
- 1如何进入到互联网行业_非互联网专业如何进入互联网行业
- 2华为OD岗位薪资大曝光:外包也能享受高薪待遇?_华为od薪资
- 3做项目时候navbar遇到的思考总结1。_@toggleclick="togglesidebar
- 4四个好看的CSS样式表格_css 黑色风格 表格
- 5如何训练一个stable diffusion模型?_stable diffusion 训练
- 6基于 SpringMvc + OpenCV 实现的答题卡识别系统(附源码)_vc 答题卡代码
- 7day 33 iptables_iptables 网卡使能
- 8echarts饼图不同样式_echarts饼图新样式
- 9JAVA ———变量和数据类型与运算符_在以下转换中,分别属于哪种类型:(1)double a=10;(2)double b=20.5; i
- 10MII、RMII、GMII和RGMII,以太网接口中常见的几种标准接口_mii rmii rgmii
DMA、链式DMA、RDMA(精华讲解)
赞
踩
一、DMA
DMA全称Direct Memory Access,即直接存储器访问。CPU完成传输配置后,即可不在参与传输过程,由DMA控制器将数据从一个地址空间复制到另外一个地址空间。最常见的是本地DMA传输,如图1.1所示。
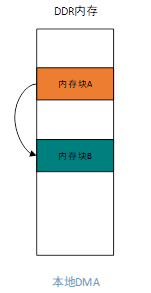
图1.1
CPU设置好三要素(源、目的、大小)后,由DMA控制器将内存块A的内容拷贝到内存块B中。这是普通DMA传输,那么,PCIe设备是如何完成DMA传输的呢?

图1.2
PCIe设备理想的DMA传输过程如图1.2所示,主机端(主片)对PCIe设备(从片)上DMA控制器配置后,由DMA控制将主机内存块A上数据搬运自身内存块B上。这里就有两个疑问了:
1.为什么是PCIe设备(从片)上的DMA控制器?
2.为什么是主机端(主片)来配置DMA控制器?
带着两个问题往下看。实际上PCIe总线上DMA过程如图1.3所示。

图1.3
真实的数据搬运过程需要透过IOMMU(ARM架构为SMMU)并跨越PCI域,才能到达从片内存上。
先回答第一个问题。一般情况主片无法直接访问到从片内存,此外,常出现一主多从情况,为提高资源利用率,也多采用从片DMA。
我们知道一般X86架构在没有开启IOMMU前,主片主存储域地址与PCI域地址是平行映射的,但开启IOMMU后就没有确定的映射关系了。比如,内存块A地址为0x100,平行映射后也是0x100,但开启IOMMU后,映射后的地址可能是0x900,也可能是0x200,即没有确定的映射地址。
从片上DMA控制器想要把主片内存块A上数据搬运到从片内存块B上,就需要知道内存块A通过IOMMU映射后的地址,而这是从片无法知道的,所以一般都是由主片来配置从片DMA控制器,这便是第二个问题答案。
我们知道,DMA控制器所看到的都是物理地址,搬运的数据需要在连续的物理地址上,那么问题来了:如果内存紧张无法申请出连续的物理地址怎么办?
由这个问题引出本文第二部分——链式DMA!
二、链式DMA
为了更好讲解链式DMA传输过程,以某个PCIe的DMA过程为例。
主片申请一块4k对齐的内存空间存放数据,一般使用posix_memalign函数。如图2.1所示,可以看见虚拟内存连续,但物理内存离散,只有物理页D、E相邻。获取这段虚拟内存对应的物理页,将它们的描述结构保存在pages数组中,同时pin住这些物理页,避免存放数据的内存被系统换页到硬盘中,导致数据搬运过程中DMA控制器读取内存不是用户所预期的。

图2.1
若虚拟页已映射物理页,则调用 find_vma_intersection、follow_pfn和 pfn_to_page 函数。若未映射,则调用 get_user_pages_fast 函数。从而获取以用户虚拟地址开始的5个虚拟页对应的物理页,将它们的描述结构保存在pages数组中。
调用sg_alloc_table_from_pages 函数,传入上面获取的pages 数组,即可得到一个sg_tabel散列表,即图2.2右侧4个条目合起来称为sg_tabel散列表。

图2.2
在填充sg_tabel散列表时,还会将相邻的物理页合并成一个条目,也就是物理页D与物理页E合并为条目DE。sg_table表对应结构体为:

图2.3
每个块物理页对应一个条目scatterlist结构,其描述结构体为:

图2.4
也就是说,现在这个sg_tabel散列表描述着这些物理页,其中dma地址是映射后的PCI域上地址,但这里还未得到。


未开启IOMMU 开启IOMMU
图2.5
调用pci_map_sg 函数完成离散映射,同时填充sg_table表中每个条目的dma地址,过程如图2.5所示,分为两种情况,在未开启IOMMU时,映射是平行映射,在开启IOMMU后,将会把离散的物理页映射成连续的PCI域空间,但并不会改变条目个数。至此sg_tabel离散映射表中即可准确描述数据内存在PCI域上地址。

图2.6
如图2.6所示(未开启IOMMU)使用sg_tabel散列表填充从片的DMA描述子(与从片约定好的格式),也就是图2.6中间task块,其结构如下:

图2.7
结构内部包含源地址、目标地址、大小及下一个task结构所在地址,就如同链表一样串在一块,所以称为链式DMA(需硬件支持)。
让从片的BARx窗口映射从片特定地址,然后主片通过ioremap将BARX空间映射到虚拟内存空间,最后将填充好的DMA任务描述子拷贝到BARX虚拟空间,进而通过TLP总线事务传输至从片特定DDR地址上,过程如图2.6所示。

图2.8
配置从片的DMA控制寄存器,从特定DDR地址上拿到DMA任务描述列表,即可开始数据搬运,如图2.8所示(未开启IOMMU)。注:从片上内存块依旧是连续物理内存块。
至此,链式DMA讲解结束,接下来讲解的是基于PCI域上链式DMA技术的RDMA技术。
三、RDMA
本部分只解释核心名词和概念,尽量简化不必要内容,方便理解。
3.1 RDMA技术简介
3.1.1 RDMA优劣势及应用场景
RDMA是Remote Direct Memory Access的缩写,即远程直接数据存取。使用RDMA的优势如下:
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
既然RDMA技术这么好,为什么没能大规模普及?这就不能不说RDMA技术的劣势了,主要有两个:
- 网络要求苛刻:RDMA为了达到高性能低延时的目标,使得RDMA对网络有苛刻的要求,就是网络不能丢包,否则性能下降会很大,这对底层网络硬件提出更大的挑战,同时也限制了rdma的网络规模;相比而言,tcp对于网络丢包抖动的容忍度就大很多。
- 成本高:RDMA通过硬件实现高带宽低时延,降低了CPU的负载,但代价是需要特定的硬件,硬件成本较高。软件上,RDMA技术的应用接口是全新的,大多数现有程序都需要作移植适配及优化,有一定挑战,人工成本高。
目前,RDMA技术有三个比较好的应用方向,即存储、HPC(高性能计算)及数据中心,简要描述如下:
- 为存储系统和计算系统加速,充分利用高带宽低延迟以及释放CPU通信处理。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。
- 为GPU异构计算通信加速,充分利用Zero Copy的特性,减少数据通路中的拷贝次数,大大降低GPU之间的传输延迟。
- 数据中心会存在大量的分布式计算集群,但大量并行程序的通讯延迟,则会极大影响整个计算过程的效率。使RDMA网络和传统数据中心融合,将会有很好的收益。
3.1.2 RDMA协议
RDMA有三种协议,如下图所示:

图3.0
图3.0较为直观的反映三种协议之间差异,再简单介绍一下它们。
Infiniband
2000年由IBTA(InfiniBand Trade Association)提出的IB协议是当之无愧的核心,其规定了一整套完整的链路层到传输层(非传统OSI七层模型的传输层,而是位于其之上)规范,但是其无法兼容现有以太网,除了需要支持IB的网卡之外,企业如果想部署的话还要重新购买配套的交换设备。
RoCE
RoCE从英文全称就可以看出它是基于以太网链路层的协议,v1版本网络层仍然使用了IB规范,而v2使用了UDP+IP作为网络层,使得数据包也可以被路由。RoCE可以被认为是IB的“低成本解决方案”,将IB的报文封装成以太网包进行收发。由于RoCE v2可以使用以太网的交换设备,所以现在在企业中应用也比较多,但是相同场景下相比IB性能要有一些损失。
iWARP
iWARP协议是IETF基于TCP提出的,但是因为TCP是面向连接的协议,而大量的TCP连接会耗费很多的内存资源,另外TCP复杂的流控等机制会导致性能问题,所以iWARP相比基于UDP的RoCE v2来说并没有优势(IB的传输层也可以像TCP一样保证可靠性),所以iWARP相比其他两种协议的应用不是很多。
需要注意的是,上述几种协议都需要专门的硬件(RDMA网卡)支持。后续内容以RoCEv2协议进行讲解,但由于本部分只讲解原理,并不涉及底层实现,因此差异不大。
3.1.3 RDMA原理简介
用一张图描述RDMA过程,如图3.1所示

图3.1
HCA是宿主通道适配器,即RDMA网卡。相比于TCP/IP数据传输,RDMA传输可直接将本端用户态虚拟内存数据传输到对端用户态内存中,而不需要陷入内核!
这是如何实现的?通过本文前两部分讲解,我们知道带DMA引擎的PCI设备能够直接读写宿主机内存,如下图3.2所示。

图3.2
如果DMA引擎从内存块A读取的数据不是放到内存块B,而是通过某种方法传递出去会怎样?如下图3.3所示。

图3.3
原理:
1.HCA是带DMA引擎的PCI设备,具有读写主机DDR能力。
2.HCA是特殊网卡,除了普通网卡功能外,内部支持IB传输协议。
HCA(RDMA网卡)读取本端数据后,在内部将数据按某些格式组包,再通过硬件接口传输到对端HCA上,由对端HCA解包后写入对端内存。值得注意的是,内存块A、B都是连续的虚拟内存,对应的物理内存可不一定连续。
HCA硬件上天然支持RDMA传输,但软件上实现可不容易,先看下图。
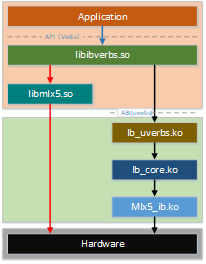
图3.4
先简单介绍一下图3.4中模块:
libibverbs.so:rdma-core核心库
libmlx5.so:用户态驱动,也是个动态链接库,实现厂商的驱动逻辑
ib_uverbs.ko:uverbs驱动
ib_core.ko:RDMA子系统核心模块
mlx5_ib.ko:RDMA硬件驱动程序(PCI设备驱动),负责直接和硬件交互
图3.4中有两条路径,为后续描述方便,称右侧路径为准备路径,称左侧路径为工作路径。可以看到,准备路径需要陷入内核态,而工作路径将绕过内核直接操作硬件,后续的讲解将从这两部分说明。上面说到,硬件天然支持RDMA传输,而软件的工作简要概括就是,通过某种方法告诉硬件三要素——源、目的、大小。
3.2 准备阶段
准备阶段的部分工作就是获取三要素(源、目的、大小),但在此之前还需解决一个问题,在用户态下,用什么方法绕过内核,直接告诉硬件三要素?
3.2.1 获取通知方法
以X86架构为例,我们知道BOIS启动阶段会在主机上为每个PCI设备分配BAR空间,如图3.5主存储域上橘黄色块,就是RDMA网卡的BAR空间。

图3.5
RDMA设备驱动(如mlx5_ib.ko)匹配上设备后,会执行一系列初始化动作,同时保存设备BAR空间在主存储域上的地址。
用户空间进程调用mmap函数分配一块虚拟内存,同时将调用到RDMA设备驱动的mmap函数,进而将主存储域上设备BAR空间映射到所申请的虚拟内存!所以在用户空间操作bar虚拟空间,即可操作RDMA网卡的某些寄存器或内存。
在这块虚拟内存中,比较重要的是Doorbell,其实就是门铃的意思,是一种通知机制,当用户准备好工作请求之后,向Doorbell的地址中写一下数据,就等于敲了一下门铃,硬件就知道可以开始干活了。这便是用户态下的通知方法。
3.2.2 获取源
通知方法有了,现在还需获取三要素,先来说源怎么获取,需要说明一下,这个源是一个集合,不仅仅是数据源地址。

图3.6
如图3.6所示,用户申请一块长度为len的虚拟内存,执行RDMA注册函数,将会得到一个映射表,包含两部分,一个是sg_table记录着物理地址到pci域地址的转换关系,另一个是VA->PA映射表,记录着VA到PA的转换关系。VA->PA映射表很容易理解,sg_tabel获取过程和本文第二部分中描述类似,同样也会pin主内存,这里不再赘述。除此之外,还会获得lkey和rkey,一个是本端操作秘钥,另一个是本端赋予远端的操作秘钥。秘钥由两部分组成,低字节部分是真正的钥匙,高字节部分是本MR的映射表在缓存区的索引。
每注册一个MR都会生成映射表和秘钥,这一系列映射表将放一个硬件知道的缓存区中,由秘钥的高字节索引。
还有一个比较重要的东西,叫QP工作队列对,由SQ发送队列和RQ接收队列组成。QP是软件向硬件“发号施令”的媒介,由用户调用特定函数将其创建,如下图3.7所示。

图3.7
除了创建QP外,还会创建QP的上下文QPC,即描述QP属性的一个结构,这个结构放在硬件知道的一段缓存区里,由QP号(QPN)索引,也就是说,可以有很多个QP,它们之间由QPN区分。值得注意的是,QPC中有一个GID存储区域,这个是存储对端GID的(RC连接)。
GID是一个全局ID,由MAC地址和IP地址转换得来,根据GID就可以找到局域中唯一宿主机。调用专用函数可以获取本端的GID序列号。
至此,源集合已准备好,有MR addr、len、lkey、QPN,再看看如何获取目的集合。
3.2.3 获取目的
本端是无法直接获得对端基本信息的,所以需要通过某些方式,让两端建立通信交换基本信息。有两种方式:TCP/IP和RDMA CM,如下图3.8所示。

图3.8
以socket交换方式为例,双方约定号消息格式,将需要传递的信息通过socket交换就好了。图3.8中LID是本端RDMA适配器激活后分配的ID,在本端唯一,而PSN是本端发送到对端第一个数据包序号,可以随机指定。信息交换完毕后即可关闭上述连接。
至此,目的集合已经准备好,有raddr、rkey、rGID、rQPN,加r表示远端(对端)的意思。万事具备只欠东风。
3.3 工作阶段
3.3.1 下发工作请求
本端在下发工作请求前,还需要处理rQPN和rGID,这里以RC链接(类似于TCP链接)为例。本端需要将QP(节点A)与对端QP(节点x)绑定,在QPC中填入对端QPN,同时又因为是RC链接(点到点),还需在QPC中填入rGID。
现在可以填写工作请求了,这个请求结构称为WQE,即工作请求元素,主要由三部分组成,控制头,远端地址和远端秘钥,本端地址、本端秘钥、数据大小,如下图3.9所示。
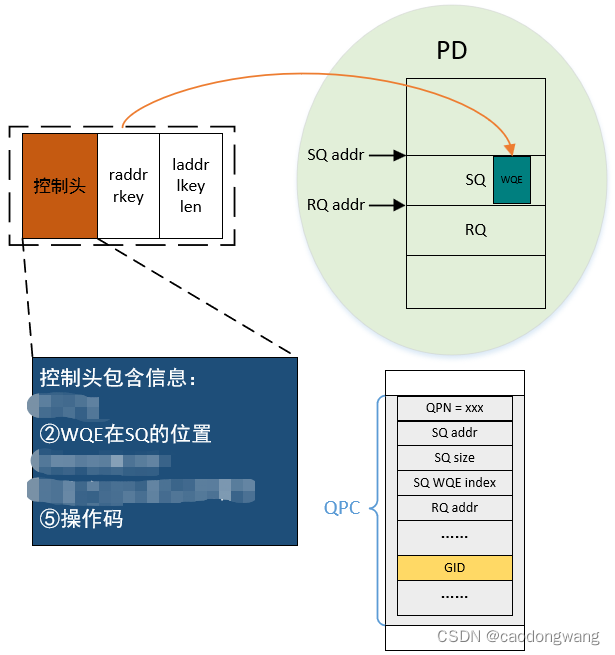
图3.9
结合图3.5,向bar虚拟内存的Doorbell地址一笔数据,通过TLP总线事务传输到RDMA网卡内部,即敲响门铃,硬件就可以开始工作了。
硬件通过Doorbell地址偏移计算出QPN找到对应的QPC,从而找到SQ中的WQE,通过DMA控制器把WQE搬运到内部解析,再通过lkey找到对应的映射表,然后将laddr转换获得数据所在物理页,最终从物理页取得数据组包,如下图3.10所示。

图3.10
硬件还会在数据包中添加对端raddr和rkey,再从QPC中取得对端rGID、rQPN,这样数据包才能到对端宿主机。对端接收到数据包后,根据rkey找到映射表,将raddr翻译,最后将数据写入对应离散物理页中,注意,这个过程对端的cpu是不知道的(需要本端主动通知对端),完全由RDMA网卡完成,不需要内核参与,在对端的app侧看来,就是有人往某块连续的虚拟内存写了数据。
3.3.2 write流程简介
在两方完成准备阶段并交换信息后,操作流程如下图3.11所示。

图3.11
将发送write请求的这侧称为请求端,另一侧称为响应端;
①请求端A下发write请求的WQE(src_addr、len、dst_addr、r_key),里面包含双方地址信息及秘钥;
②请求端A硬件(RDMA网卡)从SQ队列中取得WQE,获取源-目的-长度,这三要素;
③请求端A硬件(RDMA网卡)从内存src_addr地址取得长度为len的数据并组装成数据报文;
④请求端A硬件(RDMA网卡)将数据报文发送至响应端B;
⑤响应端B硬件检查秘钥无误后,根据rkey查找到映射表,将数据写至dst_addr地址对应的物理页中;
⑥响应端B硬件向请求端A硬件返回操作结果;
⑦请求端A硬件根据响应端B的反馈结果上报工作完成CQE,操作成功或失败,失败有错误码;
⑧请求端A的APP查看CQE获取工作完成情况。
其中CQ完成队列,存放的CQE是完成队列元素。
文章讲解完毕,觉得博主讲解不错就点个赞呗。

