
- 1华为官方推荐:学习鸿蒙开发高分好书,这6本能帮你很多!_鸿蒙开发 推荐 书籍
- 2ELF文件中得section(.data .bss .text .altinstr_replacement、.altinstr_aux)_.section .datar, data
- 3ssm的maven坐标_ssm maven 坐标
- 4MySQL存储引擎详解(一)-InnoDB架构_mysql引擎innodb
- 5(一)使用AI、CodeFun开发个人名片微信小程序_ai生成小程序代码
- 6求助:R包安装失败_cannot open compressed file description
- 74款超好用的AI换脸软件,一键视频直播换脸(附下载链接)
- 8【深度学习】激活函数(sigmoid、ReLU、tanh)_sigmoid激活函数
- 9操作系统的程序内存结构 —— data和bss为什么需要分开,各自的作用_为什么分bss和data
- 10记一次 Docker Nginx 自定义 log_format 报错的解决方案_log_format" directive no dyconf_version config in
【损失函数】深度学习回归任务中你必须了解的三种损失函数,绝对误差损失(L1 Loss、MAE)均方误差损失(L2 Loss、MSE)以及平滑L1损失(Huber Loss)(2024最新整理)
赞
踩
目录
一、绝对误差损失(L1 Loss、Mean Absolute Error,MAE)
二、均方误差损失(L2 Loss、Mean Squared Error,MSE)
先放一张三种损失函数全家福:
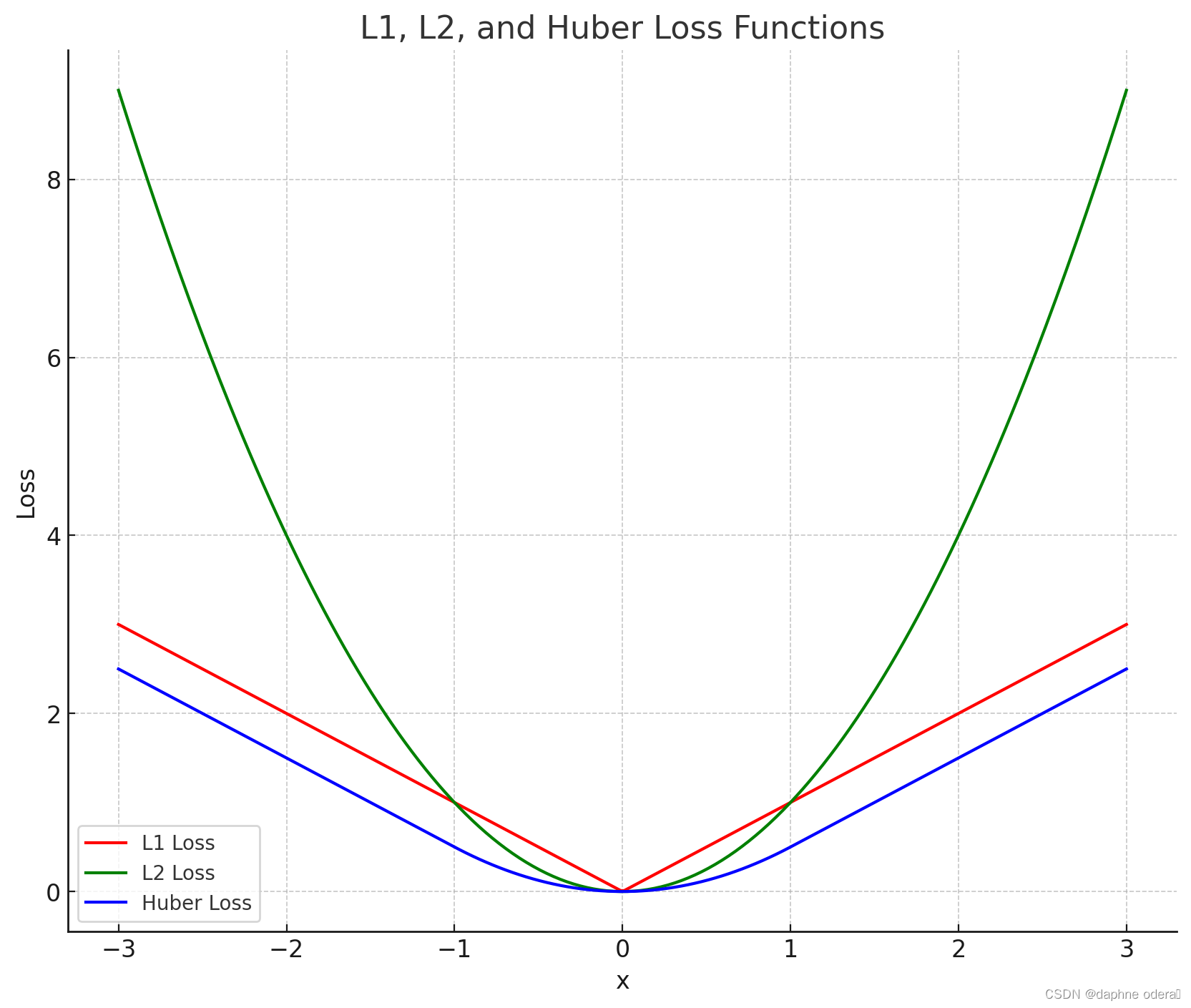
一、绝对误差损失(L1 Loss、Mean Absolute Error,MAE)
1、定义
L1 损失 是预测值和真实值之差的绝对值的总和。
其中,是样本数量,
是第
个样本的真实值,
是第
个样本的预测值。
2、Pytorch 代码
- import torch
- import torch.nn as nn
-
- y_true = torch.tensor([3.0, 4.0, 5.0])
- y_pred = torch.tensor([2.5, 3.5, 5.0])
-
- l1_loss_function = nn.L1Loss()
-
- l1_loss = l1_loss_function(y_pred, y_true)
-
- print("L1 Loss:", l1_loss.item())
3、图像

4、特点
因为它不会对大误差赋予过大的惩罚,对异常值(离群点)包容度较高。
产生的损失函数不是处处可导的,这可能会在优化过程中带来挑战。
促使模型更加稳健(robust),即不受异常值的影响。
二、均方误差损失(L2 Loss、Mean Squared Error,MSE)
1、定义
L2 损失 是预测值和真实值之差的平方的总和。
其中,是样本数量,
是第
个样本的真实值,
是第
个样本的预测值。
2、Pytorch 代码
- import torch
- import torch.nn as nn
-
- y_true = torch.tensor([3.0, 4.0, 5.0])
- y_pred = torch.tensor([2.5, 3.5, 5.0])
-
- l2_loss_function = nn.MSELoss() # 均方误差损失 (MSE) 是 L2 损失的另一种称呼
-
- l2_loss = l2_loss_function(y_pred, y_true)
-
- print("L2 Loss:", l2_loss.item())
3、图像

4、特点
因为对于较大的误差赋予了更高的惩罚,使得模型倾向于减少较大的误差,但这也可能导致模型对异常值过于敏感。
产生的损失函数是平滑且处处可导的,这使得优化算法(如梯度下降)更容易找到最小值。
倾向于没有很大波动的解,通常导致在模型预测中的较小差异。
三、 平滑L1损失(Huber Loss)
1、定义
Huber Loss 是一种用于回归任务的损失函数,它在预测值与目标值之间引入了平滑,相比于均方误差(MSE)对异常值更具鲁棒性。
其中, 是第
个样本的真实值,
是第
个样本的预测值,
是控制平滑范围的阈值。
2、Pytorch 代码
- import torch
- import torch.nn as nn
-
- class HuberLoss(nn.Module):
- def __init__(self, delta=1.0):
- super(HuberLoss, self).__init__()
- self.delta = delta
-
- def forward(self, y_true, y_pred):
- diff = torch.abs(y_true - y_pred)
- loss = torch.where(diff < self.delta, 0.5 * diff ** 2, self.delta * (diff - 0.5 * self.delta))
- return torch.mean(loss)
-
- # 示例
- delta_value = 1.0
- criterion = HuberLoss(delta=delta_value)
-
- # 创建一些示例数据
- y_true = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
- y_pred = torch.tensor([0.9, 2.5, 3.5], requires_grad=True)
-
- # 计算损失
- loss = criterion(y_true, y_pred)
-
- # 打印结果
- print("Huber Loss:", loss.item())
3、图像
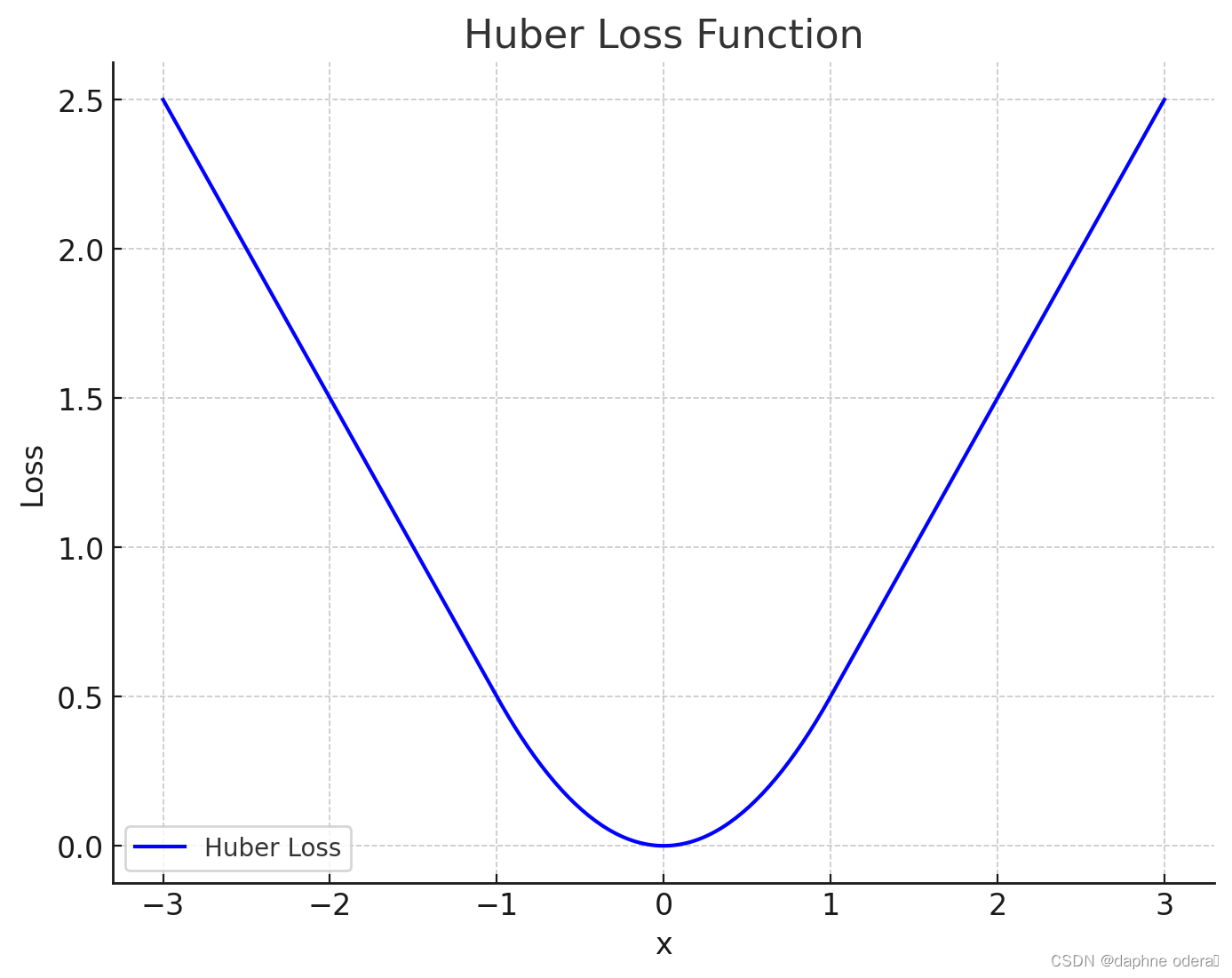
Huber Loss 在 x 的小值(在此示例中,阈值 delta 设置为 1.0)时表现为一个抛物线(类似于 L2 损失),而在大值时变成线性(类似于 L1 损失)。
4、特点
结合了 L1 和 L2 损失特点的设计,使得 Huber Loss 对于异常值不那么敏感。
引入了一个可调参数 ,可以更灵活地适应不同数据集的特性。
在预测值与目标值接近时表现得像均方误差,具有较强的平滑性。而在较远的情况下表现得像绝对误差,保持了一定的敏感性,有助于防止过拟合。
四、深度分析
1、对比 L1 损失和 L2 损失
对异常值的敏感性: L1 损失对异常值更敏感。它试图减少预测值和真实值之间差异的绝对值,使得模型对异常值更加敏感。而 L2 损失通过平方差减少异常值的影响。
优化难度: L1 损失可能导致优化问题,在损失函数的绝对值点上不可导。而 L2 损失因为处处可导,通常在数学上更易于处理。
结果特性: L1 损失通常导致更稀疏的结果,这在某些情况下是有益的,比如特征选择。L2 损失则倾向于更平滑的解决方案。
总结来说,选择 L1 损失还是 L2 损失取决于具体的应用场景和对异常值的敏感度。在某些情况下,将两者结合使用(如 Elastic Net 回归)可能会产生更好的结果。
2、为何使用Huber损失函数?
使用MAE用于训练神经网络的一个大问题就是,如下图左半部分所示,它的梯度始终很大,这会导致使用梯度下降训练模型时,在结束时遗漏最小值。对于MSE,如下图右半部分所示,梯度会随着损失值接近其最小值逐渐减少,从而使其更准确。

在这些情况下,Huber损失函数真的会非常有帮助,因为它围绕的最小值会减小梯度。而且相比MSE,它对异常值更具鲁棒性。因此,它同时具备MSE和MAE这两种损失函数的优点。不过,Huber损失函数也存在一个问题,我们可能需要训练超参数δ,而且这个过程需要不断迭代。
3、L1损失 L2损失 Huber损失成立的先验假设?
这三个 loss 是回归任务中最直观也是最常见的 loss,前两者都假设了误差服从某种特定分布,然后通过最大似然估计(MLE)确定最终的 loss 形式,huber 则是前两种 loss 的混合版本。
MSE 其假设是预估值和真实值的误差服从标准高斯分布,然后写出误差的似然 (likelihood) 函数,并通过最大似然估计推导出来最终的 loss 的形式。
MAE 的推导跟 MSE 很类似,只是假设误差服从拉普拉斯分布。
这部分内容想深入探讨请移步传送门:回归任务里的损失函数 - 知乎 (zhihu.com) (初学者不建议,内容复杂)
五、内容拓展
更多内容请查阅我另一篇博客:
文章链接:
回归损失函数:Huber Loss_huber函数-CSDN博客
高斯分布:
高斯分布(也称为正态分布)的概率密度函数(PDF)是用来描述正态分布的特性的重要公式。
其中, 是随机变量
的期望,
是方差,而
是标准差。


