
- 1【无标题】Unity HDRP渲染管线 材质与着色器【Shader/Lit】简单说明_unity hdrp materail type
- 2Unity-C#基础学习02_unity =>
- 3Ubuntu18.04安装ROS Melodic出现gpg: invalid key resource URL_gpg: invalid key resource url '/etc/apt/trusted.gp
- 4Win11安装CUDA教程
- 5译:在 CentOS 7上安装Anaconda_centos7安装anaconda出现symbol __strtof128_nan, version
- 6EAP-TLS实验之Ubuntu20.04环境搭建配置(FreeRADIUS3.0)(一)
- 7 JS进阶篇--怎样实现图片的懒加载以及jquery.lazyload.js的使用
- 8【Python】【进阶篇】十三、Tkinter的Event事件处理_tkinter event参数
- 9mybatis-generator构建表问题_ignorequalifiersatruntime
- 10unity shader可视化工具——Shader Graph_unity的shader graph
【教程】LLM集成进LangChain工具,并实现本地知识库的问答_langchain from_chain_type
赞
踩
0. Introduction:
LangChain提供了丰富的生态,可以非常方便的封装自己的工具,并接入到LangcChain的生态中,从而实现语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
本文将介绍下如何将本地的大模型服务集成进LangChain工具链中。
1. 在本地部署LLM,并搭建API服务
利用FastAPI和uvicorn构建本地化部署大语言模型的接口服务,实现大模型的API接口调用。
参考我的另一篇文章:【FastAPI】利用FastAPI构建大模型接口服务
2. 测试API服务

测试完成,API成功返回LLM的回答,接下来进入下一步,将API以自定义LLM的方式封装进LangChain。
3. 封装LLM到LangChain工具
参考官方文档 How to write a custom LLM wrapper,只需要继承LangChain的LLM方法,并且实现_call方法即可。
官方提供的一个简单的示例:
from langchain.llms.base import LLM from typing import Optional, List, Mapping, Any class CustomLLM(LLM): n:int @property def _llm_type(self) -> str: return "custom" def _call(self,prompt:str,stop:Optional[List[str]]=None) -> str: if stop is not None: raise ValueError("stop kwargs are not permitted") return prompt[:self.n] @property def _identifying_params(self) -> Mapping[str, Any]: """Get the identifying parameters.""" return {"n": self.n}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我们根据自己实际的API接口,修改这个示例的call方法:
class BaiChuan(LLM): history = [] def __init__(self): super().__init__() @property def _llm_type(self) -> str: return "BaiChuan" def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str: data={'text':prompt} url = "http://0.0.0.0:6667/chat/" response = requests.post(url, json=data) if response.status_code!=200: return "error" resp = response.json() if stop is not None: response = enforce_stop_tokens(response, stop) self.history = self.history+[[None, resp['result']]] return resp['result']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
测试一下是否封装成功:
llm = BaiChuan()
llm('你好,你是谁?')
- 1
- 2
output:
'您好!作为一个大语言模型,我可以回答您的各种问题并帮助您解决问题。请问有什么我可以帮到您的吗?'
- 1
好了,到这里我们成功将BaiChuan13B模型给封装进LangChain工具链中。接下来我们将利用LangChain实现本地知识库问答功能。
4. 实现本地知识库问答:
LangChain实现基于本地私有知识库问答的流程:
加载文件 → 读取文件 → 文本分割 → 文本向量化 → 问题向量化 → 在文本向量中匹配与问题最相近的TopK → 匹配出的文本作为上下文与问题一起添加进prompt → 提交给LLM生成回答
4.1 载入本地文档,并切片成若干小片段
LangChain提供了Docx、PPT、PDF等格式文件的加载器、分片器:
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = Docx2txtLoader("新闻.docx")
data = loader.load()
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=128)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里LangChain提供的RecursiveCharacterTextSplitter文本分片器将该Word文档切分为了每段有256个tokens,片段与片段之间有128个Tokens重叠的文本小片段。chunk_size是片段长度,chunk_overlap是片段之间的重叠长度。设置重叠部分是为了避免在切片的过程中,丢失一部分信息。
拿出一个小片段看看:
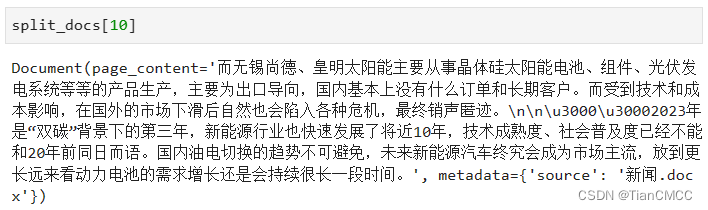
4.2 文本向量化
基于开源的预训练的Embedding语言模型,对文本进行向量化。
Embedding方法分类为:
- word2vec(基于seq2seq的神经网络结构)
- Glove(词共现矩阵)
- Item2Vec(推荐中的双塔模型)
- FastText(浅层神经网络)
- ELMo(独立训练双向,stacked Bi-LSTM架构)
- GPT(从左到右的单向Transformer)
- BERT(双向transformer的encoder,attention联合上下文双向训练)
开源的预训练Embedding模型有:
- Text2vec文本表征及相似度计算:包括text2vec-large-chinese(LERT,升级版)、base(CoSENT方法训练,MacBERT)两个模型。这个模型也使用了word2vec(基于腾讯的800万中文词训练)、SBERT(Sentence-BERT)、CoSENT(Cosine Sentence)三种表示方法训练
- OpenAI的Embeddings:这是OpenAI官方发布的Embeddings的API接口。目前有2代产品。目前主要是第二代模型:text-embedding-ada-002。它最长的输入是8191个tokens,输出的维度是1536
- 百度的ernie-3.0-base-zh:https://github.com/PaddlePaddle/PaddleNLP、ERNIE三个版本进化史
- SimCSE:https://github.com/princeton-nlp/SimCSE
- 其他模型:embedding模型 · 魔搭社区
- M3E:Moka Massive Mixed Embedding的缩写,由MokaAI训练,训练脚本使用 uniem,评测BenchMark使用MTEB-zh,通过千万级 (2200w+) 的中文句对数据集进行训练。
这里我们使用HuggingFace社区里面的ERNIE模型,并且使用HuggingFaceEmbeddings,对文本进行向量化。
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
EMBEDDING_MODEL = "/workdir/model/text2vec_ernie/"
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL)
embeddings.client = sentence_transformers.SentenceTransformer(embeddings.model_name, device='cuda')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.3 FAISS向量数据库
Faiss的全称是Facebook AI Similarity Search。是一个开源库,针对高维空间中的海量数据,提供了高效且可靠的检索方法。
在本文中,我们将用FAISS向量数据库,存储每个文本片段的向量,并实现后续的向量相似度的高效计算。
Step1:将切分好的文本片段转换为向量,并存入FAISS中:
from langchain.vectorstores import FAISS
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("/workdir/temp/faiss/") # 指定Faiss的位置
- 1
- 2
- 3
- 4
Step2:载入FAISS数据库:
db = FAISS.load_local("/workdir/temp/chroma/",embeddings=embeddings)
- 1
Step3:将问题也转换为文本向量,并在FAISS中查找最为相近的TopK
question = "新能源行业发展了多久?"
similarDocs = db.similarity_search(question, include_metadata=True, k=2)
for x in similarDocs:
print(x)
- 1
- 2
- 3
- 4
- 5
- 6
输出如下,可见找出的信息与用户提出的问题匹配度还是挺高的。
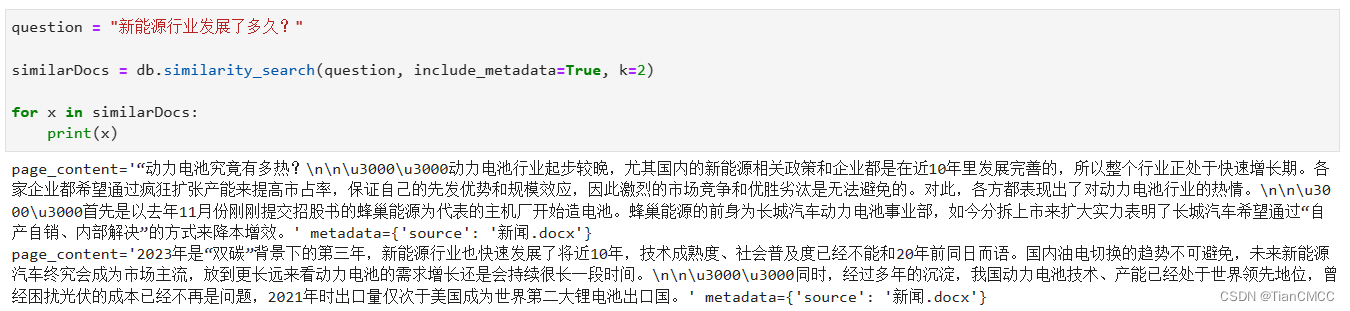
4.4 LLM基于本地知识库回答
直接调用LangChain的RetrievalQA,实现基于上下文的问答。省去了写prompt的步骤。
from langchain.chains import RetrievalQA
import IPython
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
query = "新能源行业发展了多久?"
print(qa.run(query))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出及知识库中的原文如下,可见回答的非常准确~
Word中的原文:

LLM的回答:


