
- 1使用 AES 算法在 C# 中实现安全字符串加密和解密_c# aes
- 2图嵌入概述
- 3ubuntu设置网络代理_ubuntu 网络代理
- 4怎么卸载mysql2008_SQL Server 2008怎么卸载?SQL Server 2008完全卸载教程
- 5计算机制图设计教程-以全国降水处理为例_气温降水专题地图设计报告
- 6kubernetes-v1.23.3 部署 kafka_2.12-2.3.0_kubernetes kafka搭建
- 7高并发高可用微服务架构技术选型Dubbo与Spring Cloud
- 8Spring Gateway转发websocket原理
- 9python虚拟环境搭建mac_mac搭建python virtualenv虚拟环境并使用 - 李金龙
- 10vue2 播放大华 rtsp 视频流方法_vue播放rtsp视频流
94. BERT以及BERT代码实现
赞
踩
1. NLP里的迁移学习
- 使用预训练好的模型来抽取词、句子的特征
- 例如word2vec 或语言模型
- 不更新预训练好的模型
- 需要构建新的网络来抓取新任务需要的信息
- Word2vec忽略了时序信息,语言模型只看了一个方向
- Word2vec只是抽取底层的信息,作为embedding层,之后的网络还是得自己设计,所以新的任务需要构建新的网络
2. BERT的动机
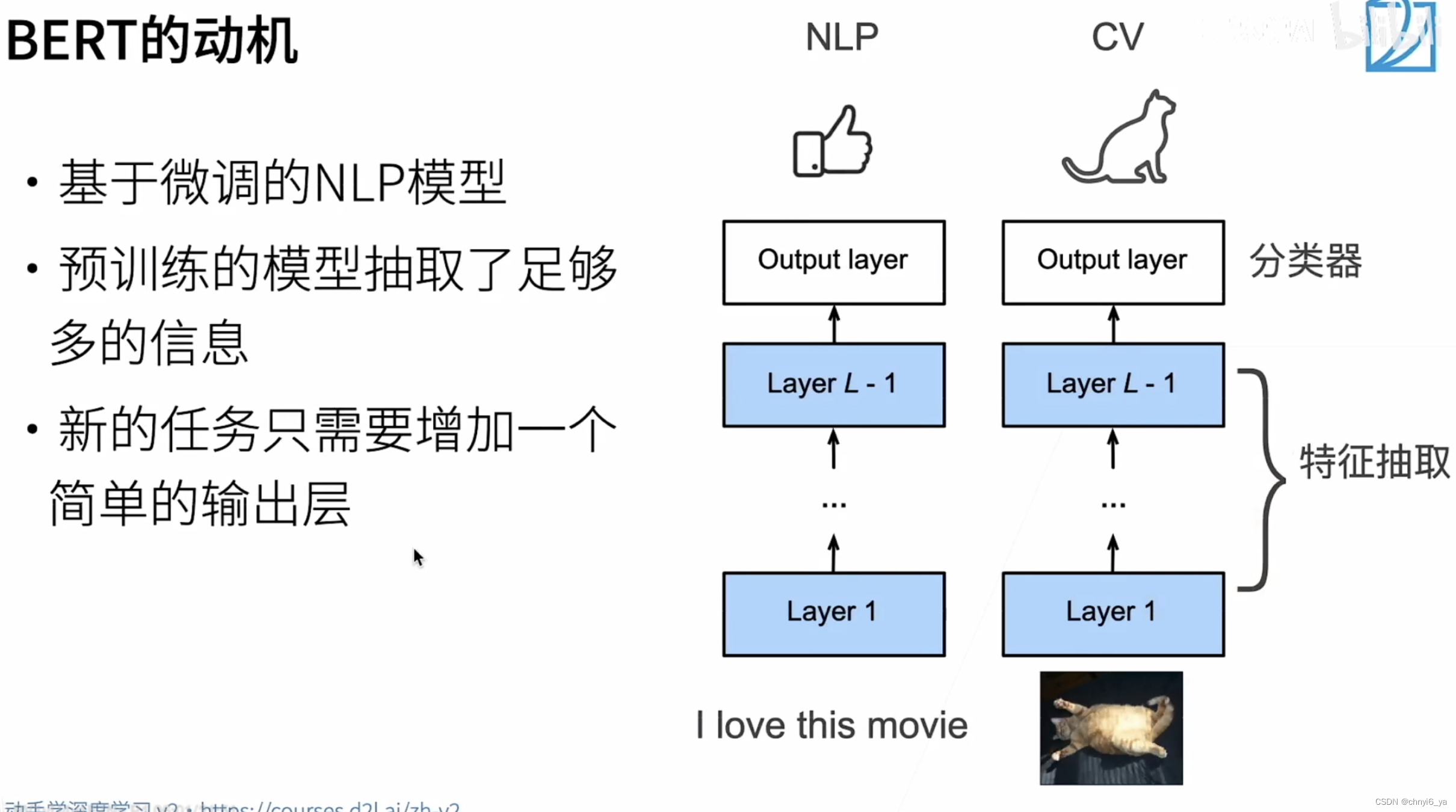
3. BERT架构

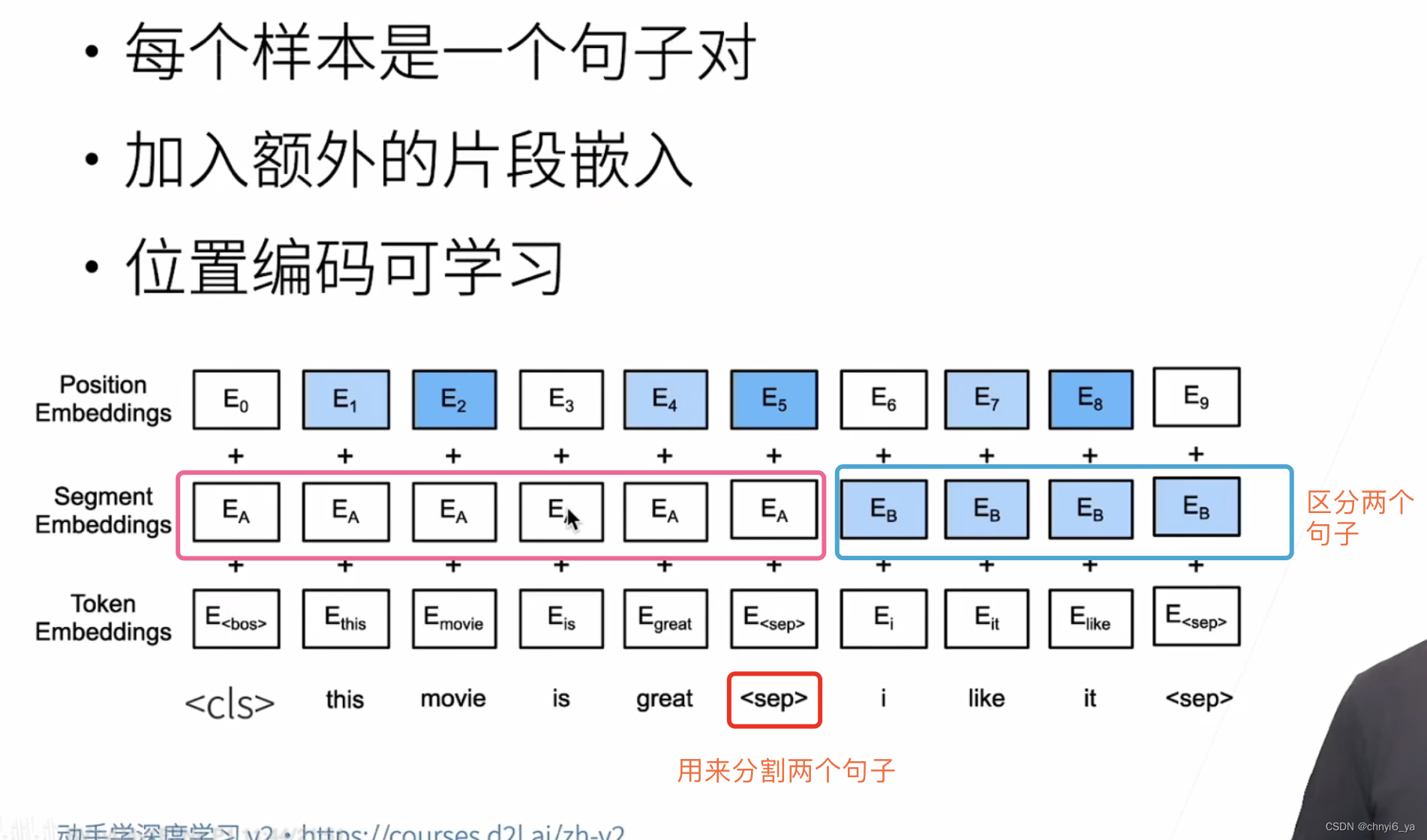
4. 输入的修改
5. 预训练任务1:带掩码的语言模型

6. 预训练任务2:下一句子预测

7. 总结
- BERT是针对微调设计的
- 基于Transformer的编码器做了如下修改
- 模型更大,训练数据更多
- 输入句子对,片段嵌入,可学习的位置编码
- 训练时使用两个任务:
- 带掩码的语言模型
- 下一个句子预测
8. 代码实现
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
8.1 输入表示
下面的get_tokens_and_segments将一个句子或两个句子作为输入,然后返回BERT输入序列的标记及其相应的片段索引。
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
# segements 是一个长为len(tokens_a) + 2的向量,每个元素都是0
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
下面的BERTEncoder类类似于transformer中实现的TransformerEncoder类。与TransformerEncoder不同,BERTEncoder使用片段嵌入和可学习的位置嵌入。
class BERTEncoder(nn.Module): """BERT编码器""" def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000, key_size=768, query_size=768, value_size=768, **kwargs): super(BERTEncoder, self).__init__(**kwargs) self.token_embedding = nn.Embedding(vocab_size, num_hiddens) # segment_embedding中第一个参数是2,因为输入是0和1 self.segment_embedding = nn.Embedding(2, num_hiddens) self.blks = nn.Sequential() for i in range(num_layers): # 加入多少个EncoderBlock self.blks.add_module(f"{i}", d2l.EncoderBlock( key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, True)) # 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数 # batch_size=1,随机初始化pos_embedding self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens)) def forward(self, tokens, segments, valid_lens): # 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens) X = self.token_embedding(tokens) + self.segment_embedding(segments) X = X + self.pos_embedding.data[:, :X.shape[1], :] # 以上两行代码是对输入X进行处理 for blk in self.blks: # 接着让X输入到之前设置好的blk中,自行计算 X = blk(X, valid_lens) return X

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
假设词表大小为10000,为了演示BERTEncoder的前向推断,让我们创建一个实例并初始化它的参数。
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
- 1
- 2
- 3
- 4
我们将tokens定义为长度为8的2个输入序列,其中每个词元是词表的索引。使用输入tokens的BERTEncoder的前向推断返回编码结果,其中每个词元由向量表示,其长度由超参数num_hiddens定义。此超参数通常称为Transformer编码器的隐藏大小(隐藏单元数)。
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
- 1
- 2
- 3
- 4
运行结果:

8.2 预训练任务
1. 掩蔽语言模型(Masked Language Modeling)
我们实现了下面的MaskLM类来预测BERT预训练的掩蔽语言模型任务中的掩蔽标记。预测使用单隐藏层的多层感知机(self.mlp)。在前向推断中,它需要两个输入:BERTEncoder的编码结果和用于预测的词元位置。输出是这些位置的预测结果。
class MaskLM(nn.Module): """BERT的掩蔽语言模型任务""" def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs): super(MaskLM, self).__init__(**kwargs) self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.LayerNorm(num_hiddens), nn.Linear(num_hiddens, vocab_size)) # X是上面上一块代码中BERT encoder的输出, # pred_positions是要预测的词元的位置 def forward(self, X, pred_positions): # 每个输入序列要预测的位置个数 # 假设pred_positions是一个二维数组:[[1, 5, 2], [6, 1, 5]] # 则shape[1]表示列数,也就是有几个位置需要预测 num_pred_positions = pred_positions.shape[1] # reshape(-1) 表示把pred_positions弄成一行,也就是: # [1, 5, 2, 6, 1, 5] pred_positions = pred_positions.reshape(-1) # X是encoded_X,形状是(2, 8, 768), # 表示批量大小为2,长度为8,每个词元用长为768的向量表示 batch_size = X.shape[0] # batch_idx:(0,1) batch_idx = torch.arange(0, batch_size) # 假设batch_size=2,num_pred_positions=3 # 那么batch_idx是np.array([0,0,0,1,1,1]) # repeat_interleave((0,1), 3),得到batch_idx为:tensor([0, 0, 0, 1, 1, 1]) batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions) # X[batch_idx, pred_positions]也就是X[([0,0,0,1,1,1]),([1, 5, 2, 6, 1, 5])] # 分别拿到(0,1),(0,5),(0,2),(1,6),(1,1),(1,5)这一些需要mask的位置 # (0,1)解释:拿到第一个序列的第1行,第一行也就是我要用做预测的词元 # 所以,masked_X得到的是所有要mask的词元的原本的向量表示(经过BERT之后的向量表示) masked_X = X[batch_idx, pred_positions] # 形状是(6,768) # 对masked_X 进行reshape(2,3,768) masked_X = masked_X.reshape((batch_size, num_pred_positions, -1)) # 再把对masked_X放入mlp中,这也对应了mlp定义的第一层的num_inputs大小为768 # 放入mlp中就会对这些mask词元做预测,由长为768的向量表示,变成vocab_size大小的向量表示 mlm_Y_hat = self.mlp(masked_X) # 因此返回的mlm_Y_hat的形状是(2,3,10000),也就是最后一维发生了改变 return mlm_Y_hat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
为了演示MaskLM的前向推断,我们创建了其实例mlm并对其进行了初始化。回想一下,来自BERTEncoder的正向推断encoded_X表示2个BERT输入序列。我们将mlm_positions定义为在encoded_X的任一输入序列中预测的3个指示。mlm的前向推断返回encoded_X的所有掩蔽位置mlm_positions处的预测结果mlm_Y_hat。对于每个预测,结果的大小等于词表的大小。
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shape
- 1
- 2
- 3
- 4
运行结果:

通过掩码下的预测词元mlm_Y的真实标签和预测结果mlm_Y_hat,我们可以计算在BERT预训练中的遮蔽语言模型任务的交叉熵损失。
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
# mlm_Y_hat.reshape((-1, vocab_size))后得到的形状是(6,10000)
# mlm_Y.reshape(-1)的形状是一个长为6的向量
# 这里应该是随意举的例子,为了表示一下要算交叉熵损失函数
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果:

2. 下一句预测(Next Sentence Prediction)
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
下面的NextSentencePred类使用单隐藏层的多层感知机来预测第二个句子是否是BERT输入序列中第一个句子的下一个句子。由于Transformer编码器中的自注意力,特殊词元“< cls>”的BERT表示已经对输入的两个句子进行了编码。因此,多层感知机分类器的输出层(self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而MLP隐藏层的输入是编码后的“< cls>”词元。
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们可以看到,NextSentencePred实例的前向推断返回每个BERT输入序列的二分类预测。
# 一开始的encoded_X的形状是(2,8,768)
# 从第1维开始展平得到的形状是(2,8*768)=(2,6144)
encoded_X = torch.flatten(encoded_X, start_dim=1)
# encoded_X.shape[-1]:6144
# 这个6144是来初始化NextSentencePred实例的,作为num_inputs
nsp = NextSentencePred(encoded_X.shape[-1])
# NSP的输入形状:(batchsize,num_hiddens)
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行结果:

还可以计算两个二元分类的交叉熵损失。
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l.shape
- 1
- 2
- 3
运行结果:

值得注意的是,上述两个预训练任务中的所有标签都可以从预训练语料库中获得,而无需人工标注。原始的BERT已经在图书语料库 :cite:Zhu.Kiros.Zemel.ea.2015和英文维基百科的连接上进行了预训练。这两个文本语料库非常庞大:它们分别有8亿个单词和25亿个单词。
3. 整合代码
在预训练BERT时,最终的损失函数是掩蔽语言模型损失函数和下一句预测损失函数的线性组合。现在我们可以通过实例化三个类BERTEncoder、MaskLM和NextSentencePred来定义BERTModel类。前向推断返回编码后的BERT表示encoded_X、掩蔽语言模型预测mlm_Y_hat和下一句预测nsp_Y_hat。
class BERTModel(nn.Module): """BERT模型""" def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000, key_size=768, query_size=768, value_size=768, hid_in_features=768, mlm_in_features=768, nsp_in_features=768): super(BERTModel, self).__init__() # Bert的encoder self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=max_len, key_size=key_size, query_size=query_size, value_size=value_size) # 隐藏层,是下一个句子预测任务的隐藏层 self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens), nn.Tanh()) # 任务1 self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features) # 任务2 self.nsp = NextSentencePred(nsp_in_features) def forward(self, tokens, segments, valid_lens=None, pred_positions=None): # 获得输入X进行了各种编码,位置编码+segement embedding + token embedding encoded_X = self.encoder(tokens, segments, valid_lens) if pred_positions is not None: # 需要预测位置的话,就需要掩码语言模型 mlm_Y_hat = self.mlm(encoded_X, pred_positions) else: mlm_Y_hat = None # encoded_X的第0个维度是batch_szie,第1个维度是输入的句子长度(一个句子对), # 第2个维度是 表示每个词元的向量的长度 # 那么0就是这个句子对的第一个元素“<cls>”的索引 # 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引 nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :])) return encoded_X, mlm_Y_hat, nsp_Y_hat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

