
- 1python中tkinter实现GUI程序:三个实例_python 界面开发实例
- 2putty连接linux设置文件夹,【整理】Windows用ssh连接Linux,想要从Linux上面上传/下载文件 -> putty的子工具psftp...
- 3月球绘画软件测试,宇宙飞船简笔画:第一个登上月球的宇航员
- 4PuTTY用户手册(十二)_puttygen ed25519 key
- 5debug模式下动态代理invoke方法重复执行问题_invocationhandler的invoke方法 会执行多次
- 6【NLP实践-Task3 特征选择】TF-IDF&互信息_tfidftransformer互信息
- 7Android Studio无法自动填充代码的可能原因及解决办法_android studio没有代码补全
- 8postgresql数据库中出现锁表如何解决_pgsql锁表解锁
- 9神经网络发展历程_98年神经网络遇到
- 10nRF52832 DFU升级导致FDS数据丢失的问题_nrf fds烧录被擦除
【图像分类】实战——使用ResNet实现猫狗分类(pytorch)_effnetv2导入
赞
踩
目录
摘要
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常明显。
模型的创新点在于提出残差学习的思想,在网络中增加了直连通道,将原始输入信息直接传到后面的层中,如下图所示:

传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或者梯度爆炸,导致很深的网络无法训练。ResNet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度。VGGNet和ResNet的对比如下图所示。ResNet最大的区别在于有很多的旁路将输入直接连接到后面的层,这种结构也被称为shortcut或者skip connections。

在ResNet网络结构中会用到两种残差模块,一种是以两个3*3的卷积网络串接在一起作为一个残差模块,另外一种是1*1、3*3、1*1的3个卷积网络串接在一起作为一个残差模块。如下图所示:

ResNet有不同的网络层数,比较常用的是18-layer,34-layer,50-layer,101-layer,152-layer。他们都是由上述的残差模块堆叠在一起实现的。 下图展示了不同的ResNet模型。
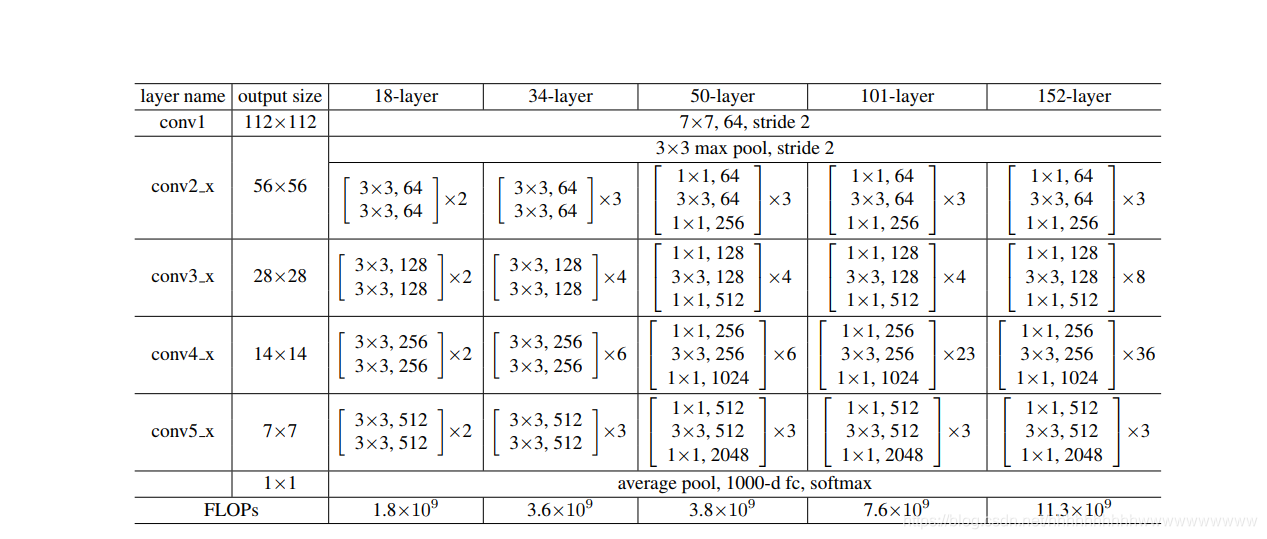
本次使用ResNet18实现图像分类,模型使用pytorch集成的模型。
具体的实现方式可以查考这篇文章。里面说的很详细了。但是我们在实战项目中能用官方的还是优先选用官方的,有预训练模型,而且有的模型还做了优化。
手撕ResNet——复现ResNet(Pytorch)_AI浩-CSDN博客
导入项目使用的库
- import torch.optim as optim
- import torch
- import torch.nn as nn
- import torch.nn.parallel
- import torch.optim
- import torch.utils.data
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
- import torchvision.datasets as datasets
- import torchvision.models
- from effnetv2 import effnetv2_s
- from torch.autograd import Variable
设置全局参数
设置BatchSize、学习率和epochs,判断是否有cuda环境,如果没有设置为cpu。
- # 设置全局参数
- modellr = 1e-4
- BATCH_SIZE = 64
- EPOCHS = 20
- DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
图像预处理
在做图像与处理时,train数据集的transform和验证集的transform分开做,train的图像处理出了resize和归一化之外,还可以设置图像的增强,比如旋转、随机擦除等一系列的操作,验证集则不需要做图像增强,另外不要盲目的做增强,不合理的增强手段很可能会带来负作用,甚至出现Loss不收敛的情况。
- # 数据预处理
-
- transform = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
-
- ])
- transform_test = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
读取数据
使用Pytorch的默认方式读取数据。数据的目录如下图:

训练集,取了猫狗大战数据集中,猫狗图像各一万张,剩余的放到验证集中。
- # 读取数据
- dataset_train = datasets.ImageFolder('data/train', transform)
- print(dataset_train.imgs)
- # 对应文件夹的label
- print(dataset_train.class_to_idx)
- dataset_test = datasets.ImageFolder('data/val', transform_test)
- # 对应文件夹的label
- print(dataset_test.class_to_idx)
-
- # 导入数据
- train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型
使用交叉熵作为loss,模型采用resnet18,建议使用预训练模型,我在调试的过程中,使用预训练模型可以快速得到收敛好的模型,使用预训练模型将pretrained设置为True即可。更改最后一层的全连接,将类别设置为2,然后将模型放到DEVICE。优化器选用Adam。
- # 实例化模型并且移动到GPU
- criterion = nn.CrossEntropyLoss()
- model = torchvision.models.resnet18(pretrained=False)
- num_ftrs = model.fc.in_features
- model.fc = nn.Linear(num_ftrs, 2)
- model.to(DEVICE)
- # 选择简单暴力的Adam优化器,学习率调低
- optimizer = optim.Adam(model.parameters(), lr=modellr)
-
-
- def adjust_learning_rate(optimizer, epoch):
- """Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
- modellrnew = modellr * (0.1 ** (epoch // 50))
- print("lr:", modellrnew)
- for param_group in optimizer.param_groups:
- param_group['lr'] = modellrnew

设置训练和验证
- # 定义训练过程
-
- def train(model, device, train_loader, optimizer, epoch):
- model.train()
- sum_loss = 0
- total_num = len(train_loader.dataset)
- print(total_num, len(train_loader))
- for batch_idx, (data, target) in enumerate(train_loader):
- data, target = Variable(data).to(device), Variable(target).to(device)
- output = model(data)
- loss = criterion(output, target)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- print_loss = loss.data.item()
- sum_loss += print_loss
- if (batch_idx + 1) % 50 == 0:
- print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
- epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
- 100. * (batch_idx + 1) / len(train_loader), loss.item()))
- ave_loss = sum_loss / len(train_loader)
- print('epoch:{},loss:{}'.format(epoch, ave_loss))
-
- def val(model, device, test_loader):
- model.eval()
- test_loss = 0
- correct = 0
- total_num = len(test_loader.dataset)
- print(total_num, len(test_loader))
- with torch.no_grad():
- for data, target in test_loader:
- data, target = Variable(data).to(device), Variable(target).to(device)
- output = model(data)
- loss = criterion(output, target)
- _, pred = torch.max(output.data, 1)
- correct += torch.sum(pred == target)
- print_loss = loss.data.item()
- test_loss += print_loss
- correct = correct.data.item()
- acc = correct / total_num
- avgloss = test_loss / len(test_loader)
- print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
- avgloss, correct, len(test_loader.dataset), 100 * acc))
-
-
- # 训练
-
- for epoch in range(1, EPOCHS + 1):
- adjust_learning_rate(optimizer, epoch)
- train(model, DEVICE, train_loader, optimizer, epoch)
- val(model, DEVICE, test_loader)
- torch.save(model, 'model.pth')
这是有预训练模型的情况下训练的结果,1个epoch就已经得到很好的结果了。

验证
测试集存放的目录如下图:

第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!我们在训练时,cat类别是0,dog类别是1,所以我定义classes为(cat,dog)。
第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
第三步 加载model,并将模型放在DEVICE里,
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
-
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
-
- from torch.autograd import Variable
- import os
- from PIL import Image
-
- classes = ('cat', 'dog')
-
- transform_test = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
-
- DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- model = torch.load("model.pth")
- model.eval()
- model.to(DEVICE)
- path='data/test/'
- testList=os.listdir(path)
- for file in testList:
- img=Image.open(path+file)
- img=transform_test(img)
- img.unsqueeze_(0)
- img = Variable(img).to(DEVICE)
- out=model(img)
- # Predict
- _, pred = torch.max(out.data, 1)
- print('Image Name:{},predict:{}'.format(file,classes[pred.data.item()]))
-
-
运行结果:

其实在读取数据,也可以巧妙的用datasets.ImageFolder,下面我们就用datasets.ImageFolder实现对图片的预测。改一下test数据集的路径,在test文件夹外面再加一层文件件,取名为dataset,如下图所示:

然后修改读取图片的方式。代码如下:
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
- import torchvision.datasets as datasets
- from torch.autograd import Variable
-
- classes = ('cat', 'dog')
- transform_test = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
-
- DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- model = torch.load("model.pth")
- model.eval()
- model.to(DEVICE)
-
- dataset_test = datasets.ImageFolder('data/datatest', transform_test)
- print(len(dataset_test))
- # 对应文件夹的label
-
- for index in range(len(dataset_test)):
- item = dataset_test[index]
- img, label = item
- img.unsqueeze_(0)
- data = Variable(img).to(DEVICE)
- output = model(data)
- _, pred = torch.max(output.data, 1)
- print('Image Name:{},predict:{}'.format(dataset_test.imgs[index][0], classes[pred.data.item()]))
- index += 1
-
完整代码:
train.py
- import torch.optim as optim
- import torch
- import torch.nn as nn
- import torch.nn.parallel
- import torch.optim
- import torch.utils.data
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
- import torchvision.datasets as datasets
- import torchvision.models
- from effnetv2 import effnetv2_s
- from torch.autograd import Variable
-
- # 设置超参数
-
- BATCH_SIZE = 16
- EPOCHS = 10
- DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-
- # 数据预处理
-
- transform = transforms.Compose([
- transforms.Resize((128, 128)),
- # transforms.RandomVerticalFlip(),
- # transforms.RandomCrop(50),
- # transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
-
- ])
- transform_test = transforms.Compose([
- transforms.Resize((128, 128)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
- # 读取数据
- dataset_train = datasets.ImageFolder('data/train', transform)
- print(dataset_train.imgs)
- # 对应文件夹的label
- print(dataset_train.class_to_idx)
- dataset_test = datasets.ImageFolder('data/val', transform_test)
- # 对应文件夹的label
- print(dataset_test.class_to_idx)
-
- # 导入数据
- train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
- modellr = 1e-4
-
- # 实例化模型并且移动到GPU
- criterion = nn.CrossEntropyLoss()
- # model = effnetv2_s()
- # num_ftrs = model.classifier.in_features
- # model.classifier = nn.Linear(num_ftrs, 2)
- model = torchvision.models.resnet18(pretrained=False)
- num_ftrs = model.fc.in_features
- model.fc = nn.Linear(num_ftrs, 2)
- model.to(DEVICE)
- # 选择简单暴力的Adam优化器,学习率调低
- optimizer = optim.Adam(model.parameters(), lr=modellr)
-
-
- def adjust_learning_rate(optimizer, epoch):
- """Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
- modellrnew = modellr * (0.1 ** (epoch // 50))
- print("lr:", modellrnew)
- for param_group in optimizer.param_groups:
- param_group['lr'] = modellrnew
-
-
- # 定义训练过程
-
- def train(model, device, train_loader, optimizer, epoch):
- model.train()
- sum_loss = 0
- total_num = len(train_loader.dataset)
- print(total_num, len(train_loader))
- for batch_idx, (data, target) in enumerate(train_loader):
- data, target = Variable(data).to(device), Variable(target).to(device)
- output = model(data)
- loss = criterion(output, target)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- print_loss = loss.data.item()
- sum_loss += print_loss
- if (batch_idx + 1) % 50 == 0:
- print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
- epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
- 100. * (batch_idx + 1) / len(train_loader), loss.item()))
- ave_loss = sum_loss / len(train_loader)
- print('epoch:{},loss:{}'.format(epoch, ave_loss))
-
- def val(model, device, test_loader):
- model.eval()
- test_loss = 0
- correct = 0
- total_num = len(test_loader.dataset)
- print(total_num, len(test_loader))
- with torch.no_grad():
- for data, target in test_loader:
- data, target = Variable(data).to(device), Variable(target).to(device)
- output = model(data)
- loss = criterion(output, target)
- _, pred = torch.max(output.data, 1)
- correct += torch.sum(pred == target)
- print_loss = loss.data.item()
- test_loss += print_loss
- correct = correct.data.item()
- acc = correct / total_num
- avgloss = test_loss / len(test_loader)
- print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
- avgloss, correct, len(test_loader.dataset), 100 * acc))
-
-
- # 训练
-
- for epoch in range(1, EPOCHS + 1):
- adjust_learning_rate(optimizer, epoch)
- train(model, DEVICE, train_loader, optimizer, epoch)
- val(model, DEVICE, test_loader)
- torch.save(model, 'model.pth')
test1.py
-
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
-
- from torch.autograd import Variable
- import os
- from PIL import Image
-
- classes = ('cat', 'dog')
-
- transform_test = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
-
- DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- model = torch.load("model.pth")
- model.eval()
- model.to(DEVICE)
- path='data/test/'
- testList=os.listdir(path)
- for file in testList:
- img=Image.open(path+file)
- img=transform_test(img)
- img.unsqueeze_(0)
- img = Variable(img).to(DEVICE)
- out=model(img)
- # Predict
- _, pred = torch.max(out.data, 1)
- print('Image Name:{},predict:{}'.format(file,classes[pred.data.item()]))
-
-
test2.py
- import torch.utils.data.distributed
- import torchvision.transforms as transforms
- import torchvision.datasets as datasets
- from torch.autograd import Variable
-
- classes = ('cat', 'dog')
- transform_test = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- ])
-
- DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- model = torch.load("model.pth")
- model.eval()
- model.to(DEVICE)
-
- dataset_test = datasets.ImageFolder('data/datatest', transform_test)
- print(len(dataset_test))
- # 对应文件夹的label
-
- for index in range(len(dataset_test)):
- item = dataset_test[index]
- img, label = item
- img.unsqueeze_(0)
- data = Variable(img).to(DEVICE)
- output = model(data)
- _, pred = torch.max(output.data, 1)
- print('Image Name:{},predict:{}'.format(dataset_test.imgs[index][0], classes[pred.data.item()]))
- index += 1
-

