
详解Python正则表达式(含丰富案例)
赞
踩
前言:正则表达式在网络爬虫、数据分析中有着广泛使用,掌握正则表达式能够达到事半功倍的效果。本文详细介绍正则表达式中各种规则及其符号含义,并结合Python中的Re库进行演示,由浅入深,即学即练即用,内容丰富,非常适合初学者。
正则表达式(regular expression)就是用一组由字母和符号组成的“表达式”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征。比如表达式“xy+” 描述的特征是“一个 ‘x’ 和 至少一个 ‘y' ”,那么‘xy',‘xyy', ‘xyyyyyyy'都符合这个特征。
正则表达式主要应用场景
-
验证字符串是否符合指定特征,比如验证用户名或密码是否符合要求、是否是合法的邮件地址等;
-
用来查找字符串,从一个长的文本中查找符合指定特征的字符串,比查找固定字符串更加灵活方便;
-
用来替换,比普通的替换更强大。
正则表达式的规则
(1)普通字符
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是"普通字符"。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
例1:表达式 “c”,在匹配字符串 “abcde” 时,匹配结果是:成功;匹配到的内容是:“c”;匹配到的位置是:开始于2,结束于3。(包含开始位置,不包含结束位置)
例2:表达式 "bcd",在匹配字符串"abcde"时,匹配结果是:成功;匹配到的内容是:"bcd";匹配到的位置是:开始于1,结束于4。
(2)转义字符
-
一些不便书写的字符,采用在前面加“\” 的方法。例如制表符、换行符等;
-
一些有特殊用处的标点符号,在前面加“\” 后,代表该符号本身。例如{,}, [, ], /, \, +, *, ., $, ^, |, ? 等;
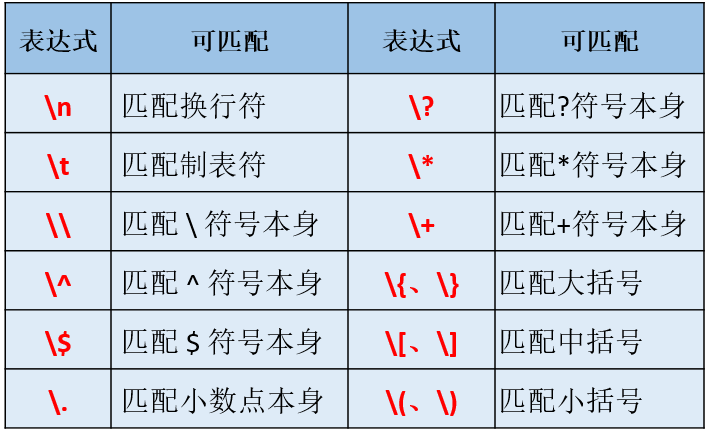
转义字符的匹配方法与“普通字符”类似,也是匹配与之相同的一个字符。
例如:表达式 "\$d",在匹配字符串 "abc$de" 时,匹配结果是:成功;匹配到的内容是:"$d";匹配到的位置是:开始于3,结束于5。
(3)能够与 '多种字符' 匹配的表达式
正则表达式中的一些表示方法,可以匹配 ‘多种字符’ 中的任意一个字符。例如,表达式"\d" 可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。

例如:表达式 "\d\d",在匹配 "abc123" 时,匹配的结果是:成功;匹配到的内容是:"12";匹配到的位置是:开始于3,结束于5。
(4)自定义能够匹配 '多种字符' 的表达式
使用方括号 [ ] 包含一系列字符,能匹配其中任意一个字符。用 [^ ] 包含一系列字符,则能匹配其中字符之外的任意一个字符。虽然可以匹配其中任意一个,但是只能是一个,不是多个。

例如:表达式 "[bcd][bcd]" 匹配 "abc123" 时,匹配的结果是:成功;匹配到的内容是:"bc";匹配到的位置是:开始于1,结束于3。
(5)修饰匹配次数的特殊符号

例如:表达式 "\d+\.?\d*" 在匹配 "It costs $12.5" 时,匹配的结果是:成功;匹配到的内容是:"12.5";匹配到的位置是:开始于10,结束于14。
(6)一些代表抽象意义的特殊符号

例1:表达式 "^aaa" 在匹配 "xxxaaaxxx" 时,匹配失败。因为 "^" 要求与字符串开始的地方匹配,只有当 "aaa" 位于字符串的开头的时候,"^aaa" 才能匹配,比如:"aaaxxxxxx"。
例2:表达式 "aaa$"在匹配 "xxxaaaxxx" 时,匹配失败。因为"$" 要求与字符串结束的地方匹配,只有当"aaa"位于字符串的结尾的时候,"aaa$"才能匹配,比如:"xxxxxxaaa"。
例3:表达式 "Tom|Jack"在匹配字符串 "I'mTom, he is Jack" 时,匹配结果是:成功;匹配到的内容是:"Tom";匹配到的位置是:开始于4,结束于7。匹配下一个时,匹配结果是:成功;匹配到的内容是:"Jack";匹配到的位置时:开始于15,结束于19。
例4:表达式 "(go\s*)+"在匹配 "Let'sgo gogo!"时,匹配结果是:成功;匹配到内容是:"gogogo";匹配到的位置是:开始于6,结束于14。
例5:表达式 "¥(\d+\.?\d*)"在匹配 "$10.9,¥20.5"时,匹配的结果是:成功;匹配到的内容是:"¥20.5";匹配到的位置是:开始于6,结束于10。单独获取括号范围匹配到的内容是:"20.5"。
思考题:写出满足下列要求的正则表达式
-
仅含6位数字的字符串
-
18位身份证号码(最后一位可能包含X)
-
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线)
匹配次数中的贪婪与非贪婪
在使用修饰匹配次数的特殊符号时,如“?”,“*”, “+”等,可以使同一个表达式能够匹配不同的次数,具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配,这种匹配原则就叫作"贪婪" 模式 。例如,针对文本“dxxxdxxxd”,下列表达式匹配结果如下。

在修饰匹配次数的特殊符号后再加上一个"?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "不匹配"。这种匹配原则叫作"非贪婪" 模式。如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,非贪婪模式会最小限度的再匹配一些,以使整个表达式匹配成功。例如,针对文本“dxxxdxxxd”,下列表达式匹配结果如下。

Python中的正则表达式库 - re
-
re库是Python的标准库,不需要额外安装,主要用于字符串匹配
-
调用方式:import re
-
re 库采用raw string类型表示正则表达式,rawstring是不包含对转义符再次转义的字符串。例如:r'[1‐9]\d{5}’
-
re库也可以采用string类型表示正则表达式,但更繁琐,例如“'[1‐9]\\d{5}'”
-
当正则表达式包含转义符时,建议使用raw string
re库的主要功能函数
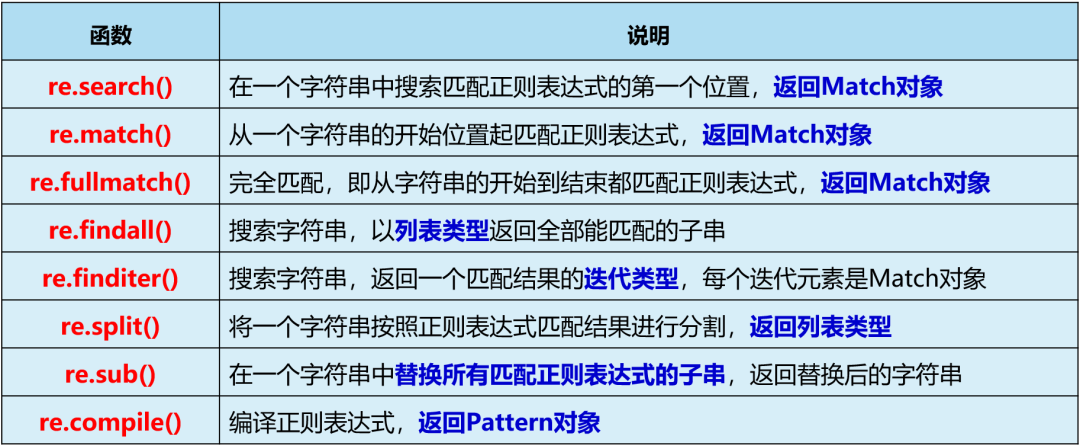


注意group()和groups()的区别,一个是返回匹配的字符串,一个是返回各部分匹配内容组成的元组。当表达式中没有圆括号时,groups()返回的是空元组,当存在圆括号时,有几个圆括号groups()返回的元组里就有几个元素。





正则表达式案例-验证用户名
编写程序实现下述功能,提示用户输入用户名,要求用户名以字母开头,长度不少于3位,只能包含字母、数字、下划线,如果用户输入符合要求,则提示注册成功,否则提示用户名不符合要求,请重新输入,一直循环直到用户名符合要求为止。程序执行效果如下图所示。

参考代码如下:
- import re # 导入正则表达式库
- name = input("请输入用户名,以字母开头,长度不少于3位,只能包含字母、数字、下划线:") # 提示用户输入
- match = re.match(r"^[a-zA-Z]\w{2,}$", name) # 验证输入是否符合要求
- while match is None: # 如果不符合要求,则循环
- print("用户名不符合要求,请重新输入:", end=" ") # 提示用户名不符合要求
- name = input() # 重新获取用户输入
- match = re.match(r"^[a-zA-Z]\w{2,}$", name) # 验证输入是否符合要求
- print("恭喜你, {} ,注册成功!".format(name)) # 提示注册成功
思考:
- 正则表达式前面的^能够省略?为什么?
- 有没有其它等价的正则表达式写法?
- 正则表达式最后的$能否省略?为什么?
正则表达式案例-编程语言排行
-
数据来源:https://www.tiobe.com/tiobe-index/网页源代码,保存到”编程语言排行.txt”文件。
-
部分内容截图如下,排行前十的编程语言数据存放在series属性里,每项编程语言包含名称(name)和数据(data)两部分内容,其中data部分包含该编程语言各个月份编程语言所占比例,。

- import re # 正则表达式
- import csv # csv文件操作
- with open("编程语言排行.txt", mode="r", encoding="utf-8") as fp: # 打开指定文件
- text = fp.read() # 读取文件内容
- content = " ".join(re.findall(r"series: (.*?)\}\);", text, re.DOTALL)) # 获取所有编程语言数据
- total_content = re.findall(r"({.*?})", content, re.DOTALL) # 获取各个编程语言的具体数据
- with open("lang.csv", mode="w", encoding="utf-8", newline="") as fp: # 对数据进行处理并保存到文件
- writer = csv.DictWriter(fp, ['name', 'value', 'date'])
- writer.writeheader() # 写入标题
- for item in total_content:
- name = " ".join(re.findall(r"name : '(.*?)'", item, re.DOTALL))
- temp_datas = re.findall(r"\[Date.UTC(.*?)\]", item, re.DOTALL) # 获取不同时间的热度信息
- for data in temp_datas:
- data = data.replace(" ", "").replace("(", "").replace(")", "")
- value = data.split(",")[-1] # 热度值
- date = data.split(",")[:-1] # 日期信息
- writer.writerow({"name": name, "value": value, "date": "{}-{:02d}-{:02d}".format(date[0], int(date[1]) + 1, int(date[2]))})
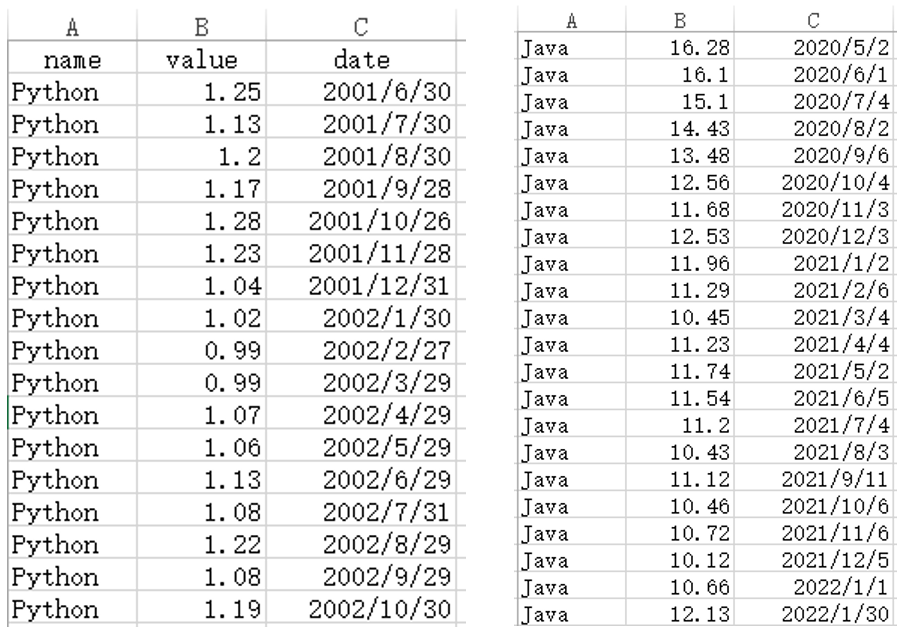
部分数据截图效果如下:
完整课件下载网址:https://download.csdn.net/download/Dream_Gao1989/81021441

