train, X_test, y_train, y_test = TTS(X, y, test_size=0.3, random_state=0) # 使用scale_pos_weight默认值1 sklearn_model = xgb.XGBClassifier(random_state=1, scale_pos_weight=1) sklearn_model.fit(X_train, y_train, eval_metric="logloss") y_pre = sklearn_model.predict(X_test) # 混淆矩阵 cm(y_test,y_pre,labels=[1,0]) # array([[ 15, 3], # [ 5, 142]], dtype=int64) # 准确率 sklearn_model.score(X_test, y_test) # 0.9515151515151515 # 召回率 recall(y_test,y_pre) # 0.8333333333333334 # AUC auc(y_test,sklearn_model.predict_proba(X_test)[:,1]) # 0.9792139077853362 #****************************scale_pos_weight变成10,因为class_1 : class_2 = 500 : 50 sklearn_model_scale = xgb.XGBClassifier( random_state=1, scale_pos_weight=10) sklearn_model_scale.fit(X_train, y_train, eval_metric="logloss") y_pre_scale = sklearn_model_scale.predict(X_test) cm(y_test,y_pre_scale,labels=[1,0]) #array([[ 16, 2], # [ 4, 143]], dtype=int64) sklearn_model_scale.score(X_test, y_test) #0.9636363636363636 recall(y_test,y_pre_scale) #0.8888888888888888 auc(y_test,sklearn_model_scale.predict_proba(X_test)[:,1]) #0.9792139077853362 # ************************************不同scale_pos_weight下准确率,召回率,AUC曲线 rang=[1,5,10,20,30] acu_list=[] recall_list=[] auc_list=[] for i in rang: clf=xgb.XGBClassifier(scale_pos_weight=i).fit(X_train,y_train) y_pr=clf.predict(X_test) acu_list.append(clf.score(X_test,y_test)) recall_list.append(recall(y_test,y_pr)) auc_list.append(auc(y_test,clf.predict_proba(X_test)[:,1])) ax = plt.figure(figsize=(15, 8)).add_subplot(111) ax.plot(rang,acu_list,label="Accuracy") ax.plot(rang,recall_list,label="Recall") ax.plot(rang,auc_list,label="AUC") plt.legend(fontsize = "xx-large") plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
在一些特定情况下,我们更加倾向于在保证准确率的情况下看中召回率,这就是scale_pos_weight参数的作用,而不是一味的追求准确率。

- 并行的线程
参数
nthread:允许并行的最大线程数,类似于sklearn中的n_jobs,默认为最大,因此xgboost在默认运行时就会占用大量资源。如果数据量较大、模型体量较大,可以设置比最大线程略小的线程,为其他程序运行留出空间。
3.10 参数总结
| 类型 | 参数 |
|---|---|
| 弱评估器 | booster:选择迭代过程中的弱评估器类型,包括gbtree,DART和线性模型 sample_type:DART树中随机抽样树的具体方法 rate_drop:DART树中所使用的抛弃率 one_drop:每轮迭代时至少需要抛弃的树的数量 skip_drop:在迭代中不进行抛弃的概率 normalized_type:根据被抛弃的树的权重控制新增树权重 max_depth:允许的弱评估器的最大深度 min_child_weight:(广义上)叶子节点上的最小样本权重/最小样本量 gamma:目标函数中叶子数量 T T T的系数,同时也是分枝时所需的最小结构分数增益值 lambda与alpha:正则项系数,同时也位于结构分数的公式中,间接影响模型的剪枝 sample_type:对样本进行抽样具体方式 subsample:对样本进行抽样的具体比例 colsample_bytree, colsample_bylevel, colsample_bynode:在建树过程中对特征进行抽样的比例 |
3.11 结构化分数样例
那结构分数的含义是什么呢?它也像信息熵一样,可以衡量叶子节点的某种属性吗?为什么结构分数需要越大越好呢?这些问题需要大家了解数学推导过程后才能解答,但我们在这里可以举一个很简单的例子来证实结构分数增益越大、选出的分枝越好。
假设现在我们有一个超简单的节点需要分割,该节点中所包含的样本如下:
| 样本 | y | y_hat |
|---|---|---|
| 1 | 1 | 0.5 |
| 2 | -2 | 0.5 |
| 3 | -2 | 0.5 |
众所周知,在决策树中一个节点只能有一个输出值,因此同一片叶子上所有样本的预测值都一致,不同的树模型使用不同的方法来计算叶子节点上的输出值,大部分模型都直接使用样本的真实值的均值作为输出,但XGBoost有自己不同的手段。现在我们可以暂时忽略这一点,先假设当前的节点预测值为0.5。
现在要对该节点进行分割,你知道从哪里分枝会最有效吗?因为一片叶子只会输出一个预测值,所以相同标签的样本最好在一片叶子上。因此很明显,因为2、3号叶子的真实值一致,我们应该将该节点从1号样本和2号样本中间分开,让1号样本单独在一片叶子上,而2、3号样本在一片叶子上(1,23)。但实际在进行分枝时,我们需要尝试所有可能的方式,并分别计算以下方式的结构分数增益:
- 分割方案1:(1,23)
| 左子节点 | y | y_hat | 右子节点 | y | y_hat | |
|---|---|---|---|---|---|---|
| 1 | 1 | 0.5 | 2 | -2 | 0.5 | |
| 3 | -2 | 0.5 |
- 分割方案2:(12,3)
| 左子节点 | y | y_hat | 右子节点 | y | y_hat | |
|---|---|---|---|---|---|---|
| 1 | 1 | 0.5 | 3 | -2 | 0.5 | |
| 2 | -2 | 0.5 |
假设现在执行的是XGBoost回归,损失函数为0.5倍MSE,公式为 1 2 ( y − y ^ ) 2 \frac{1}{2}(y - \hat{y})^2 21(y−y^)2,假设lambda=1。那基于MSE的一阶导数为:
l
=
1
2
(
y
i
−
y
i
^
)
2
l
′
=
∂
∂
y
i
^
1
2
(
y
i
−
y
i
^
)
2
=
−
(
y
i
−
y
i
^
)
=
y
i
^
−
y
i
基于MSE的二阶导数为:
l
′
′
=
∂
∂
y
i
^
(
y
i
^
−
y
i
)
=
1
因此无论如何划分, g i = y i ^ − y i g_i = \hat{y_i} - y_i gi=yi^−yi, h i = 1 h_i = 1 hi=1。现在来计算父节点和两个子节点上每个样本的 g i g_i gi与 h i h_i hi:
- 父节点:
| 样本 | y | y_hat | gi | hi |
|---|---|---|---|---|
| 1 | 1 | 0.5 | -0.5 | 1 |
| 2 | -2 | 0.5 | 2.5 | 1 |
| 3 | -2 | 0.5 | 2.5 | 1 |
因此父节点的结构分数为:
S
c
o
r
e
P
=
(
∑
i
∈
P
g
i
)
2
∑
i
∈
P
h
i
+
λ
=
(
−
0.5
+
2.5
+
2.5
)
2
3
+
1
=
5.0625
- 方案1
| 左子节点 | y | y_hat | gi | hi | 右子节点 | y | y_hat | gi | hi | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.5 | -0.5 | 1 | 2 | -2 | 0.5 | 2.5 | 1 | |
| 3 | -2 | 0.5 | 2.5 | 1 |
方案1下两个子节点的结构分数为:
S
c
o
r
e
L
1
=
(
∑
i
∈
L
1
g
i
)
2
∑
i
∈
L
1
h
i
+
λ
=
(
−
0.5
)
2
1
+
1
=
0.125
S
c
o
r
e
R
1
=
(
∑
i
∈
R
1
g
i
)
2
∑
i
∈
R
1
h
i
+
λ
=
(
2.5
+
2.5
)
2
2
+
1
=
8.333
因此增益等于:
G
a
i
n
=
S
c
o
r
e
L
1
+
S
c
o
r
e
R
1
−
S
c
o
r
e
P
=
0.125
+
8.333
−
5.6025
=
3.395
- 方案2
| 左子节点 | y | y_hat | gi | hi | 右子节点 | y | y_hat | gi | hi | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.5 | -0.5 | 1 | 3 | -2 | 0.5 | 2.5 | 1 | |
| 2 | -2 | 0.5 | 2.5 | 1 |
方案1下两个子节点的结构分数为:
S
c
o
r
e
L
1
=
(
∑
i
∈
L
1
g
i
)
2
∑
i
∈
L
1
h
i
+
λ
=
(
−
0.5
+
2.5
)
2
2
+
1
=
1.333
S
c
o
r
e
R
1
=
(
∑
i
∈
R
1
g
i
)
2
∑
i
∈
R
1
h
i
+
λ
=
(
2.5
)
2
1
+
1
=
3.125
因此增益等于:
G
a
i
n
=
S
c
o
r
e
L
1
+
S
c
o
r
e
R
1
−
S
c
o
r
e
P
=
1.333
+
3.125
−
5.0625
=
−
0.604
很明显,方案1(1,23)的增益为3.395,远远大于方案2(12,3)的增益-0.604,因此根据结构分数增益的指示,我们应该使用第一种分割方式,这与我们经验判断的一致。在XGBoost建树过程中,我们需要对每一个节点进行如上计算,不断来选出令增益更大的分枝。
- 结构分数与信息熵的关键区别
不知道你是否注意到一个问题。在之前我们提到过,结构分数是越大越好。在方案1当中,左侧叶子节点上的结构分数为0.125,右侧叶子节点上的结构分数为8.333,这是否意味着左侧叶子比右侧叶子更好呢?答案是否定的。与信息熵、基尼系数等可以评价单一节点的指标不同,结构分数只能够评估结构本身的优劣,不能评估节点的优劣。
比如说,方案1中的树结构有更高的分数之和,方案2中的树结构的分数之和较低,所以方案1更好。但我们不能说,方案1中的左节点分数低,右节点分数高,所以右节点比左节点更好。因此,在XGBoost原始论文当中,我们利用一棵树上所有叶子的结构分数之和来评估整棵树的结构的优劣,分数越高则说明树结构质量越高,因此在原论文中,结构分数也被称为质量分数(quality score)。
3.12 超参数优化
3.12.1 参数影响力
| 影响力 | 参数 |
|---|---|
| ⭐⭐⭐⭐⭐ 几乎总是具有巨大影响力 | num_boost_round(整体学习能力) eta(整体学习速率) |
| ⭐⭐⭐⭐ 大部分时候具有影响力 | booster(整体学习能力) colsample_by*(随机性) gamma(结构风险 + 精剪枝) lambda(结构风险 + 间接剪枝) min_child_weight(精剪枝) |
| ⭐⭐ 可能有大影响力 大部分时候影响力不明显 | max_depth(粗剪枝) alpha(结构风险 + 精剪枝) subsamples(随机性) objective(整体学习能力) scale_pos_weight(样本不均衡) |
| ⭐ 当数据量足够大时,几乎无影响 | seed base_score(初始化) |
比起其他树的集成算法,XGBoost有大量通过影响建树过程而影响整体模型的参数(比如gamma,lambda等)。这些参数以较为复杂的方式共同作用、影响模型的最终结果,因此他们的影响力不是线性的,也不总是能在调参过程中明显地展露出来,但调节这些参数大多数时候都能对模型有影响,因此大部分与结构风险相关的参数都被评为4星参数了。相对的,对XGBoost来说总是具有巨大影响力的参数就只有迭代次数与学习率了。
在上述影响力排名当中,需要特别说明以下几点:
-
在随机森林中影响力巨大的
max_depth在XGBoost中默认值为6,比GBDT中的调参空间略大,但还是没有太多的空间,因此影响力不足。 -
在GBDT中影响力巨大的
max_features对标XGBoost中的colsample_by*系列参数,原则上来说影响力应该非常大,但由于三个参数共同作用,调参难度较高,在只有1个参数作用时效果略逊于max_features。 -
精剪枝参数往往不会对模型有太大的影响,但在XGBoost当中,
min_child_weight与结构分数的计算略微相关,因此有时候会展现出较大的影响力。故而将这个精剪枝参数设置为4星参数。 -
类似于
objective这样影响整体学习能力的参数一般都有较大的影响力,但XGBoost当中每种任务可选的损失函数不多,因此一般损失函数不在调参范围之内,故认为该参数的影响力不明显。 -
XGBoost的初始化分数只能是数字,因此当迭代次数足够多、数据量足够大时,起点的影响会越来越小。因此我们一般不会对base_score进行调参。
首先会考虑所有影响力巨大的参数(5星参数),当算力足够/优化算法运行较快的时候,我们可以考虑将大部分时候具有影响力的参数(4星)也都加入参数空间。一般来说,只要样本量足够,我们还是愿意尝试subsample以及max_depth,如果算力充足,我们还可以加入obejctive这样或许会有效的参数。
需要说明的是,一般不会同时使用三个colsample_by*参数、更不会同时调试三个colsample_by*参数。首先,参数colsample_bylevel较为不稳定,不容易把握,因此当训练资源充足时,会同时调整colsample_bytree和colsample_bynode。如果计算资源不足,或者优先考虑节约计算时间,则会先选择其中一个参数、尝试将特征量控制在一定范围内来建树,并观察模型的结果。在这三个参数中,使用bynode在分枝前随机,比使用bytree建树前随机更能带来多样性、更能对抗过拟合,但同时也可能严重地伤害模型的学习能力。在这里,我将尝试同时使用两个参数进行调参。
3.12.2 参数空间的确定
需要确认参数空间:
- 对于有界的参数(比如
colsample_bynode,subsamples等),或者有固定选项的参数(比如booster,objective),无需确认参数空间。 - 对取值较小的参数(例如学习率
eta,一般树模型的min_impurity_decrease等),或者通常会向下调整的参数(比如max_depth),一般是围绕默认值向两边展开构建参数空间。 - 对于取值可大可小,且原则上可取到无穷值的参数(
num_boost_round,gamma、lambda、min_child_weight等),一般需要绘制学习曲线进行提前探索,或者也可以设置广而稀的参数空间,来一步步缩小范围。
在之前的课程当中,我们已经对gamma和lambda的范围进行过探索,其中lambda范围[1,2]之间对模型有影响,而gamma在[1e6,1e7]之间才对模型有影响。因此我们可以先规定lambda的参数空间为np.arange(0,3,0.2),并规定gamma的参数空间为np.arange(1e6,1e7,1e6)。现在我们对剩下2个参数num_boost_round,min_child_weight绘制学习曲线进行轻度探索。结果如下所示:
| 参数 | 范围 |
|---|---|
num_boost_round | 学习曲线探索,最后定为 (50,200,10) |
eta | 以0.3为中心向两边延展,最后定为 (0.05,2.05,0.05) |
booster | 两种选项 [“gbtree”,“dart”] |
colsample_bytree | 设置为(0,1]之间的值,但由于还有参数bynode,因此整体不宜定得太小,因此定为(0.3,1,0.1) |
colsample_bynode | 设置为(0,1]之间的值,定为 (0.1,1,0.1) |
gamma | 学习曲线探索,有较大可能需要改变,定为 (1e6,1e7,1e6) |
lambda | 学习曲线探索,定为 (0,3,0.2) |
min_child_weight | 学习曲线探索,定为 (0,50,2) |
max_depth | 以6为中心向两边延展,右侧范围定得更大 (2,30,2) |
subsample | 设置为(0,1]之间的值,定为 (0.1,1,0.1) |
objective | 两种回归类模型的评估指标 [“reg:squarederror”, “reg:squaredlogerror”] |
rate_drop | 如果选择"dart"树所需要补充的参数,设置为(0,1]之间的值 (0.1,1,0.1) |
3.12.4 优化代码
#日常使用库与算法 import pandas as pd import numpy as np import sklearn import matplotlib as mlp import matplotlib.pyplot as plt import time import xgboost as xgb #导入优化算法 import hyperopt from hyperopt import hp, fmin, tpe, Trials, partial from hyperopt.early_stop import no_progress_loss data = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\train_encode.csv",index_col=0) X = data.iloc[:,:-1] y = data.iloc[:,-1] def hyperopt_objective(params): paramsforxgb = {"eta":params["eta"] ,"booster":params["booster"] ,"colsample_bytree":params["colsample_bytree"] ,"colsample_bynode":params["colsample_bynode"] ,"gamma":params["gamma"] ,"lambda":params["lambda"] ,"min_child_weight":params["min_child_weight"] ,"max_depth":int(params["max_depth"]) ,"subsample":params["subsample"] ,"objective":params["objective"] ,"rate_drop":params["rate_drop"] ,"nthread":14 ,"verbosity":0 ,"seed":1412} result = xgb.cv(paramsforxgb,data_xgb, seed=1412, metrics=("rmse") ,num_boost_round=int(params["num_boost_round"])) return result.iloc[-1,2] def param_hyperopt(max_evals=100): #保存迭代过程 trials = Trials() #设置提前停止 early_stop_fn = no_progress_loss(30) #定义代理模型 params_best = fmin(hyperopt_objective , space = param_grid_simple , algo = tpe.suggest , max_evals = max_evals , verbose=True , trials = trials , early_stop_fn = early_stop_fn ) #打印最优参数,fmin会自动打印最佳分数 print("\n","\n","best params: ", params_best, "\n") return params_best, trials
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
运行:
params_best, trials = param_hyperopt(100)
- 1
由于高斯最优化模型具有随机性,所以要运行多次(M次)代码:
params_best, trials = param_hyperopt(100)
得出M个最优参数组合,根据这几个最优化模型参数组合保留参数相同的一些参数像:criterion,loss,但是如果尽管max_depth参数可能相同,但是不能确定,因为后续进一步调参具有随机性。
然后根据这M次最优化组合,取得近边缘值则调整参数范围、取得中值减小参数范围增加参数密度,进一步调参,运行param_hyperopt代码.
3.13 Xgboost数学原理
3.13.1 算法流程
假设现有数据集 N N N,含有形如 ( x i , y i ) (x_i,y_i) (xi,yi)的样本 M M M个, i i i为任意样本的编号,单一样本的损失函数为 l ( y i , H ( x i ) ) l(y_i,H(x_i)) l(yi,H(xi)),其中 H ( x i ) H(x_i) H(xi)是 i i i号样本在集成算法上的预测结果,整个算法的损失函数为 L ( y , H ( x ) ) L(y,H(x)) L(y,H(x)),且总损失等于全部样本的损失之和: L ( y , H ( x ) ) = ∑ i l ( y i , H ( x i ) ) L(y,H(x)) = \sum_i l(y_i,H(x_i)) L(y,H(x))=∑il(yi,H(xi))。目标函数中使用L2正则化( λ \lambda λ为0, α \alpha α为0),并且 γ \gamma γ不为0。
同时,弱评估器为回归树 f f f,总共学习 K K K轮(注意在GBDT当中我们使用的是大写字母T来表示迭代次数,由于在XGBoost当中字母T被用于表示目标函数中的叶子总量,因此我们在这里使用字母K表示迭代次数)。则XGBoost回归的基本流程如下所示:
-
1) 初始化
初始化数据迭代的起点 H 0 ( x ) H_0(x) H0(x)。在应用xgboost时,我们可以指定任意数字来作为 H 0 ( x ) H_0(x) H0(x),但在xgboost原始论文当中,并未详细讨论如何计算迭代的初始值。考虑到XGBoost在许多方面继承了梯度提升树GBDT的思想,我们可以使用公式来计算XGBoost的 H 0 H_0 H0:
H 0 ( x ) = a r g m i n C ∑ i = 1 M l ( y i , C ) = a r g m i n C L ( y , C )H0(x)=argminCi=1∑Ml(yi,C)=argminCL(y,C)H0(x)=argminC∑i=1Ml(yi,C)=argminCL(y,C)
其中 y i y_i yi为真实标签, C C C为任意常数。以上式子表示,找出令 ∑ i = 1 M l ( y i , C ) \sum_{i=1}^Ml(y_i,C) ∑i=1Ml(yi,C)最小的常数 C C C值,并输出最小的 ∑ i = 1 M l ( y i , C ) \sum_{i=1}^Ml(y_i,C) ∑i=1Ml(yi,C)作为 H 0 ( x ) H_0(x) H0(x)的值。需要注意的是,由于 H 0 ( x ) H_0(x) H0(x)是由全部样本的 l l l计算出来的,因此所有样本的初始值都是 H 0 ( x ) H_0(x) H0(x),不存在针对某一样本的单一初始值。
由于在初始的时候没有树结构,因此没有复杂度等信息,因此没有使用目标函数求初始值,而是使用了损失函数。在GBDT的数学过程当中,我们详细展示过如何求解令初始损失最小的 C C C(对损失求一阶导数并让一阶导数为0),并且我们详细证明过,当损失函数为MSE时,令整体初始损失最小的 C C C值就是 y y y的均值。对XGBoost来说这一切都成立,只不过在xgboost库中我们默认的初始值为0.5。
开始循环,for k in 1,2,3…K:
2) 抽样
在现有数据集 N N N中,抽样 M M M *subsample个样本,构成训练集 N k N^k Nk
3) 求拟合项
对任意一个样本 i i i,计算一阶导数 g i k g_{ik} gik,二阶导数 h i k h_{ik} hik,以及伪残差(pseudo-residuals) r i k r_{ik} rik,具体公式为:
g i k = ∂ l ( y i , H k − 1 ( x i ) ) ∂ H k − 1 ( x i ) g_{ik} = \frac{\partial{l(y_i,H_{k-1}(x_i))}}{\partial{H_{k-1}(x_i)}} gik=∂Hk−1(xi)∂l(yi,Hk−1(xi))
h i k = ∂ 2 l ( y i , H k − 1 ( x i ) ) ∂ H k − 1 2 ( x i ) h_{ik} = \frac{\partial^2{l(y_i,H_{k-1}(x_i))}}{\partial{H^2_{k-1}(x_i)}} hik=∂Hk−12(xi)∂2l(yi,Hk−1(xi))
r i k = − g i k h i k r_{ik} = -\frac{g_{ik}}{h_{ik}} rik=−hikgik
不难发现,伪残差是一个样本的一阶导数除以二阶导数并取负的结果,并且在进行第k次迭代、计算第k个导数时,我们使用的是前k-1次迭代后输出的集成算法结果。同时,我们是先对目标函数 l l l中的自变量 H ( x ) H(x) H(x)求导,再令求导后的结果等于 H t − 1 ( x i ) H_{t-1}(x_i) Ht−1(xi)的值,并不是直接对 H t − 1 ( x i ) H_{t-1}(x_i) Ht−1(xi)这一常数求导。
对常数求导,以及对变量求导是两个概念,举例说明:
l = x 2 + x l = x^2+x l=x2+x
对常数0求导: ∂ l ∂ 0 = ∂ ( x 2 + x ) 0 = 0 \frac{\partial{l}}{\partial{0}} = \frac{\partial{(x^2 + x)}}{0} = 0 ∂0∂l=0∂(x2+x)=0
对变量x求导并让x=0: ∂ l ∂ x = ∂ ( x 2 + x ) ∂ x = 2 x + 1 = 2 ∗ 0 + 1 = 1 \frac{\partial{l}}{\partial{x}} = \frac{\partial{(x^2 + x)}}{\partial x} = 2x + 1 = 2*0 + 1 = 1 ∂x∂l=∂x∂(x2+x)=2x+1=2∗0+1=1
因此, g i k g_{ik} gik标准的写法应该是:
g i k = [ ∂ l ( y i , H ( x i ) ) ∂ H ( x i ) ] H ( x i ) = H k − 1 ( x i ) g_{ik} = \big[\frac{\partial{l(y_i,H(x_i))}}{\partial{H(x_i)}}\big]_{H(x_i) = H_{k-1}\ \ (x_i)} gik=[∂H(xi)∂l(yi,H(xi))]H(xi)=Hk−1 (xi)
在实际推导过程中,为公式简洁,简写为上述流程中的写法。
在k=1时,所有求导计算过程中的 H k − 1 ( x i ) H_{k-1}(x_i) Hk−1(xi)都等于初始 H 0 ( x ) H_0(x) H0(x),在k>1时,每个样本上的 H k − 1 ( x i ) H_{k-1}(x_i) Hk−1(xi)都是不同的取值。
4) 建树
求解出伪残差后,在数据集 ( x i , r i k ) (x_i, r_{ik}) (xi,rik)上按colsample_by*规则进行抽样,再按照结构分数增益规则建立一棵回归树 f k f_k fk。注意在这个过程中,训练时拟合的标签为样本的伪残差 r i k r_{ik} rik,并且叶子节点 j j j的结构分数和任意分枝时的结构分数增益的公式为:
S c o r e j = ( ∑ i ∈ j g i ) 2 ∑ i ∈ j h i + λ Score_j = \frac{(\sum_{i \in j}g_i)^2}{\sum_{i \in j}h_i + \lambda} Scorej=∑i∈jhi+λ(∑i∈jgi)2
G a i n = 1 2 ( ( ∑ i ∈ L g i ) 2 ∑ i ∈ L h i + λ + ( ∑ i ∈ R g i ) 2 ∑ i ∈ R h i + λ − ( ∑ i ∈ P g i ) 2 ∑ i ∈ P h i + λ ) − γ Gain = \frac{1}{2} \left( \frac{(\sum_{i \in L}g_i)^2}{\sum_{i \in L}h_i + \lambda} + \frac{(\sum_{i \in R}g_i)^2}{\sum_{i \in R}h_i + \lambda} - \frac{(\sum_{i \in P}g_i)^2}{\sum_{i \in P}h_i + \lambda} \right) - \gamma Gain=21(∑i∈Lhi+λ(∑i∈Lgi)2+∑i∈Rhi+λ(∑i∈Rgi)2−∑i∈Phi+λ(∑i∈Pgi)2)−γ
建树过程不影响任何 g i k g_{ik} gik与 h i k h_{ik} hik的值。
5) 输出树上的结果
建树之后,依据回归树 f k f_k fk的结构输出叶子节点上的输出值(预测值)。对任意叶子节点 j j j来说,输出值为:
w j = − ∑ i ∈ j g i k ∑ i ∈ j h i k + λ w_j = -\frac{\sum_{i \in j}g_{ik}}{\sum_{i \in j}h_{ik} + \lambda} wj=−∑i∈jhik+λ∑i∈jgik
假设样本 i i i被分割到叶子 j j j上,则有:
f k ( x i ) = w j f_k(x_i) = w_j fk(xi)=wj
使用字母 w w w表示叶子节点上的输出值是XGBoost论文所规定的,我们曾经见过一次 w w w,你还记得在哪里吗?在我们介绍XGBoost的目标函数时,L2正则项的表达式为 1 2 λ ∑ j = 1 T w j 2 \frac{1}{2} \lambda \sum_{j=1}^T w_j^2 21λ∑j=1Twj2。我们曾说过 w w w代表XGBoost中的叶子权重,实际上叶子权重就是叶子上的输出值。为不和其他权重混淆,之后我们统一称呼 w w w为输出值。
不难发现,叶子节点上的输出值与结构分数很相似,只不过结构分数的分子上是平方,而输出值的分子上没有平方。在数学上我们可以证明,该输出值能让目标函数最快减小。
你可能注意到了,在迭代刚开始时我们已经知道了输出值式子中所需的所有 g g g和 h h h。为什么还要建树呢?只有当我们建立了决策树,我们才能够知道具体哪些样本 i i i在叶子节点 j j j上。因此树 f k f_k fk提供的是结构信息。
由于任意样本必然被分到任意叶子上,因此对整棵树 f k f_k fk来说,任意 f k ( x i ) f_k(x_i) fk(xi)一定有对应的 w w w。
6) 迭代
根据预测结果 f k ( x i ) f_k(x_i) fk(xi)迭代模型,具体来说:
H k ( x i ) = H k − 1 ( x i ) + f k ( x i ) H_k(x_i) = H_{k-1}(x_i) + f_k(x_i) Hk(xi)=Hk−1(xi)+fk(xi)
假设输入的步长为 η \eta η,则 H k ( x ) H_k(x) Hk(x)应该为:
H k ( x i ) = H k − 1 ( x i ) + η f k ( x i ) H_k(x_i) = H_{k-1}(x_i) + \eta f_k(x_i) Hk(xi)=Hk−1(xi)+ηfk(xi)
对整个算法则有:
H k ( x ) = H k − 1 ( x ) + η f k ( x ) H_k(x) = H_{k-1}(x) + \eta f_k(x) Hk(x)=Hk−1(x)+ηfk(x) -
7) 循环结束
输出 H K ( x ) H_K(x) HK(x)的值作为集成模型的输出值。
以上就是XGBoost的完整数学流程。不难发现,作为从GBDT改进而来的算法,XGBoost在基础数学流程上基本继承了GBDT的流程(7步走的流程与GBDT一模一样,同时也有继承伪残差等细节),但又在具体每个流程中都做出了改进,进一步简化了Boosting算法的运算流程——比如说,虽然整个算法持续再向降低目标函数的方向运行,但整个过程中不存在任何的求最优解的数学计算。除了建树流程以外,其他流程都是非常简单的按公式计算而已。
3.13.2 存在的问题
对XGBoost来说,真正难度较大的部分并不是梳理以上算法流程,而是证明这一流程可以让模型向着目标函数最小化的方向运行。在这个流程中包括如下很明显的问题:
-
建树时拟合的 r i k = − g i k h i k r_{ik} = -\frac{g_{ik}}{h_{ik}} rik=−hikgik究竟是什么?拟合它有什么意义?
-
结构分数和结构分数增益的公式是如何推导出来的?为什么这样建树可以提升模型的效果?
-
为什么叶子节点的输出值 w j w_j wj是 − ( ∑ i ∈ j g i k ) ∑ i ∈ j h i k + λ -\frac{(\sum_{i \in j} g_{ik})}{\sum_{i \in j} h_{ik} + \lambda} −∑i∈jhik+λ(∑i∈jgik)?这样输出有什么意义?
-
课程的第一部分说XGBoost拟合的也是残差,残差在哪里?
文章太长转账另一篇:

