- 1洛谷B2002 Hello,World! /B2025 输出字符菱形_洛谷提交文言
- 2“33岁转行软件测试还来得及吗?”怎么去转行软件测试?_怎么转行学测试需要多久
- 3finalshell本地连接的账号密码在哪个配置文件
- 4yolov4训练自己的数据集(详细)_yolov4训练自己数据集
- 5Json文件编辑功能
- 6速盾:高防cdn和普通cdn的区别?
- 7AIGC内容分享(二):全球大模型技术与应用分析_aigc大会分享ppt
- 8词向量、预训练词向量、Word2Vec、Word Embedding概述_词向量一定要预先训练吗
- 9Oracle转Postgresql_oracle数据库如何转成postgres
- 10YARA扫描svchost.exe_yara 扫描进程
【理解机器学习算法】之岭回归Ridge - L2 Rgularization_ridge regression
赞
踩
Ridge 回归(Ridge Regression)也称作岭回归或脊回归,是一种专用于共线性数据分析的有偏估计回归方法。在多元线性回归中,如果数据集中的特征(自变量)高度相关,也就是说存在共线性(Multicollinearity),那么模型参数估计将变得不稳定,输出结果的方差会非常大。Ridge 回归通过在损失函数中增加一个正则项来解决这个问题。
Ridge 回归的损失函数包括两部分:数据的预测误差和一个与系数大小相关的正则化项。该正则化项是系数的L2范数乘以一个称为 `alpha` 的参数。Ridge 回归的目标是最小化以下的损失函数:
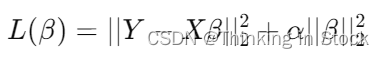
这里:
- ![]() 表示预测误差,即实际观测值与模型预测值之间差的平方和。
表示预测误差,即实际观测值与模型预测值之间差的平方和。
- ![]() 是系数向量的L2范数的平方,也就是各系数平方和。
是系数向量的L2范数的平方,也就是各系数平方和。
- ![]() 是正则化强度,控制着正则化项的大小。
是正则化强度,控制着正则化项的大小。
正则化参数 `alpha` 决定了你想对模型系数的大小施加多大的惩罚。`alpha` 的值越大,对系数的惩罚越重,系数越倾向于变小,模型的复杂度就越低,这有助于防止模型过拟合。相反,如果 `alpha` 设得太小,正则化的效果就会弱,可能不能有效地处理共线性(Multicollinearity)问题。
Ridge 回归的系数
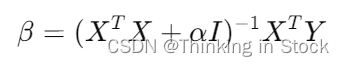
其中![]() 是单位矩阵。
是单位矩阵。
在实践中,Ridge 回归特别适用于当你有很多相互关联的预测变量时,因为它会保留所有的预测变量,但是会减小变量的系数,使模型对数据中的随机误差不那么敏感。
由于正则化,Ridge 回归能够提高模型的泛化能力,但同时也会引入一定的偏差。因此,选择合适的 `alpha` 值是应用Ridge回归的关键。这通常通过交叉验证来完成,目标是找到可以使交叉验证误差最小化的 `alpha` 值。
- import numpy as np
-
- # 定义 Ridge 回归函数
- def ridge_regression(X, y, alpha):
- # 为特征矩阵增加一列全为1的截距项
- X = np.concatenate((np.ones((X.shape[0], 1)), X), axis=1)
-
- # 计算与特征数量相同大小的单位矩阵(包括截距项)
- # 并且不对截距项进行正则化处理
- I = np.eye(X.shape[1])
- I[0, 0] = 0 # 不对截距项进行正则化
-
- # 使用 Ridge 回归公式计算系数
- beta = np.linalg.inv(X.T @ X + alpha * I) @ X.T @ y
- return beta
-
- # 示例用法:
- # 假设 X_train 是您的特征矩阵,y_train 是您的目标向量
- # alpha 是您选择的正则化参数
- # beta = ridge_regression(X_train, y_train, alpha)
-
- # 注意在应用 ridge 回归之前应当对 X_train 进行标准化处理(每个特征的均值为0,方差为1)

使用sklearn
以下是用 Python 中的 sklearn 使用 Ridge 回归的方法:
- from sklearn.linear_model import Ridge
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import mean_squared_error
- import numpy as np
-
- # 假设你有一个数据集 `X` 和 `y`
-
- # 将数据集分割成训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 标准化特征
- scaler = StandardScaler()
- X_train_scaled = scaler.fit_transform(X_train)
- X_test_scaled = scaler.transform(X_test)
-
- # 使用 alpha 值初始化 Ridge 回归模型
- ridge_model = Ridge(alpha=1.0) # 你可以根据需要调整 alpha 值
-
- # 拟合模型
- ridge_model.fit(X_train_scaled, y_train)
-
- # 使用模型进行预测
- y_pred = ridge_model.predict(X_test_scaled)
-
- # 计算均方误差
- mse = mean_squared_error(y_test, y_pred)
- print(f'均方误差: {mse}')
-
- # 系数
- print(f'系数: {ridge_model.coef_}')
-
- # 截距
- print(f'截距: {ridge_model.intercept_}')
记住选择正确的 alpha 值是非常关键的。更高的 alpha 值增加了正则化的量,这可以防止过拟合,但也可能导致欠拟合。交叉验证技术,如 sklearn 中的 RidgeCV,可以帮助找到最优的 alpha 值。
下图显示了选择不同的alpha对回归系数的影响:

在图中:
- 蓝色点代表 `alpha=1` 时模型的系数。
- 橙色点对应 `alpha=14` 时的系数。
- 绿色点显示 `alpha=100` 时的系数。
随着 `alpha` 值的增加,Ridge 回归更加强调保持系数的小幅度,我们通常期望系数的绝对值会减少,这通常表现为点在 y 轴上向零靠近。这有助于减少模型的复杂性并防止过拟合。
从图中可以清楚地看出,随着 `alpha` 从1增加到100,系数缩小向零收敛,这与增加 Ridge 回归中正则化强度的效果一致。水平轴代表系数的索引。
使用GridSearchCV找到最佳的alpha
使用 sklearn 的 GridSearchCV 进行 Ridge 回归的方法如下,我们需要定义一个 alpha 值范围,在这个范围内找到最佳的alpha,然后对参数网格进行交叉验证的网格搜索。以下是 Python 中的操作方法:
- from sklearn.linear_model import Ridge
- from sklearn.model_selection import GridSearchCV
- from sklearn.preprocessing import StandardScaler
- from sklearn.pipeline import make_pipeline
- from sklearn.metrics import mean_squared_error
-
- from sklearn.model_selection import train_test_split
-
- # 准备数据,将其分割为训练集和测试集,必要时进行标准化。使用 make_pipeline 确保标准化是交叉验证过程的一部分,避免数据泄漏。
- # 假设 `X` 是特征矩阵,`y` 是目标向量
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义参数网格,指定希望搜索的 alpha 值的范围
- param_grid = {'ridge__alpha': [0.01, 0.1, 1, 10, 100]}
-
- # 创建一个包含标准化和 Ridge 回归模型的流水线。这里的 'ridge' 是在流水线中引用 Ridge 回归模型的名称
- pipeline = make_pipeline(StandardScaler(), Ridge())
-
- # 使用流水线、参数网格和交叉验证的折数初始化 GridSearchCV
- grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='neg_mean_squared_error')
-
- # 在训练数据上拟合 GridSearchCV
- grid_search.fit(X_train, y_train)
-
- # 拟合后,可以检查找到的最佳 alpha 值和相应的分数
- print(f'最佳 alpha: {grid_search.best_params_}')
- print(f'最佳分数: {grid_search.best_score_}')
-
- # 使用最佳估计器进行预测并评估它们
- y_pred = grid_search.best_estimator_.predict(X_test)
-
-
- mse = mean_squared_error(y_test, y_pred)
- print(f'测试集上的均方误差: {mse}')
-
记得将 X、y 和 alpha 范围替换为实际的数据和想要测试的特定值。GridSearchCV 将系统地进行多种参数组合的调整,交叉验证结果,并确定哪种调整提供了最佳性能。
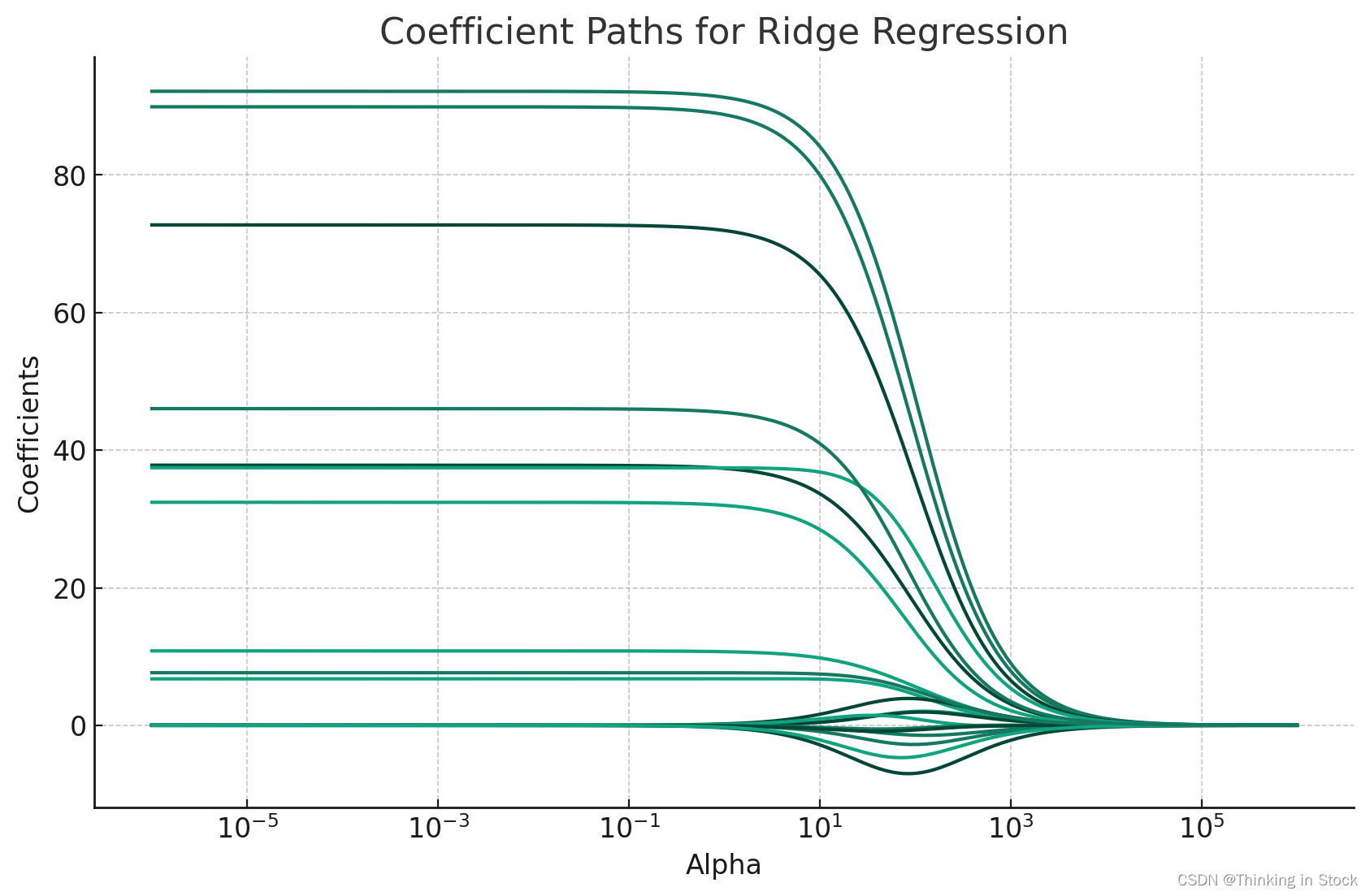
画出系数变化路径:
在 Ridge 和 Lasso回归等线性模型中,“系数路径”(Coefficient Paths)这个术语指的是模型系数作为正则化强度参数(通常在 Ridge 中表示为![]() 、在 Lasso 中表示为
、在 Lasso 中表示为 ![]() 的函数的轨迹。随着正则化强度的增加,系数的绝对值倾向于减小,有些可能达到零(尤其是在 Lasso 中,它可以引入稀疏性)。
的函数的轨迹。随着正则化强度的增加,系数的绝对值倾向于减小,有些可能达到零(尤其是在 Lasso 中,它可以引入稀疏性)。
系数路径的重要性
1. 解释性:它们提供了洞察,让我们了解随着模型变得更加正则化,每个特征的重要性是如何变化的。这有助于理解特征的稳定性和相关性。
2. 模型选择:通过可视化系数路径,您可以更好地理解正则化对您的模型的影响,并选择适当的正则化水平![]() 或
或![]() ,该水平平衡了偏差和方差,可能使用交叉验证等技术。
,该水平平衡了偏差和方差,可能使用交叉验证等技术。
3. 特征选择:在 Lasso 回归的情况下,系数路径可以帮助进行特征选择,因为随着 ![]() 的增加,系数较早归零的特征被认为是不那么重要的。
的增加,系数较早归零的特征被认为是不那么重要的。
如何生成系数路径
要生成系数路径,您通常需要在一个广泛的范围内变化正则化参数,对每个值拟合模型,跟踪系数如何变化。这可以通过折线图可视化,其中 x 轴代表正则化参数的值(通常在对数尺度上),y 轴代表系数的值。
使用 `sklearn`
在 Python 的 `sklearn` 库中,您可以使用 `Ridge` 和 `Lasso` 等模型以及像 `RidgeCV` 或 `LassoCV` 这样的工具进行交叉验证选择正则化参数。尽管 `sklearn` 没有直接提供绘制系数路径的函数,但您可以通过手动记录用不同的 ![]() 或
或 ![]() 值拟合的模型的系数来轻松生成它们。
值拟合的模型的系数来轻松生成它们。
这里提供了使用 Ridge 回归的一个基本示例。
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.linear_model import Ridge
- from sklearn.preprocessing import StandardScaler
-
- # Assuming X and y are your features and target variable
- # Standardize features
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # Define a range of alpha values
- alphas = np.logspace(-6, 6, 300)
-
- # Initialize list to store coefficients
- coef_paths = []
-
- for alpha in alphas:
- ridge = Ridge(alpha=alpha)
- ridge.fit(X_scaled, y)
- coef_paths.append(ridge.coef_)
-
- # Convert list of coefficients into a numpy array for easier plotting
- coef_paths = np.array(coef_paths)
-
- # Plotting
- for i in range(coef_paths.shape[1]):
- plt.plot(alphas, coef_paths[:, i])
-
- plt.xscale('log')
- plt.xlabel('Alpha')
- plt.ylabel('Coefficients')
- plt.title('Coefficient Paths')
- plt.show()