
- 1如何在群晖NAS中使用frp进行内网穿透_chmifrp
- 2大数据分析案例-基于XGBoost算法预测航空机票价格_大数据航空机票
- 3Python Flask-Login:构建强大的用户认证系统_flask框架下的登录验证
- 4文件权限管理,特殊权限及ACL权限_umask770
- 5js Math.random() 随机数 1-10之间
- 6怎么理解Web 3.0?
- 7根据yolo训练的csv文件绘制模型对比曲线_yolov5 根据result.txt画出loss图代码
- 8【数学建模笔记】【第七讲】多元线性回归分析(二):虚拟变量的设置以及交互项的解释,以及基于Stata的普通回归与标准化回归分析实例_stata虚拟变量回归命令
- 9搭建mock服务器(微信小程序)
- 108.计算球的体积(编程入门题-C/C++&Java&Python实现)_python输出对应的球的体积,输出一行,计算结果保留三位小数。
MySQL索引之全文索引(FULLTEXT)
赞
踩
MySQL创建全文索引
使用索引时数据库性能优化的必备技能之一。在MySql数据库中,有四种索引:聚焦索引(主键索引)、普通索引、唯一索引以及我们这里将要介绍的全文索引(FUNLLTEXT INDEX)。
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用【分词技术】等多种算法智能分析出文本文字中关键词的频率和重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
在MySql中,创建全文索引相对比较简单。例如:我们有一个文章表(article),其中有主键ID(id)、文章标题(title)、文章内容(content)三个字段。现在我们希望能够在title和content两个列上创建全文索引,article表及全文索引的创建SQL语句如下:
CREATE TABLE `article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `title` (`title`,`content`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
上面就是在创建表的同时创建全文索引的SQL示例。此外,如果我们要给已经存在的表的指定字段创建全文索引,同样以article表为例,我们可以使用如下SQL语句进行创建:
ALTER TABLE article ADD FULLTEXT INDEX fulltext_article(title,content);
在MySql中创建全文索引之后,现在就该了解如何使用了。众所周知,在数据库中进行模糊查询是使用like关键字进行查询的,例如:
SELECT * FROM article WHERE content LIKE ‘%查询字符串%’;
那么,我们在使用全文索引也这样使用吗?当然不是,我们必须使用特有的语法才能使用全文索引进行查询,例如,我们想要在article表的title和content列中全文检索指定的查询字符串,我们可以如下编写SQL语句:
SELECT * FROM article WHERE MATCH(title,content) AGAINST (‘查询字符串’);
强烈注意:MySql自带的全文索引只能用于数据库引擎为MYISAM的数据表,如果是其他数据引擎,则全文索引不会生效。此外,MySql自带的全文索引只能对英文进行全文检索,目前无法对中文进行全文检索。如果需要对包含中文在内的文本数据进行全文检索,我们需要采用Sphinx(斯芬克斯)/Coreseek技术来处理中文。
注:目前,使用MySql自带的全文索引时,如果查询字符串的长度过短将无法得到期望的搜索结果。MySql全文索引所能找到的词默认最小长度为4个字符。另外,如果查询的字符串包含停止词,那么该停止词将会被忽略。
注:如果可能,请尽量先创建表并插入所有数据后再创建全文索引,而不要在创建表时就直接创建全文索引,因为前者比后者的全文索引效率要高。
一种特殊的索引,它会把某个数据表的某个数据列出现过的所有单词生成一份清单。
alter table tablename add fulltext(column1,column2)
只能在MyISAM数据表中创建
少于3个字符的单词不会被包含在全文索引里,可以通过修改my.cnf修改选项
ft_min_word_len=3
重新启动MySQL服务器,用
repair table tablename quick 为有关数据表重新生成全文索引
select * from tablename
where match(column1,column2) against('word1 word2 word3')>0.001
match ... against 把column1,column2数据列中至少包含word1,word2,word3三个单词之一的数据记录查找到,在关键字match后的数据列必须 跟创建全文索引的数据列相同,检索词不区分大小写和先后顺序,少于3个字符的单词通常被忽略。match... against ...表达式返回一个浮点数作为它本身的求值结果,这个数字反映了结果记录与被检索单词的匹配程度。如果没有匹配到任何记录,或者匹配到的结果记录太多反 而被忽略,表达式将返回0,表达式>0.001的作用是排除match的返回值太小的结果记录。
select *,match(column1,column2) against ('word1 word2 word3') as mtch
from tablename
having mtch>0.01
order by mtch desc
limit 5
找出最匹配的5条记录,在where字句中不能使用假名,所以用having
布尔全文搜索的性能支持以下操作符:
-
- +word:一个前导的加号表示该单词必须 出现在返回的每一行的开头位置。
-
- -word: 一个前导的减号表示该单词一定不能出现在任何返回的行中。
-
- (无操作符):在默认状态下(当没有指定 + 或–的情况下),该单词可有可无,但含有该单词的行等级较高。这和MATCH() ... AGAINST()不使用IN BOOLEAN MODE修改程序时的运作很类似。
-
- > <这两个操作符用来改变一个单词对赋予某一行的相关值的影响。 > 操作符增强其影响,而 <操作符则减弱其影响。请参见下面的例子。
-
- ( )括号用来将单词分成子表达式。括入括号的部分可以被嵌套。
-
- ~word:一个前导的代字号用作否定符, 用来否定单词对该行相关性的影响。 这对于标记“noise(无用信息)”的单词很有用。包含这类单词的行较其它行等级低。
-
- word* :搜索以word开头的单词,只允许出现在单词的末尾
-
- "word1 word" :给定单词必须出现在数据记录中,先后顺序也必须匹配,区分字母大小写
select * from tablename
where match(column1,column2) against ('+word1 +word2 -word3' in boolean mode')
布尔检索只能返回1或者0,不再返回表示匹配程度的浮点数
全文索引的缺陷:
-
- 数据表越大,全文索引效果好,比较小的数据表会返回一些难以理解的结果。
-
- 全文检索以整个单词作为匹配对象,单词变形(加上后缀,复数形式),就被认为另一个单词。
-
- 只有由字母,数字,单引号,下划线构成的字符串被认为是单词,带注音符号的字母仍是字母,像C++不再认为是单词
-
- 不区分大小写
-
- 只能在MyISAM上使用
-
- 全文索引创建速度慢,而且对有全文索引的各种数据修改操作也慢
前言:本文简单讲述全文索引的应用实例,MYSQL演示版本5.5.24。
Q:全文索引适用于什么场合?
A:全文索引是目前实现大数据搜索的关键技术。
至于更详细的介绍请自行百度,本文不再阐述。
--------------------------------------------------------------------------------
一、如何设置?
![]()
如图点击结尾处的{全文搜索}即可设置全文索引,不同MYSQL版本名字可能不同。
二、设置条件
1.表的存储引擎是MyISAM,默认存储引擎InnoDB不支持全文索引(新版本MYSQL5.6的InnoDB支持全文索引)
2.字段类型:char、varchar和text
三、配置
my.ini配置文件中添加
# MySQL全文索引查询关键词最小长度限制
[mysqld]
ft_min_word_len = 1
保存后重启MYSQL,执行SQL语句
SHOW VARIABLES
查看ft_min_word_len是否设置成功,如果没设置成功请确保
1.确认my.ini正确配置,注意不要搞错my.ini的位置
2.确认mysql已经重启,实在不行重启电脑
其他相关配置请自行百度。
注:重新设置配置后,已经设置的索引需要重新设置生成索引
四、SQL语法
首先生成temp表
搜索`char`字段 'a' 值
SELECT * FROM `temp` WHERE MATCH(`char`) AGAINST ('a')
但是你会发现查询无结果?!
这时你也许会想:哎呀怎么回事,我明明按照步骤来做的啊,是不是那里漏了或者错了?
你不要着急,做程序是这样的,出错总是有的,静下心来,着急是不能解决问题的。
如果一个关键词在50%的数据出现,那么这个词会被当做无效词。
如果你想去除50%的现在请使用IN BOOLEAN MODE搜索
SELECT * FROM `temp` WHERE MATCH(`char`) AGAINST ('a' IN BOOLEAN MODE)
这样就可以查询出结果了,但是我们不推荐使用。
全文索引的搜索模式的介绍自行百度。
我们先加入几条无用数据已解除50%限制
这时你执行以下SQL语句都可以查询到数据
以下SQL搜索不到数据
如果搜索多个词,请用空格或者逗号隔开
上面的SQL都可以查询到三条数据
五、分词
看到这里你应该发现我们字段里的值也是分词,不能直接插入原始数据。
全文索引应用流程:
1.接收数据-数据分词-入库
2.接收数据-数据分词-查询
现在有个重要的问题:怎么对数据分词?
数据分词一般我们会使用一些成熟免费的分词系统,当然如果你有能力也可以自己做分词系统,这里我们推荐使用SCWS分词插件。
首先下载
1.php_scws.dll 注意对应版本
2.XDB词典文件
3.规则集文件
下载地址
安装scws
1.先建一个文件夹,位置不限,但是最好不要中文路径。
2.解压{规则集文件},把xdb、三个INI文件全部扔到 D:\scws
3.把php_scws.dll复制到你的PHP目录下的EXT文件夹里面
4.在 php.ini 的末尾加入以下几行:
[scws]
;
; 注意请检查 php.ini 中的 extension_dir 的设定值是否正确, 否则请将 extension_dir 设为空,
; 再把 php_scws.dll 指定为绝对路径。
;
extension = php_scws.dll
scws.default.charset = utf8
scws.default.fpath = "D:\scws"
5.重启你的服务器
测试
如果安装未成功,请参照官方说明文档
--------------------------------------------------------------------------------
这样我们就可以使用全文索引技术了。
1.创建全文索引(FullText index)
旧版的MySQL的全文索引只能用在MyISAM表格的char、varchar和text的字段上。
不过新版的MySQL5.6.24上InnoDB引擎也加入了全文索引,所以具体信息要随时关注官网,
1.1. 创建表的同时创建全文索引
CREATE TABLE article (
id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT(title, body)
) TYPE=MYISAM;
1.2.通过 alter table 的方式来添加
ALTER TABLE `student` ADD FULLTEXT INDEX ft_stu_name (`name`) #ft_stu_name是索引名,可以随便起
或者:ALTER TABLE `student` ADD FULLTEXT ft_stu_name (`name`)
1.3. 直接通过create index的方式
CREATE FULLTEXT INDEX ft_email_name ON `student` (`name`)
也可以在创建索引的时候指定索引的长度:
CREATE FULLTEXT INDEX ft_email_name ON `student` (`name`(20))
2. 删除全文索引
2.1. 直接使用 drop index(注意:没有 drop fulltext index 这种用法)
DROP INDEX full_idx_name ON tommy.girl ;
2.2. 使用 alter table的方式
ALTER TABLE tommy.girl DROP INDEX ft_email_abcd;
3.使用全文索引
跟普通索引稍有不同
使用全文索引的格式: MATCH (columnName) AGAINST ('string')
eg:
SELECT * FROM `student` WHERE MATCH(`name`) AGAINST('聪')
当查询多列数据时:
建议在此多列数据上创建一个联合的全文索引,否则使用不了索引的。
SELECT * FROM `student` WHERE MATCH(`name`,`address`) AGAINST('聪 广东')
3.1. 使用全文索引需要注意的是:(基本单位是词)
分词,全文索引以词为基础的,MySQL默认的分词是所有非字母和数字的特殊符号都是分词符(外国人嘛)
这里推荐一篇文章:利用mysql的全文索引实现模糊查询
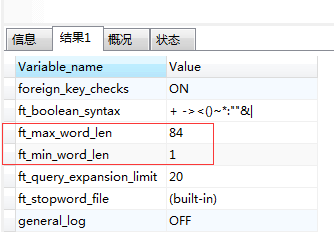
3.2. MySQL中与全文索引相关的几个变量:
使用命令:mysql> SHOW VARIABLES LIKE 'ft%'; #ft就是FullText的简写
ft_boolean_syntax + -><()~*:""&| #改变IN BOOLEAN MODE的查询字符,不用重新启动MySQL也不用重建索引
ft_min_word_len 4 #最短的索引字符串,默认值为4,(通常改为1)修改后必须重建索引文件
重新建立索引命令:repair table tablename quick
ft_max_word_len 84 #最长的索引字符串,默认值为84,修改后必须重建索引文件
ft_query_expansion_limit 20 #查询括展时取最相关的几个值用作二次查询
ft_stopword_file (built-in) #全文索引的过滤词文件,具体可以参考:MySQL全文检索中不进行全文索引默认过滤词
特别注意:50%的门坎限制(当查询结果很多,几乎所有记录都有,或者极少的数据,都有可能会返回非所期望的结果)
-->可用IN BOOLEAN MODE即可以避开50%的限制。
此时使用全文索引的格式就变成了: SELECT * FROM `student` WHERE MATCH(`name`) AGAINST('聪' IN BOOLEAN MODE)
更多内容请参考:MySQL中的全文检索(1)
4. ft_boolean_syntax (+ -><()~*:""&|)使用的例子:
4.1 + : 用在词的前面,表示一定要包含该词,并且必须在开始位置。
eg: +Apple 匹配:Apple123, "tommy, Apple"
4.2 - : 不包含该词,所以不能只用「-yoursql」这样是查不到任何row的,必须搭配其他语法使用。
eg: MATCH (girl_name) AGAINST ('-林志玲 +张筱雨')
匹配到: 所有不包含林志玲,但包含张筱雨的记录
4.3. 空(也就是默认情况),表示可选的,包含该词的顺序较高。
例子:
apple banana 找至少包含上面词中的一个的记录行
+apple +juice 两个词均在被包含
+apple macintosh 包含词 “apple”,但是如果同时包含 “macintosh”,它的排列将更高一些
+apple -macintosh 包含 “apple” 但不包含 “macintosh”
4.4. > :提高该字的相关性,查询的结果会排在比较靠前的位置。
4.5.< :降低相关性,查询的结果会排在比较靠后的位置。
例子:4.5.1.先不使用 ><
select * from tommy.girl where match(girl_name) against('张欣婷' in boolean mode);
 可以看到完全匹配的排的比较靠前
可以看到完全匹配的排的比较靠前
4.5.2. 单独使用 >
select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴' in boolean mode);
 使用了>的李秀琴马上就排到最前面了
使用了>的李秀琴马上就排到最前面了
4.5.3. 单独使用 <
select * from tommy.girl where match(girl_name) against('张欣婷 <不是人' in boolean mode);
 看到没,不是人也排到最前面了,这里使用的可是 < 哦,说好的降低相关性呢,往下看吧。
看到没,不是人也排到最前面了,这里使用的可是 < 哦,说好的降低相关性呢,往下看吧。
4.5.4.同时使用><
select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴 <练习册 <不是人>是个鬼' in boolean mode);
 到这里终于有答案了,只要使用了 ><的都会往前排,而且>的总是排在<的前面
到这里终于有答案了,只要使用了 ><的都会往前排,而且>的总是排在<的前面
小结一下:1. 只要使用 ><的总比没用的 靠前;
2. 使用 >的一定比 <的排的靠前 (这就符合相关性提高和降低);
3. 使用同一类的,使用的越早,排的越前。
4.6. ( ):可以通过括号来使用字条件。
eg: +aaa +(>bbb <ccc) 找到有aaa和bbb和ccc,aaa和bbb,或者aaa和ccc(因为bbb,ccc前面没有+,所以表示可有可无),
然后 aaa&bbb > aaa&bbb&ccc > aaa&ccc
4.7. ~ :将其相关性由正转负,表示拥有该字会降低相关性,但不像「-」将之排除,只是排在较后面。
eg: +apple ~macintosh 先匹配apple,但如果同时包含macintosh,就排名会靠后。
4.8. * :通配符,这个只能接在字符串后面。
MATCH (girl_name) AGAINST ('+*ABC*') #错误,不能放前面
MATCH (girl_name) AGAINST ('+张筱雨*') #正确
4.9. " " :整体匹配,用双引号将一段句子包起来表示要完全相符,不可拆字。
eg: "tommy huang" 可以匹配 tommy huang xxxxx 但是不能匹配 tommy is huang。
5.补充:Windows下无法修改 ft_min_word_len的情况,
5. 1. 使用cmd打开 services.msc,
找到你的 MySQL服务,右键Properties,找到你的my.ini所在的路径

5.2. 停止MySQL,在my.ini中增加 ft_min_word_len = 1,重启MySQL,
然后使用命令 show variables like 'ft_min_word_len'; 查看是否生效了
1. MySQL 4.x版本及以上版本提供了全文检索支持,但是表的存储引擎类型必须为MyISAM,以下是建表SQL,注意其中显式设置了存储引擎类型
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
其中FULLTEXT(title, body) 给title和body这两列建立全文索引,之后检索的时候注意必须同时指定这两列。
2. 插入测试数据

INSERT INTO articles (title,body) VALUES ('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
3. 全文检索测试
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database');
检索结果如下:
5 MySQL vs. YourSQL In the following database comparison ... 1 MySQL Tutorial DBMS stands for DataBase ...
说明全文匹配时忽略大小写。
4. 可能遇到的困扰
到目前为止都很顺利,但是如果检索SQL改为下面会怎样呢?
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('well');
结果让人大跌眼镜,开始我也困惑了许久,后来去网上查了下才知道原来是这么回事:
mysql指定了最小字符长度,默认是4,必须要匹配大于4的才会有返回结果,可以用SHOW VARIABLES LIKE 'ft_min_word_len' 来查看指定的字符长度,也可以在mysql配置文件my.ini 更改最小字符长度,方法是在my.ini 增加一行 比如:ft_min_word_len = 2,改完后重启mysql即可。
所以上面不能返回结果。但是我用上面的方法改配置文件并重启MySQL服务器后,再用show命令查看,并没有改变。
另外,MySQL还会计算一个词的权值,以决定是否出现在结果集中,具体如下:
mysql在集和查询中的对每个合适的词都会先计算它们的权重,一个出现在多个文档中的词将有较低的权重(可能甚至有一个零权重),因为在这个特定的集中,它有较低的语义值。否则,如果词是较少的,它将得到一个较高的权重,mysql默认的阀值是50%,上面‘you’在每个文档都出现,因此是100%,只有低于50%的才会出现在结果集中。
但是如果不考虑权重,那么该怎么办呢?MySQL提供了布尔全文检索(BOOLEAN FULLTEXT SEARCH)
假设well在所有记录中都出现,并且ft_min_word_len已经改为2,那么下面的SQL检索语句得到的结果集将包含所有记录:
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('well' IN BOOLEAN MODE );
5. 布尔全文检索语法
上面通过IN BOOLEAN MODE指定全文检索模式为布尔全文检索。MySQL还提供了一些类似我们平时使用搜索引擎时用到的的语法:逻辑与、逻辑或、逻辑非等。具体通过几个SQL语句例子来说明
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+apple -banana' IN BOOLEAN MODE);
+ 表示AND,即必须包含。- 表示NOT,即不包含。
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('apple banana' IN BOOLEAN MODE);
apple和banana之间是空格,空格表示OR,即至少包含apple、banana中的一个。
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+apple banana' IN BOOLEAN MODE);
必须包含apple,但是如果同时也包含banana则会获得更高的权重。
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+apple ~banana' IN BOOLEAN MODE);
~ 是我们熟悉的异或运算符。返回的记录必须包含apple,但是如果同时也包含banana会降低权重。但是它没有 +apple -banana 严格,因为后者如果包含banana压根就不返回。
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+apple +(>banana <orange)' IN BOOLEAN MODE);
返回同时包含apple和banana或者同时包含apple和orange的记录。但是同时包含apple和banana的记录的权重高于同时包含apple和orange的记录。
6. MySQL不支持中文的全文检索
默认MySQL不支持中文全文检索,怎么办?大致方法有下面几个:
A. 扩展MySQL,添加中文全文检索支持,难度较大
B. 为中文内容表提供一个对应的英文索引表(即将FULLTEXT索引列按照一定的规则转化成英文索引表中的每一条记录,比如全部进行base64编码,内容表和英文索引表的id相同),检索时先将检索词也用相同规则转换成英文,然后再使用。如果还要支持按拼音全文检索,那么还需要在索引表中增加对应的拼音内容(就需要中文转拼音算法了)。当然如果还需要支持中英文交互搜索,比如搜索William时也需要返回威廉,反之亦然,那么还需要将威廉对应的英文翻译也存到索引表中去。
参考网上的链接,具体做法包括先对中文内容进行分词,然后中文转换为四位区位码存到索引表中。检索时,包含中文的检索词也要先分词,再转换为四位区位码,然后在索引表中进行全文检索。
7. 核对条目
A. 只有存储引擎类型为MyISAM类型的表,并且MySQL版本为4.X或者以上才能使用MySQL内置的全文检索支持
B. MySQL全文检索默认不支持中文,且对英文检索时忽略大小写
C. MySQL全文检索时,默认检索长度为4,即关键词的长度必须大于5才能被捕获
D. MySQL全文检索时,所有FULLTEXT索引列必须使用相同的字符集
E. MySQL全文检索返回结果集时还会考虑权重
F. MySQL全文检索还支持灵活的布尔全文检索模式
G. 更多内容参考MySQL5官方手册
参考链接:
http://viralpatel.net/blogs/2009/04/full-text-search-using-mysql-full-text-search-capabilities.html
http://hi.baidu.com/gogogo/blog/item/28b16c81b3bc87d6bc3e1eb7.html
http://dev.mysql.com/doc/refman/5.1/zh/functions.html#fulltext-query-expansion
一、设置全文索引:
添加:ALTER TABLE table_name ADD FULLTEXT ( column);
删除:DROP INDEX index_name ON table_name;
注:mysql5.6版本以下只有myisam存储引擎支持全文索引,mysql5.6以上版本myisam和innodb都支持全文索引,两者性能有兴趣了可以比较一下。
二、搜索语句:
SELECT * FROM table_name WHERE MATCH(index_name) AGAINST(‘搜索值’);
多词请用逗号或空格分开:SELECT * FROM table_name WHERE MATCH(index_name) AGAINST(‘a,b’);
到这里基本已经可以使用了,但是有时候在搜索单个字符时候没有结果,这时候需要修改一下全文索引关键词长度设置了。
注:当个别词的出现频率超过50%时,被认作无效词,可以改为AGAINST (‘高频词’ IN BOOLEAN MODE)。
三、修改配置:
找到mysql.ini,在在 [mysqld] 位置添加:ft_min_word_len=1
重启mysql服务。
查看mysql环境变量:show variables;就可以看到设置的结果了
注:
1.全文索引的字段类型必须为:char,varchar,text 。
2.对于中文全文索引,必须先把字段值做好中文分词,每个关键词之间用“ ,”“ ”分开,不然即使全文索引还是无效,谁让这些都是老外开发的呢(英文单词之间都是空格,妥妥的),但是中文分词可以借助其他一些开源程序来做,比如:coreseek,附上下载地址:http://www.coreseek.cn/news/7/52/
3.有人说将中文转成拼音,然后进行搜索,或许是一个好的方法,可以试一下。
在MYSQL中使用全文索引(FULLTEXT index)
MYSQL的一个很有用的特性是使用全文索引(FULLTEXT index)查找文本的能力.目前只有使用MyISAM类型表的时候有效(MyISAM是默认的表类型,如果你不知道使用的是什么类型的表,那很可能就是 MyISAM).全文索引可以建立在TEXT,CHAR或者VARCHAR类型的字段,或者字段组合上.我们将建立一个简单的表用来解释各种特性.
简单用法(MATCH()函数)对3.23.23以后的版本有效,复杂的用法(IN BOOLEAN MODE修饰语)对4以后的版本有效,本文的第一部分着重简单用法,第二部分讲复杂用法.
一个简单的表
我们将在整个过程中使用下面的表.
CREATE TABLE fulltext_sample(copy TEXT,FULLTEXT(copy)) TYPE=MyISAM;
如果你没有把默认的表类型设置成MyISAM以外的类型那么TYPE=MyISAM可以省略.建表之后,向其中填充一些数据,例如:
INSERT INTO fulltext_sample VALUES
('It appears good from here'),
('The here and the past'),
('Why are we hear'),
('An all-out alert'),
('All you need is love'),
('A good alert');
如果你已经建立好了一个表,你可以使用ALTER TABLE(就像CREATE INDEX语句一样)语句添加一个全文索引,例如:
ALTER TABLE fulltext_sample ADD FULLTEXT(copy)
查找文本
全文索引搜索的语法很简单,你只要MATCH字段,AGAINST你要查找的文本,例如:
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('love');
+----------------------+
| copy |
+----------------------+
| All you need is love |
+----------------------+
在全文索引上进行搜索是不区分大小写的,因此下面的语句也可以正常运行:
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('LOVE');
+----------------------+
| copy |
+----------------------+
| All you need is love |
+----------------------+
全文索引通常用来搜索自然语言文本,例如报纸文章,网页内容等等.因此MySQL为这类搜索添加了很多特性.MySQL不索引任何长度小于等于3的文本, 也不索引有50%机会出现的单词.这意味着如果你的表少于2条记录,基于全文索引的搜索不会返回任何东西.将来,MySQL会使这项功能更灵活,但是现在 它应该可以适合大部分自然语言的使用.如果你的数据库中的大部分记录都包含”music”,你很可能不希望返回这些记录,你可以使用IN BOOLEAN MODE修饰符来获得50%左右的阀值,见本文第二部分.
结果将按照关联性从高到底的顺序返回.
主要特性
下面是标准的全文索引搜索的主要特性:
1.排除重复词语
2.排除长度小于4的词语
3.排除在多于一半记录中出现的词语(就是说只要要有3条记录)
4.带连字符的词语被认为两个词语
5.结果按照关联度降序返回
6.忽略列表中的词语也被从搜索结果中排除.忽略列表基于普通的英文单词,因此如果你的数据用作不同的目的,你可能希望改变忽略列表.不幸的是,这样作并 不容易.你需要编辑文件myisam/ft_static.c,重新编辑MySQL,并重建索引!这里有一个忽略列表.注意,这些在不同的版本里有所更 改.
忽略列表
"a", "a's", "able", "about", "above", "according", "accordingly", "across", "actually", "after", "afterwards", "again", "against", "ain't", "all", "allow", "allows", "almost", "alone", "along", "already", "also", "although", "always", "am", "among", "amongst", "an", "and", "another", "any", "anybody", "anyhow", "anyone", "anything", "anyway", "anyways", "anywhere", "apart", "appear", "appreciate", "appropriate", "are", "aren't", "around", "as", "aside", "ask", "asking", "associated", "at", "available", "away", "awfully", "b", "be", "became", "because", "become", "becomes", "becoming", "been", "before", "beforehand", "behind", "being", "believe", "below", "beside", "besides", "best", "better", "between", "beyond", "both", "brief", "but", "by", "c", "c'mon", "c's", "came", "can", "can't", "cannot", "cant", "cause", "causes", "certain", "certainly", "changes", "clearly", "co", "com", "come", "comes", "concerning", "consequently", "consider", "considering", "contain", "containing", "contains", "corresponding", "could", "couldn't", "course", "currently", "d", "definitely", "described", "despite", "did", "didn't", "different", "do", "does", "doesn't", "doing", "don't", "done", "down", "downwards", "during", "e", "each", "edu", "eg", "eight", "either", "else", "elsewhere", "enough", "entirely", "especially", "et", "etc", "even", "ever", "every", "everybody", "everyone", "everything", "everywhere", "ex", "exactly", "example", "except", "f", "far", "few", "fifth", "first", "five", "followed", "following", "follows", "for", "former", "formerly", "forth", "four", "from", "further", "furthermore", "g", "get", "gets", "getting", "given", "gives", "go", "goes", "going", "gone", "got", "gotten", "greetings", "h", "had", "hadn't", "happens", "hardly", "has", "hasn't", "have", "haven't", "having", "he", "he's", "hello", "help", "hence", "her", "here", "here's", "hereafter", "hereby", "herein", "hereupon", "hers", "herself", "hi", "him", "himself", "his", "hither", "hopefully", "how", "howbeit", "however", "i", "i'd", "i'll", "i'm", "i've", "ie", "if", "ignored", "immediate", "in", "inasmuch", "inc", "indeed", "indicate", "indicated", "indicates", "inner", "insofar", "instead", "into", "inward", "is", "isn't", "it", "it'd", "it'll", "it's", "its", "itself", "j", "just", "k", "keep", "keeps", "kept", "know", "knows", "known", "l", "last", "lately", "later", "latter", "latterly", "least", "less", "lest", "let", "let's", "like", "liked", "likely", "little", "look", "looking", "looks", "ltd", "m", "mainly", "many", "may", "maybe", "me", "mean", "meanwhile", "merely", "might", "more", "moreover", "most", "mostly", "much", "must", "my", "myself", "n", "name", "namely", "nd", "near", "nearly", "necessary", "need", "needs", "neither", "never", "nevertheless", "new", "next", "nine", "no", "nobody", "non", "none", "noone", "nor", "normally", "not", "nothing", "novel", "now", "nowhere", "o", "obviously", "of", "off", "often", "oh", "ok", "okay", "old", "on", "once", "one", "ones", "only", "onto", "or", "other", "others", "otherwise", "ought", "our", "ours", "ourselves", "out", "outside", "over", "overall", "own", "p", "particular", "particularly", "per", "perhaps", "placed", "please", "plus", "possible", "presumably", "probably", "provides", "q", "que", "quite", "qv", "r", "rather", "rd", "re", "really", "reasonably", "regarding", "regardless", "regards", "relatively", "respectively", "right", "s", "said", "same", "saw", "say", "saying", "says", "second", "secondly", "see", "seeing", "seem", "seemed", "seeming", "seems", "seen", "self", "selves", "sensible", "sent", "serious", "seriously", "seven", "several", "shall", "she", "should", "shouldn't", "since", "six", "so", "some", "somebody", "somehow", "someone", "something", "sometime", "sometimes", "somewhat", "somewhere", "soon", "sorry", "specified", "specify", "specifying", "still", "sub", "such", "sup", "sure", "t", "t's", "take", "taken", "tell", "tends", "th", "than", "thank", "thanks", "thanx", "that", "that's", "thats", "the", "their", "theirs", "them", "themselves", "then", "thence", "there", "there's", "thereafter", "thereby", "therefore", "therein", "theres", "thereupon", "these", "they", "they'd", "they'll", "they're", "they've", "think", "third", "this", "thorough", "thoroughly", "those", "though", "three", "through", "throughout", "thru", "thus", "to", "together", "too", "took", "toward", "towards", "tried", "tries", "truly", "try", "trying", "twice", "two", "u", "un", "under", "unfortunately", "unless", "unlikely", "until", "unto", "up", "upon", "us", "use", "used", "useful", "uses", "using", "usually", "v", "value", "various", "very", "via", "viz", "vs", "w", "want", "wants", "was", "wasn't", "way", "we", "we'd", "we'll", "we're", "we've", "welcome", "well", "went", "were", "weren't", "what", "what's", "whatever", "when", "whence", "whenever", "where", "where's", "whereafter", "whereas", "whereby", "wherein", "whereupon", "wherever", "whether", "which", "while", "whither", "who", "who's", "whoever", "whole", "whom", "whose", "why", "will", "willing", "wish", "with", "within", "without", "won't", "wonder", "would", "would", "wouldn't", "x", "y", "yes", "yet", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves", "z", "zero",
让我们看一下其中的一些词.如果你懒的输入,但是想查找”love”这个词,象下面这样:
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('lov');
Empty set (0.00 sec)
什么都没返回,因为全文索引只包含完整的单词,不是部分单词.如果想得到返回,你必须把单词写完整,就像第一个例子里一样.
就像我们提过的,连字符单词在全文索引中被排除(它们被作为单独的单词索引),因此下面的语句什么都不返回:
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('all-out');
Empty set (0.00 sec)
很不幸,两个单词都小于4个字符,因此单独搜索时也不会出现,而且通常的搜索中也不会出现.本文的第二部分中使用BOOLEAN MODE搜索可以搜索部分的或者包含连字符的单词.
你也可以一次搜索多个单词,用逗号分隔.下面的例子查找包含”here”和”appears”的记录:
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('here','appears');
Empty set (0.01 sec)
出乎意料这个语句没有返回.但是仔细看看忽略列表,这个词被列在其中,因此被从索引中排除了.忽略列表可能是人们解释MySQL全文索引没有生效的通常原因.如果你的查询返回了一个结果,那么你的版本的MySQL的忽略列表不包含”here”这个词.
关联度
下面的例子说明记录返回的优先级
mysql> SELECT * FROM fulltext_sample WHERE MATCH(copy) AGAINST('good,alert');
+---------------------------+
| copy |
+---------------------------+
| A good alert |
| It appears good from here |
| An all-out alert |
+---------------------------+
记录”A good alert”首先出现,因为它同时包含要搜索的两个词.你不必相信我-只需要看看MySQL在结果中显示的优先级.简单的在字段列表中重复MATCH()函数,例如:
mysql> SELECT copy,MATCH(copy) AGAINST('good,alert') AS relevance
FROM fulltext_sample WHERE MATCH(copy) AGAINST('good,alert');
+---------------------------+------------------+
| copy | relevance |
+---------------------------+------------------+
| A good alert | 1.3551264824316 |
| An all-out alert | 0.68526663197496 |
| It appears good from hear | 0.67003110026735 |
+---------------------------+------------------+
关联度的计算非常复杂,它基于索引中单词的数量,记录中不同单词的个数,索引和返回结果中单词的总数,以及单词的重要程度.这个数字可能在你的MySQL版本中有所不同,MySQL偶尔会强化计算逻辑.
对大多数应用来说标准的全文索引搜索非常有用而充分,MySQL 4让它更加强大.
[原文地址:http://blog.csdn.net/zyz511919766/article/details/12780173]
1.概要
InnoDB引擎对FULLTEXT索引的支持是MySQL5.6新引入的特性,之前只有MyISAM引擎支持FULLTEXT索引。对于FULLTEXT索引的内容可以使用MATCH()…AGAINST语法进行查询。
为了在InnoDB驱动的表中使用FULLTEXT索引MySQL5.6引入了一些新的配置选项和INFORMATION_SCHEMA表。比如,为了监视一个FULLTEXT索引中文本处理过程的某一方面可以查询INNODB_FT_CONFIG,INNODB_FT_INDEX_TABLE,INNODB_FT_INDEX_CACHE,INNODB_FT_DEFAULT_STOPWORD,INNODB_FT_DELETED和INNODB_FT_BEING_DELETED这些表。可以通过innodb_ft_num_word_optimize和innodb_optimize_fulltext_only选项控制OPTIMIZETABLE命令对InnoDB FULLTEXT索引的更新。
2.相关库表
INFORMATION_SCHEMA库中与InnoDB全文索引相关的表如下:
? INNODB_SYS_INDEXES:提供了InnoDB索引的状态信息。
? INNODB_SYS_TABLES:提供了InnoDB表的状态信息。
? INNODB_FT_CONFIG:显示一个InnoDB表的FULLTEXT索引及其相关处理的元数据。
? INNODB_FT_INDEX_TABLE:转化后的索引信息用于处理基于InnoDB表FULLTEXT索引的文本搜索。一般用于调试诊断目的。使用该表前需先配置innodb_ft_aux_table配置选项,将其指定为想要查看的含FULLTEXT索引的InnoDB表,选项值的格式为database_name/table_name。配置了该选项后INNODB_FT_INDEX_TABLE,INNODB_FT_INDEX_CACHE, INNODB_FT_CONFIG, INNODB_FT_DELETED和INNODB_FT_BEING_DELETED表将被填充与innodb_ft_aux_table配置选项指定的表关联的搜索索引相关信息。
? INNODB_FT_INDEX_CACHE:向含FULLTEXT索引的InnoDB表插入数据后新插入数据转后的索引信息。表结构与INNODB_FT_INDEX_TABLE一致。为含FULLTEXT索引的InnoDB表执行DML操作期间重组索引开销很大,因此将新插入的被索引的词单独存储于该表中,当且仅当为InnoDB表执行OPTIMIZE TABLE语句后才将新的转换后的索引信息与原有的主索引信息合并。使用该表前需先配置innodb_ft_aux_table配置选项。
? INNODB_FT_DEFAULT_STOPWORD:在InnoDB表上创建FULLTEXT索引所使用的默认停止字表。
? INNODB_FT_DELETED:记录了从InnoDB表FULLTEXT索引中删除的行。为了避免为InnoDB的FULLTEXT索引执行DML操作期间重组索引的高开销,新删除的词的信息单独存储于此表。当且仅当为此InnoDB表执行了OPTIMIZE TABLE操作后才会从主搜索索引中移除已删除的词信息。使用该表前需先配置innodb_ft_aux_table选项。
? INNODB_FT_BEING_DELETED:为含FULLTEXT索引的InnoDB表执行OPTIMIZE TABLE操作时会根据INNODB_FT_DELETED表中记录的文档ID从InnoDB表的FULLTEXT索引中删除相应的索引信息。而INNOFB_FT_BEING_DELETED表用于记录正在被删除的信息,用于监控和调试目的。
3.相关配置选项
| Name | Cmd- | Option file | System Var | Status Var | Scope | Dynamic |
| Yes | Yes | Yes |
| Global | Yes | |
| Yes | Yes | Yes |
| Global | No | |
| Yes | Yes | Yes |
| Global | Yes | |
| Yes | Yes | Yes |
| Global | Yes | |
| Yes | Yes | Yes |
| Global | No | |
| Yes | Yes | Yes |
| Global | No | |
| Yes | Yes | Yes |
| Global | Yes | |
| Yes | Yes | Yes |
| Global | Yes | |
| Yes | Yes | Yes |
| Global | No | |
| Yes | Yes | Yes |
| Both | Yes | |
| Yes | Yes | Yes |
| Global | Yes |
? innodb_ft_aux_table:指定包含FULLTEXT索引的InnoDB表的的名称。该变量在运行时设置用于诊断目的。设置该值后INNODB_FT_INDEX_TABLE, INNODB_FT_INDEX_CACHE, INNODB_FT_CONFIG,INNODB_FT_DELETED和INNODB_FT_BEING_DELETED表将被填充与innodb_ft_aux_table指定的表关联的搜索索引相关信息。
? innodb_ft_cache_size:当创建一个InnoDB FULLTEXT索引时在内存中存储已解析文档的缓存大小。
? innodb_ft_enable_diag_print:是否开启额外的全文搜索诊断输出。
? innodb_ft_enable_stopword:是否开启停止字。InnoDB FUllTEXT索引被创建时为其指定一个关联的停止字集。(若设置了innodb_ft_user_stopword_table则停止字由该选项指定的表获取,若没有设置innodb_ft_user_stopword_table而设置了innodb_ft_server_stopword_table则停止字由该选项指定的表获取,否则使用内置的停止字。)
? innodb_ft_max_token_size:存储在InnoDB的FULLTEXT索引中的最大词长。设置这样一个限制后可通过忽略过长的关键字等有效降低索引大小从而加速查询。
? innodb_ft_min_token_size:存储在InnoDB的FULLTEXT索引中的最小词长。增加该值后会忽略掉一些通用的没有显著意义的词汇从而降低索引大小继而加速查询。
? innodb_ft_num_word_optimize:为InnoDB FULLTEXT索引执行OPTIMIZE操作每次所处理的词数。因为在含有全文搜索索引的表中执行批量的插入或更新操作需要大量的索引维护操作来合并所有的变化。因此,一般会运行一系列OPTIMIZE TABLE语句,每次从上一次的位置开始,处理指定数目的词,知道搜索索引被完全更新。
? innodb_ft_server_stopword_table:含有停止字的表,在创建InnoDB FULLTEXT索引时或忽略表中的停止字。停止字表需为InnoDB表,且在指定前应当已存在。
? innodb_ft_sort_pll_degree:为较大的表构建搜索索引时用于索引和记号化文本的并行线程数。
? innodb_ft_user_stopword_table:含有停止字的表,在创建InnoDB FULLTEXT索引时或忽略表中的停止字。停止字表需为InnoDB表,且在指定前应当已存在。
? innodb_optimize_fulltext_only:改变OPTIMIZE TABLE语句对InnoDB表操作的方式。对含FULLTEXT 索引的InnoDB表进行维护操作期间,一般临时的开启该选项。默认情况下,OPTIMIZE TABLE语句会重组表的聚集索引中的数据。若开启了该选项则该语句会跳过表数据的重组,而是只处理FULLTEXT索引中新插入的、删除的、更新的标记数据。(在对作为FULLTEXT索引的一部分的InnoDB表列进行了大量的插入、更新或删除操作后,先将innodb_optimize_fulltext_only设置为on以改变OPTIMIZE TABLE的默认行为,然后设置innodb_ft_num_word_optimize为合适的值以将索引维护时间控制在一个合理的可接受范围内,最后执行一系列的OPTIMIZE语句知道搜索索引被完全更新。)
4.全文搜索功能
全文搜索的语法:MATCH(col1,col2,…) AGAINST (expr[search_modifier])。其中MATCH中的内容为已建立FULLTEXT索引并要从中查找数据的列,AGAINST中的expr为要查找的文本内容,search_modifier为可选搜索类型。search_modifier的可能取值有:IN NATURAL LANGUAGEMODE、IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION、IN BOOLEAN MODE、WITH QUERY EXPANSION。search_modifier的每个取值代表一种类型的全文搜索,分别为自然语言全文搜索、带查询扩展的自然语言全文搜索、布尔全文搜索、查询扩展全文搜索(默认使用IN NATURAL LANGUAGE MODE)。
MySQL中全文索引的关键字为FULLTEXT,目前可对MyISAM表和InnoDB表的CHAR、VARCHAR、TEXT类型的列创建全文索引。全文索引同其他索引一样,可在创建表是由CREATE TABLE语句创建也可以在表创建之后用ALTER TABLE或者CREATE INDEX命令创建(对于要导入大量数据的表先导入数据再创建FULLTEXT索引比先创建索引后导入数据会更快)。
4.1自然语言全文搜索
自然语言全文搜索是MySQL全文搜索的默认搜索方式,实现从一个文本集合中搜索给定的字符串。这里,文本集合指的是指由FULLTEXT索引的一个或者多个列。
建表,并给title,body字段加FULLTEXT索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=InnoDB;
导入数据
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);

可以看到,语句查找到了包含指定内容的行。实际上,返回的行是按与所查找内容的相关度由高到低的顺序排列的。这个相关度的值由WHERE语句中的MATCH (…) AGAINST (…)计算所得,是一个非负浮点数。该值越大表明相应的行与所查找的内容越相关,0值表明不相关。该值基于行中的单词数、行中不重复的单词数、文本集合中总单词数以及含特定单词的行数计算得出。
例2:
由上例可知MATCH (…) AGAINST (…)实际上会计算一个相关值,可通过下例来验证。
SELECT id, MATCH (title,body)
AGAINST ('Tutorial' IN NATURAL LANGUAGE MODE) AS score
FROM articles;
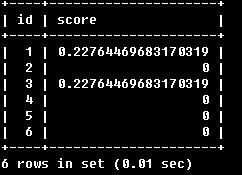
可以看到,所得结果的第二列即为改行与查找内容的相关度。上例1中所得结果的顺序就是按此相关度排列的。
例3:
若想既看到查找到的结果又需要了解具体的相关度,可用下述方法达成。
SELECT id, body, MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE) AS score
FROM articles WHERE MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE);
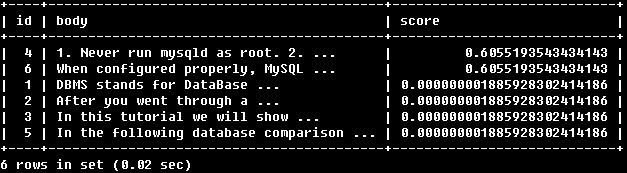
可以看到,通过在查找部分和条件部分分别使用相同的MATCH(…) AGAINST(…)可以同时获取两方面的内容(不会增加额外开销,优化器知道两个MATCH(…) AGAINST(..)是相同的,只会执行一次该语句)
注意事项
默认情况下全文搜索大小写不敏感,如上例1,查找的内容为‘database’但含有‘DataBase’的行也会返回。可以通过为FULLTEXT索引列所使用的字符集指定一个特定的校对集来改变这种行为。
考虑下述两个SELECT语句:
1. SELECTCOUNT(*) FROM articles
WHEREMATCH (title,body)
AGAINST('database' IN NATURAL LANGUAGE MODE);
2. SELECTCOUNT(IF(MATCH (title,body)
AGAINST('database' IN NATURAL LANGUAGE MODE), 1, NULL)) AS count
FROMarticles;
这两条查询语句均可返回匹配的行数。但第一条语句可以利用基于WHERE从句的索引查找,因此在匹配的行数较少时速度较第二句更快。第二句执行了全表扫描,因此在匹配的行数较多时较第一句更快。
MATCH()函数中的列必须与FULLTEXT索引中的列相同。如MATCH(title,body)与FULLTEXT(title,body)。若要单独搜索某列,如body列,则需另外单独为该列建全文索引FULLTEXT(body),然后用MATCH(body)搜索。
对于InnoDB表MATCH()中的列仅能来自于同一个表,因为索引不能快多张表(MyISAM表的的布尔搜索因为可以不使用索引所以可以跨多张表中的列,但速度很慢)。
全文搜索不仅可以搜索类似例1中‘database’这样的单个的单词,还可以搜索句子(这才是其被称为‘全文搜索‘的关键),如例3。全文搜索把任何数字、字母、下划线序列看作是单词,还可以包含“’”如aaa’bbb备解析为一个单词,但aaa’’bbb备解析为两个单词,FULLTEXT解析器自动移除首尾的“’”,如’aaa’bbb’被解析为aaa’bbb。FULLTEXT解析器用“ ”(空格)、“,”(逗号)“.”(点号)作为默认的单词分隔符,因此对于不使用这些分隔符的语言如汉语来说FULLTEXT解析器不能正确的识别单词,对于这种情况需做额外处理。
全文搜索中一些单词会被忽略。首先是过短的单词,InnoDB全文搜索中默认为3个字符,MyISAM默认4个字符,可通过在创建FULLTEXT索引前改变配置参数来改变默认行为,对于InnoDB该参数为:innodb_ft_min_token_size,对于MyISAM为ft_min_word_len;另外stopword列表中的单词会被忽略。stopword列表包含诸如“the”、“or”、“and”等常用单词,这些词通常被认为没有什么语义价值。MySQL由内建的停止字列表,但是可以所使用自定义的停止字列表来覆盖默认列表。对于InnoDB控制停止字的配置参数为innodb_ft_enable_stopword,innodb_ft_server_stopword_table, innodb_ft_user_stopword_table对于MyISAM参数为ft_stopword_file。
文本集合和查询语句中的单词的权重由该单词在集合或语句中的重要性确定。单词在越多的行中出现则该单词的权重越低,因为这表明其在文本集合中的语义价值较小。反之权重越高。例1中提到的相关度计算也与此值有关。
4.2布尔全文搜索
如果在AAGAINST()函数中指定了INBOOLEN MODE模式,则MySQL会执行布尔全文搜索。在该搜索模式下,待搜索单词前或后的一些特定字符会有特殊的含义。
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL-YourSQL' IN BOOLEAN MODE);
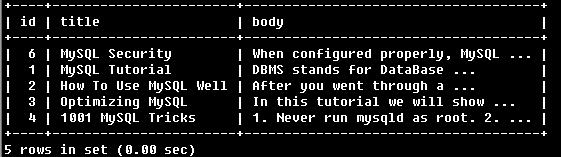
该查询语句中“MySQL”前的“+”表明结果中必须包含“MySQL”而“YourSQL”前的“-”表明所得结果中不能含有“YourSQL”。
除了“+”和“-”外还有其他一些特定的字符。如空字符表明后跟的单词是可选的,但出现的话会增加该行的相关性;“@distance”用于指定两个或多个单词相互之间的距离(以单词度量)需在指定的范围内;“>”用于增加后跟单词对其所在行的相关性的贡献“<”用于降低该贡献;“()”用于将单词分组为子表达式且可以嵌套;“~”是后跟单词对其所在行的相关性的贡献值为负;“*”为普通的通配符,若为单词指定了通配符,那么即使该单词过短或者出现在了停止字列表中它也不会被移除;“””,括在双引号中的短语指明行必须在字面上包含指定的短语,全文搜索将短语分割为词后在FULLTEXT索引中搜索。非字字符无需完全匹配,如”test phrase”可以匹配含”test phrase”和”test phrase”的行,但匹配含”phrase test”的行。
例2:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('MySQL YourSQL' IN BOOLEAN MODE);
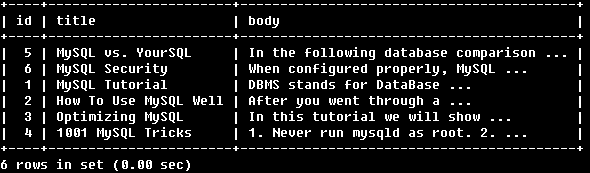
找到包含MySQL或者YourSQL的行
例3:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL+YourSQL' IN BOOLEAN MODE);

找到包含同时MySQL和YourSQL的行
例4:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL YourSQL' IN BOOLEAN MODE);
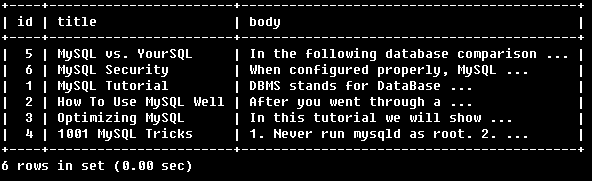
找到必须包含MySQl的行,YourSQL可有可无,但有YourSQL会增加相关性。
例5:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL ~YourSQL' INBOOLEAN MODE);
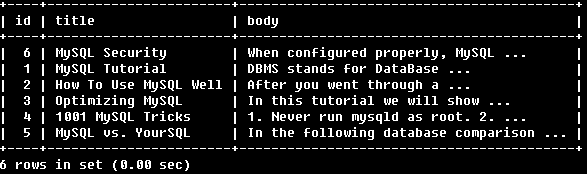
找到包含必须包含MySQL的行,YourSQL可有可无,若出现了YourSQL则会降低其所在行的相关性。
例6:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+MySQL +(>Security <Optimizing)' IN BOOLEANMODE);
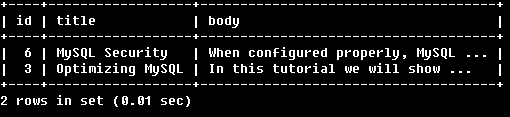
找到必须同时包含MySQL以及Security或Optimizing的行Security会增加所在行的相关性,而Optimizing会降低所在行的相关性。
例7:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('da*' IN BOOLEAN MODE);
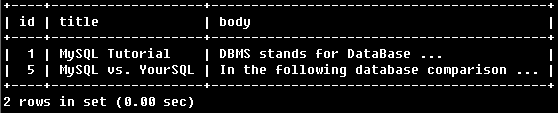
找到包含da*的行。如包含DataBase、database等。
例8:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST('"MySQL,Tutorial"' IN BOOLEAN MODE);
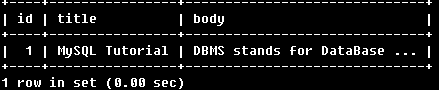
找到包含“MySQL Tutorial”短语的行。
布尔全文搜索的一些特点
? MyISAM全文搜索会忽略至少在一半以上数据行中出现的单词(也即所谓的50%阈值),InnoDB无此限制。而在布尔全文搜索中MyISAM的50%阈值不生效。
? 停止字列表也适用于布尔全文搜索。
? 最小和最大词长全文搜索参数也适用于布尔全文搜索
? MyISAM中的布尔搜索在FULLTEXT索引不存在的时候仍可工作,但速度很慢。而InnoDB表的各类全文搜索必须有FULLTEXT索引,否则会出现找不到与指定列相匹配的FULLTEXT索引的错误
? InnoDB中的全文搜索不支持在单一搜索单词前使用多个操作符如“++MySQL”。MyISAM中全文搜索可以处理这种情况,但是会忽略除了紧邻单词之外的其他操作符。
4.3查询扩展全文搜索
某些时候我们通过全文搜索来查找包含某方面内容的行,比如我们搜索“database”,实际上我们期望返回结果不仅仅是仅包含“database”单词的行,一些包含“MySQL”、“SQLServer”、“Oracle”、“DB2”、“RDBMS”等的行也期望被返回。这个时候查询扩展全文搜索就能大显身手。
通过在AGAINST()函数中指定WITHQUERY EXPANSION 或者IN NATURAL MODE WITH QUERY EXPANSION可以开启查询扩展全文搜索模式。其工作原理是执行两次搜索,第一次用给定的短语搜索,第二次使用给定的短语结合第一次搜索返回结果中相关性非常高的一些行进行搜索。
例1:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);
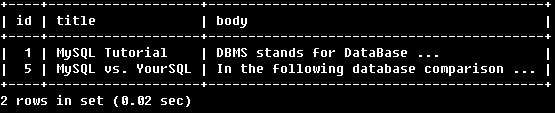
使用自然语言搜索返回了包含“database”的行。
例2:
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' WITH QUERY EXPANSION);
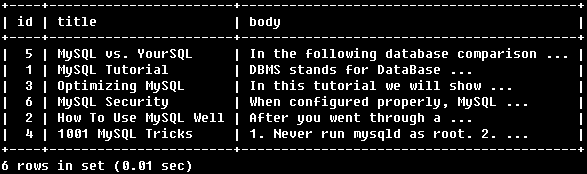
使用查询扩展全文搜索,不进返回了包含“database”的行,也返回了与例1中返回的行的内容相关的行。
注意事项
因为查询扩展会返回一些不相关的内容,因此会显著的引入噪声。索引仅当要查询的短语较短时才在考虑使用查询扩展全文搜索。
4.4全文搜索的停止字
上文已经简单介绍过了停止字列表,这里做详细介绍。停止字列表用MySQL Server所使用的字符集和校对集(分别由character_set_server和collation_server两个参数控制)载入并执行搜索。若用于全文索引和搜索的停止字文件或者停止字表使用了与MySQL Server不同的字符集和校对集会则导致查找停止字时错误的命中或未命中。
停止字查找的大小写敏感性也依赖于MySQL Server所使用的校对集,例如校对集为latin1_swedish_ci则查找是大小写不敏感的,若校对集为latin1_geberal_cs或者latin1_bin则查找是大小写敏感的。
InnoDB默认的停止字列表相对较短(因为技术上的或者文学等方面的文档常使用较短的词作为关键字或者有其他显著意义)。InnoDB默认的停止字列表存储在information_schema.innodb_ft_default_stopword表中。当然也可以通过自定义与innodb_ft_default_stopword表结构相同的表,填充期望的停止字,然后通过innodb_ft_server_stopword_table选项指定自定义的停止字表db_name/table_name,来改变默认的行为。另外还可以为innodb_ft_user_stopword_table选项指定含停止字的表,若同时指定了innodb_ft_default_stopword和innodb_ft_user_stopword_table则将使用后者指定的停止字表。上述操作改变所使用停止字表的操作需在创建全文索引前完成。且在指定所使用的停止字表时,表必须已经存在。
对于MyISAM可通过 ft_stopword_file选项指定所使用的停止字列表。MyISAM默认的停止字列表可在MySQL源码的 storage/myisam/ft_static.c文件中找到。
4.5全文搜索的限制
? 目前只有InnoDB和MyISAM引擎支持全文搜索。其中InnodB表对FULLTEXT索引的支持从MySQL5.6.4开始。
? 分区表不支持全文搜索。
? 全文索引适用于多数多字节字符集。例外情况是:对于Unicode,utf8字符集可用但ucs2字符集不适用。尽管不能在ucs2列建立FULLTEXT索引,但可以在MyISAM表IN BOOLEAN MODE模式的搜索中搜索没有建立FULLTEXT索引的列。utf8的特性适用于utf8mb4,ucs2的特性适用于utf16、utf16e和utf32。
? 表意型语言如汉语、日语没有诸如空格之类的单词定界符。因此FULLTEXT解析器不能确定此类语言中词的起止。对于此种情况要特殊处理(比如将中文转换成一种单字节类似英文习惯的存储方式)。
? 允许在同一表中使用多种字符集,但FULLTEXT索引中的列必须使用同一字符集和校对集。
? MATCH()函数中的列必须与FULLTEXT索引中定义的列完全一致,除非是在MyISAM表中使用IN BOOLEAN MODE模式的全文搜索(可在没有建立索引的列执行搜索,但速度很慢)。
? AGAINST()函数中的参数需为在查询评估期间保持不变的字符串常量。
? FULLTEXT搜索的索引提示比non-FULLTEXT搜索的索引提示要多一些限定:对于自然语言模式的全文搜索,索引提示会被忽略而不给出任何提示,比如虽明确在查询语句中给出了IGNORE INDEX(i)指明不使用i索引,但是该索引提示会被忽略掉,最终的查询中仍会使用索引i;对于布尔模式的全文搜索,FOR ORDER BY和FOR GROUP BY的索引提示会被忽略,FOR JOIN和不带FOR修饰符的索引提示不被忽略。
4.6全文搜索参数调整
仅有少量的用户可调参数用于调整MySQL的全文搜索能力。可以通过修改源码来获取更多对MySQL全文搜索行为的控制。但一般情况下不推荐这么做,除非很清楚自己在做什么,因为这些参数已经针对效率做过调整,修改默认的行为多数情况下反而会带来性能下降。
多数全文搜索相关的变量不能在Server运行的时候修改。需在Server启动时指定这些参数,或者修改完参数之后重新启动Server。另外,某些变量修改后需要重建FULLTEXT索引。
控制最小、最大字长的配置选项对于InnoDB为:innodb_ft_min_token_size和innodb_ft_max_token_size,对于MyISAM为:ft_min_word_len 和 ft_max_word_len。改变这些选项中任意一个的值都需重建FULLTEXT索引并重启Server。
用于停止字列表的配置选项对于InnoDB为:innodb_ft_enable_stopword、innodb_ft_server_stopword_table和innodb_ft_user_stopword_table,对于MyISAM为:ft_stopword_file。可以通过改变这些选项的值来开启/关闭停止字过滤并指定停止字列表。修改了这些选项后需重建索引并在必要的时候重启Server。
ft_stopword_file指定了包含停止字列表的文件,Server默认在数据目录搜索该文件除非用绝对路径指定了文件位置,若文件内容为空,则会关闭MyISAM的停止字过滤功能。停止字文件格式很灵活,可以使用任何非字母或数字的字符来界定停止字,但“_”和“’”例外,它们会被当作字的一部分处理。停止字列表使用Server默认的字符集。
MyISAM全文搜索的50%阈值特性可通过修改源码来关闭,将源码storage/myisam/ftdefs.h中的宏#define GWS_IN_USEGWS_PROB替换为#define GWS_IN_USE GWS_FREQ后重新编译MySQL即可。同样,不推荐上述方式,如果确实需要搜索一些通用的词,可以用布尔模式的全文搜获,此种情况下50%阈值特性不生效。
可以通过修改ft_boolean_syntax选项的值来更改MyISAM布尔全文搜做中默认使用的操作符(InnoDB无此选项)。该选项可动态改变但须超级用户权限,另外,改变了改制后无需重建FULLTEXT索引。
可以通过多种方式更改期望被认作是单词字符成分的字符集合。默认情况下“_”和“’”以及字母和数字被认为是组成单词的字符,其他的被默认为定界符。例如,我们现在想把连字符“-”也作为组成单词的字符处理,那么可以通过如下方式完成:
? 修改MySQL源码,在storage/myisam/ftdefs.h文件中找到true_word_char()和misc_word_char()两个宏,在任一个宏定义里添加“-”,重新编译MySQL。
? 修改字符集文件,true_word_char()宏实际上利用“character type”表来从其他字符中区分出字母和数字。可以通过编辑字符集对应的XML文件中<ctype><map>节点中的内容来将“-”指定为“字母“,然后将该字符集用于FULLTEXT索引。此种方式无需重新编译MySQL。对于编辑字符集XML文件,可参阅MySQL参考手册CharacterDefinition Arrays部分。
http://dev.mysql.com/doc/refman/5.6/en/character-arrays.html
? 对FULLTEXT索引列使用的字符集添加新的校对集,然后更新该列以使用新添加的校对集。具体参阅MySQL手册Adding a Collation to a Character Set以及Adding a Collation for Full-Text Indexing部分。
http://dev.mysql.com/doc/refman/5.6/en/full-text-adding-collation.html
http://dev.mysql.com/doc/refman/5.6/en/adding-collation.html
为InnoDB表重建FULLTEXT索引可以通过带DROP INDEX和ADD INDEX从句的ALTER TABLE语句完成,先删除旧的再创建新的。为MyISAM表重建FULLTEXT索引同样可通过上述语句完成,也可以通过QUICK repair操作来重建(但通常第一种方式会更快),如:
mysql> REPAIR TABLE tbl_name QUICK;
需要特别说明的是,若通过repair表的方式来为MyISAM表重建FULLTEXT索引,则通过上述语句进行即可。用myisamchk工具也可以为MyISAM表重建索引,但是容易导致查询产生错误的结果,对表的修改可能使Server认为该表被损坏了。究其原因是因为通过myisamchk工具执行修改MyISAM表的索引的操作时,除非明确指定了要使用的参数值否则使用默认的全文索引参数值(如最小最大词长等)重建FULLTEXT索引。导致这种情况是因为只有Server才知道这些全文索引参数值,MyISAM索引文件中不存储这些值。若更改过了这些值,如设置了ft_min_word_len=2,则在通过myisamchk工具修复表时要明确指定该修改过的参数值如:
shell> myisamchk --recover--ft_min_word_len=3 tbl_name.MYI
当然也可以通过在MySQL配置文件[myisamchk]节中加入同[mysqld]节中与全文搜索相关参数一致的参数来确保myisamchk使用最新的参数值来重建表的FULLTEXT索引。
用myisamchk为MyISAM表修改索引的替代方式是使用REPAIR TABLE、ANALYZE TABLE、 OPTIMIZE TABLE、ALTER TABLE,这些语句是由Server执行的因此可以读取到正确的全文索引参数值,不会引起问题。
4.7为全文搜索添加校对字符集
参考
10.4. Adding a Collation to a Character Set
http://dev.mysql.com/doc/refman/5.6/en/adding-collation.html
12.9.7. Adding a Collation for Full-Text Indexing
http://dev.mysql.com/doc/refman/5.6/en/full-text-adding-collation.html
5.性能对比测试
5.1测试环境
测试机:SVR644HP380
内存容量:8G
MySQL Server版本:5.6.12
5.2测试设计
词汇量:6个等级,分别用vocab01k、vocab05k、vocab10k、vocab15k,vocab25k、vocab35k标记,每个等级的词汇数如下,1000、5000、10000、15000、25000、35000。(取牛津词典单词部分,去重复后随机打乱顺序,分别截取前1000、5000、10000……作为对应的词汇量)
记录数:20个等级,分别用rec005k、rec010k、rec015k、rec020k、……rec095k、rec100k标记,每个等级的记录数如下,5000、10000、15000、20000、25000、30000、……、95000、100000。
根据词汇量等级和记录数等级分别生成含不同记录数且表中文本列是由对应的词汇量生成的随机文本的表,共6*20=120个。表的存储引擎使用InnoDB。表由id和body两个字段组成,分别为整型和文本型,且在body列创建了FULLTEXT索引。表名的命名规则为vocab01k_rec005k,表示该表中共含有5千条记录,每条记录中的body列由vocab01k对应的词汇量生成的随机单词组成,以此类推。每行记录中的body列定为由50个随机单词组成。
比较两类查询:LIKE从句查询以及使用FULLTEXT索引的MATCH()AGAINST()查询。在每个表上分别执行LIKE查询和MATCH() AGAINST()全文查询,每个表上的每个查询分别执行50次,记录每次所耗费的时间。对于每50个消耗的时间,删除其最大两个值和最小两个值,取剩余值的均值作为查询耗时的最终结果。这样一共可获得120*2 = 240个时间数据,根据这些数据绘图。在每个表上执行的查询如下(其中random_word1、random_word2、random_word3是根据查询时表对应的词汇量生成的随机单词。):
LIKE搜索:
SELECT body FROM table_name WHERE body LIKE "%random_word1%" AND bodyLIKE "% random_word2%" AND body LIKE "% random_word3%";
FULLTEXT搜索:
SELECT body FROM table_name WHERE MATCH(body) AGAINST("+random_word3 + random_word3+ random_word3" IN BOOLEAN MODE)
5.3测试结果
图示
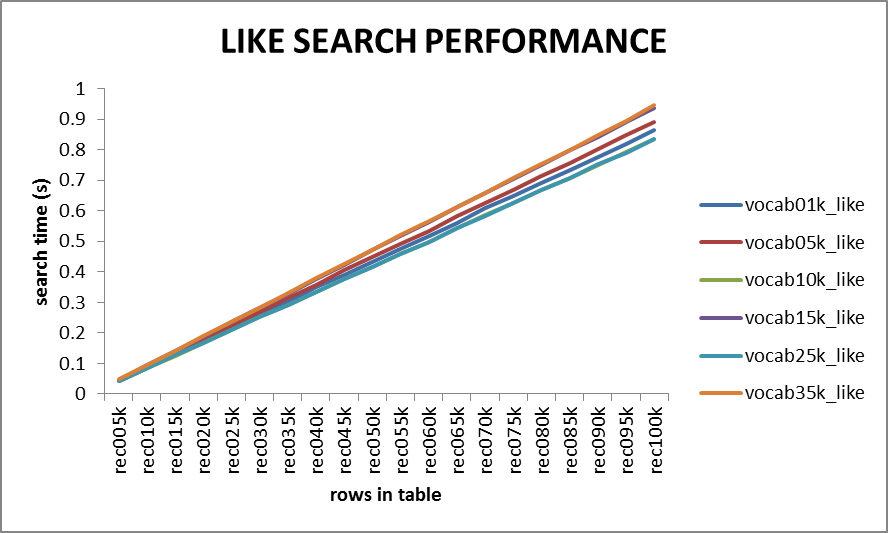
LIKE搜索:
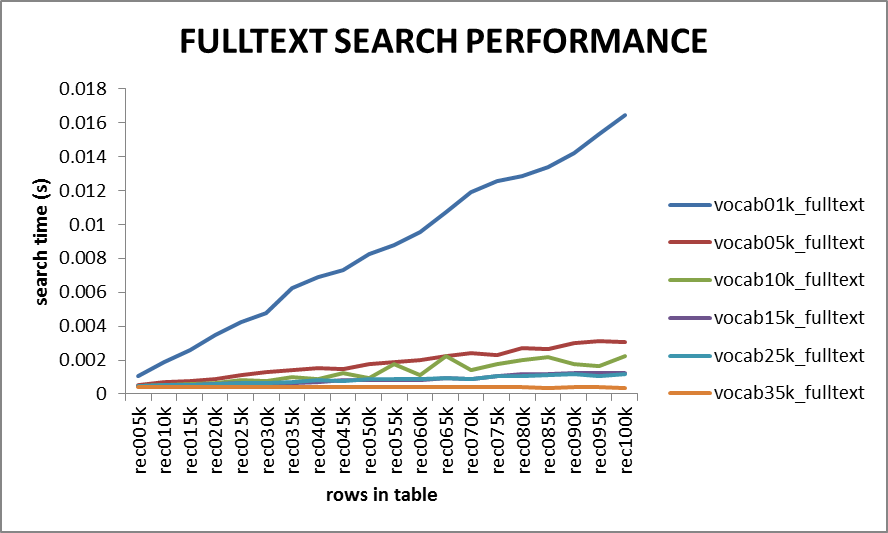
FULLTEXT搜索:
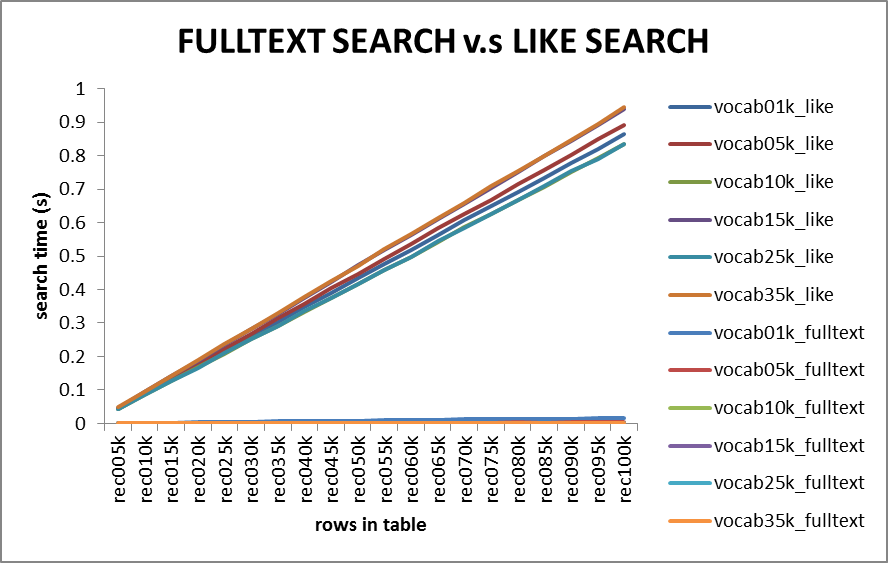
FULLTEXT搜索与LIKE搜索对比:
结果讨论
LIKE搜索的耗时随着记录数的增加而线性增长,但对于10万行记录以下的表(这里共100000*50个单词)搜索时间基本上能保持在1秒以内,所以like搜索的性能也不是特别差。由不同词汇量生成的文本对LIKE搜索的性能影响不大,不同词汇量对应的搜索时间基本上在一个很小的时间范围内变化。
FULLTEXT搜索耗时也随表中记录数的增长而线性增加。对于10万行记录以下的表(这里共100000*50个单词)搜索时间基本上能保持在0.01秒以内。由不同词汇量生成的随机文本对FULLTEXT搜索性能有相对来说比较显著的影响。每行记录中含同样的单词数,这样,较大的词汇量倾向于生成冗余度更低的文本,相应的搜索耗时倾向于更少。这可能与FULLTEXT索引建立单词索引的机制有关,较大的词汇量倾向于生成范围广但相对较浅的索引,因而能快速确定文本是否匹配。
与LIKE搜索相比,FULLTEXT全文搜索的性能要强很多,对于10万行记录的表,搜索时间都在0.02秒以下。因此可以将基于FULLTEXT索引的文本搜索部署于网站项目中的文本搜索功能中。但是,正如上述提到的,无论是LIKE搜索还是FULLTEXT搜索,其性能都会随着记录数的增长而下降,因此,若网站项目中的文本搜索数据库记录数庞大的一定规模后,可能需要考虑使用MySQL数据库全文搜索以外的文本搜索解决方案了。
About Me
.............................................................................................................................................
● 本文作者:小麦苗,部分内容整理自网络,若有侵权请联系小麦苗删除
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、个人简介及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA宝典今日头条号地址:http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826
.............................................................................................................................................
● QQ群号:230161599(满)、618766405
● 微信群:可加我微信,我拉大家进群,非诚勿扰
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-09-01 09:00 ~ 2017-09-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
.............................................................................................................................................
● 小麦苗的微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
● 小麦苗出版的数据库类丛书:http://blog.itpub.net/26736162/viewspace-2142121/
.............................................................................................................................................
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(xiaomaimiaolhr)及QQ群(DBA宝典),学习最实用的数据库技术。
小麦苗的微信公众号 小麦苗的DBA宝典QQ群1 小麦苗的DBA宝典QQ群2 小麦苗的微店
.............................................................................................................................................







来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2144690/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2144690/

