- 12015年认证杯SPSSPRO杯数学建模A题(第二阶段)绳结全过程文档及程序
- 2sklearn.tree.DecisionTreeClassifier()函数解析_decisiontreeclassifier函数
- 3python PyQt5的安装_pyqt5 安装
- 4工业制造中的大数据分析应用_工业大数据分析方案-美林数据_大数据分析在工业应用
- 5Resource punkt not found_tensorflow resource punkt not found
- 6更多代码阅读及测试(词典操作)_user_dict.txt
- 7在Blender中使用代码控制人物模型的头部姿态 - 前置知识_头部姿态 控制
- 8杨强 : 迁移学习——人工智能的最后一公里
- 9【多模态】17、CORA | 将 CLIP 使用到开集目标检测_clip 目标检测
- 10机器学习 主成分分析(Principal Component Analysis)_机器学习主成分分析
计算机视觉:图像特征与描述大全 ,有代码(一篇博文带你简单了解完图像特征提取技术)_计算机视觉 分析图片的特点代码
赞
踩
图像特征提取是 我们在做图像分类,图像检测,图像分割等任务前的任务。
图像特征提取的好坏,一定程度上决定着后续任务最终的结果。是特征工程,特征工程的重要性就不多说啦把,它决定着一个任务的上限成就。
算法还是其次的。
本文介绍图像特征提取。
使用的编程语言:python
本文的原理文字部分借鉴了不是少博主的,感谢各位大佬。
本文只是将这些总结起来,供自己以后做图像任务时参考,以便自己可以选择合适的特征选取方法。
毕竟本文涉及到的太多,所以每一个知识点只是简单讲解。
能力有限,博主不够聪明,未能从公式层进行细讲原理。
1直方图
具体讲解链接:
opencv进阶学习笔记7:直方图,直方图均衡化,直方图比较,直方图反向投影
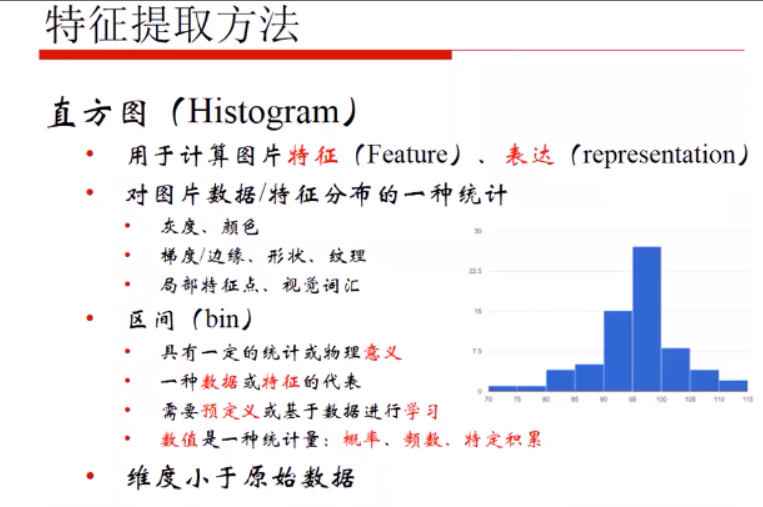
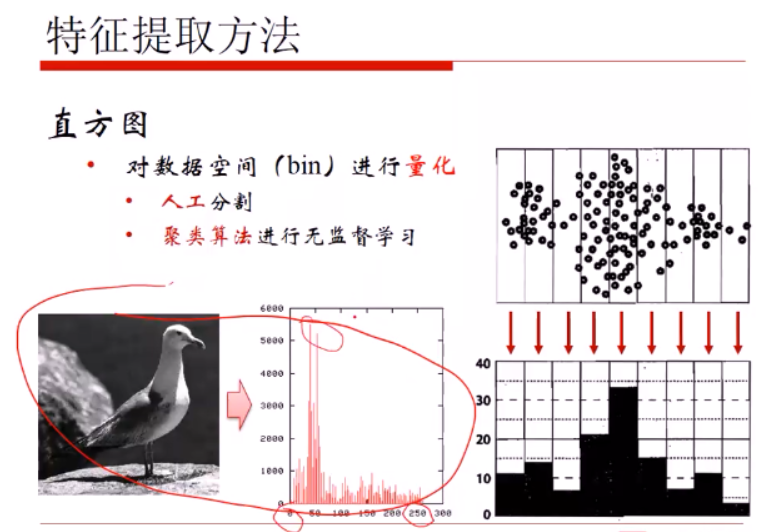
bins的选择很重要:太多如256导致数据稀疏,太小则损失数据信息啦。
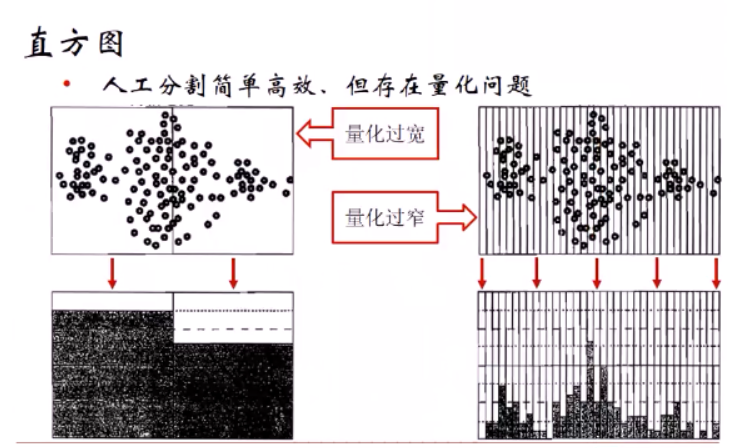
2聚类

假设存在一张200×200像素的灰度图像,它由40000个RGB灰度级组成,我们通过K-Means可以将这些像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有的像素点,这样就能实现在不改变分辨率的情况下量化压缩图像颜色,实现图像颜色层级分割。
OpenCV中kmeans
retval, bestLabels, centers = kmeans(data, K, bestLabels, criteria, attempts, flags[, centers])
data表示聚类数据,最好是np.flloat32类型的N维点集
K表示聚类类簇数
bestLabels表示输出的整数数组,用于存储每个样本的聚类标签索引
criteria表示算法终止条件,即最大迭代次数或所需精度。在某些迭代中,一旦每个簇中心的移动小于criteria.epsilon,算法就会停止
attempts表示重复试验kmeans算法的次数,算法返回产生最佳紧凑性的标签
flags表示初始中心的选择,两种方法是cv2.KMEANS_PP_CENTERS ;和cv2.KMEANS_RANDOM_CENTERS
centers表示集群中心的输出矩阵,每个集群中心为一行数据
1灰度图图像聚类
import cv2
import numpy as np
import matplotlib.pyplot as plt
#
def grayjulei(img,k,attempts=2):#attempts 重复聚类算法次数,k聚类中心数
# 获取图像高度、宽度
rows, cols = img.shape[:]
# 图像二维像素转换为一维
data = img.reshape((rows * cols, 1))
data = np.float32(data) #
# 定义终止条件 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置示初始中心的选择
flags = cv2.KMEANS_RANDOM_CENTERS
# K-Means聚类
compactness, labels, centers = cv2.kmeans(data, k, None, criteria, attempts, flags)
# 生成最终图像
dst = labels.reshape((img.shape[0], img.shape[1]))
return dst
#读取原始图像灰度颜色
img = cv2.imread('duoren.jpg', 0)#读取灰度图格式
dst=grayjulei(img,3,10)#得到dst为int32型,无法cv显示图
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图像
titles = [u'原始图像', u'聚类图像']
images = [img, dst]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
结果:
我们把提取的dst用于模型输入就可以。
注意在大量图像数据时,应统一图片尺寸,然后再做聚类,使得到的dst维度也一样。

打印下dst

2彩色图像聚类
import cv2
import numpy as np
#
def RgbJulei(img,k,attempts=2):#attempts 重复聚类算法次数,k聚类中心数
# 图像二维像素转换为一维
data = img.reshape((-1,3))
data = np.float32(data) #转为flaot型
# 定义终止条件 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置示初始中心的选择
flags = cv2.KMEANS_RANDOM_CENTERS
# K-Means聚类
compactness, labels, centers = cv2.kmeans(data, k, None, criteria, attempts, flags)
# 图像转换回uint8二维类型
centers2 = np.uint8(centers)#centers为聚类中心点的像素值,labels为每个像素点的类型索引值,是1,2,3这种
res = centers2[labels.flatten()]#求取每个像素点新的像素值
dst = res.reshape((img.shape))
return dst
#读取原始图像灰度颜色
img = cv2.imread('duoren.jpg')#读取彩色图格式
dst=RgbJulei(img,3,10)#
cv2.imshow('img',img)
cv2.imshow('result',dst)
cv2.waitKey()
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

3颜色特征
特征1.提取RGB各通道的直方图,
特征2.提取颜色聚类后的直方图


4几何特征
几何特征1:边缘提取
具体讲解链接:
opencv进阶学习笔记11:cannny边缘检测,直线检测,圆检测
opencv学习笔记18:canny算子边缘检测原理及其函数使用
阈值的大小,决定着边缘提取好坏。

边缘有亮度上的变化和颜色上的变化。


这里的滤波主要指高斯滤波,用于在边缘提取前进行去噪。

几何特征2:兴趣点关键点
模仿人类从图中找出关键点。点要多和显著。
不一定是视觉上的关键点,是算法上的关键点就可以。
一般会从边缘信息找关键点。边缘信息要丰富才好。

关键点特征:
轮廓之间的交点;
对于同一场景,即使视角发生变化,通常具备稳定性质的特征;
该点附近区域的像素点无论在梯度方向上还是其梯度幅值上有着较大变化;
一:Harris角点检测
思想:
算法基本思想是使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
原理如图所示:移动小窗,如果发现在某一个区域小窗内的元素变化很大,则认为这个区域存在关键点。

原理公式:
xy为坐标,U,V为两个方向的偏移量。
I(x+u,y+v) 为移动后的框内像素,
I(x,y) 为移动前的框内像素
w(x,y)是窗口函数矩阵,一般以高斯权重为主,离中心点越近权重越高。也有矩阵权重的。
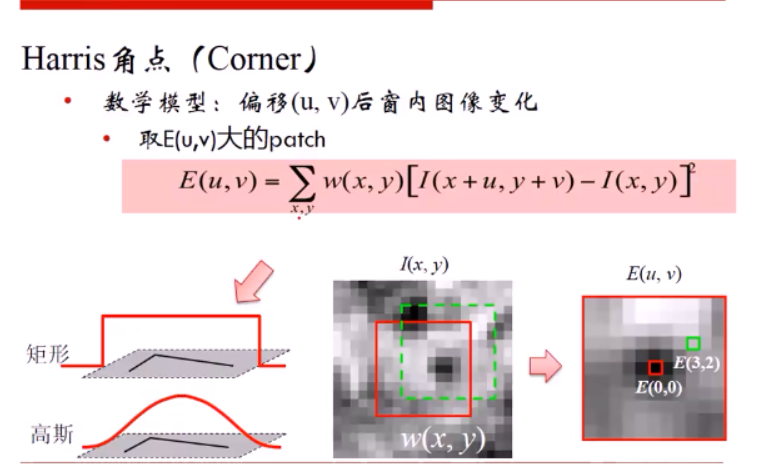
流程:

OpenCV实现
dst = cv.cornerHarris( src, blockSize, ksize, k[, dst[, borderType]] )
src:输入单通道8位或浮点图像;
blockSize:角点检测中指定区域的大小;
ksize:Sobel求导中使用的窗口大小;
k:取值参数为 [0,04,0.06]。
Note:在Harris角点检测中应用到了sobel算子,其主要作用在于求X轴以及Y轴上的梯度即导数。
import numpy as np
import cv2 as cv
img = cv.imread("duoren.jpg")
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)#转换为灰度图
img_gray = np.float32(img_gray)
#角点检测
Harris = cv.cornerHarris(img_gray, 2, 3, 0.04)
print("img_shape:", img.shape)#(399, 600, 3)
print("harris_shape:", Harris.shape)#(399, 600)
#筛选角点,选取大于0.01max的关键点。
img[Harris > (0.01 * Harris.max())] = [0,0,255]
cv.imshow("cornerHarris", img)
cv.waitKey(0)
cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
提取到的Harris 作为输入特征。

二:斑点
斑点通常是指与周围有着颜色和灰度差别的区域。在实际地图中,往往存在着大量这样的斑点,如一颗树是一个斑点,一块草地是一个斑点,一栋房子也可以是一个斑点。由于斑点代表的是一个区域,相比单纯的角点,它的稳定性要好,抗噪声能力要强,所以它在图像配准上扮演了很重要的角色。
同时有时图像中的斑点也是我们关心的区域,比如在医学与生物领域,我们需要从一些X光照片或细胞显微照片中提取一些具有特殊意义的斑点的位置或数量。
涉及到的拉普拉斯梯度:
opencv学习笔记17:梯度运算之laplacian算子及其应用

import cv2 as cv
import numpy as np
def Blob(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
params = cv.SimpleBlobDetector_Params()
# Change thresholds
params.minThreshold = 0;
params.maxThreshold = 256;
# Filter by Area.
params.filterByArea = True # 斑点面积的限制变量
params.minArea = 10 # 斑点的最小面积 还有最大面积maxArea
# Filter by Circularity
params.filterByCircularity = True # 斑点圆度的限制变量,默认是不限制
params.minCircularity = 0.1 # 斑点的最小圆度
# Filter by Convexity
params.filterByConvexity = True # 斑点凸度的限制变量
params.minConvexity = 0.5
# Filter by Inertia
params.filterByInertia = True
params.minInertiaRatio = 0.5
detector = cv.SimpleBlobDetector_create(params)
# Detect blobs.
cv.imshow("input", image)
keypoints = detector.detect(gray)
result = cv.drawKeypoints(image, keypoints, None, (0, 0, 255), cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#print(result)
cv.imshow("result", result)
frame = cv.imread("duoren.jpg")
Blob(frame)
cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
返回的一个 keypoints是一个一个有很多不用属性的特殊结构体,属性当中有坐标,方向、角度等等
不同图像点不一样。所有传入我们图像分类训练模型的是一张带有很多点的图,而不是输入这些点。
cv2.drawKeypoints()绘制点函数主要包含五个参数:
image:也就是原始图片
keypoints:从原图中获得的关键点,这也是画图时所用到的数据
outputimage:输出
color:颜色设置,通过修改(b,g,r)的值,更改画笔的颜色,b=蓝色,g=绿色,r=红色。
flags:绘图功能的标识设置
cv2.DRAW_MATCHES_FLAGS_DEFAULT, cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG, cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS

三:SIFT
之前的harris算法和Shi-Tomasi 算法,由于算法原理所致,具有旋转不变性,在目标图片发生旋转时依然能够获得相同的角点。但是如果对图像进行缩放以后,再使用之前的harris算法就会检测不出来。


import cv2
import numpy as np
img = cv2.imread('duoren.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()#导入包
kp = sift.detect(gray,None)#找到关键点
img=cv2.drawKeypoints(gray,kp,img)#绘制关键点
cv2.imshow('result',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

关键点kp 为一个有很多不用属性的特殊结构体,属性当中有坐标,方向、角度等等。
不同图像点不一样。所有传入我们图像分类训练模型的是一张带有很多点的图,而不是输入这些点。
如果未找到关键点,可使用函数sift.detectAndCompute()直接找到关键点并计算。
kp, des = sift.detectAndCompute(gray,None)
在第二个函数中,kp为关键点列表,des为numpy的数组,为关键点数目×128
import cv2
import numpy as np
img = cv2.imread(‘duoren.jpg’)
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
print(gray.shape)
#kp = sift.detect(gray,None)#找到关键点
kp, des = sift.detectAndCompute(gray,None)
print(kp)
print(des.shape)

5纹理特征
纹理:边缘的组合
1:HOG 方向梯度直方图


OpenCV实现
hog=cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins,derivAperture,winSigma,
常用的是winSize, blockSize, blockStride, cellSize, nbins这四个,分别是窗口大小(单位:像素)、block大小(单位:像素)、block步长(单位:像素)、cell大小(单位:像素)、bin的取值
import numpy as np
import cv2
img = cv2.imread("duoren.jpg")
img=cv2.resize(img,(400,300),fx=None,fy=None)
print(img.shape)
#在这里设置参数
winSize = (128,128)
blockSize = (64,64)
blockStride = (8,8)
cellSize = (16,16)
nbins = 9
#定义对象hog,同时输入定义的参数,剩下的默认即可
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
winStride = (8,8)
padding = (8,8)
test_hog = hog.compute(img, winStride, padding).reshape((-1,))
print(test_hog.shape)
#(10357632,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
compute常用的参数有3个,第一个是必须的参数,就是图片(用opencv读取的numpy-nparray,经测试3通道BGR或者单通道灰度图都可以,而且结果也一样)数据结构。第二个是winStride,是窗口滑动步长(影响最终n的大小)。第三个是padding,填充,就是在外面填充点来处理边界。
返回的是一个一维数组
当不同图片的尺寸大小一样时,返回的一维数组维度也一样。
进阶应用:
HOG+SVM实现行人检测
import cv2 as cv
# 读取图像
src = cv.imread("duoren.jpg")
cv.imshow("input", src)
# HOG + SVM
hog = cv.HOGDescriptor()
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector())
# Detect people in the image
(rects, weights) = hog.detectMultiScale(src,winStride=(4, 4), padding=(8, 8),scale=1.25,useMeanshiftGrouping=False)
# 矩形框
for (x, y, w, h) in rects:
cv.rectangle(src, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示
cv.imshow("result", src)
cv.waitKey(0)
cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

2:LBP


通俗的理解是将周围的像素与中间位置像素进行比较,并将比较结果以0 | 1写入对应的像素位中(etc: 左上角 1 < 5 , 故 第二幅图左上角写入 0),从左上角顺时针依次填入二进制字符串中(二进制表示依次为: 00010011),然后转换成十进制(19),即是结果
mport cv2
import numpy as np
from skimage.feature import local_binary_pattern
img = cv2.imread('duoren.jpg')
#显示到plt中,需要从BGR转化到RGB,若是cv2.imshow(win_name, image),则不需要转化
#image1 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#灰度转换
print(image.shape)
# settings for LBP
radius = 1 # LBP算法中范围半径的取值
n_points = 4 * radius # 领域像素点数
lbp = local_binary_pattern(image, n_points, radius)
print(lbp.shape)
cv2.imshow('input',img)
cv2.imshow('result',lbp)
cv2.waitKey()
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
返回结果和图像灰度尺寸一致

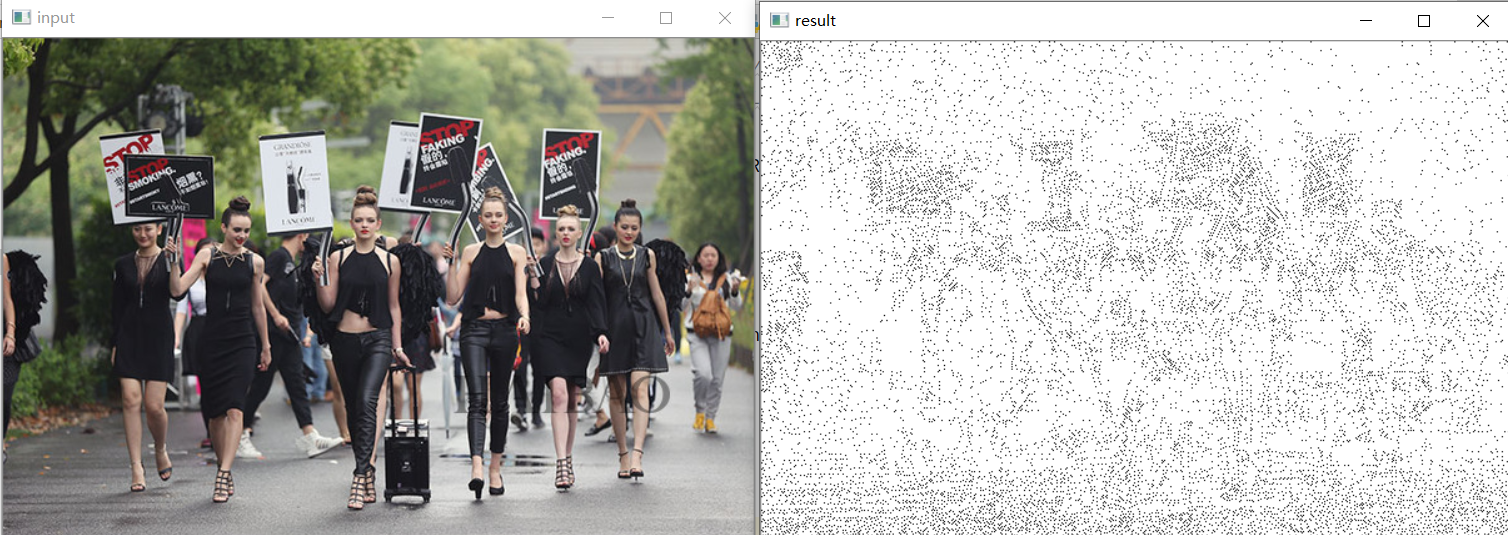
3:Gabor滤波器组
Gabor是一个用于边缘提取的线性滤波器,其频率和方向表达与人类视觉系统类似,能够提供良好的方向选择和尺度选择特性,而且对于光照变化不敏感,因此十分适合纹理分析。
Fourier 变换是一种信号处理的有力工具,可以将图像从空域转换到频域,并提取到空域上不易提取到的特征。但是Fourier变换缺乏时间和位置的局部信息。
Gabor 变换是一种短时加窗Fourier变换(简单理解起来就是在特定时间窗内做Fourier变换),是短时傅里叶变换中窗函数取为高斯函数时的一种特殊情况。因此,Gabor滤波器可以在频域上不同尺度、不同方向上提取相关的特征。另外,Gabor函数与人眼的作用相仿,所以经常用作纹理识别上,并取得了较好的效果。
在二维空间中,使用一个三角函数(a)(如正弦函数)与一个高斯函数(b)叠加,我们得到了一个Gabor滤波器©。如下图所示:

数学表达式:

波长(λ):表示Gabor核函数中余弦函数的波长参数。它的值以像素为单位制定,通常大于等于2,但不能大于输入图像尺寸的1/5.
方向(θ):表示Gabor滤波核中平行条带的方向。有效值为从0°到360°的实数。
相位偏移(ψ):表示Gabor核函数中余弦函数的相位参数。它的取值范围为-180°到180°。其中,0°与180°对应的方程与原点对称,-90°和90°的方程关于原点成中心对称。
长宽比(γ):空间纵横比,决定了Gabor函数形状的椭圆率。当γ=1时,形状是圆形;当γ<1时,形状随着平行条纹方向而拉长。通常该值为0.5.
该段原理借鉴:
Gabor滤波器详解
代码实现:
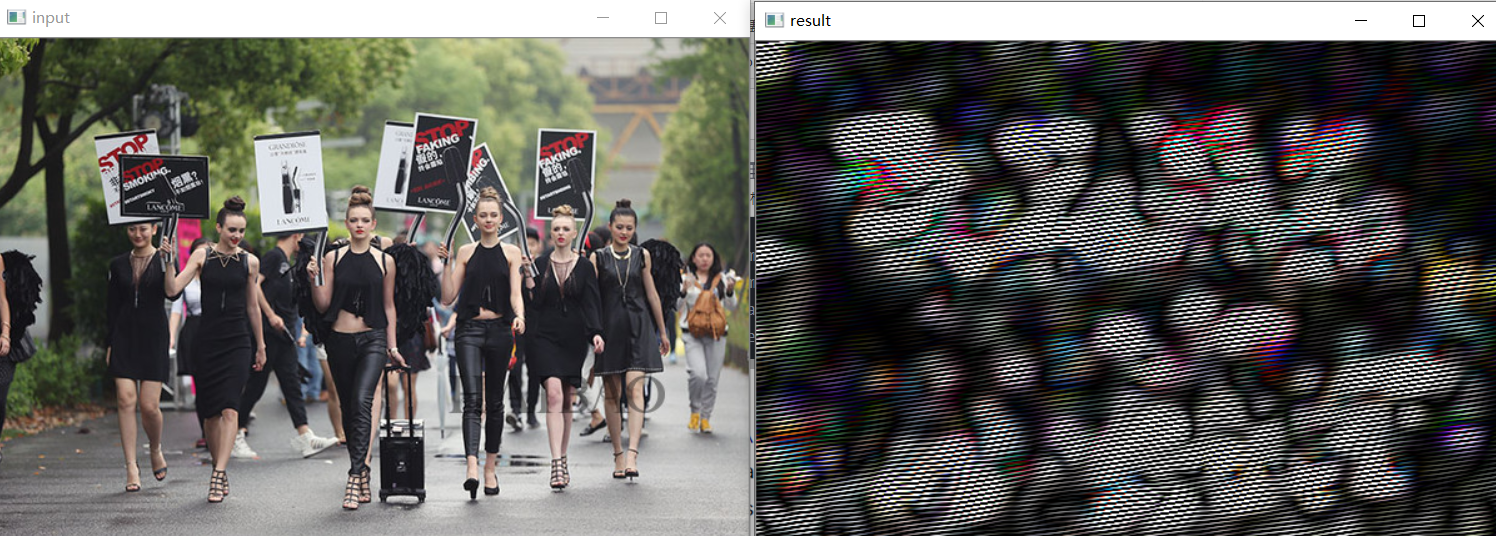
import numpy as np
import cv2 as cv
# retval = cv.getGaborKernel(ksize, sigma, theta, lambd, gamma[, psi[, ktype]])
# Ksize 是一个元组
retval = cv.getGaborKernel(ksize=(111,111), sigma=10, theta=6, lambd=1, gamma=1.2)
image1 = cv.imread('duoren.jpg')
# dst = cv.filter2D(src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]])
result = cv.filter2D(image1,-1,retval)
print('image1.shape:',image1.shape)
print('result.shape:',result.shape)
cv.imshow('input',image1)
cv.imshow('result',result)
cv.waitKey(0)
cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
电气专业的计算机萌新,写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢。
自学人工智能一年多,从入门到放弃,以前还有点想法:靠这个吃饭。
现在看来,还是将这个作为自己专业的辅助吧。