
- 1你觉得做为一名开发负责人需要具备哪些特质--chatgpt回答_开发项目负责人 需要具备
- 2Django进阶:DRF(Django REST framework)_django drf
- 3Kafka 最佳实践:构建高性能、可靠的数据管道_kafka消费模式最佳实践
- 4python转换成c语言_将Python转换成C语言,然后用Cython编译成exe
- 5记 搭建pycharm远程连接spark的艰难过程_importerror: no module named findspark
- 6从零开始研发GPS接收机连载——3、用HackRF软件无线电平台作为GPS模拟器_gps sdr sim
- 7utf8mb4_0900_ai_ci_utf8mb40900aici
- 8Java项目:客户关系管理系统(java+SpringBoot+layui+html+maven+mysql)_java 管理系统角色划分
- 9Hadoop集群环境配置及安装配置(详细过程包含安装包)_hadoop安装与配置_hadoop 配置
- 10深度学习笔记(九):神经网络剪枝(Neural Network Pruning)详细介绍
大模型OpenCompass评测实战_opencompass 数据
赞
踩
一、模型评测背景:
大模型发展过程中模型评测起到的意义,评测体系的发展、挑战、方向,评测社区的贡献与工具的作用,评测方式、方法、规范在大模型评测过程中全面了解大模型的优势和限制。通过本次学习掌握、熟悉OpenCompass评测工具的用法、配置文件的作用以及评测体系的内在涵义。
实战OpenCompass评测体系采取客观评测与主观评测相结合的方法对InternLM2-Chat-1.8B 模型在 C-Eval 数据集上的具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价,体现模型能力的开放式或半开放式的问题、模型安全问题等。
二、评测促进模型发展:
1.面向未来拓展能力维度
通过能力维度、数学、复杂、逻辑推理,代码、智能体等全面评估模型性能。
2.扎根通用能力聚焦垂直行业
在专业领域结合行业知识、规范评估模型的行业适用性。
3.高质量中文基准
在中文场景,能准确评估能力的中文评测基准,促进中文社区大模型的发展。
4.性能评测反哺能力迭代
深入分析评测性能,探索模型能力形成机制,发现模型不足,研究针对性提升策略。
三、评测中的挑战
1.全面性:
场景千变万化、能力演进迅速、设计和构造的能力维度体系
2.评测成本
需要打算里资源、高昂的基于人工打分的主观评测成本
3.数据污染
海量语料带来的评测集污染、可高的数据污染检测技术、设计动态更新的高质量评测基准。
4.鲁棒性
提示词的敏感性、多次采样情况下的性能稳定性。
四、OpenCompass大模型评测体系开源历程

五、助力大模型产业发展和学术研究

六、评测大模型
对模型评测采用的方式、方法、维度、工具等来评测模型在各方面表现出的性能。
基座模型:海量数据无监督训练。
对话模型:指令数据有监督微调,人类偏好对其。
公开权重的开源模型:使用GPU/推理加速卡进行本地推理。
API模型:发送网络请求回去回复。
客观问答题:

客观选择题:

开放式主观问答:

提示词工程:


长文本评测(大海捞针):

工具-记准-榜单三位一体的社区力量汇聚

大模型评测全栈工具链:


评测流水线:
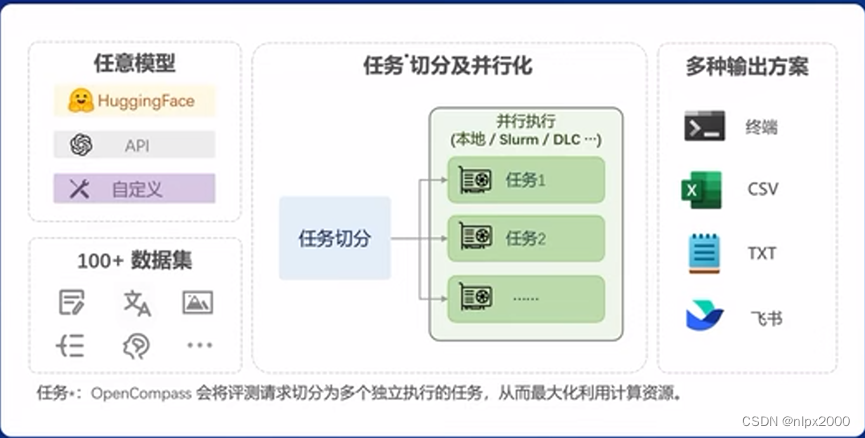
高质量评测基准社区:
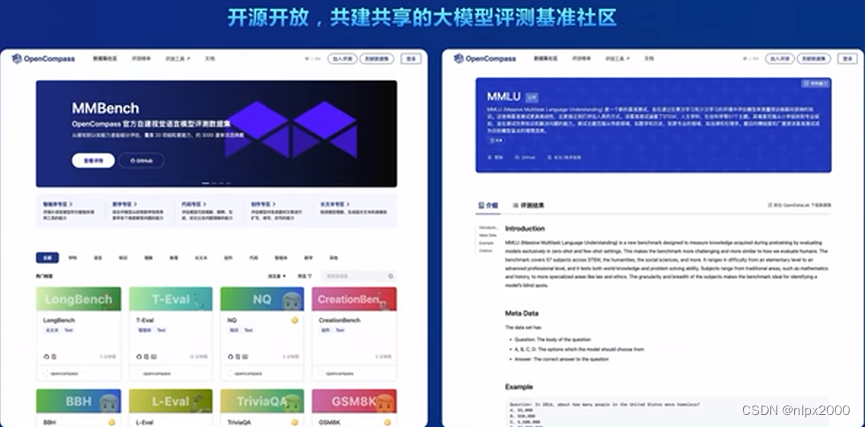
能力维度全面升级:

高质量大模型评测基准:

七、评测实战
OpenCompass 评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
工具架构

环境配置:
安装:
studio-conda -o internlm-base -t opencompass
source activate opencompass
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
pip install -r requirements.txt
数据准备:
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
数据集和模型查看:
列出所有跟 internlm 及 ceval 相关的配置
python tools/list_configs.py internlm ceval

启动评测:
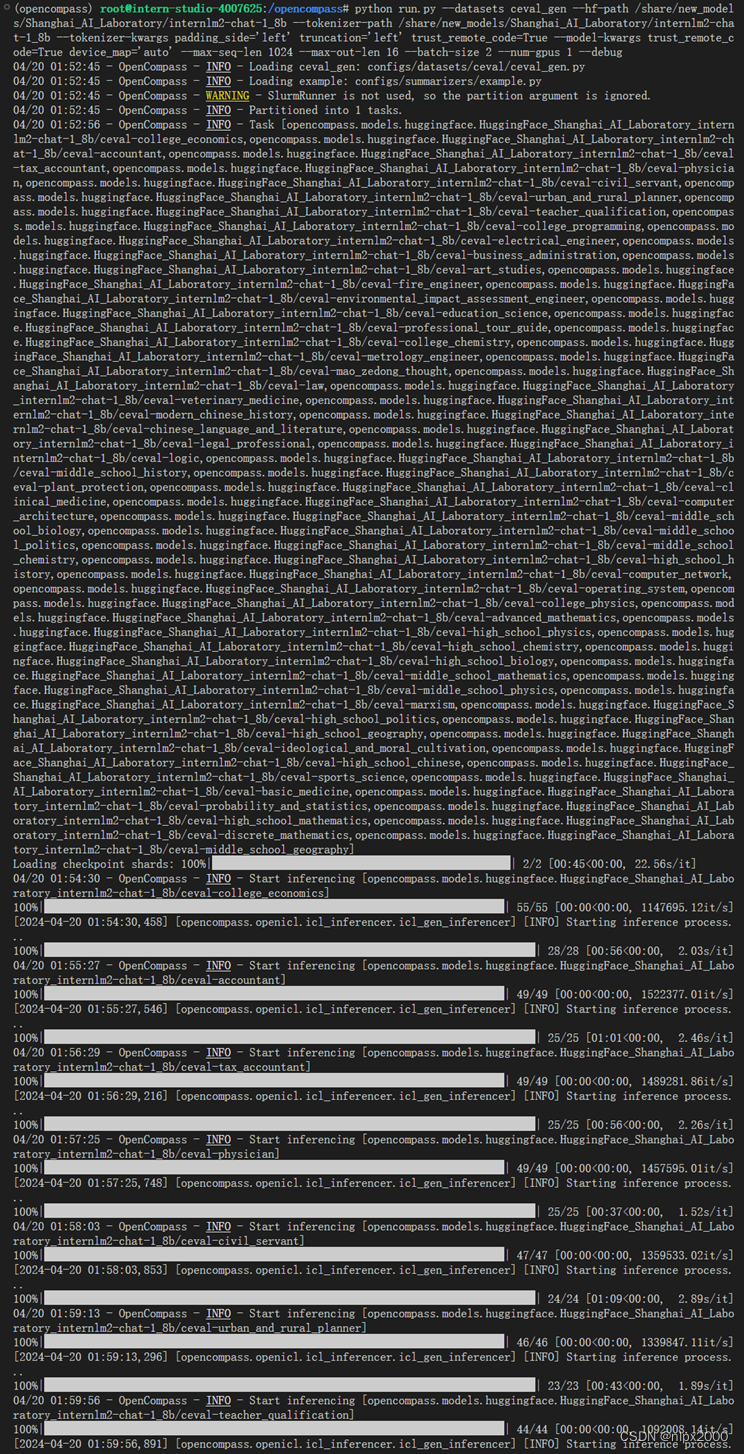
OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。启动命令如下:
- python run.py
- --datasets ceval_gen \
- --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
- --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
- --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
- --model-kwargs device_map='auto' trust_remote_code=True \ #构建模型的参数
- --max-seq-len 1024 \ # 模型可以接受的最大序列长度
- --max-out-len 16 \ # 生成的最大 token 数
- --batch-size 2 \ # 批量大小
- --num-gpus 1 # 运行模型所需的 GPU 数量
- --debug
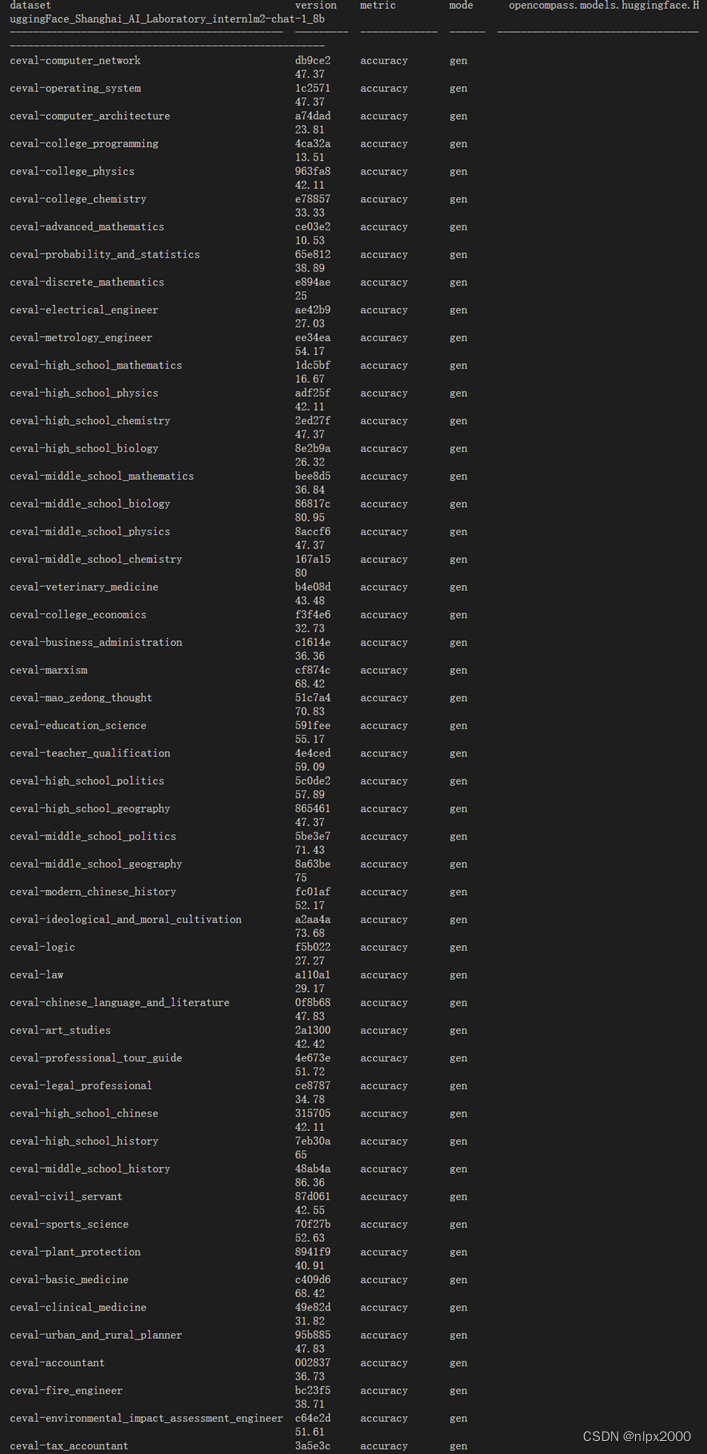
评测完成情况,会打印出模型在各维度的一个评价情况。



八、自定义数据集评测配置
介绍自定义ceval数据集评测配置方法,详细数据集配置请参见opencompass官方文档。
第一步:opencompass/config/database/ceval目录下新建或者修改ceval文件,按照现有文件格式修改!以ceval_gen_5f30c7.py文件为例修改或新建:注意红框处的修改。

第二步:opencompass/ opencompass/database/目录下新建或者修改ceval文件,按照现有文件格式修改加载数据集!以ceval.py文件为例修改或新建,文件中的新建类,在第一步文件中必须引入该文件中实现的模块。

第三步:opencompass/ opencompass/database/_init_.py文件中添加第二步中的py文件,注册实现的模块。

第四步:opencompass/config/database/ceval/ceval_gen.py文件中修改为第一步中的数据集文件名称:

第五步:执行命令:
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
![[Algorithm][动态规划][子序列问题][最长递增子序列][摆动序列]详细讲解](https://img-blog.csdnimg.cn/direct/0d6d1381fcfc456d8ef38c868d225d60.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

