
- 1驾驭多云环境,加速AI创新丨Animbus Cloud 8.3.0 算力调度平台升级发布
- 2基于动力学模型的机械臂滑膜控制_机械臂滑模控制
- 3C语言程序设计知识点总结归纳(全书)_《c语言程序设计》知识点
- 4链表OJ练习_if(head.val == head.next.val) head = head.next;
- 5docker安装Elasticsearch+Kibana+密码配置_xpack.monitoring.ui.container.elasticsearch.enable
- 6Git——撤销本地add、commit操作 & 回退remote版本_git 撤销本地add
- 7Mysql的隔离级别_mysql 隔离级别
- 8ELINK离线编程器常见问题
- 9一文带你打通Vue3、TypeScript基础_typescripe 省略.vue后缀导入
- 10如何有序高效地进行大文件跨国传输?
k8s集群离线部署_rpm -ivh cri-dockerd
赞
踩
K8s离线部署
环境

目标
k8s离线部署
步骤
部署docker
详情见文章:《离线安装docker及后端项目离线打包》
https://blog.csdn.net/qq_45371023/article/details/140279746?spm=1001.2014.3001.5501
所用到的所有文件在:
链接:https://pan.baidu.com/s/10cb-dXkgdShdjPEBCyvTrw?pwd=fpuy
提取码:fpuy
安装cri_dockerd
1、安装cri_dockerd
rpm -ivh cri-dockerd-0.3.9-3.el8.x86_64.rpm

2、重载系统守护进程→设置cri-dockerd自启动→启动cri-dockerd
重载系统守护进程
sudo systemctl daemon-reload
- 1
设置cri-dockerd自启动
sudo systemctl enable cri-docker.socket cri-docker
- 1
启动cri-dockerd
sudo systemctl start cri-docker.socket cri-docker
sudo systemctl status cri-docker.socket
sudo systemctl status cri-docker
- 1
- 2
- 3
- 4
- 5
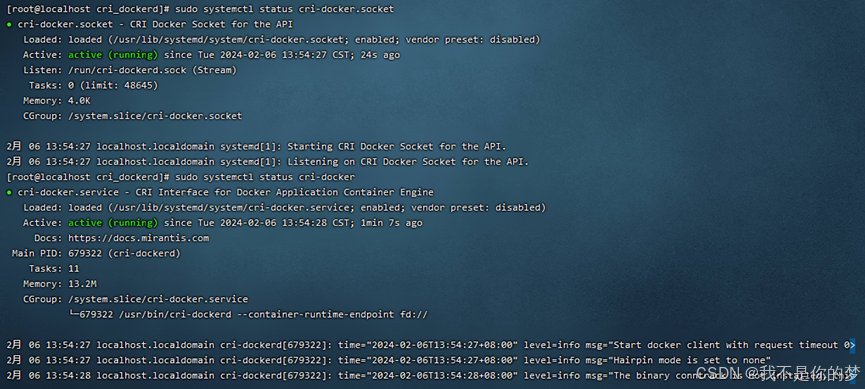
问题:启动cri-docker失败
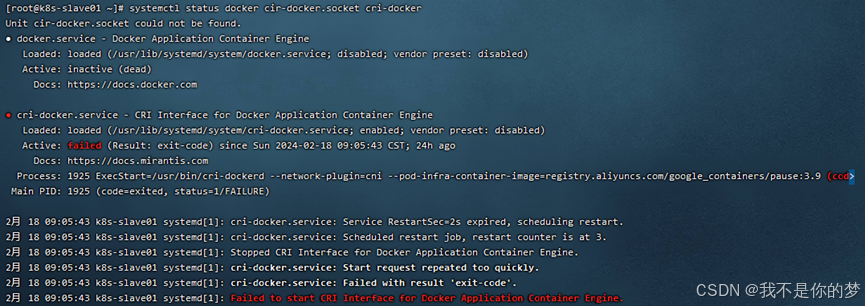
措施:
方法一:systemctl restart docker # 重启docker
方法二:卸载docker重新安装,重新执行以上步骤
*安装Kubernetes
安装kubectl
1、安装kubectl
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
- 1
2、检测是否安装完成
kubectl version --client
- 1

安装kubeadm
3、开放端口或关闭防火墙(用于确保安装过程顺利)
开放端口(云服务器)
开启6443端口
sudo firewall-cmd --zone=public --add-port=6443/tcp --permanent
- 1
重新加载防火墙
sudo firewall-cmd --reload
- 1
查看所有开放的端口
sudo firewall-cmd --zone=public --list-ports
- 1
或关闭防火墙(虚拟机)
关闭防火墙
sudo systemctl stop firewalld
- 1
关闭防火墙自启动
sudo systemctl disable firewalld
- 1
4、禁用SELinux(确保容器能够访问系统资源)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
- 1
- 2
5、安装 kubeadm、kubelet 和 kubectl
相关离线安装包一下载rpm格式,存在于3_yum_package下,使用命令安装目录下所有rpm安装包
cd 3_yum_package && rpm -ivh *.rpm
- 1
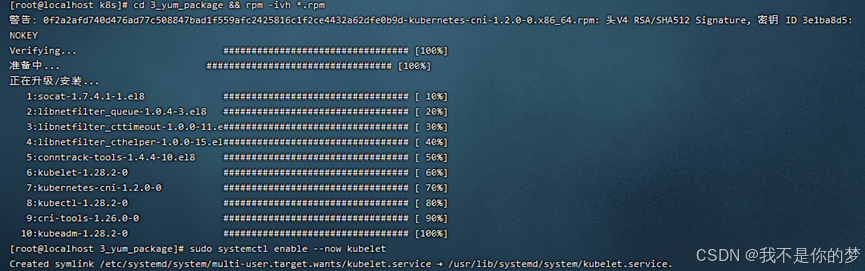
6、设置kubelet自启动
sudo systemctl enable --now kubelet
- 1

*部署k8s集群
以上步骤完成后,具备以下环境
·两台ip不相同的服务器或虚拟机,能够互相通信,保持局域网状态,ip设为192.168..34和192.168..35
·两台server上都安装了容器运行时(Docker+cri_dockerd),已经安装kubernetes组件kubectl、kubeadm和kubelet。
环境准备
7、关闭swap分区,这里分为临时关闭和永久关闭,虚拟机环境推荐永久关闭,因为会经常开关机,反之云环境推荐临时关闭。
临时关闭swap分区
swapoff -a
- 1
永久关闭swap分区,注释掉fstab中包含swap的这一行即可
vi /etc/fstab
- 1
# /dev/mapper/centos-swap swap swap defaults 0 0
重启使其生效,重启可能导致cri-dockerd状态发生变化,实际部署中我没有选择重启,原因猜测是由于版本或配置没配好,可以通过重装docker与cri-dockerd再启动cri-dockerd使cri-dockerd状态正常
reboot
8、安装runc作为k8s运行环境
安装runc
sudo install -m 755 runc.amd64 /usr/local/bin/runc
- 1
# 检查是否安装成功
runc -v
- 1

9、Docker和cri-dockerd设置国内镜像加速(由于本次文件夹中以下要用到的软件包名称带有镜像地址,即使是局域网也建议配置相应镜像加速,防止安装完成后kubectl要求联网拉取软件包而忽略本地镜像)
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://tsvqojsz.mirror.aliyuncs.com"]
}
EOF
\# 找到第10行
vi /usr/lib/systemd/system/cri-docker.service
\# 修改为ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
重启Docker组件
systemctl daemon-reload && systemctl restart docker cri-docker.socket cri-docker
- 1
# 检查Docker组件状态
systemctl status docker cir-docker.socket cri-docker
- 1
10、检查hostname以及hosts
主节点
hostname为k8s-master
hostnamectl set-hostname k8s-master (从节点也需要设置)
- 1
or
vi /etc/hostname
- 1
添加域名映射(也可以直接修改hosts文件进行添加)
echo "192.168.**.35 k8s-slave01">> /etc/hosts
- 1
其他node
hostname为k8s-slave01
vi /etc/hostname
- 1
添加域名映射
echo "192.168.**.34 k8s-master" >> /etc/hosts
- 1
11、转发IPv4并让iptables看到桥接流
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
lsmod | grep br_netfilter
lsmod | grep overlay
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
# 如果init时仍提示iptables错误请执行
echo "1">/proc/sys/net/bridge/bridge-nf-call-iptables
echo "1">/proc/sys/net/ipv4/ip_forward
- 1
- 2
- 3
初始化控制平面节点/master
12、初始化主节点
在初始化之前需要通过kubeadm config images获得初始化需要的docker镜像(所有节点都需要):

安装镜像docker load -i **.tar
相关镜像文件存在5_kubeadm-images中。
执行初始化:
kubeadm init --node-name=k8s-master list--image-repository=registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock --apiserver-advertise-address=192.168.**.34 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
- 1
–image-repository=registry.aliyuncs.com/google_containers # 将下载容器镜像源替换为阿里云,否则因为网络原因会导致镜像拉不下来,一定会执行不成功。
–cri-socket=unix:///var/run/cri-dockerd.sock # 这是指定容器运行时,因为containerd也是Docker的组件之一,下载Docker会一并将containerd下载下来,在执行初始化时当Kubernetes检测到有多个容器运行时环境,就必须要手动选择一个。这里也可以看出containerd实际上比Docker更轻量得多。
–apiserver-advertise-address=192.168.56.50 # 为API server设置广播地址,这里选择本机的ipv4地址,这里不希望API SERVER设置在其他node上的话就不要改为其他地址。
–pod-network-cidr=10.244.0.0/16 # 指明 pod 网络可以使用的 IP 地址段,暂时不清楚的可以先不管就用这个值。
–service-cidr=10.96.0.0/12 # 为服务的虚拟 IP 地址另外指定 IP 地址段,暂时不清楚的可以先不管就用这个值。
问题:cordns:v1.10.1检查不存在,实际上cordns:v1.10.1已存在,但是是cordns:1.10.1。
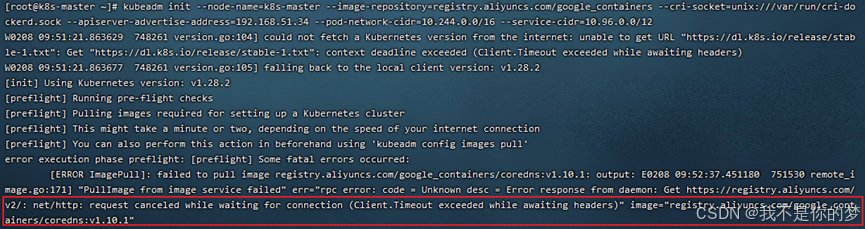
措施:修改cordns的tag。
docker tag registry.aliyuncs.com/google_containers/coredns:1.10.1 registry.aliyuncs.com/google_containers/coredns:v1.10.1
- 1
重新执行初始化命令
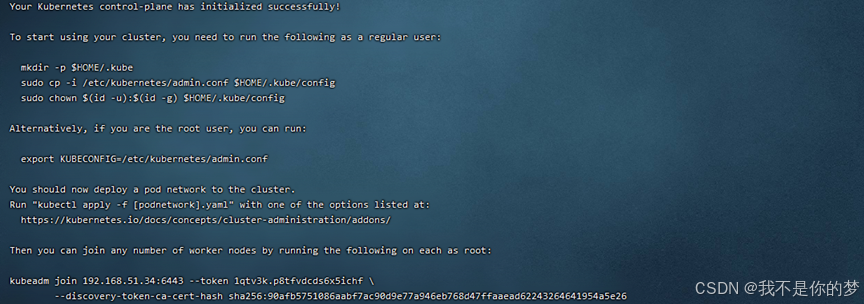
记录kubeadm join下面的信息,node join时需要,以上示例的相关信息是:
kubeadm join 192.168.51.34:6443 --token 1qtv3k.p8tfvdcds6x5ichf \
--discovery-token-ca-cert-hash sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26
- 1
- 2
- 3
如果忘记了可以使用kubeadm token list查询,该token存在24h,重新创建kubeadm token create --print-join-command,删除使用kubeadm token delete tokenid。
非root用户请执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 1
- 2
- 3
- 4
- 5
root用户直接执行
临时生效,重启后失效,不推荐。
export KUBECONFIG=/etc/kubernetes/admin.conf
- 1
永久生效,执行kubeadm reset后再次init也无需再次执行这条命令
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
- 1
执行永久生效命令之后需要source一下使其生效
source ~/.bash_profile
- 1
检测配置是否生效
echo $KUBECONFIG
/etc/kubernetes/admin.conf
- 1
- 2
- 3
13、安装配置网络插件
这里使用flannel,将kube-flannel.yml文件下载并上传到server上。
将相关镜像上传到server上安装。kube-flannel.yml和镜像文件存在于6_kube-flannel中。
(docker load -i xxx.tar加载到所有节点)
查询网卡
ifconfig
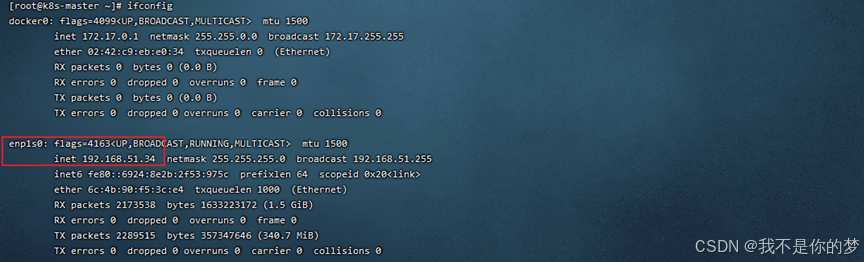
kube-flannel.yml默认会找enp1s0网卡,本次示例中34的网卡为enp1s0,无需修改,35的网卡为enp4s0。
//修改35的kube-flannel.yml,添加–iface=enp0s3进行指定(这里的enp0s3是ip对应的网卡,例如上图框中部分)。参数位置如下:
container:
......
command:
- /opt/bin/flanneld
arg:
- --ip-masq
- --kube-subnet-mgr
- --iface=enp4s0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
为Kubernetes配置flannel网络插件
kubectl apply -f /data/k8s/6_kube-flannel/kube-flannel.yml
- 1

cat /run/flannel/subnet.env
- 1
# 没有这个文件或文件夹的话则需要手动创建,内容同下
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Node节点加入Master
14、Node节点加入Master
14.1、将主节点机器中的/etc/kubernetes/admin.conf拷贝到从节点机器中
scp /etc/kubernetes/admin.conf 192.168.56.51:/etc/kubernetes/
- 1
# 不要忘记将admin.conf加入环境变量,这里直接使用永久生效。
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
- 1
- 2
- 3
拷贝时如果出现问题:
ECDSA host key for 192.168.55.187 has changed and you have requestd strict checking.Host key verification failed.
执行以下语句进行修复
ssh-keygen -R 192.168.55.187
- 1
14.2、执行join指令(初始化主节点成功后,会给出join命令)
例如:
kubeadm join 192.168.51.34:6443 --token by7t4x.da3f98dzrvjylykz --discovery-token-ca-cert-hash sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26 --cri-socket unix:///var/run/cri-dockerd.sock
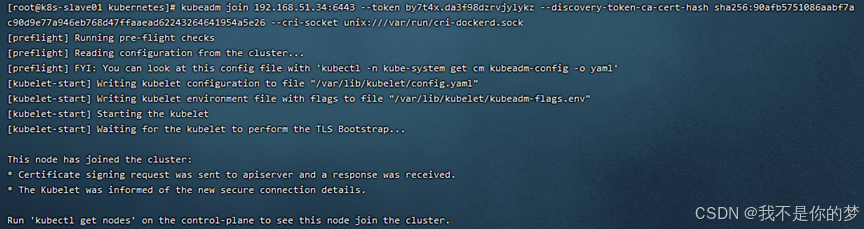
14.3、执行kubectl get nodes

k8s集群部署成功!!!
问题
问题一
kubectl get nodes
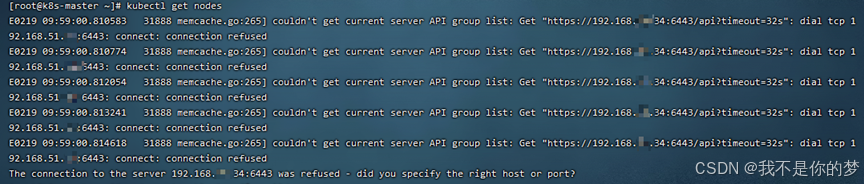
措施:检查swap是否关闭;检查防火墙是否开启6443端口
关闭swap

临时关闭防火墙

成功

问题二
kubectl get nodes
向集群添加k8s节点后查看该节点状态为NotReady

措施:
systemctl restart kubelet.service
systemctl restart docker.service
- 1
- 2
- 3
重启kubelet和docker

问题三
kubeadm join 192.168.51.34:6443 --token l2qlvh.and3fnjmzecueu9h --discovery-token-ca-cert-hash sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26 --cri-socket unix:///var/run/cri-dockerd.sock
将子节点加入k8s集群中时出现初始化超时的情况

措施:
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
- 1
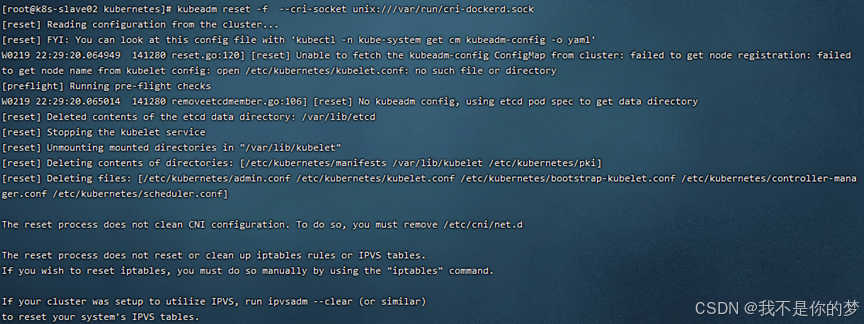
成功
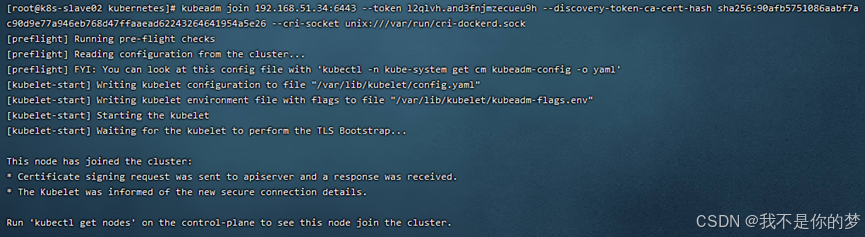

问题四
将主节点机器中的/etc/kubernetes/admin.conf拷贝到从节点机器中
scp /etc/kubernetes/admin.conf 192.168.55.187:/etc/kubernetes/
如果拷贝文件失败时,报错如下:
ECDSA host key for 192.168.55.187 has changed and you have requestd strict cheching.
Host key verification failed.
执行以下语句进行修复
ssh-keygen -R 192.168.55.187
- 1
快速删除
kubectl delete node k8s-slave01
kubectl delete node k8s-slave02
kubectl delete node k8s-master
- 1
- 2
- 3
从节点
rm -rf /etc/kubernetes/*
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
- 1
- 2
主节点
rm -rf /etc/kubernetes/*
rm -rf ~/.kube/*
rm -rf /var/lib/etcd/*
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
- 1
- 2
- 3
- 4
如果需要就要重新初始化k8s集群
kubeadm init --node-name=k8s-master --image-repository=registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock --apiserver-advertise-address=192.168.51.34 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
- 1
主节点
kubectl apply -f /data/k8s/6_kube-flannel/kube-flannel.yml
kubectl get pod -A
- 1
- 2
主节点
scp /etc/kubernetes/admin.conf 192.168.51.35:/etc/kubernetes/
scp /etc/kubernetes/admin.conf 192.168.51.36:/etc/kubernetes/
- 1
- 2
从节点
kubeadm join 192.168.51.34:6443 --token 1k9kdy.dvn2qbtd7rjar1ly \
--discovery-token-ca-cert-hash sha256:ff90d8ed41ae1902a839194f179a1c3ba8374a5197ea3111e10e5ca1c09fa442 --cri-socket unix:///var/run/cri-dockerd.sock
- 1
- 2
kubectl get pod -A
kubectl get nodes
- 1
- 2

