
- 1FISCO BCOS 五、一键部署(及环境配置)_flsco bcos链部署
- 2WPF 中下划线显示不对问题_wpf label下划线
- 32.vector容器_vector中使用swap
- 4UniVue更新日志:使用ObservableList优化LoopList/LoopGrid组件的使用
- 5vscode: make sure you configure your user.name and user.email in git_make sure you configure your "user.name" and "user
- 6MATLAB用改进K-Means(K-均值)聚类算法数据挖掘高校学生的期末考试成绩
- 7在使用jplayer播放器报错The play() request was interrupted by a call to pause().怎么解决_the play() request was interrupted because the med
- 8单例模式-确保对象的唯一性_模式层缺少唯一性
- 9Van-Pull-Refresh 和 Van-List 的使用问题及解决方案
- 10PySpark数据分析基础:Spark本地环境部署搭建_pyspark运行环境部署
人体关键点姿态识别_人体关键点识别
赞
踩
一、技术难点介绍
人体关键点姿态识别是人体姿态识别技术的重要分支。通过检测人体行为表达过程中,每一帧人体姿态关键部位的位置,将人体姿态简化为人体关键点,并通过这些关键点对人体姿态表达的语义进行分类识别。
基于关键点的人体姿态识别可分为两个方面,即静态的人体姿态识别与动态的人体姿态识别,总的来说,人体关键点姿态识别技术主要面临的几方面技术难点如下:
(1) 姿态位移尺度变换
不同相机角度下捕获到的姿态关键点的空间位置、视角方向各不相同
(2) 姿态大小尺度变换
不同行为个体的差异造成相同人体姿态的尺寸大小、表观形状不完全相同。
(3) 关键点噪声与关键点缺失
人体姿态检测的造成的人体骨骼关键点丢失,或者关键点漂移等。
(4) 人体姿态表达的视频区域分割
对运动人体姿态语义视频的有效分割。比如,喝水动作,需要分割出人体从拿起水杯喝水,到喝完水放下水杯的过程。
二、关键技术介绍:
2.1 动态人体关键点姿态识别:
传统机器学习算法中,将人体骨骼关键点看作时间域动态轨迹序列,可通过隐马尔科夫HMM,条件随机场CRFs,时域金字塔等模型求解。对时域骨骼关键点的特征提取方法主要有关键点的联合位置直方图分布,关键点3D位置的旋转与位移特征等等。
在深度学习领域,可通过RNNs、LSTM、CNN等手段将时空域人体姿态关键点建模来完成分类识别。
下图所示为基于3D骨骼点的人体行为姿态检测方法分类:
Joint-based Representations:
基于关键点坐标的行为姿态表达,包括空间描述子(Spatial Descriptors)、几何描述子(Geometrical Descriptors)、关键帧描述子(key-poses Descriptors)。
Mined Joints based Descriptors:
考虑子空间关键点的相关性来提升判别度。
Dynamics based descriptors:
基于动态规划算法来考虑不同视频序列的匹配度。
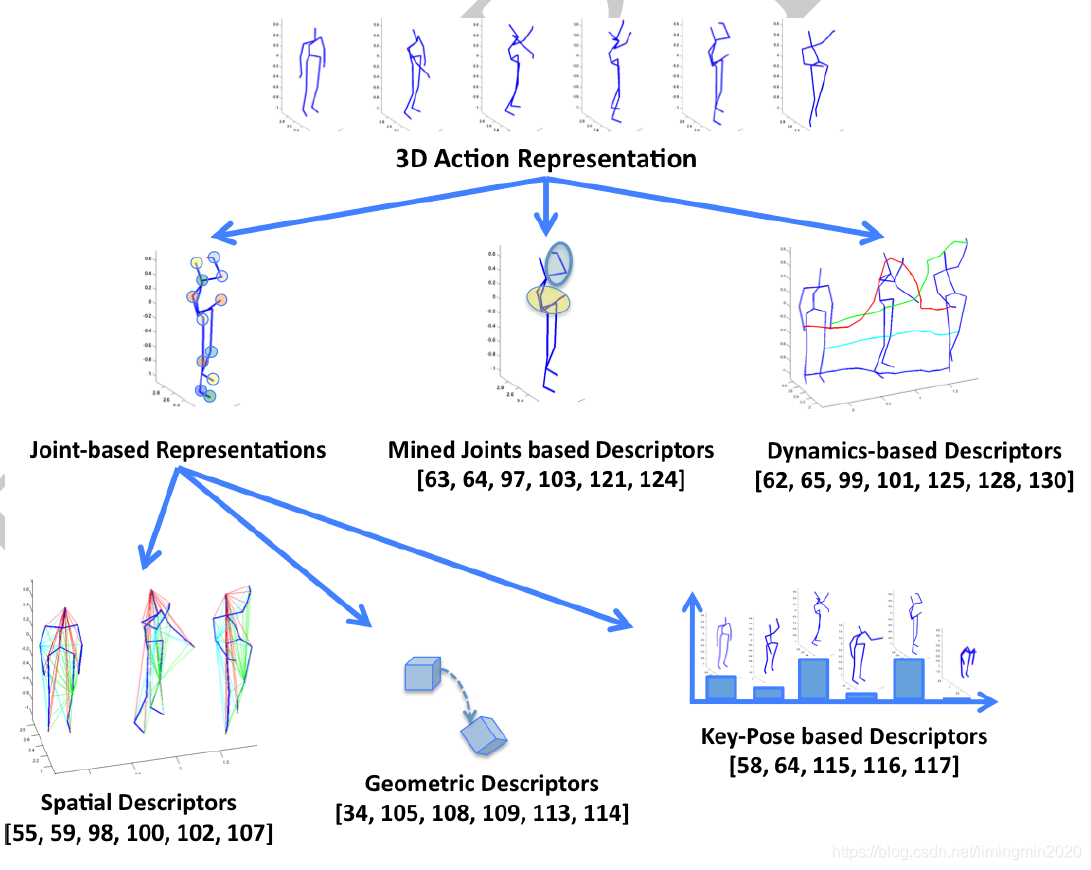 图 1 基于图像学表达的3D人体行为姿态识别方法分类
图 1 基于图像学表达的3D人体行为姿态识别方法分类
(Presti L L, Cascia M L. 3D skeleton-based human action classification[M]. Elsevier Science Inc. 2016.)
各类经典算法分类识别率对比,如图2©所示:
 其中,S指空间描述子方法(Spatial Descriptors)、G指几何描述子方法(Geometrical Descriptors)、K指关键帧描述子方法(key-poses Descriptors)。
其中,S指空间描述子方法(Spatial Descriptors)、G指几何描述子方法(Geometrical Descriptors)、K指关键帧描述子方法(key-poses Descriptors)。
数据库介绍:
UCF:骨骼点(15 joints)、16个动作;
MHAD: 11个动作、660个motion sequences;
MSRA3D: 骨骼点(20个)、20个动作。
对于视频序列的人体骨骼关键点姿态识别,这里介绍一种基于深度神经网络的方法,该方法具有识别率相对较高、算法复杂度低、实现简单快速等优势,并对人体姿态的位移与尺度变化具有不变性。缺点在于其输入的人体姿态必须是具备先验的视频姿态起始和结尾帧。
首先算法的总体流程框架如下图所示,:
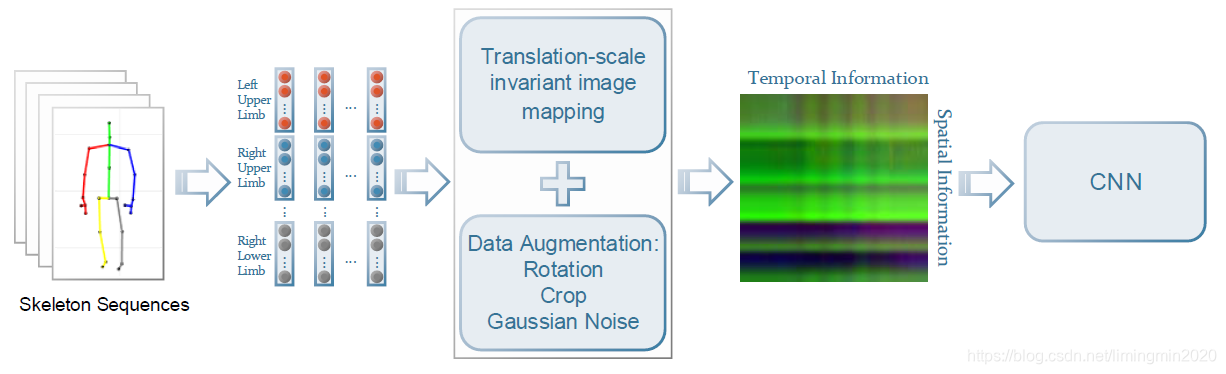 图2(a) CNN框架下基于人体骨骼关键点的姿态识别
图2(a) CNN框架下基于人体骨骼关键点的姿态识别
将每一幅图中的骨骼点分为五个部分,分别为左右手臂骨骼点、左右腿骨骼点、躯干骨骼点。如上图左,用不同颜色区分。按照表述顺序,将每一帧骨骼点拉成一维向量。随后,将一个完整的视频姿态序列中每一帧的向量进行级联,组成一幅RGB图像,(R,G,B)通道分别对应每个骨骼点的(x,y,z)坐标,从而完成将人体视频姿态关键点到一幅图像的映射。
具体来说,人体姿态图像的行定义为: Ri = [xi1; xi2; :::; xiN ], Gi = [yi1; yi2; :::; yiN ], Bi = [zi1; zi2; :::; ziN ], 其中i为关键点的索引,N为视频序列的总帧数。随后通过对上述每一帧中的向量进行坐标系像素对应级联,得到最终的姿态图像,表达为N×M×3, 其中M为每一帧中骨骼点的数量(保持不变)如下图所示。
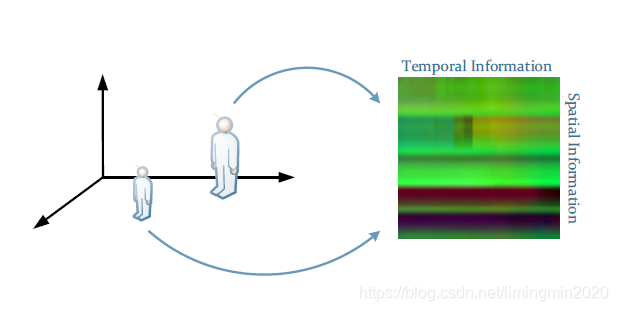 图(b) 时空域人体关键点RGB图像映射表达与尺度不变性示意
图(b) 时空域人体关键点RGB图像映射表达与尺度不变性示意
随后,对每幅图像的像素点进行归一化:
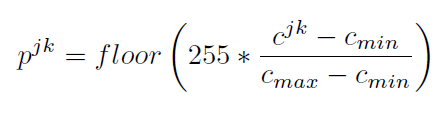 其中,Cmax和Cmin为训练数据集中的最大最小坐标值。255则是将其归一化到图像表达的(0~255)像素区间。
其中,Cmax和Cmin为训练数据集中的最大最小坐标值。255则是将其归一化到图像表达的(0~255)像素区间。
该算法所用数据库为NTU datsets:60个动作,每个动作分别相隔45度从三个角度拍摄;骨骼点(24 joints)。该算法可利用多种CNN开源框架进行训练,对于60个类,测试结果根据训练情况为80%~90%。该算法的缺点是,无法估计人体姿态的首尾帧,需要人工标注。
其他人体骨骼关键点的分类识别方法,绝大部分也类似于上述将关键点序列转化为图像的方式,只是转化方式略有不同,且特征表达较为复杂,不利于算法实时性实现。
2.2 静态人体关键点识别
推荐一种基于形状上下文(shape context)的人体姿态识别方法。形状上下文是基于物体轮廓样本点进行描述, 如下图3所示。
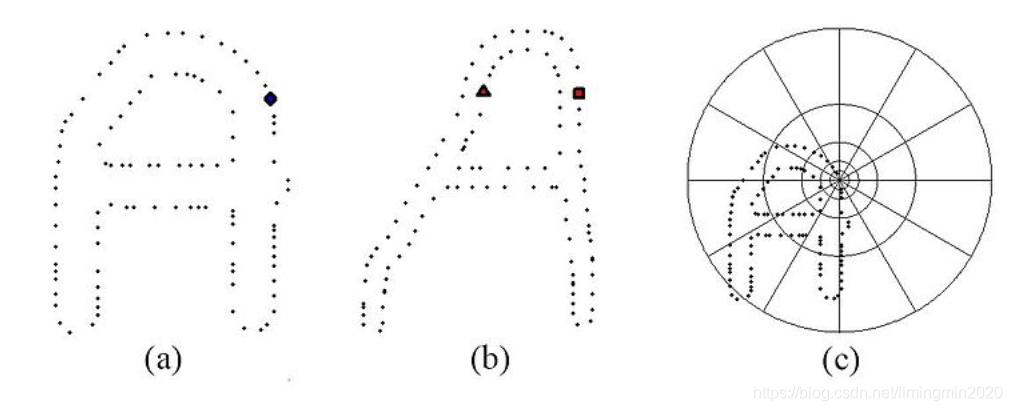 图3 基于形状上下文(shape context)的目标轮廓点特征表达
图3 基于形状上下文(shape context)的目标轮廓点特征表达
形状上下文算子的基本原理是通过建立目标关于每个轮廓点的极坐标,并将极坐标进行区间划分,计算轮廓点落入每个极坐标区间的个数,构成矩阵分布,如下图4所示。
 图4 每一个轮廓点形状上下文特征表达矩阵可视化
图4 每一个轮廓点形状上下文特征表达矩阵可视化
其中图4左为图3(a)中菱形坐标为参考坐标系的特征分布矩阵;图4中为图3(b)中三角坐标为参考坐标系的特征分布矩阵;图4右为图3(b)中方框坐标为参考坐标系的特征分布矩阵.由图4可见,图3(a)的菱形和图3(b)的矩形坐标系下的轮廓点特征分布的可视化矩阵十分相似,从而说明这种特征表达方式对目标具有一定的尺度不变性。
最终通过计算不同目标之间的向量分布差异,从而得到目标相似匹配度。
该算法的初衷是对二维平面的目标进行匹配识别,然后可以将该算法中的极坐标扩展成三维,并将人体骨骼点当作目标轮廓点进行类似的骨骼点坐标分布计算。
三、骨骼点噪声问题
主流文献对该部分的处理不多见,个人理解对于丢失的骨骼关键点,可以通过邻域坐标差值的方法进行拟合 ,对于坐标漂移剧烈的骨骼关键点,可以首先将某个关键点的时域轨迹单独提取,根据帧间轨迹点的速度、位移、方向等变化规律,利用RANSCA或轨迹预测等方法进行漂移关键点剔除。
备注:
点击下面链接,进入奥比中光开发者社区,了解更多3D视觉技术信息:
https://developer.orbbec.com.cn/
或扫描下方二维码,进入奥比中光开发者社区:


