
强化学习算法SAC的学习探究及基于百度PARL的实战_sac算法
赞
踩
本文要点:
- SAC算法的理解
- 基于百度飞桨PARL的算法实战
- 个人学习心得
- 参考文献及学习资源
1. SAC算法的理解
SAC即Soft Actor-Critic(柔性致动/评价),它是一种基于off-policy和最大熵的深度强化学习算法,其由伯克利和谷歌大脑的研究人员提出。作为目前高效的model-free算法,SAC是深度强化学习中对于连续动作控制的又一经典algorithm,十分适用于真实世界中的机器人任务学习。
SAC基于最大熵强化学习框架,其中的熵增目标函数如下所示:
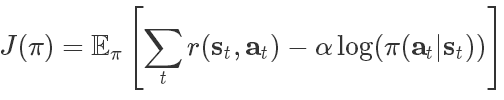
其中s 和a 是状态和行动,期望则包含了策略和来自真实系统的动力学性能。换句话说,优化策略不仅最大化期望(第一项),同时还最大化期望的熵(第二项)。其中的参数α平衡了这两项对于结果的影响,当α为0时上式就退化为传统的预期回报目标函数。研究人员认为可以将上述目标函数视为熵约束的最大化预期回报,通过自动学习α参数来代替超参数。我们可以从多个角度解释这一目标函数。既可以将熵看作是策略的先验,也可以将其视为正则项,同时也可以看作是探索(最大化熵)和利用(最大化回报)间的平衡。SAC通过神经网络参数化高斯策略和Q函数来最大化这一目标函数,并利用近似动力学编程来进行优化。
SAC采用Soft policy iteration,而Soft policy iteration可以看成是policy iteration的soft版本,policy iteration的基本步骤是交替地运行policy evaluation和policy improvement两个步骤,直至收敛。也就是说,它先固定policy π去提升Q value,然后固定Q value去提升policy π。这个思路很像EM算法。
SAC算法流程及伪代码如下所示:

SAC模型同时学习action value Q、state value V和policy π。V中引入Target V,供Q学习时使用;Target Network使学习有章可循、效率更高。Q有两个单独的网络,选取最小值供V和π学习时使用,希望减弱Q的过高估计。π学习的是分布的参数:均值和标准差;这与DDPG不同,DDPG的π是Deterministic的,输出直接就是action,而SAC学习的是个分布,学习时action需要从分布中采样,是Stochastic的。
2.基于百度飞桨PARL的算法实战
在百度飞桨PaddlePaddle的PARL算法库中已提供了SAC的实现样例,可访问PaddlePaddle-PARL的GitHub库链接获取相应样例源码,因为使用了PARL封装好的算法,SAC整个实现显得很整洁,实现样例共分为如下三个文件:
- mujoco_agent.py
- mujoco_model.py
- train.py
关于三个文件的源码分析在此不作展开说明,若对基于PARL编程较陌生,读者朋友可自行学习百度强化学习7日打卡营的课程后快速上手基于PARL的强化学习编程,本文基于百度飞桨PARL的SAC算法实战项目请访问链接https://aistudio.baidu.com/aistudio/projectdetail/647210查阅。
3. 个人学习心得
SAC的关键是引入最大熵,优化soft value。最大熵会使action探索能力很强,模型效果更平稳,但注意需要场景也是接受较强的探索。从结构上讲,SAC模型冗余,在学习π和soft Q的情况下,又学习了soft V。由于面临的是连续动作空间,求期望的地方,采取了采样近似,需要批次处理的数据集更加完整。优化技巧比较晦涩,感觉很难通用。
4. 参考文献及学习资源
[2] Soft Actor-Critic Algorithms and Applications.
[3]OpenAI上强化学习算法原理文章: 关于SAC论文的解析.

