
- 1单兵渗透工具-Yakit-Windows安装使用
- 2【k8s总结】
- 3大数据毕业设计hadoop+spark+hive招聘推荐系统 招聘分析可视化大屏 职位推荐系统 就业推荐系统 招聘爬虫 招聘大数据 计算机毕业设计 机器学习 深度学习 人工智能_spark招聘就业类大屏
- 4媒体邀约有啥要注意的
- 5【CVPR2021】LoFTR:基于Transformers的无探测器的局部特征匹配方法_loftr场景匹配
- 6人工智能的研究方向
- 7uniapp跨域解决_uniapp解决跨域问题
- 8稀疏编码在深度学习中的挑战
- 9【ubuntu-22.04】系统配置之 netplan 网络配置_netplan routes
- 10【深度学习】读取和存储训练好的模型参数(pyTorch)_训练结束后得到了一个pytorchmodel.bin文件,怎么去读取运用他
AI小程序——文本绘图_图像生成文本的ai
赞
踩
一、摘要
在文字生成图像上,文心 ERNIE-ViLG 可以根据用户输入的文本,自动创作图像,生成的图像不仅符合文字描述,而且达到了非常逼真的效果。在图像到文本的生成上,文心 ERNIE-ViLG 能够理解画面,用简洁的语言描述画面的内容,还能够根据图片中的场景回答相关的问题。
前不久,百度产业级知识增强大模型 “文心” 全景图亮相,近日,其中的跨模态生成模型 ERNIE-ViLG 在百度文心官网开放体验入口,并放出了论文:
论文链接:https://arxiv.org/pdf/2112.15283.pdf

据悉,文心 ERNIE-ViLG 参数规模达到 100 亿,是目前为止全球最大规模中文跨模态生成模型,该模型首次通过自回归算法将图像生成和文本生成统一建模,增强模型的跨模态语义对齐能力,显著提升图文生成效果。
先带你体验一下体验文心 ERNIE-ViLG “图像创作”能力:


最近也注意到用AI技术来指定文本来画图,感觉挺好玩,遂写了个调用百度文心大模型的API的电脑程序,来增强体验感。

下面先放个最终体验:

二、文心 ERNIE-ViLG 技术原理解读:图文双向生成统一建模
百度文心 ERNIE-ViLG 使用编码器 - 解码器参数共享的 Transformer 作为自回归生成的主干网络,同时学习文本生成图像、图像生成文本两个任务。
基于图像向量量化技术,文心 ERNIE-ViLG 把图像表示成离散的序列,从而将文本和图像进行统一的序列自回归生成建模。在文本生成图像时, 文心 ERNIE-ViLG 模型的输入是文本 token 序列,输出是图像 token 序列;图像生成文本时则根据输入的图像序列预测文本内容。两个方向的生成任务使用同一个 Transformer 模型。视觉和语言两个模态在相同模型参数下进行相同模式的生成,能够促进模型建立更好的跨模态语义对齐。
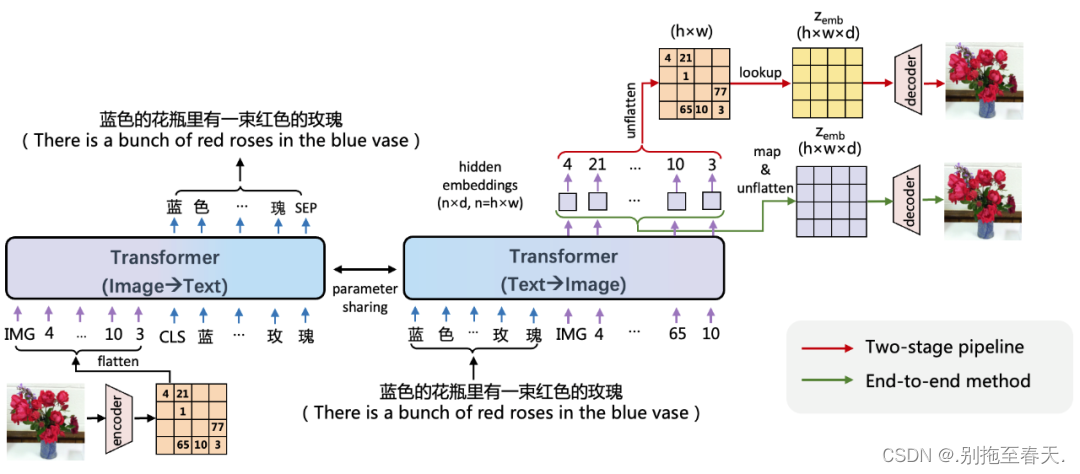
已有基于图像离散表示的文本生成图像模型主要采用两阶段训练,文本生成视觉序列和根据视觉序列重建图像两个阶段独立训练,文心 ERNIE-ViLG 提出了端到端的训练方法,将序列生成过程中 Transformer 模型输出的隐层图像表示连接到重建模型中进行图像还原,为重建模型提供语义更丰富的特征;对于生成模型,可以同时接收自身的抽象监督信号和来自重建模型的原始监督信号,有助于更好地学习图像表示。
文心 ERNIE-ViLG 构建了包含 1.45 亿高质量中文文本 - 图像对的大规模跨模态对齐数据集,并基于百度飞桨深度学习平台在该数据集上训练了百亿参数模型,在文本生成图像、图像描述等跨模态生成任务上评估了该模型的效果。
三、使用教程
2.1 exe下载
文心大模型在官网也可以直接体验,我是简单制作了一个小程序,来调用API并在本地显示,windows体验小程序也打包成了exe文件,下载链接:文本生成图片exe可执行文件
2.2 获取API
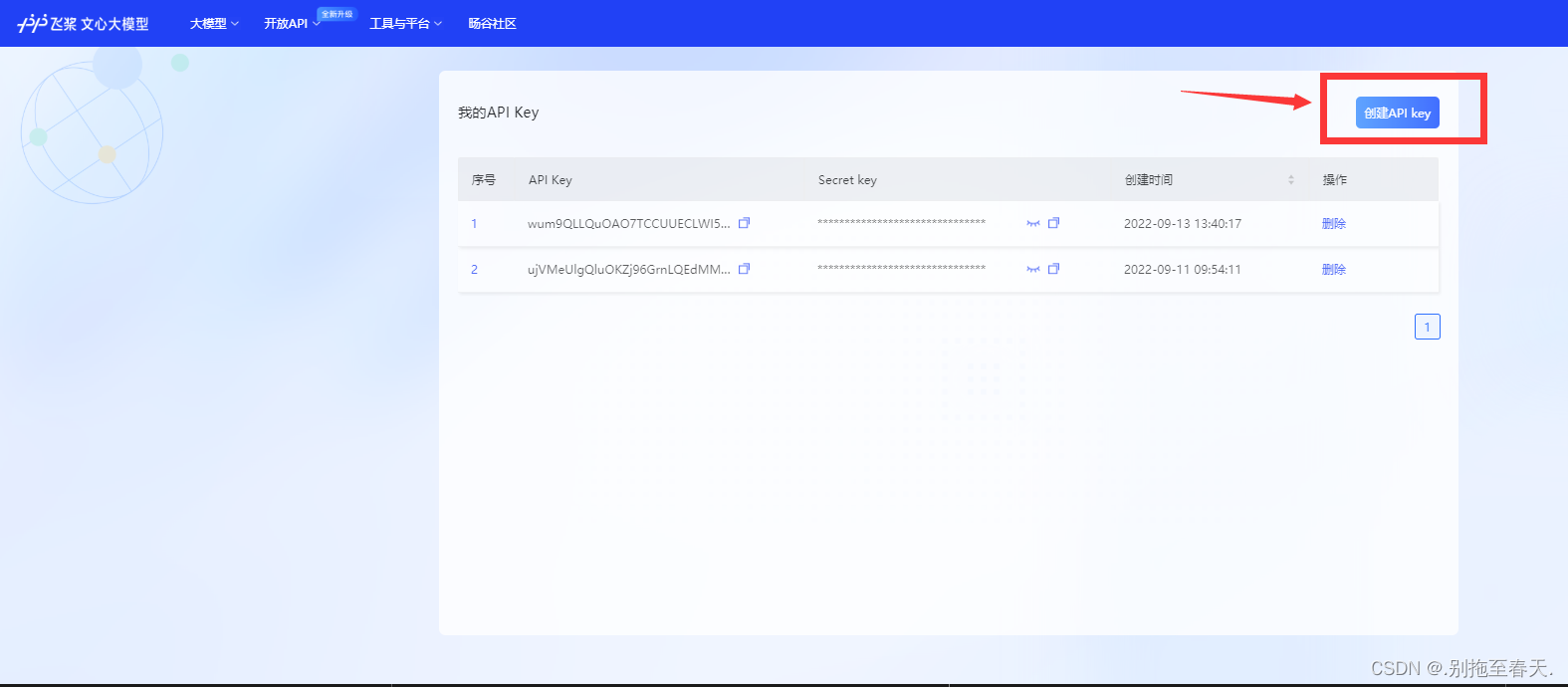
打开链接:https://wenxin.baidu.com/moduleApi/key
可能需要登陆,登陆之后在该界面点击创建API,然后就会生成下方显示的API Key
2.3 软件使用
其实看文章最开始放的体验视频就能完全了解使用过程
将之前获取的API Key和Select Key分别输入并点击上传:
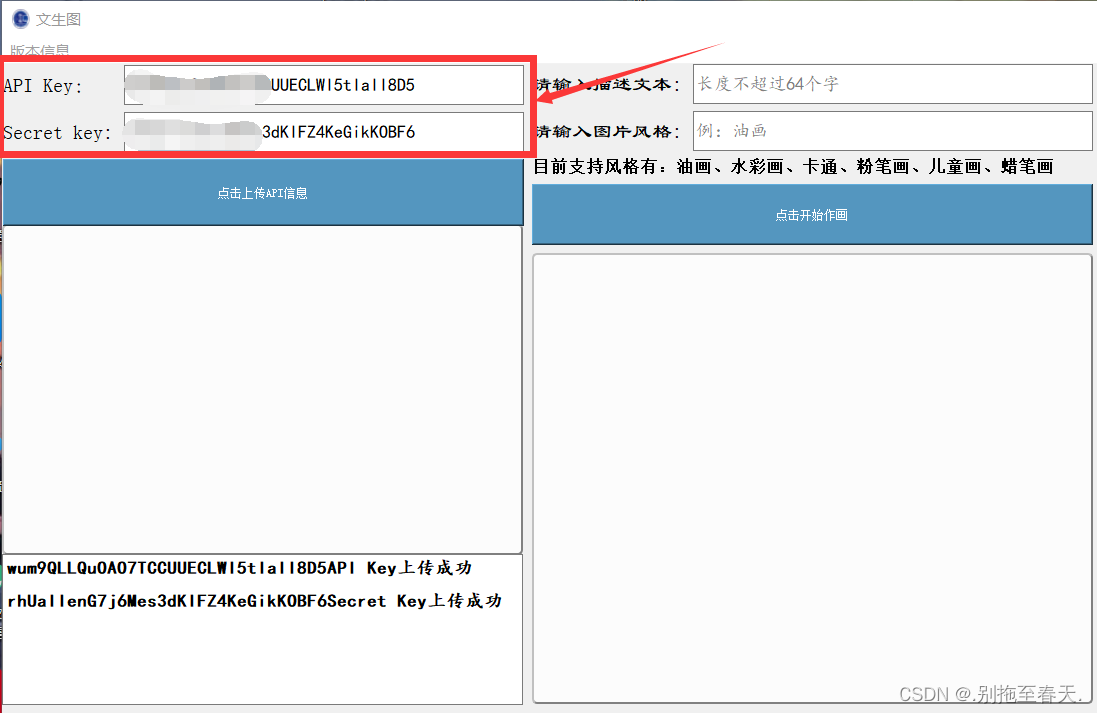
上传成功后下方会有提示,之后再输入描述文本,选择图片风格输入,点击开始作画后等待大约60秒左右,就可以点击查看图片了

2.4 源码链接
https://gitee.com/zhgn2020814/ernie-vi-lge.git


