
- 1代码生成工具 AutoCode For XML发布_autoxml工具
- 2算法:FloodFill算法
- 3科大讯飞首发开源大模型“星火开源-13B” 深度适配昇思MindSpore AI框架_科大讯飞星火 昇思
- 4signature=f62f1ec47a85918a7d111dd1dcc3aa4e,ant-design-pro-vue
- 5Linux用户管理与文件权限_superuser用户权限
- 6mysql 列转行,合并字段_mysql如何在extra列变成一
- 7RabbitMQ的基本绑定
- 8使用YOLOv4进行自定义数据集训练的流程及结果_yolov4训练过程
- 9[终端安全]-2 移动终端之硬件安全(SE)
- 10最长连续递增子序列_最长递增序列回溯最终索引
【爬虫项目-4】微博超话内容爬取/selenium使用教学_微博超话数据爬虫
赞
踩
一、代码撰写目的
闲来无事想了解王者荣耀某个英雄最近的风评,例如是版本之子吗or出装怎么搭配or大家对策划这次改动有何看法,发现微博超话这方面的内容非常多,于是想把超话内容爬取下来做进一步数据分析。温馨提示 本代码可以适用于任何微博超话内容的爬取,只需修改url即可。
二、网页结构
可以看到超话一打开,网页是如下布局,一篇帖子大概包含如下一些信息:用户id、发布时间、来自xxx超话、帖子正文内容以及收藏、转发、评论、点赞数量。
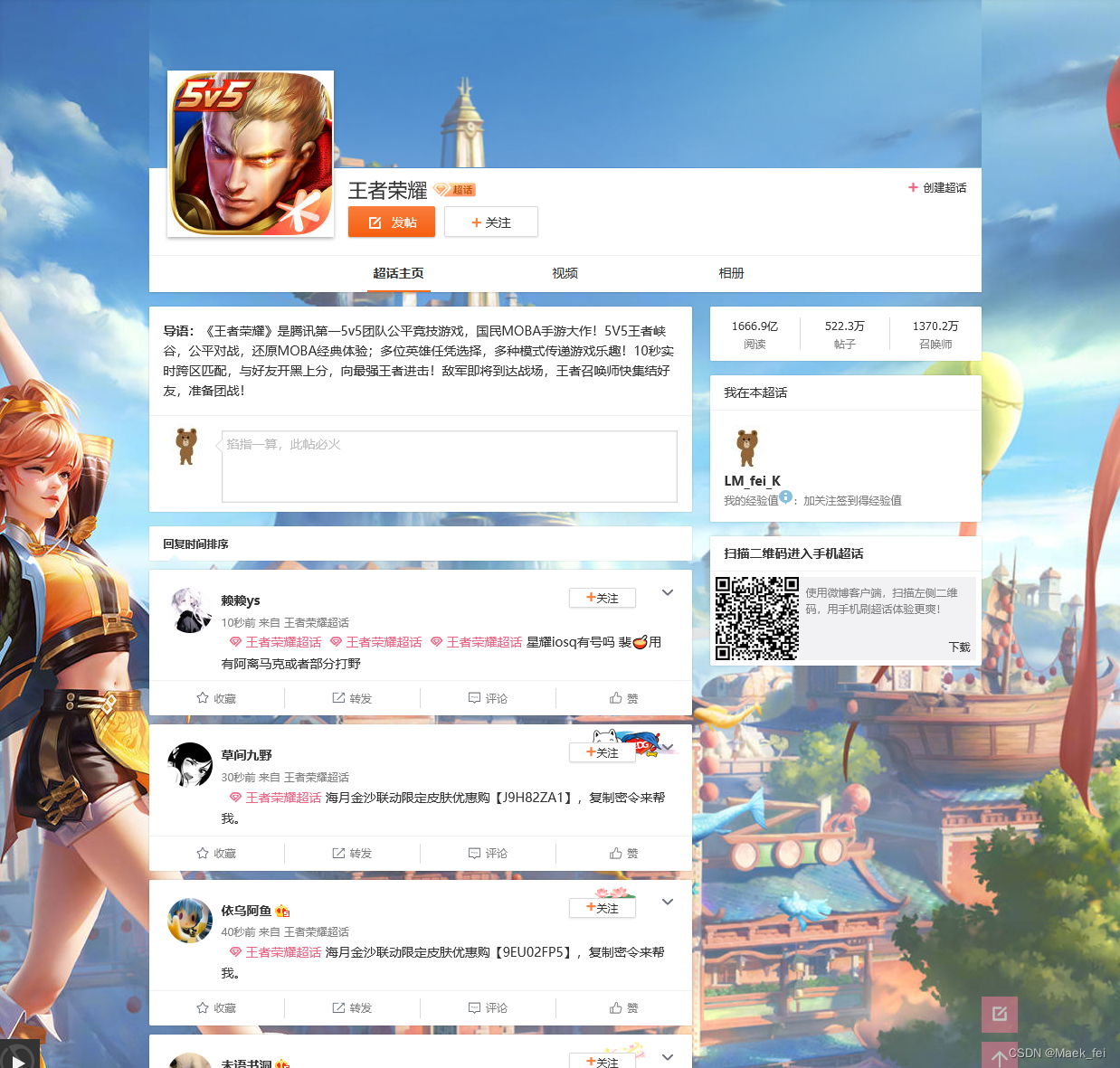
再往下翻会发现,通常无法完整加载出来一整夜,会下翻会触发加载,所以说这是一个动态网页
 想要批量爬取上百页超话内容,我们不仅要克服动态加载还要实现自动翻页
想要批量爬取上百页超话内容,我们不仅要克服动态加载还要实现自动翻页
三、代码主体
话不多说,上菜
版本一定要注意,selenium的版本会影响后面代码的编写
- import time
- from bs4 import BeautifulSoup #4.10.0
- from selenium import webdriver #3.141.0
- from xlrd import open_workbook
- from xlutils.copy import copy
- import eventlet#导入eventlet这个模块
配置webdriver,webdriver的路径根据自己实际进行配置,一定要下载和自己电脑谷歌浏览器版本相匹配的的webdriver否则会出现错误,怎么查看自己谷歌浏览器版本可以自行百度,Chromewebdriver下载链接也可以自行百度,网上一大堆,下载完成之后解压出来exe放到自己的项目路径下就可以。
这里的base_url可以根据自己爬取的超话进行修改,baseurl是用于后面翻页的,所以url最后是page=而不是page=xx(某一具体数字)
- #调用selenium工具
- options = webdriver.ChromeOptions()
- options.add_experimental_option('excludeSwitches', ['enable-automation'])
- driver = webdriver.Chrome(executable_path=r"chromedriver.exe", options=options)
-
- base_url = "https://s.weibo.com/weibo?q=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80%E8%B6%85%E8%AF%9D%E4%BC%A0%E7%BB%9F%E6%96%87%E5%8C%96&page="
下面这段代码用于登录微博(不登录的话无法批量爬取),其中cookies需要自己配置(登录自己的微博然后复制自己的cookies),cookies如何获取可以百度(真的很多教学,这里就不展开篇幅说了)
- driver.get("https://weibo.com/p/100808ccb61d96c8f867d4f6c412e95c4f173a/super_index?current_page=3&since_id=4878245637659820&page=2#1678548112338")
- driver.delete_all_cookies()
- cookies ={}
- for cookie in cookies:
- cookie_dict = {
- 'domain': '.weibo.com',
- 'name': cookie.get('name'),
- 'value': cookie.get('value'),
- "expires": cookie.get('value'),
- 'path': '/',
- 'httpOnly': False,
- 'HostOnly': False,
- 'Secure': False}
- driver.add_cookie(cookie_dict)
- driver.refresh()
如果实在不会配置,可以采用下面这段代码,即直接暂停一分钟,自己手动登录一下
- driver.get("https://weibo.com/p/100808ccb61d96c8f867d4f6c412e95c4f173a/super_index?current_page=3&since_id=4878245637659820&page=2#1678548112338")
- driver.delete_all_cookies()
- time.sleep(60)
下面这段代码用于解决动态加载,即一直自动下滑直到触底
- driver.get(url)
- time.sleep(5)
- eventlet.monkey_patch() # 必须加这条代码
- with eventlet.Timeout(10, False): # 设置超时时间为20秒
- while True:
- # 循环将滚动条下拉
- driver.execute_script("window.scrollBy(0,1000)")
- # sleep一下让滚动条反应一下
- time.sleep(0.05)
- # 获取当前滚动条距离顶部的距离
- check_height = driver.execute_script(
- "return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
- # 如果两者相等说明到底了
- if check_height >9000:
- break
再往下的代码都是用于定位元素,爬取内容的,真正的难题已经都被解决了,因为观察到有的帖子内容比较长,需要点击展开才能爬取完整内容,因此自动定位页面中所有展开字样并自动点击再进行帖子正文抓取
- elements = driver.find_elements_by_css_selector(
- "div.content p.txt a")
- for i in elements:
- if "展开" in i.text:
- driver.execute_script("arguments[0].click()",i)
保存数据
- r_xls = open_workbook(r"帖子内容.xlsx") # 读取excel文件
- row = r_xls.sheets()[0].nrows # 获取已有的行数
- excel = copy(r_xls) # 将xlrd的对象转化为xlwt的对象
- worksheet = excel.get_sheet(0) # 获取要操作的sheet
- # 对excel表追加一行内容
- for i in range(len(chuantong)):
- worksheet.write(row, 0, chuantong[i]) # 括号内分别为行数、列数、内容
-
- row += 1
- excel.save(r"帖子内容.xlsx") # 保存并覆盖文件
四、注意事项(完整的代码和数据在公主号和Github)
大家白嫖代码的时候一定要注意我标明的三方库版本,版本不对很有可能会出错,此外最后保存数据的方法有很多大家可以自行挑选更改。
最重要的一点,如果大家觉得有用跪求大家给我一个关注和点赞,有不懂的问题可以私信或者留言,欢迎大家关注我的公主号,上面有更多更详尽的代码,喜欢白嫖的有福了。

GitHub - Maekfei/Spider-projects: 爬虫实战,集合了数十个爬虫实战代码,全都亲测可用,借鉴麻烦点个star谢谢 同时欢迎访问我的github主页,copy代码的同时别忘了点个star 谢谢!

