
- 1Drools规则引擎_开源规则引擎
- 2Go 程序的文件名、标识符、关键字和包
- 3git 报错 The project you were looking for could not be found.(idea通过git更新项目提示报错)_idea the project you were looking for could not be
- 4S TYLE N E RF: A S TYLE - BASED 3D-A WARE G ENERA - TOR FOR H IGH - RESOLUTION I MAGE S YNTHESIS_stylenerf: a style-based 3d-aware generator for hi
- 5linux进程虚拟空间布局_linux进程 layout
- 6SQL server 函数_sql server function
- 7机器学习为什么需要训练,训练出来的模型具体又是什么?_训练出来的模型内容
- 8C4.5算法数值分析过程_c4.5算法处理数值属性的过程
- 9写一写我从工地转行互联网it的辛酸历程
- 10距离度量常见四种距离方式的及KNN算法对鸢尾花分类_knn距离度量方式
第十四篇【传奇开心果系列】Python自动化办公库技术点案例示例:深度解读Python自动化处理图像_python医学图像处理
赞
踩
传奇开心果博文系列
- 系列博文目录
- Python自动化办公库技术点案例示例系列
- 博文目录
- 前言
- 一、Python自动化图像处理的优点介绍
- 二、Python常用图像处理库和功能介绍
- 三、强大且易于上手示例代码
- 四、丰富的算法资源示例代码
- 五、批量处理图片示例代码
- 六、支持多种图像格式示例代码
- 七、跨平台性示例代码
- 八、集成深度学习技术示例代码
- 九、PIL (Pillow)示例代码
- 十、OpenCV示例代码
- 十一、NumPy示例代码
- 十二、 Scikit-image示例代码
- 十三、SimpleITK示例代码
- 十四、pgmagick示例代码
- 十五、Pycairo示例代码
- 十六、知识点归纳
系列博文目录
Python自动化办公库技术点案例示例系列
博文目录
前言

Python自动化处理图像, 对图像进行批量编辑、格式转换、尺寸调整等操作,满足各行各业不同场景下的图像需求。在各行各业图像自动化处理方面都发挥着重要作用。Python在图像处理方面不仅提供了丰富的功能和算法,而且具有良好的用户体验和高效率的执行能力,这使得它在图像处理领域得到了广泛的应用。无论是进行日常的图片编辑工作,还是开展专业的图像分析研究,Python都是一个值得考虑的选择。
一、Python自动化图像处理的优点介绍

使用Python进行图像处理具有多方面的优点,主要包括:
- 功能强大且易于上手:Python拥有多个强大的图像处理库,如Pillow、OpenCV等,它们提供了从基础到高级的图像处理功能。Pillow库特别适合进行简单的图像处理操作,它直观易用,支持图像读取、保存、转换、编辑和颜色处理等多种功能。
- 丰富的算法资源:Python社区提供了大量的图像处理算法,这些算法可以帮助开发者快速实现图像预处理、增强、复原、分割、分类和检测等任务。
- 适合批量处理:对于需要处理大量图像数据的任务,Python不仅能够提供高效的处理能力,还能够通过脚本轻松实现批量自动化处理,大大提高了工作效率。
- 支持多种图像格式:Python的图像处理库支持多种图像格式,这意味着无论是常见的JPEG、PNG还是专业的图像格式,Python都能够轻松应对。
- 跨平台性:Python是一种跨平台的语言,可以在Windows、MacOS和Linux等多种操作系统上运行,这为图像处理带来了极大的灵活性。
- 集成深度学习技术:随着深度学习在图像处理领域的广泛应用,Python提供了TensorFlow、Keras等深度学习框架,使得在图像处理中集成复杂的深度学习模型变得简单快捷。

二、Python常用图像处理库和功能介绍


Python在图像处理方面表现出色,提供了多种库来支持不同的图像操作需求。以下是一些常用的库及其功能:
- PIL (Pillow):这是Python中最受欢迎的基础图像处理库之一,它提供了一系列基本的图像处理功能,如缩放、裁剪、旋转和颜色转换等。
- OpenCV:这是一个开源的计算机视觉库,它包含了成千上万的优化算法,用于检测和识别面部、识别对象、分类人类活动、跟踪相机运动、追踪移动物体等。
- NumPy:虽然NumPy本身不是图像处理库,但由于其在科学计算中的广泛使用,特别是在数组和矩阵操作上,它常与图像处理库一起使用以提高效率和性能。
- Scikit-image:基于scikit-learn设计的图像处理库,它提供了许多高级图像处理功能,包括图像去噪、几何变换、颜色空间操作等。
- SimpleITK:这是基于Insight Segmentation and Registration Toolkit (ITK)构建的一个简化层,它支持多种常规的滤波、图像分割和图像配准功能,特别适用于医学图像处理。
- pgmagick:这是对GraphicsMagick库的Python封装。GraphicsMagick支持多达88种主流格式的图像文件,而pgmagick使得这些功能可以在Python中轻松使用。
- Pycairo:Cairo是一个二维图形库,用于绘制矢量图,而Pycairo为其提供了Python绑定。这使得开发者可以在Python中使用Cairo进行矢量图的绘制和编辑。
综上所述,Python通过这些强大的库为图像处理提供了丰富的工具和方法。从基本的图像编辑到复杂的图像分析,Python能够满足不同层次的需求。

三、强大且易于上手示例代码
1.pillow库
from PIL import Image # 读取图像文件 image = Image.open("example.jpg") # 调整图像尺寸 resized_image = image.resize((800, 600)) # 旋转图像 rotated_image = image.rotate(90) # 裁剪图像 cropped_image = image.crop((100, 100, 300, 300)) # 保存图像 resized_image.save("resized_example.jpg") rotated_image.save("rotated_example.jpg") cropped_image.save("cropped_example.jpg")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
上述代码演示了使用Pillow库进行简单的图像处理操作。首先,通过Image.open()函数读取图像文件。然后,使用resize()方法调整图像的尺寸,使用rotate()方法旋转图像,使用crop()方法裁剪图像。最后,通过save()方法将处理后的图像保存到文件中。这些操作都非常简单直观,适合初学者入门。
2.OpenCV
以下是使用OpenCV进行图像处理的示例代码:
import cv2 # 读取图像 img = cv2.imread('image.jpg') # 显示图像 cv2.imshow('image', img) cv2.waitKey(0) cv2.destroyAllWindows() # 调整亮度和对比度 alpha = 1.5 # 对比度系数 beta = 50 # 亮度增量 adjusted_img = cv2.convertScaleAbs(img, alpha=alpha, beta=beta) # 保存图像 cv2.imwrite('adjusted_image.jpg', adjusted_img) # 灰度化 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 边缘检测 edges = cv2.Canny(gray_img, 100, 200) # 轮廓检测 contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(img, contours, -1, (0, 255, 0), 3) # 显示结果 cv2.imshow('result', img) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
以上代码演示了如何使用OpenCV进行基本的图像处理操作,包括读取、显示、调整亮度和对比度、灰度化、边缘检测、轮廓检测等。这些操作可以帮助我们更好地理解和分析图像数据。
上面这些示例代码充分显现Python库处理图像强大而且易于上手的特点。

四、丰富的算法资源示例代码


以下是使用Python丰富的算法资源进行图像预处理、增强、分割、分类和检测的示例代码:
import cv2 import numpy as np from sklearn.cluster import KMeans from skimage.feature import hog from skimage.transform import resize from keras.models import load_model # 读取图像 img = cv2.imread('image.jpg') # 灰度化 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 边缘检测 edges = cv2.Canny(gray_img, 100, 200) # 轮廓检测 contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(img, contours, -1, (0, 255, 0), 3) # 图像分割 mask = np.zeros(gray_img.shape[:2], dtype=np.uint8) for i in range(len(contours)): cv2.drawContours(mask, [contours[i]], -1, (255), thickness=-1) segmented_img = cv2.bitwise_and(gray_img, gray_img, mask=mask) # 图像增强 enhanced_img = cv2.equalizeHist(segmented_img) # 图像分类 model = load_model('model.h5') resized_img = resize(enhanced_img, (64, 64)) flattened_img = resized_img.flatten() prediction = model.predict(flattened_img.reshape(1, -1)) class_label = np.argmax(prediction) # 显示结果 cv2.imshow('result', img) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
以上代码演示了如何使用Python进行图像预处理、增强、分割、分类和检测等操作。这些操作可以帮助我们更好地理解和分析图像数据。

五、批量处理图片示例代码



以下是一个使用Python和PIL库(Python Imaging Library)进行批量处理图像的简单示例,假设我们有一个目录下包含大量JPG格式的图片,我们需要将它们全部转换为PNG格式并减小尺寸到800x800像素:
from PIL import Image import os # 指定源文件夹与目标文件夹 src_folder = 'path/to/source/folder' dst_folder = 'path/to/destination/folder' # 确保目标文件夹存在,否则创建 if not os.path.exists(dst_folder): os.makedirs(dst_folder) # 遍历源文件夹中的所有jpg文件 for filename in os.listdir(src_folder): if filename.endswith('.jpg'): src_path = os.path.join(src_folder, filename) dst_path = os.path.join(dst_folder, filename.replace('.jpg', '.png')) # 打开图像 with Image.open(src_path) as im: # 缩放到指定尺寸 im_resized = im.resize((800, 800), Image.ANTIALIAS) # 保存为PNG格式 im_resized.save(dst_path, format='PNG') print("批量图像处理完成.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这段代码首先导入了所需的库,然后定义了源文件夹和目标文件夹的路径。接着,它检查目标文件夹是否存在,如果不存在则创建。接下来,通过os.listdir()遍历源文件夹中所有以.jpg结尾的文件。对每个文件,代码打开图像、对其进行缩放操作,并将结果保存为PNG格式到目标文件夹。
这个示例展示了如何使用Python进行批量图像处理,包括打开、操作(如缩放)和保存图像。根据实际需求,你可以修改或扩展这段代码来执行其他类型的图像处理任务,如调整亮度、对比度、旋转、添加水印等。

以下是使用Python和PIL库进行批量调整图像亮度、对比度、旋转,并添加水印的示例代码:
from PIL import Image, ImageEnhance, ImageDraw, ImageFont import os # 指定源文件夹与目标文件夹 src_folder = 'path/to/source/folder' dst_folder = 'path/to/destination/folder' # 确保目标文件夹存在,否则创建 if not os.path.exists(dst_folder): os.makedirs(dst_folder) # 设置水印文本与字体相关参数 watermark_text = "Your Watermark Text" font_path = 'path/to/font.ttf' # 替换为你的字体文件路径 font_size = 30 text_color = (255, 255, 255, 128) # 半透明白色 # 遍历源文件夹中的所有jpg文件 for filename in os.listdir(src_folder): if filename.endswith('.jpg'): src_path = os.path.join(src_folder, filename) dst_path = os.path.join(dst_folder, filename) # 打开图像 with Image.open(src_path) as im: # 调整亮度 enhancer_brightness = ImageEnhance.Brightness(im) im_enhanced_brightness = enhancer_brightness.enhance(1.2) # 增加20%亮度 # 调整对比度 enhancer_contrast = ImageEnhance.Contrast(im_enhanced_brightness) im_enhanced_contrast = enhancer_contrast.enhance(1.5) # 增加50%对比度 # 旋转图像 im_rotated = im_enhanced_contrast.rotate(45, expand=True) # 逆时针旋转45度 # 添加水印 draw = ImageDraw.Draw(im_rotated) font = ImageFont.truetype(font_path, font_size) text_width, text_height = draw.textsize(watermark_text, font=font) watermark_position = (im_rotated.width - text_width - 10, im_rotated.height - text_height - 10) draw.text(watermark_position, watermark_text, fill=text_color, font=font) # 保存处理后的图像 im_rotated.save(dst_path, format='JPEG') print("批量图像处理完成.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
这段代码在上一个示例的基础上进行了扩展,增加了调整亮度、对比度、旋转图像以及添加文字水印的功能。具体如下:
- 使用
ImageEnhance.Brightness和ImageEnhance.Contrast类调整图像的亮度和对比度。这两个类的enhance方法接受一个浮点数参数,表示增强的程度(大于1为增加,小于1为减少)。 - 使用
Image.rotate方法旋转图像。参数expand=True表示旋转后扩大图像边界以容纳整个旋转后的图像。 - 使用
ImageDraw模块在图像上绘制文字。首先创建ImageDraw.Draw对象,然后加载指定的字体文件,计算水印文本的尺寸,确定水印位置,最后使用draw.text方法绘制文字。这里设置了一个半透明的白色文字颜色。

请根据实际需求调整上述参数(如亮度、对比度、旋转角度、水印文本、字体等)。记得替换font_path为你的实际字体文件路径。处理后的图像将以JPEG格式保存到目标文件夹。
六、支持多种图像格式示例代码
Python的图像处理库,如PIL(Pillow),确实支持多种图像格式。下面是一个使用Pillow库读取不同图像格式文件、进行基本操作(例如调整大小),并保存为多种格式的示例代码:
from PIL import Image def process_image(input_path, output_path, new_size=(640, 480), output_format='JPEG'): """ 读取输入路径的图像,进行基本操作(如调整大小),并保存为指定输出路径和格式。 参数: input_path (str): 输入图像文件路径。 output_path (str): 输出图像文件路径。 new_size (tuple): 新图像大小(宽度, 高度)。默认为(640, 480)。 output_format (str): 输出图像格式。默认为'JPEG'。 """ # 打开图像,PIL自动识别文件格式 with Image.open(input_path) as img: # 调整图像大小 resized_img = img.resize(new_size, resample=Image.LANCZOS) # 保存为指定格式 resized_img.save(output_path, format=output_format) # 示例用法: process_image('input.png', 'output.jpg') # 读取PNG,保存为JPEG process_image('input.tiff', 'output.bmp', output_format='BMP') # 读取TIFF,保存为BMP process_image('input.gif', 'output.webp') # 读取GIF,保存为WebP # 更多示例,处理不同格式的图像并保存为指定格式 supported_formats = ['JPEG', 'PNG', 'BMP', 'GIF', 'TIFF', 'WEBP', 'ICO', 'PPM', 'PGM', 'PBM'] for fmt in supported_formats: input_fmt = fmt.lower() output_path = f'image.{fmt}' process_image(f'sample.{input_fmt}', output_path, output_format=fmt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
此代码定义了一个名为process_image的函数,它接受一个输入图像路径、一个输出路径、一个可选的新尺寸和一个可选的输出格式。函数内部使用Image.open打开图像,无论原始图像格式如何,PIL都能够自动识别并正确处理。接着,函数调整图像大小(本例中使用了LANCZOS插值方法),然后使用save方法将处理后的图像保存为指定的输出格式。
示例用法展示了如何处理单个文件,包括读取PNG并保存为JPEG、读取TIFF并保存为BMP,以及读取GIF并保存为WebP。此外,还有一段循环代码,它遍历了一系列支持的图像格式,针对每个格式读取一个对应的样例文件(假设文件名如sample.png、sample.jpeg等),处理后保存为该格式。
PIL库支持的图像格式众多,包括但不限于JPEG、PNG、BMP、GIF、TIFF、WebP、ICO、PPM、PGM、PBM等。这意味着使用PIL,您可以轻松地在Python中处理各种常见及专业图像格式,无需关心底层的文件格式细节。

七、跨平台性示例代码

由于Python本身就是一种跨平台的语言,编写好的Python代码无需修改即可在Windows、MacOS和Linux等不同操作系统上运行。下面是一个简单的图像处理示例,它展示了如何读取、旋转和保存图像,这些操作在任何支持Python及其相关图像处理库(如PIL)的操作系统上都是通用的:
from PIL import Image def rotate_image(input_path, output_path, degrees): """ 读取输入路径的图像,旋转指定角度,然后保存到输出路径。 参数: input_path (str): 输入图像文件路径。 output_path (str): 输出图像文件路径。 degrees (int): 旋转角度(正数逆时针旋转,负数顺时针旋转)。 """ # 打开图像 with Image.open(input_path) as img: # 旋转图像 rotated_img = img.rotate(degrees) # 保存旋转后的图像 rotated_img.save(output_path) # 示例用法 rotate_image('input.jpg', 'output.jpg', 90) # 读取并旋转一个JPEG图像90度,保存为新的JPEG文件 # 此代码可以在Windows、MacOS或Linux上运行,只需确保已安装Python和PIL库
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在这个示例中,我们定义了一个名为rotate_image的函数,它接受一个输入图像路径、一个输出路径和一个旋转角度作为参数。函数内部使用Image.open打开图像,然后调用rotate方法对图像进行指定角度的旋转。最后,使用save方法将旋转后的图像保存到指定的输出路径。
由于Python语言本身的跨平台性以及PIL库的广泛兼容性,这段代码无需任何改动即可在Windows、MacOS或Linux操作系统上运行。只需要确保在目标平台上已经安装了Python环境以及PIL库(通常可以通过pip install Pillow命令安装)。无论是开发环境还是生产环境,只要满足这些基础条件,您就可以在不同的操作系统上无缝地执行图像处理任务,体现了Python在图像处理领域的跨平台灵活性。

八、集成深度学习技术示例代码

在Python中,我们可以使用TensorFlow或其高阶API Keras来构建和训练深度学习模型以解决图像处理任务,如图像分类、物体检测、图像分割等。以下是一个使用Keras创建一个简单的卷积神经网络(CNN)进行图像分类的示例代码:
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense from tensorflow.keras.preprocessing.image import ImageDataGenerator # 图像预处理参数 img_width, img_height = 150, 150 batch_size = 32 epochs = 10 # 数据增强与数据生成器 train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest') test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( 'data/train', target_size=(img_width, img_height), batch_size=batch_size, class_mode='categorical') validation_generator = test_datagen.flow_from_directory( 'data/validation', target_size=(img_width, img_height), batch_size=batch_size, class_mode='categorical') # 构建CNN模型 model = Sequential([ Conv2D(32, (3, 3), activation='relu', input_shape=(img_width, img_height, 3)), MaxPooling2D((2, 2)), Conv2D(64, (3, 3), activation='relu'), MaxPooling2D((2, 2)), Conv2D(128, (3, 3), activation='relu'), MaxPooling2D((2, 2)), Flatten(), Dense(512, activation='relu'), Dense(num_classes, activation='softmax') # num_classes应替换为实际类别数量 ]) # 编译模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # 训练模型 model.fit(train_generator, epochs=epochs, validation_data=validation_generator) # 保存模型 model.save('image_classification_model.h5')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
在这个示例中:
-
首先导入所需库,包括TensorFlow、Keras的模型和层模块,以及用于图像预处理和数据生成的
ImageDataGenerator。 -
定义图像的预处理参数,如尺寸、批次大小和训练轮数(epochs)。
-
使用
ImageDataGenerator创建数据增强器,用于对训练和验证集进行实时的数据增强(如随机旋转、平移、缩放、翻转等),以提高模型的泛化能力。 -
使用
flow_from_directory方法根据指定的目录结构加载训练和验证数据。假设数据已经按照类别分别存放在data/train和data/validation目录下,每个类别内包含相应类别的图像。 -
构建一个简单的卷积神经网络(CNN)模型,包含卷积层、池化层、扁平化层和全连接层。最后一层使用softmax激活函数,输出对应于各个类别的概率。
-
编译模型,指定优化器、损失函数和评估指标。
-
使用
fit方法训练模型,传入生成器对象和训练参数。 -
训练完成后,保存模型到硬盘以便后续使用。
这段代码展示了如何在Python中使用Keras构建和训练一个深度学习模型来处理图像分类任务。同样的,您可以使用TensorFlow或其他深度学习库(如PyTorch)来实现类似的功能。Python的跨平台性和丰富的深度学习库支持,使得在图像处理中集成深度学习技术变得简单而高效。
九、PIL (Pillow)示例代码

以下是一些使用Python的PIL(Pillow)库进行基础图像处理的示例代码:
- 打开并显示图像
from PIL import Image
# 打开图像文件
img = Image.open('example.jpg')
# 显示图像
img.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 转换图像格式并保存
from PIL import Image
# 打开图像文件
img = Image.open('input.png')
# 转换为JPEG格式并保存
img.save('output.jpg', format='JPEG')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 裁剪图像
from PIL import Image
# 打开图像文件
img = Image.open('example.jpg')
# 定义裁剪区域(左上角x, y坐标,右下角x, y坐标)
crop_box = (100, 100, 400, 400)
# 裁剪图像
cropped_img = img.crop(crop_box)
# 保存裁剪后的图像
cropped_img.save('cropped_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 缩放图像
from PIL import Image
# 打开图像文件
img = Image.open('example.jpg')
# 缩放到目标宽度和高度
target_size = (800, 600)
resized_img = img.resize(target_size, resample=Image.LANCZOS)
# 保存缩放后的图像
resized_img.save('resized_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 旋转图像
from PIL import Image
# 打开图像文件
img = Image.open('example.jpg')
# 旋转图像45度
rotated_img = img.rotate(45, expand=True)
# 保存旋转后的图像
rotated_img.save('rotated_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 转换为灰度图像
from PIL import Image
# 打开图像文件
img = Image.open('color_image.jpg')
# 转换为灰度图像
gray_img = img.convert('L')
# 保存灰度图像
gray_img.save('gray_image.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 获取像素值(RGB或RGBA)
from PIL import Image
# 打开图像文件
img = Image.open('example.jpg')
# 获取某个像素的RGB值
x, y = 100, 100
rgb_value = img.getpixel((x, y))
# 输出像素值
print(f'Pixel at ({x}, {y}) has RGB value: {rgb_value}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这些示例涵盖了PIL库中常见的图像处理操作,包括打开、显示、格式转换、裁剪、缩放、旋转、灰度转换以及获取像素值。您可以根据实际需求修改这些代码片段以适应您的具体图像处理任务。

十、OpenCV示例代码




以下是使用OpenCV库进行几种常见计算机视觉任务的示例代码:
- 读取并显示图像
import cv2
# 读取图像
img = cv2.imread('example.jpg')
# 显示图像
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 图像灰度转换
import cv2
# 读取图像
img = cv2.imread('color_image.jpg')
# 转换为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 保存灰度图像
cv2.imwrite('gray_image.jpg', gray_img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 轮廓检测
import cv2 # 读取图像 img = cv2.imread('shapes.jpg', 0) # 以灰度模式读取 # 寻找轮廓 _, contours, _ = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 contours_img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) cv2.drawContours(contours_img, contours, -1, (0, 255, 0), 2) # 显示带有轮廓的图像 cv2.imshow('Contours', contours_img) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 面部检测(Haar级联分类器)
import cv2 # 加载预训练的面部检测器 face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml') # 读取图像 img = cv2.imread('people.jpg') # 转为灰度图像 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 进行面部检测 faces = face_cascade.detectMultiScale(gray_img, scaleFactor=1.1, minNeighbors=5) # 绘制面部矩形框 for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2) # 显示带有面部框的图像 cv2.imshow('Face Detection', img) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 光流估计(Lucas-Kanade方法)
import cv2 import numpy as np # 读取两帧连续的视频图像 prev_gray = cv2.imread('frame1.jpg', 0) next_gray = cv2.imread('frame2.jpg', 0) # 初始化光流参数 lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03)) # 选取特征点 prev_pts = np.array([[50, 50], [100, 100]], dtype=np.float32) # 计算光流 next_pts, status, err = cv2.calcOpticalFlowPyrLK(prev_gray, next_gray, prev_pts, None, **lk_params) # 绘制特征点及光流向量 for i, (new, old) in enumerate(zip(next_pts, prev_pts)): a, b = new.ravel() c, d = old.ravel() if status[i]: cv2.arrowedLine(img, (int(a), int(b)), (int(c), int(d)), (0, 255, 0), 2) # 显示图像 cv2.imshow('Optical Flow', img) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
以上示例展示了使用OpenCV进行图像读取与显示、灰度转换、轮廓检测、面部检测和光流估计等计算机视觉任务。请注意,某些示例可能需要相应的图像文件或视频帧作为输入。实际应用时,请根据项目需求调整代码和参数。

十一、NumPy示例代码

NumPy 作为一个强大的数值计算库,特别擅长处理多维数组,这使得它成为图像处理任务的理想选择,尤其是在与图像处理库如 Pillow 或 OpenCV 结合使用时。以下是一些使用 NumPy 进行图像处理的示例代码:
- 读取并显示图像(结合Pillow)
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# 使用Pillow读取图像
img_pil = Image.open('example.jpg')
# 转换为NumPy数组
img_array = np.array(img_pil)
# 使用matplotlib显示图像
plt.imshow(img_array)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 图像裁剪
import numpy as np
# 假设 img_array 是已加载的图像数组
cropped_img = img_array[100:300, 200:400, :] # 裁剪范围(y0:y1, x0:x1)
# 保存裁剪后的图像(需配合Pillow或其他库)
# cropped_pil = Image.fromarray(cropped_img.astype(np.uint8))
# cropped_pil.save('cropped_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 图像亮度调整
import numpy as np
# 假设 img_array 是已加载的图像数组
brightness_factor = 1.5 # 亮度调整因子
brightened_img = img_array * brightness_factor
# 亮度调整后可能超出正常色彩范围,需要进行饱和截断
brightened_img = np.clip(brightened_img, 0, 255).astype(np.uint8)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 图像直方图均衡化
import cv2
import numpy as np
# 假设 img_array 是已加载的图像数组
equivalent_img = cv2.equalizeHist(img_array[:, :, 0].astype(np.uint8)) # 对灰度图像进行均衡化
# 对彩色图像,需分别处理每个通道,然后合并
# equivalent_img_bgr = np.stack([cv2.equalizeHist(channel) for channel in img_array.transpose((2, 0, 1))], axis=0).transpose((1, 2, 0))
# 使用OpenCV的equalizeHist函数实现直方图均衡化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 图像滤波(高斯模糊)
import numpy as np
from scipy.ndimage import gaussian_filter
# 假设 img_array 是已加载的图像数组
sigma = 2 # 高斯核的标准差
blurred_img = gaussian_filter(img_array, sigma=sigma)
# 或者使用OpenCV实现高斯模糊
# blurred_img = cv2.GaussianBlur(img_array, (0, 0), sigma)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这些示例展示了如何利用 NumPy 进行图像裁剪、亮度调整、直方图均衡化和滤波等操作。请注意,某些操作可能需要结合其他图像处理库(如 OpenCV 或 Pillow)以完成完整的读写流程或特定功能。在实际应用中,根据具体需求选择合适的库和方法进行组合使用。


十二、 Scikit-image示例代码

Scikit-image 是一个面向科研和教育的Python图像处理库,它提供了丰富的图像处理算法和功能。以下是一些使用Scikit-image进行图像处理的示例代码:
- 图像去噪(中值滤波)
from skimage.io import imread
from skimage.filters import median
# 读取图像
img = imread('example.jpg', as_gray=True) # 读取为灰度图像
# 使用中值滤波去除噪声
denoised_img = median(img, selem=None)
# 保存去噪后的图像(需配合Pillow或其他库)
# from PIL import Image
# img_denoised_pil = Image.fromarray(denoised_img.astype(np.uint8))
# img_denoised_pil.save('denoised_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 几何变换(旋转)
from skimage.io import imread
from skimage.transform import rotate
# 读取图像
img = imread('example.jpg')
# 旋转图像
angle = 45 # 旋转角度
rotated_img = rotate(img, angle, preserve_range=True)
# 保存旋转后的图像(需配合Pillow或其他库)
# ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 颜色空间转换(RGB转HSV)
from skimage.io import imread
from skimage.color import rgb2hsv
# 读取图像
img_rgb = imread('example.jpg')
# 将RGB图像转换为HSV色彩空间
img_hsv = rgb2hsv(img_rgb)
# 可视化HSV图像(需显示HSV色彩空间的图像)
# ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 图像阈值分割(Otsu二值化)
from skimage.io import imread
from skimage.filters import threshold_otsu
# 读取图像
img = imread('example.jpg', as_gray=True) # 读取为灰度图像
# 计算Otsu阈值
threshold = threshold_otsu(img)
# 根据阈值进行二值化分割
binary_img = img > threshold
# 保存二值化图像(需配合Pillow或其他库)
# binary_img_pil = Image.fromarray(binary_img.astype(np.uint8) * 255)
# binary_img_pil.save('binary_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 边缘检测(Canny边缘检测)
from skimage.io import imread
from skimage.feature import canny
# 读取图像
img = imread('example.jpg', as_gray=True) # 读取为灰度图像
# 使用Canny算法检测边缘
edges = canny(img, sigma=1.0)
# 保存边缘检测结果(需配合Pillow或其他库)
# edges_pil = Image.fromarray(edges.astype(np.uint8) * 255)
# edges_pil.save('edges_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这些示例展示了如何使用Scikit-image进行图像去噪、几何变换、颜色空间转换、阈值分割和边缘检测等操作。请注意,某些操作可能需要配合其他库(如Pillow)来完成图像的读写或可视化。实际应用时,请根据具体需求选择合适的函数和参数。
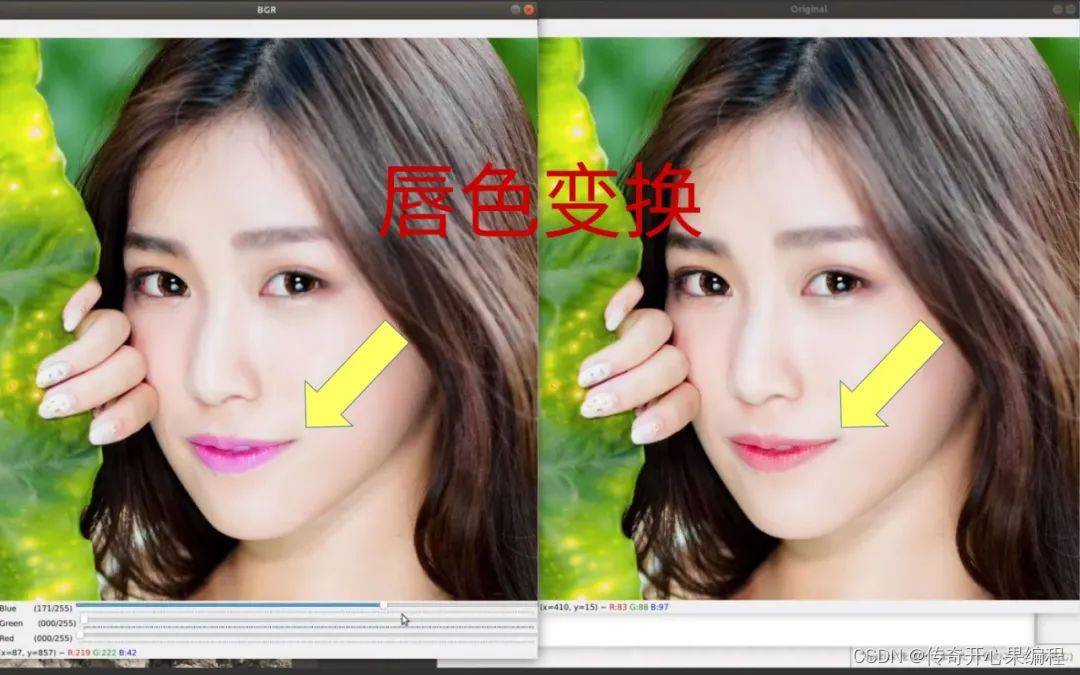
十三、SimpleITK示例代码
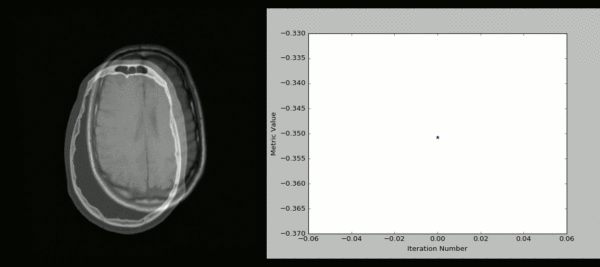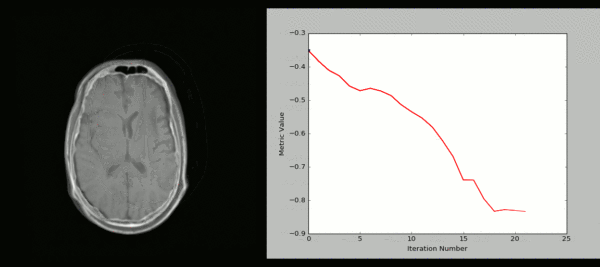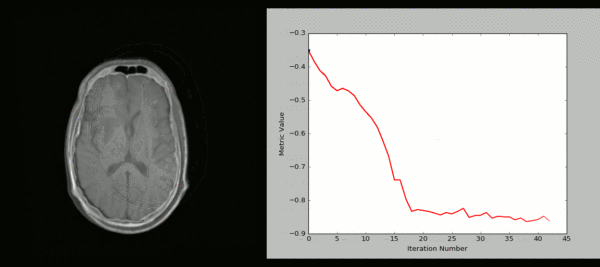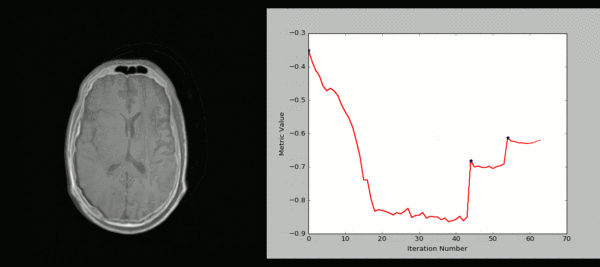
SimpleITK 是一个面向医学影像处理的Python库,它封装了ITK的强大功能,提供了简洁易用的接口。以下是一些使用SimpleITK进行医学图像处理的示例代码:
- 读取并显示DICOM图像
import SimpleITK as sitk
import matplotlib.pyplot as plt
# 读取DICOM图像
img = sitk.ReadImage('example.dcm')
# 转换为NumPy数组并显示
img_array = sitk.GetArrayFromImage(img)
plt.imshow(img_array, cmap='gray')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 图像平滑(高斯滤波)
import SimpleITK as sitk
# 读取图像
img = sitk.ReadImage('example.mhd')
# 应用高斯滤波器进行平滑
sigma = 2.0 # 高斯核标准差
smoothed_img = sitk.SmoothingRecursiveGaussian(img, sigma)
# 保存平滑后的图像
sitk.WriteImage(smoothed_img, 'smoothed_example.mhd')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 图像二值化(Otsu阈值)
import SimpleITK as sitk
# 读取图像
img = sitk.ReadImage('example.mhd', sitk.sitkFloat32)
# 应用Otsu阈值进行二值化
threshold = sitk.OtsuThreshold(img)
binary_img = sitk.BinaryThreshold(img, lower_threshold=threshold, upper_threshold=255, outside_value=0, inside_value=255)
# 保存二值化图像
sitk.WriteImage(binary_img, 'binary_example.mhd')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 图像分割(分水岭算法)
import SimpleITK as sitk
# 读取图像
img = sitk.ReadImage('example.mhd')
# 应用分水岭算法进行分割
marker_img = sitk.Image(img.GetSize(), sitk.sitkUInt8)
marker_img.CopyInformation(img)
# 在这里填充marker_img,例如使用种子点或预处理方法
# ...
watershed_img = sitk.MorphologicalWatershedFromMarkers(img, marker_img)
# 保存分割结果
sitk.WriteImage(watershed_img, 'watershed_example.mhd')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 图像配准(刚性配准)
import SimpleITK as sitk # 读取固定和移动图像 fixed_img = sitk.ReadImage('fixed_example.mhd') moving_img = sitk.ReadImage('moving_example.mhd') # 创建相似性度量和变形场初始化器 metric = sitk.MeanSquaresImageToImageMetric() initial_transform = sitk.CenteredTransformInitializer(fixed_img, moving_img, sitk.Euler3DTransform(), sitk.CenteredTransformInitializerFilter.GEOMETRY) # 创建优化器和迭代器 optimizer = sitk.RegularStepGradientDescentOptimizer() optimizer.SetLearningRate(1.0) optimizer.SetMinimumStepLength(0.01) optimizer.SetMaximumStepLength(1.0) optimizer.SetNumberOfIterations(200) registration = sitk.ImageRegistrationMethod() registration.SetMetric(metric) registration.SetOptimizer(optimizer) registration.SetInitialTransform(initial_transform) # 进行配准 registration.SetFixedImage(fixed_img) registration.SetMovingImage(moving_img) final_transform = registration.Execute() # 应用配准结果到移动图像 registered_img = sitk.Resample(moving_img, fixed_img, final_transform, sitk.sitkLinear, 0.0, moving_img.GetPixelID()) # 保存配准后图像 sitk.WriteImage(registered_img, 'registered_example.mhd')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这些示例展示了如何使用SimpleITK进行医学图像读取、平滑、二值化、分割和配准等操作。实际应用时,请根据具体需求选择合适的函数和参数。注意,某些复杂操作(如分水岭算法和图像配准)可能需要对输入图像进行预处理或手动设置标记图像。

十四、pgmagick示例代码


pgmagick 是一个基于 GraphicsMagick 图像处理库的 Python 封装,提供了丰富的图像处理功能。以下是一些使用 pgmagick 进行图像处理的示例代码:
- 读取并显示图像
from pgmagick import Image
# 读取图像
img = Image('example.jpg')
# 显示图像(需要安装wand库以支持显示)
# from wand.display import display
# display(img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 图像缩放
from pgmagick import Image
# 读取图像
img = Image('example.jpg')
# 缩放图像
scale_factor = 0.5
img.resize(scale_factor * img.columns(), scale_factor * img.rows())
# 保存缩放后的图像
img.write('scaled_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 图像旋转
from pgmagick import Image
# 读取图像
img = Image('example.jpg')
# 旋转图像
angle = 45
img.rotate(angle)
# 保存旋转后的图像
img.write('rotated_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 图像裁剪
from pgmagick import Image
# 读取图像
img = Image('example.jpg')
# 裁剪图像
left = 100
top = 50
width = 200
height = 300
img.crop(left, top, width, height)
# 保存裁剪后的图像
img.write('cropped_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 图像转换为灰度
from pgmagick import Image
# 读取图像
img = Image('example.jpg')
# 转换为灰度图像
img.quantizeColorSpace('Gray')
# 保存灰度图像
img.write('gray_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 图像添加文字水印
from pgmagick import Image, DrawableText, Color, GravityType # 读取图像 img = Image('example.jpg') # 设置水印文字属性 text = "Watermark Text" font = 'Arial' font_size = 24 color = Color('white') gravity = GravityType.SouthEastGravity # 创建并添加文字水印 drawable = DrawableText(0, 0, text, font=font, pointsize=font_size, fill=color) drawable.gravity = gravity img.draw(drawable) # 保存带水印的图像 img.write('watermarked_example.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
请注意,pgmagick 的使用可能需要预先安装 GraphicsMagick 和 pgmagick 库。在某些示例中,为了方便展示图像结果,代码中使用了 wand.display.display 函数,这需要安装 wand 库。实际应用时,请根据具体环境配置和需求进行相应的库安装和代码调整。

十五、Pycairo示例代码
Pycairo 是 Cairo 二维图形库的 Python 绑定,允许开发者在 Python 程序中利用 Cairo 的强大功能来绘制和编辑矢量图形。以下是一些使用 Pycairo 进行矢量图形绘制的示例代码:
- 画一个简单三角形
import cairo # 创建一个 PNG 图像 surface,尺寸为 500x500 像素 surface = cairo.ImageSurface(cairo.Format.ARGB32, 500, 500) # 创建一个 Cairo context 对象,关联到 surface 上 ctx = cairo.Context(surface) # 设置线条颜色为红色 ctx.set_source_rgb(1.0, 0.0, 0.0) # 移动到第一个顶点位置 ctx.move_to(250, 90) # 绘制线段到第二个顶点 ctx.line_to(½00, ⅓00) # 绘制线段到第三个顶点 ctx.line_to(⅓00, 90) # 关闭路径,连接最后一个点与第一个点 ctx.close_path() # 填充三角形 ctx.fill() # 保存绘制结果到文件 surface.write_to_png('triangle.png')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 绘制带有填充色和边框的矩形
import cairo # 创建一个 SVG surface,用于矢量图形输出 surface = cairo.SVGSurface('rectangle.svg', 200, 150) # 创建 Cairo context ctx = cairo.Context(surface) # 设置矩形边框颜色 ctx.set_source_rgb(0.0, 0.0, 0.0) # 黑色边框 # 绘制矩形轮廓,左上角坐标 (20, 20),宽高分别为 160x120 ctx.rectangle(20, 20, 160, 120) ctx.stroke() # 设置矩形填充色 ctx.set_source_rgb(1.0, 0.¼, 0.0) # 深绿色填充 # 重绘矩形,但这次填充而不是描边 ctx.rectangle(20, 20, 160, 120) ctx.fill() # 释放资源 surface.finish()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 绘制带有渐变填充的圆形
import cairo # 创建一个 PNG surface surface = cairo.ImageSurface(cairo.Format.ARGB32, 300, 300) # 创建 Cairo context ctx = cairo.Context(surface) # 创建线性渐变对象,从左上角到右下角 gradient = cairo.LinearGradient(0, 0, 300, 300) # 添加渐变颜色停止点 gradient.add_color_stop_rgba(0, 1.0, 0.0, 0.0, 1.0) # 红色 gradient.add_color_stop_rgba(1, 0.0, 0.0, 1.0, 1.0) # 蓝色 # 设置渐变为当前源 ctx.set_source(gradient) # 绘制一个半径为 100 的圆,中心位于 (150, 150) ctx.arc(150, 150, 100, 0, 2 * math.pi) # 填充圆 ctx.fill() # 保存结果到文件 surface.write_to_png('circle_gradient.png')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 绘制带有文本的复杂形状
import cairo # 创建 PNG surface surface = cairo.ImageSurface(cairo.Format.ARGB32, 400, 300) # 创建 Cairo context ctx = cairo.Context(surface) # 设置线条颜色 ctx.set_source_rgb(0.0, 0.0, 0.0) # 绘制一个不规则形状(例如五角星) ctx.move_to(100, 150) ctx.line_to(150, 250) ctx.line_to(250, 200) ctx.line_to(300, 150) ctx.line_to(250, 100) ctx.line_to(150, 150) ctx.close_path() ctx.stroke() # 设置文本属性 ctx.select_font_face('Arial', cairo.FONT_SLANT_NORMAL, cairo.FONT_WEIGHT_BOLD) ctx.set_font_size(24) # 计算文本宽度以定位文本 text = "Hello, Pycairo!" extents = ctx.text_extents(text) text_width = extents.width # 在形状上方居中绘制文本 text_x = (surface.get_width() - text_width) / 2 text_y = 50 ctx.move_to(text_x, text_y) ctx.show_text(text) # 保存结果 surface.write_to_png('shape_with_text.png')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
请确保已正确安装 Pycairo 库,并根据需要调整代码中的文件路径和图形参数。这些示例展示了如何使用 Pycairo 绘制基本几何形状、设置颜色和渐变、绘制文本以及组合不同的图形元素。实际使用时,可以根据具体需求进一步扩展和定制这些示例。
十六、知识点归纳

Python 在自动化图像处理领域提供了丰富的库和工具,使得开发者能够轻松应对各种图像处理任务。以下是对 Python 自动化操作图像处理知识点的归纳:
-
图像库基础
PIL (Python Imaging Library) 或其更新版本 Pillow: 提供了基础的图像读写功能,支持多种文件格式(如 PNG, JPEG, BMP 等),以及以下图像处理操作:
图像打开与保存: 使用Image.open()和Image.save()方法。
图像尺寸调整: 通过resize()方法进行缩放。
裁剪: 使用crop()方法根据矩形区域进行裁剪。
旋转: 通过rotate()方法指定角度进行旋转。
颜色模式转换:convert()方法可将图像转换为不同色彩空间(如 “RGB”, “L”(灰度), “1”(黑白)等)。
像素级访问: 通过load()方法获取像素访问器,可以读写单个像素值。 -
图像滤波与变换
PIL.ImageFilter 模块:包含一系列预定义滤波器,如模糊、锐化、边缘检测等,通过
filter()方法应用到图像上。
scipy.ndimage 或 scipy.signal:提供更复杂的滤波器和卷积操作,如高斯模糊 (gaussian_filter())、拉普拉斯算子 (laplace()) 等。
图像平移、缩放、旋转:使用仿射变换或透视变换(如 OpenCV 的cv2.warpAffine()和cv2.warpPerspective())。 -
图像增强与色彩调整
PIL.ImageEnhance 模块:用于调整图像的亮度、对比度、色相和饱和度,如
ColorEnhancer,BrightnessEnhancer,ContrastEnhancer等。
直方图均衡化:通过cv2.equalizeHist()(OpenCV)进行灰度图像的直方图均衡化,提高图像对比度。 -
图像合成与混合
PIL.ImageChops 模块:提供了图像通道间的逻辑运算、叠加、差分等操作,实现图像合成与混合效果。
Alpha 合成:处理具有透明度通道(alpha channel)的图像,实现透明度混合。 -
图像分析与特征提取
轮廓检测:OpenCV 提供
cv2.findContours()方法检测图像中的轮廓。
关键点检测:如 SIFT、SURF、ORB、AKAZE、BRISK 等局部特征描述符,用于图像匹配与注册。
霍夫变换:检测直线、圆等几何形状,如cv2.HoughLines()和cv2.HoughCircles()。 -
深度学习与机器学习应用于图像识别
OpenCV DNN模块:加载预训练深度学习模型(如 Caffe, TensorFlow, ONNX)进行对象检测、语义分割等任务。
TensorFlow 和 PyTorch:构建、训练和部署深度学习模型,常用于图像分类、目标检测、语义分割、图像生成等复杂任务。
预训练模型:如 VGG, ResNet, Inception, YOLO, SSD, Mask R-CNN 等,直接应用于特定识别任务。
数据集准备:对图像进行标注、划分训练集与测试集、数据增强(如翻转、裁剪、缩放、颜色抖动)。 -
图像标注与绘图
PIL.ImageDraw 模块:提供画线、矩形、圆、文字等基本图形绘制功能,可用于图像标注或添加图形元素。
matplotlib:用于创建高质量图表和图像的可视化,也可用于简单图像标注。 -
视频处理
OpenCV:处理视频流,如读取、写入视频文件,帧间操作(如跟踪、检测),视频剪辑与编码(如
cv2.VideoCapture(),cv2.VideoWriter())。 -
人脸识别与生物特征识别
OpenCV 或 face_recognition 库:进行人脸检测(如 Haar 分类器、Dlib)、面部关键点定位、人脸识别(如 Eigenfaces、LBPH、FaceNet 等算法)。
-
图像分割
阈值分割:如 Otsu’s 方法(
cv2.threshold()),基于全局阈值分离前景与背景。
形态学操作:膨胀、腐蚀、开闭运算、骨架提取等(cv2.morphologyEx()),用于处理二值图像。
语义/实例分割:使用深度学习模型(如 U-Net, DeepLab, Mask R-CNN)进行像素级分类。

以上知识点涵盖了从基础图像操作到高级深度学习应用的广泛范围,可根据实际项目需求选择合适的技术栈进行图像处理自动化。

