
- 1Cesium.js基础使用(vue)
- 2网络工程实训_5交换机配置
- 3nginx快速入门,使用多种方式部署nginx(mac/windows/docker/docker-compose)_mac nginx
- 4总结:大模型技术栈---算法与原理
- 5python怎么做gui界面,python gui界面设计_gui练习-制作两个界面
- 6django + mssql + sqlserver2008_django+serversql源码
- 7git 本地改动了,不保留,直接拉取线上最新代码_git强制拉取最新代码覆盖原有代码的命令
- 8性能监控与报告:实时了解ReactFlow应用的性能指标
- 9【蓝桥杯】-刷题技巧-总结_蓝桥杯会员到期可以刷题吗
- 10python获取剪切板内容
RKNN模型部署(1)—— 相关介绍_rknn部署
赞
踩
1 RKNN介绍
1.1 简介
Rockchip板载AI芯片,内置高能效NPU,拥有强劲算力,支持多种AI框架和AI应用开发SDK,易于开发,拥有面向AI应用的丰富接口,便于扩展,适用于语音唤醒、语音识别、人脸识别等功能应用场景。
RKNN 是 Rockchip npu 平台使用的模型类型,以.rknn后缀结尾的模型文件。Rockchip提供RKNN-Toolkit开发套件进行模型转换、推理运行和性能评估。
用户通过提供的 python 接口可以便捷地完成以下功能:
1)模型转换:支持 Caffe、Tensorflow、TensorFlow Lite、ONNX、Darknet 模型,支持RKNN 模型导入导出,后续能够在硬件平台上加载使用。
2)模型推理:能够在 PC 上模拟运行模型并获取推理结果,也可以在指定硬件平台RK3399Pro Linux上运行模型并获取推理结果。
3)性能评估:能够在 PC 上模拟运行并获取模型总耗时及每一层的耗时信息,也可以通过联机调试的方式在指定硬件平台 RK3399Pro Linux上运行模型,并获取模型在硬件上运行时的总时间和每一层的耗时信息。
RKNN Tookit仅支持Linux系统,可在PC上使用。此外, Rockchip 也提供了c/c++和python的API 接口。
1.2 RKNN-Toolkit
RKNN-Toolkit是为用户提供在 PC、 Rockchip NPU 平台上进行模型转换、推理和性能评估的开发套件,用户通过该工具提供的 Python 接口可以便捷地完成以下功能:
1、模型转换
支持Caffe、Tensorflow、TensorFlow Lite、ONNX、Darknet、Pytorch、MXNet 模型转成 RKNN 模型,支持 RKNN 模型导入导出,后续能够在 Rockchip NPU 平台上加 载使用。从1.2.0版本开始支持多输入模型。从1.3.0版本开始支持 Pytorch 和 MXNet。
2、量化功能
支持将浮点模型转成量化模型, 目前支持的量化方法有非对称量化( asymmetric_quantized-u8 ) , 动态定点量化 ( dynamic_fixed_point-8 和 dynamic_fixed_point-16)。从1.0.0版本开始, RKNN-Toolkit 开始支持混合量化功能。
3、模型推理
能够在 PC 上模拟 Rockchip NPU 运行 RKNN 模型并获取推理结果;也可以将 RKNN 模型分发到指定的 NPU 设备上进行推理。
4、性能评估
能够在 PC 上模拟 Rockchip NPU 运行 RKNN 模型,并评估模型性能(包括总 耗时和每一层的耗时);也可以将 RKNN 模型分发到指定 NPU 设备上运行,以评估模型 在实际设备上运行时的性能。
5、内存评估
评估模型运行时对系统和 NPU 内存的消耗情况。使用该功能时,必须将 RKNN 模型分发到 NPU 设备中运行,并调用相关接口获取内存使用信息。从0.9.9版本开始支持该功能。
6、模型预编译
通过预编译技术生成的 RKNN 模型可以减少在硬件平台上的加载时间。对 于部分模型,还可以减少模型尺寸。但是预编译后的 RKNN 模型只能在 NPU 设备上运行。 目前只有 x86_64 Ubuntu 平台支持直接从原始模型生成预编译 RKNN 模型。 RKNN-Toolkit 从0.9.5版本开始支持模型预编译功能,并在1.0.0版本中对预编译方法进行了升级,升级 后的预编译模型无法与旧驱动兼容。从1.4.0版本开始,也可以通过 NPU 设备将普通 RKNN 模型转成预编译 RKNN 模型。
7、模型分段
该功能用于多模型同时运行的场景下,可以将单个模型分成多段在 NPU 上执 行,借此来调节多个模型占用 NPU 的执行时间,避免因为一个模型占用太多执行时间, 1而使其他模型得不到及时执行。RKNN-Toolkit 从1.2.0版本开始支持该功能。该功能必须 在带有 Rockchip NPU 的硬件上使用,且 NPU 驱动版本要大于0.9.8。
8、自定义算子功能
如果模型含有 RKNN-Toolkit 不支持的算子(operator),那么在模型转 换阶段就会失败。这时候可以使用自定义算子功能来添加不支持的算子,从而使模型能正 常转换和运行。RKNN-Toolkit 从1.2.0版本开始支持该功能。自定义算子的使用和开发请参考《Rockchip_Developer_Guide_RKNN_Toolkit_Custom_OP_CN》文档。
9、量化精度分析功能
该功能将给出模型量化前后每一层推理结果的欧氏距离或余弦距离, 以分析量化误差是如何出现的,为提高量化模型的精度提供思路。该功能从1.3.0版本开 始支持。1.4.0版本增加逐层量化精度分析子功能,将每一层运行时的输入指定为正确的 浮点值,以排除逐层误差积累,能够更准确的反映每一层自身受量化的影响。
10、可视化功能
该功能以图形界面的形式呈现 RKNN-Toolkit 的各项功能,简化用户操作步 骤。用户可以通过填写表单、点击功能按钮的形式完成模型的转换和推理等功能,而不需 要再去手动编写脚本。有关可视化功能的具体使用方法请参考《Rockchip_User_Guide_RKNN_Toolkit_Visualization_CN》文档。1.3.0版本开始支持该功 能。1.4.0版本完善了对多输入模型的支持,并且支持 RK1806, RV1109, RV1126 等新的 Rockchip NPU 设备。
11、模型优化等级功能
RKNN-Toolkit 在模型转换过程中会对模型进行优化,默认的优化选项 可能会对模型精度产生一些影响。通过设置优化等级,可以关闭部分或全部优化选项。有 关优化等级的具体使用方法请参考 config 接口中optimization_level参数的说明。该功能从 1.3.0版本开始支持。
1.3 环境依赖
1、系统支持
Ubuntu 16.04 x64(以上)、Window 7 x64(以上)、Mac OS X 10.13.5 x64 (以上)、 Debian 9.8 (x64)以上;
2、Python版本
3.5/3.6/3.7;
3、Python依赖
'numpy == 1.16.3'
'scipy == 1.3.0'
'Pillow == 5.3.0'
'h5py == 2.8.0'
'lmdb == 0.93'
'networkx == 1.11'
'flatbuffers == 1.10',
'protobuf == 3.6.1'
'onnx == 1.4.1'
'onnx-tf == 1.2.1'
'flask == 1.0.2'
'tensorflow == 1.11.0' or 'tensorflow-gpu'
'dill == 0.2.8.2'
'ruamel.yaml == 0.15.81'
'psutils == 5.6.2'
'ply == 3.11'
'requests == 3.11'
'pytorch == 1.2.0'
'mxnet == 1.5.0'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.Windows 只提供Python3.6的安装包。
2.MacOS 提供Python3.6和Python3.7的安装包。
3.ARM64 平台(安装 Debian 9 或 10 操作系统)提供Python3.5(Debain 9)和Python3.7(Debian10)的安装包。
4.除 MacOS 平台外,其他平台的 scipy 依赖为>=1.1.0。
2 NPU开发简介
2.1 NPU特性
- 支持 8bit/16bit 运算,运算性能高达 3.0TOPS。
- 相较于 GPU 作为 AI 运算单元的大型芯片方案,功耗不到 GPU 所需要的 1%。
- 可直接加载 Caffe / Mxnet / TensorFlow 模型。
- 提供 AI 开发工具:支持模型快速转换、支持开发板端侧转换 API、支持 TensorFlow / TF Lite / Caffe / ONNX / Darknet 等模型 。
2.2 开发流程
NPU开发完整的流程如下图所示:
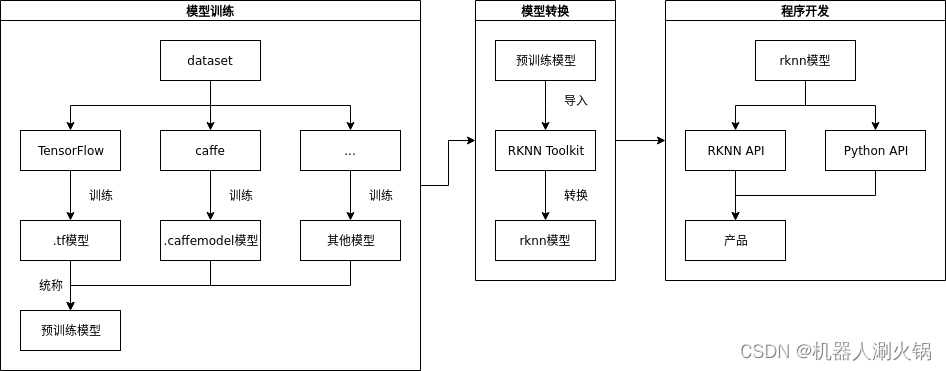
1、模型训练
在模型训练阶段,用户根据需求和实际情况选择合适的框架(如Caffe、TensorFlow等)进行训练得到符合需求的模型。也可直接使用已经训练好的模型。
2、模型转换
此阶段为通过RKNN Toolkit把模型训练中得到的模型转换为NPU可用的模型。
3、程序开发
最后阶段为基于RKNN API或RKNN Tookit的Python API开发程序实现业务逻辑。
2.3 NPU驱动说明
NPU的驱动在$SDK/external/rknpu/drivers/目录下或者https://github.com/rockchip-linux/rknpu/tree/master/drivers
其中的编译、安装规则参考$SDK/buildroot/package/rockchip/rknpu/rknpu.mk
主要目录包括:
drivers/
├── common
├── linux-aarch64 // RK1808 full driver
├── linux-aarch64-mini // RK1808 mini driver
├── linux-armhf // RK1806 full driver
├── linux-armhf-mini // RK1806 mini driver
├── linux-armhf-puma // RV1109/RV1126 full driver
├── linux-armhf-puma-mini // RV1109/RV1126 mini driver
├── npu_ko // NPU内核驱动KO
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在更新驱动时,需要同时更新用户态驱动及内核驱动,不然会产生类似错误:
[ 1] HAL user version 6.4.6.5.351518
[ 2] HAL kernel version 6.4.6.5.351518
- 1
- 2
另外,npu ko与内核配置强相关,有可能会加载不成功,运行程序时,会产生类似错误:
[ 1] Failed to open device: No such file or directory, Try again...
[ 2] Failed to open device: No such file or directory, Try again...
- 1
- 2
有时需要手动更新NPU驱动,只要将相关的驱动拷贝到对应的目录就可以,具体方式见手动更新NPU驱动。
3 RKNN SDK
RKNN SDK为带有RKNPU的芯片平台提供C语言编程接口,用于用户部署RKNN模型。
在使用 RKNN SDK 之前,用户首先需要使用 RKNN-Toolkit 工具将用户的模型转换为RKNN模型,成功转换生成RKNN 模型之后,用户可以先通过RKNN-Toolkit 连接RK1808 等开发板进行联机调试,确保模型的精度性能符合要求。得到RKNN 模型文件之后,用户可以选择使用 C 或Python 接口在RK1808 等平台开发应用。
详情见Rockchip_User_Guide_RKNN_API_V1.7.3_CN.pdf
4 Rock-X SDK 快捷AI组件库
Rock-X SDK是基于RK3399Pro/RK1808的一组快捷AI组件库,初始版本包括:人脸检测、人脸识别、活体检测、人脸属性分析、人脸特征点、人头检测、人体骨骼关键点、手指关键点、人车物检测等功能,开发者仅需要几条API调用即可在嵌入式产品中离线地使用这些功能,而无需关心AI模型的部署细节,极大加速了产品的原型验证和开发部署。
Rock-X组件库根据用户的需求仍会不断扩充,并将支持基于计算棒的调用。

