
- 1安装ollama并部署大模型并测试_ollama 测试
- 2MATLAB求解微分方程_matlab解微分方程
- 3管理Windows/Mac混合环境的三个选项_域控管理的环境有macos怎么办
- 4【详讲】手把手带你 Typora+PicGoo 配置 gitee 图床_typora+gitee配置picgo图床
- 5算术逻辑单元 —— 串行加法器和并行加法器
- 6java xml transformer_Java xml出现错误 javax.xml.transform.TransformerException: java.lang.NullPointerExc...
- 7python哈希值与地址值_什么时候计算python对象的哈希值,为什么是-1的哈希值是不同的?...
- 8Linux学习系列(二十):在Linux系统中使用Git上传代码到GitHub仓库_linux github
- 9关于warp操作_warp+
- 10头歌MySQL数据库实训答案 有目录_头歌数据库答案mysql
自然语言处理系列十一》中文分词》规则分词》正向最大匹配法、逆向最大匹配法、双向最大匹配法_利用词典的词汇切分方法进行正向最大匹配、逆向最大匹配算法及双向匹配算法,比较
赞
踩
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
自然语言处理系列十一
规则分词
规则分词是基于字典、词库匹配的分词方法(机械分词法),其实现的主要思想是:切分语句时,将语句特定长的字符串与字典进行匹配,匹配成功就进行切分。按照匹配的方式可分为:正向最大匹配分词、逆向最大匹配分词和双向最大匹配分词。这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
正向最大匹配法
正向最大匹配分词(Forward maximum matching segmentation)通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理…… 如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
其算法描述如下:
(1)初始化当前位置计数器,置为0;
(2)从当前计数器开始,取前2i个字符作为匹配字段,直到文档结束;
(3)如果匹配字段长度不为0,则查找词典中与之等长的作匹配处理。
如果匹配成功,则:
a)把这个匹配字段作为一个词切分出来,放入分词统计表中;
b)把当前位置计数器的值加上匹配字段的长度;
c)跳转到步骤2);
否则
a) 如果匹配字段的最后一个字符为汉字字符,
则
①把匹配字段的最后一个字去掉;
②匹配字段长度减2;
否则
①把匹配字段的最后一个字节去掉;
②匹配字段长度减1;
b)跳转至步骤3);
否则
a)如果匹配字段的最后一个字符为汉字字符,
则
当前位置计数器的值加2;
否则当前位置计数器的值加1;
b)跳转到步骤2)。
下面使用HanLP工具包给大家代码示例:
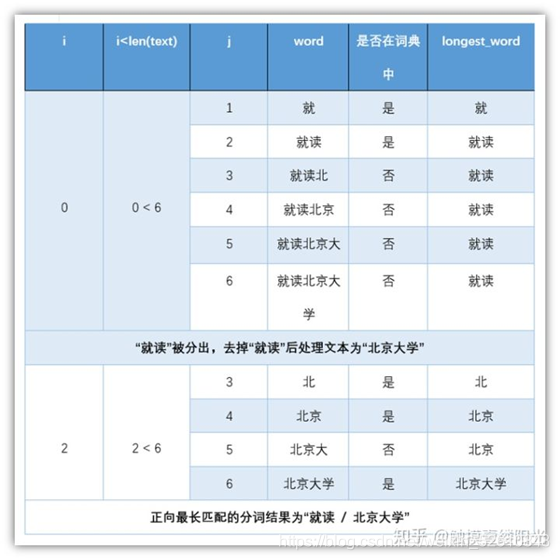
正向最长匹配简单来说就是从前往后进行取词,假设此时词典中最长单词包含5个汉字,对"就读北京大学"进行分词,正向最长匹配的基本流程:
第一轮
正向从前往后选取5个汉字。“就读北京大”,词典中没有对应的单词,匹配失败;
减少一个汉字。“就读北京”,词典中没有对应的单词,匹配失败;
减少一个汉字。“就读北”,词典中没有对应的单词,匹配失败;
减少一个汉字。“就读”,词典中有对应的单词,匹配成功;
扫描终止,输出第1个单词"就读",去除第1个单词开始第二轮扫描。
第二轮
去除"就读"之后,依然正向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的4个汉字进行匹配。“北京大学”,词典中有对应的单词,匹配成功;
至此,通过正向最大匹配对"就读北京大学"的匹配结果为:“就读 / 北京大学”。不过书中实现的正向最长匹配没有考虑设置最长匹配的起始长度,而是以正向逐渐增加汉字的方式进行匹配,如果此时匹配成功还需要进行下一次匹配,保留匹配成功且长度最长的单词作为最终的分词结果。
不过为了提升效率在实际使用中倾向于设置最长匹配的起始长度,如果想更进一步提升分词的速度,可以将词典按照不同汉字长度进行划分,每次匹配的时候搜索相对应汉字个数的词典。虽然代码和讲解有所不同,但是本质和结果都是一样的,越长单词的优先级越高,这里注意一下即可。
from utility import load_dictionary # 导入加载词典函数 def forward_segment(text, dic): """ :param text: 待分词的中文文本 :param dic: 词典 :return: 分词结果 """ word_list = [] i = 0 while i < len(text): longest_word = text[i] for j in range(i + 1, len(text) + 1): word = text[i:j] if word in dic: # 优先输出单词长度更长的单词 if len(word) > len(longest_word): longest_word = word word_list.append(longest_word) # 提出匹配成功的单词,分词剩余的文本 i += len(longest_word) return word_list if __name__ == '__main__': # 加载词典 dic = load_dictionary() print(forward_segment('就读北京大学', dic))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码运行输出结果:
['就读', '北京大学']
- 1
使用上面的代码对"就读北京大学"进行分词,正向最大匹配的具体代码流程如图所示:
 使用正向最长匹配对"就读北京大学"的分词效果很好,但是如果对"研究生命起源"进行分词的话,正向最大匹配分词的结果为"研究生 / 命 / 起源",产生这种误差的原因在于,正向最长匹配中"研究生"的优先级要大于"研究"("研究生"长度长)。正向匹配出的"研究生"优先级要高,很自然的想法从后往前进行匹配,这样就可以先将"生命"划分出来,避免从前到后先把"研究生"划分出来的错误。
使用正向最长匹配对"就读北京大学"的分词效果很好,但是如果对"研究生命起源"进行分词的话,正向最大匹配分词的结果为"研究生 / 命 / 起源",产生这种误差的原因在于,正向最长匹配中"研究生"的优先级要大于"研究"("研究生"长度长)。正向匹配出的"研究生"优先级要高,很自然的想法从后往前进行匹配,这样就可以先将"生命"划分出来,避免从前到后先把"研究生"划分出来的错误。
接下来详细讲解逆向最大匹配法的原理,并用HanLP举例子给大家代码演示。
逆向最大匹配法
逆向最大匹配法 (Reverse maximum matching method)通常简称为RMM法。RMM法的基本原理与MM法相同 ,不同的是分词切分的方向与MM法相反,而且使用的分词辞典也不同。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的2i个字符(i字字串)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精确度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明 ,单纯使用正向最大匹配的错误率为 1/16 9,单纯使用逆向最大匹配的错误率为 1/245。例如切分字段“硕士研究生产”,正向最大匹配法的结果会是“硕士研究生 / 产”,而逆向最大匹配法利用逆向扫描,可得到正确的分词结果“硕士 / 研究 / 生产”。
当然,最大匹配算法是一种基于分词词典的机械分词法,不能根据文档上下文的语义特征来切分词语,对词典的依赖性较大,所以在实际使用时,难免会造成一些分词错误,为了提高系统分词的准确度,可以采用正向最大匹配法和逆向最大匹配法相结合的分词方案,也就是双向匹配法。
下面进行代码示例:
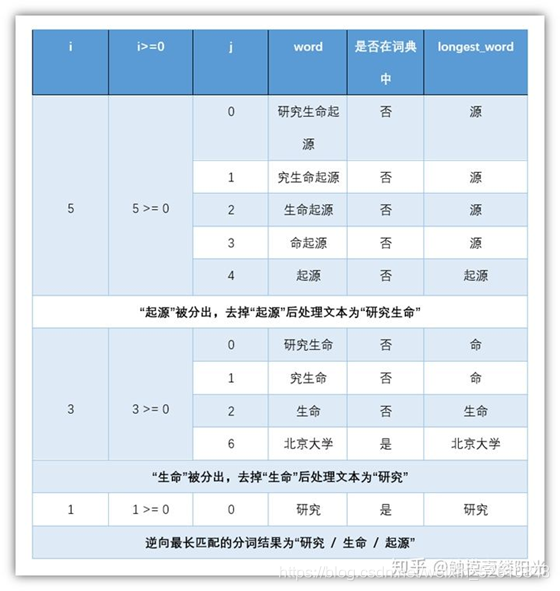
逆向最长匹配顾名思义就是从后往前进行扫描,保留最长单词,逆向最长匹配与正向最长匹配唯一的区别就在于扫描的方向。逆向最长匹配简单来说就是从后往前进行取词,假设此时词典中最长单词包含5个汉字,对"研究生命起源"进行分词,逆向最长匹配的基本流程:
第一轮
正向从后往前选取5个汉字。“究生命起源”,词典中没有对应的单词,匹配失败;
减少一个汉字。“生命起源”,词典中没有对应的单词,匹配失败;
减少一个汉字。“命起源”,词典中没有对应的单词,匹配失败;
减少一个汉字。“起源”,词典中有对应的单词,匹配成功;
扫描终止,输出第1个单词"起源",去除第1个单词开始第二轮扫描。
第二轮
去除"起源"之后,依然反向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的4个汉字进行匹配。“研究生命”,词典中没有对应的单词,匹配失败;
减少一个汉字。“究生命”,词典中没有对应的单词,匹配失败;
减少一个汉字。“生命”,词典中有对应的单词,匹配成功;
扫描终止,输出第2个单词"生命",去除第2个单词开始第三轮扫描。
第三轮
去除"生命"之后,依然反向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的2个汉字进行匹配。“研究”,词典中有对应的单词,匹配成功;
至此,通过逆向最大匹配对"研究生命起源"的匹配结果为:“研究 / 生命 / 起源”。
在书中实现的逆向最长匹配没有考虑设置最长匹配的起始长度,其余与上面的具体流程一致。
from utility import load_dictionary # 导入加载词典函数 def backward_segment(text, dic): """ :param text:待分词的文本 :param dic:词典 :return:元素为分词结果的list列表 """ word_list = [] # 扫描位置作为终点 i = len(text) - 1 while i >= 0: longest_word = text[i] for j in range(0, i): word = text[j: i + 1] if word in dic: # 越长优先级越高 if len(word) > len(longest_word): longest_word = word break # 逆向扫描,所以越先查出的单词在位置上越靠后 word_list.insert(0, longest_word) i -= len(longest_word) return word_list if __name__ == '__main__': # 加载词典 dic = load_dictionary() print(backward_segment('研究生命起源', dic))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
代码运行输出结果:
['研究', '生命', '起源']
- 1
使用上面的代码对"研究生命起源"进行分词,逆向最大匹配的具体代码流程如图所示:
接下来详细讲解双向最大匹配法的原理,并用HanLP举例子给大家代码演示。
双向最大匹配法
双向最大匹配分词是综合了前两者的算法。先根据标点对文档进行粗切分,把文档分解成若干个句子,然后再对这些句子用正向最大匹配法和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小集处理。准确的结果往往是词数切分较少的那种。经研究表明,90%的中文使用正向最大匹配分词和逆向最大匹配分词能得到相同的结果,而且保证分词正确;9%的句子是正向最大匹配分词和逆向最大匹配分词切分有分歧的,但是其中一定有一个是正确的;不到1%的句子是正向和逆向同时犯相同的错误:给出相同的结果但都是错的。因此,在实际的中文处理中,双向最大匹配分词能够胜任几乎全部的场景。
下面进行代码示例:
对"项目的研究"进行分词:
正向最长匹配:“项目 / 的 / 研究”
逆向最长匹配:“项 / 目的 / 研究”
对"研究生命起源"进行分词:
正向最长匹配:“研究生 / 命 / 起源”
逆向最长匹配:“研究 / 生命 / 起源”
通过上面的例子可以看出,有时候正向最长匹配正确,而有的时候逆向匹配的更好,当然也有可能正向最长匹配和逆向最长匹配都无法消除歧义的情况。清华大学孙茂松教授做过统计,在随机挑选的3680个句子中,正向匹配错误而逆向匹配正确的句子占比9.24%,正向匹配正确而逆向匹配错误的情况则没有被统计到。
因此有人提出了融合正向最长匹配和逆向最长匹配的双向最长匹配,双向最长匹配简单来说就是同时执行正向最长匹配和逆向最长匹配,然后在给定的一些规则中选择最优,本质上就是在正向最长匹配和逆向最长匹配中进行二选一。
择优规则:
最长的单词所表达的意义越丰富并且含义越明确。如果正向最长匹配和逆向最长匹配分词后的词数不同,返回词数更少结果;
非词典词和单字词越少越好,在语言学中单字词的数量要远远小于非单字词。如果正向最长匹配和逆向最长匹配分词后的词数相同,返回非词典词和单字词最少的结果;
根据孙茂松教授的统计,逆向最长匹配正确的可能性要比正向最长匹配的可能性要高。如果正向最长匹配的词数以及非词典词和单字词都相同的情况下,优先返回逆向最长匹配的结果;
双向最长匹配的代码如下:
from backward_segment import backward_segment # 导入实现正向最长匹配的函数 from forward_segment import forward_segment # 导入实现逆向最长匹配的函数 from utility import load_dictionary # 导入加载词典的函数 def count_single_char(word_list: list): # 统计单字成词的个数 """ 统计单字词的个数 :param word_list:分词后的list列表 :return: 单字词的个数 """ return sum(1 for word in word_list if len(word) == 1) def bidirectional_segment(text, dic): """ 双向最长匹配 :param text:待分词的中文文本 :param dic:词典 :return:正向最长匹配和逆向最长匹配中最优的结果 """ f = forward_segment(text, dic) b = backward_segment(text, dic) print(f) print(b) # 词数更少优先级更高 if len(f) < len(b): return f elif len(f) > len(b): return b else: # 单字词更少的优先级更高 if count_single_char(f) < count_single_char(b): return f else: # 词数以及单字词数量都相等的时候,逆向最长匹配优先级更高 return b if __name__ == '__main__': # 加载词典 dic = load_dictionary() print(bidirectional_segment('项目的研究', dic)) print(bidirectional_segment('研究生命起源', dic))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
代码运行输出结果:
['项', '目的', '研究']
['研究', '生命', '起源']
- 1
- 2
通过观察双向最长匹配对"项目的研究"的分词结果,发现即使是融合了正向最长匹配和逆向最长匹配的双向最长匹配也不一定得到正确的分词结果,甚至有可能正确率比逆向最长匹配还要低,由此,规则系统的脆弱可见一斑,规则集的维护有时是拆东墙补西墙,有时是帮倒忙。不过基于词典分词的核心价值不在于精度,而在于速度。
由于正向最大匹配分词和逆向最大匹配分词给出相同词数的分词结果,可以制定默认的选择是其中一种。当然,实际的中文处理中,这种情况并不会很常见。
上面讲到的是基于规则的分词方式,另一种方式是基于机器学习的统计分词,接下来的自然语言处理系列进行详细讲解。
总结
此文章有对应的配套视频,其它更多精彩文章请大家下载充电了么app,可获取千万免费好课和文章,配套新书教材请看陈敬雷新书:《分布式机器学习实战》(人工智能科学与技术丛书)
【新书介绍】
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目
【新书介绍视频】
分布式机器学习实战(人工智能科学与技术丛书)新书【陈敬雷】
视频特色:重点对新书进行介绍,最新前沿技术热点剖析,技术职业规划建议!听完此课你对人工智能领域将有一个崭新的技术视野!职业发展也将有更加清晰的认识!
【精品课程】
《分布式机器学习实战》大数据人工智能AI专家级精品课程
【免费体验视频】:
人工智能百万年薪成长路线/从Python到最新热点技术
视频特色: 本系列专家级精品课有对应的配套书籍《分布式机器学习实战》,精品课和书籍可以互补式学习,彼此相互补充,大大提高了学习效率。本系列课和书籍是以分布式机器学习为主线,并对其依赖的大数据技术做了详细介绍,之后对目前主流的分布式机器学习框架和算法进行重点讲解,本系列课和书籍侧重实战,最后讲几个工业级的系统实战项目给大家。 课程核心内容有互联网公司大数据和人工智能那些事、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)、就业/面试技巧/职业生涯规划/职业晋升指导等内容。
【充电了么公司介绍】
充电了么App是专注上班族职业培训充电学习的在线教育平台。
专注工作职业技能提升和学习,提高工作效率,带来经济效益!今天你充电了么?
充电了么官网
http://www.chongdianleme.com/
充电了么App官网下载地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行业职位】 - 专注职场上班族职业技能提升
覆盖所有行业和职位,不管你是上班族,高管,还是创业都有你要学习的视频和文章。其中大数据智能AI、区块链、深度学习是互联网一线工业级的实战经验。
除了专业技能学习,还有通用职场技能,比如企业管理、股权激励和设计、职业生涯规划、社交礼仪、沟通技巧、演讲技巧、开会技巧、发邮件技巧、工作压力如何放松、人脉关系等等,全方位提高你的专业水平和整体素质。
【牛人课堂】 - 学习牛人的工作经验
1.智能个性化引擎:
海量视频课程,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习课程。
2.听课全网搜索
输入关键词搜索海量视频课程,应有尽有,总有适合你的课程。
3.听课播放详情
视频播放详情,除了播放当前视频,更有相关视频课程和文章阅读,对某个技能知识点强化,让你轻松成为某个领域的资深专家。
【精品阅读】 - 技能文章兴趣阅读
1.个性化阅读引擎:
千万级文章阅读,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习文章。
2.阅读全网搜索
输入关键词搜索海量文章阅读,应有尽有,总有你感兴趣的技能学习文章。
【机器人老师】 - 个人提升趣味学习
基于搜索引擎和智能深度学习训练,为您打造更懂你的机器人老师,用自然语言和机器人老师聊天学习,寓教于乐,高效学习,快乐人生。
【精短课程】 - 高效学习知识
海量精短牛人课程,满足你的时间碎片化学习,快速提高某个技能知识点。
上一篇:自然语言处理系列十》中文分词》规则分词》双向最大匹配法
下一篇:自然语言处理系列十二》中文分词》机器学习统计分词

