
- 1词性标注教程_propn
- 2Android使用Tesseract-ocr进行文字识别_android tesseract
- 3基于神经网络的依存句法分析_神经网络 依存句法分析
- 4跟着Kimi Chat学习提示工程Prompt Engineering!让AI更高效地给你打工!
- 5区别探索:掩码语言模型 (MLM) 和因果语言模型 (CLM)的区别
- 6UEditor富文本编辑器
- 7人工智能原理(学习笔记)_生理学派起源于仿生学
- 8知识图谱基础知识(一): 概念和构建_本体作为知识图谱的模式层,在约束概念关系、明确概念属性上起到了重要 作用。
- 9TCP系列教程—SIM7000X TCP 通信猫之旅_tcp 猫
- 10【NLP】第15章 从 NLP 到与任务无关的 Transformer 模型_google/reformer-crime-and-punishment
基于知识图谱的问答系统(下)_命名实体识别在知识图谱问答系统中是哪个步骤
赞
踩
基于知识图谱的问答系统(下)
本项目是基于知识图谱的问答系统,BERT/BILSTM+CRF做命名实体识别和句子相似度比较,最后实现线上的部署。
项目的分以下步骤进行描述:
- 1-项目介绍
- 1.1-数据集介绍
- 1.2-技术方案流程
- 1.3-评价标准 - 2-命名实体识别模型训练代码理解
- 2.1-数据集准备
- 2.2-数据预处理
- 2.3-定义主模型 - 3-BERT-BILSTM-CRF原理及使用
- 3.1-BERT原理介绍
- 3.2-BERT+CRF模型
- 3.3-训练结果
- 3.4-预测 - 4-属性映射模型原理和训练代码
- 4.1-数据集处理
- 4.2-BERT分类模型训练 - 5-知识库导入数据库,并抽取三元组
- 5.1-知识库导入数据库
- 5.2-返回分数最高的三元组
- 5.3-预测 - 6-总结
- 7-参考
1-项目介绍
1.1-数据集介绍
NLPCC全称自然语言处理与中文计算会议(The Conference on Natural Language Processing and Chinese Computing),它是由中国计算机学会(CCF)主办的 CCF 中文信息技术专业委员会年度学术会议,专注于自然语言处理及中文计算领域的学术和应用创新。
此次使用的数据集来自NLPCC ICCPOL 2016 KBQA 任务集,其包含 14 609 个问答对的训练集和包含 9 870 个问答对的测试集。 并提供一个知识库,包含 6 502 738 个实体、 587 875 个属性以及 43 063 796 个 三元组。知识库文件中每行存储一个事实( fact) ,即三元组 ( 实体、属性、属性值) 。各文件统计如下:
训练集:14609
开发集:9870
知识库:43063796
- 1
- 2
- 3
知识库样里如下:
空气干燥 ||| 别名 ||| 空气干燥
空气干燥 ||| 中文名 ||| 空气干燥
空气干燥 ||| 外文名 ||| air drying
空气干燥 ||| 形式 ||| 两个
空气干燥 ||| 作用 ||| 将空气中的水份去除
- 1
- 2
- 3
- 4
- 5
原数据中本只有问答对(question-answer),并无标注三元组(triple),本人所用问答对数据来自该比赛第一名的预处理https://github.com/huangxiangzhou/NLPCC2016KBQA。构造Triple的方法为从知识库中反向查找答案,根据问题过滤实体,最终筛选得到,也会存在少量噪音数据。该Triple之后用于构建实体识别和属性选择等任务的数据集。
<question id=1> 《机械设计基础》这本书的作者是谁?
<triple id=1> 机械设计基础 ||| 作者 ||| 杨可桢,程光蕴,李仲生
<answer id=1> 杨可桢,程光蕴,李仲生
==================================================
<question id=2> 《高等数学》是哪个出版社出版的?
<triple id=2> 高等数学 ||| 出版社 ||| 武汉大学出版社
<answer id=2> 武汉大学出版社
==================================================
<question id=3> 《线性代数》这本书的出版时间是什么?
<triple id=3> 线性代数 ||| 出版时间 ||| 2013-12-30
<answer id=3> 2013-12-30
==================================================
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.2-技术方案流程
- 1 输入问句
- 2 通过实体识别模型检测问句中的实体,得到实体(BERT+LSTM+CRF)
- 3 在知识库中检索实体,得到和实体相关的前n个三元组。
- 4 通过属性抽取模型在n个三元组中挑选最合适的属性,得到唯⼀三元组 (BERT)
- 5 输出答案
第一步:主要模型构建
基于知识图谱的⾃动问答主要的模型主要有两个:
命名实体识别步骤和属性映射步骤。(就是上述流程的第2、4步)
其中,实体识别步骤的⽬的是找到问句中询问的实体名称,如下图,就是找到“⽯头记”这个实体。
⽽属性映射步骤的⽬的在于找到问句中询问的相关属性,如下图,就是找到这句话问的是“作者”这个属
性。
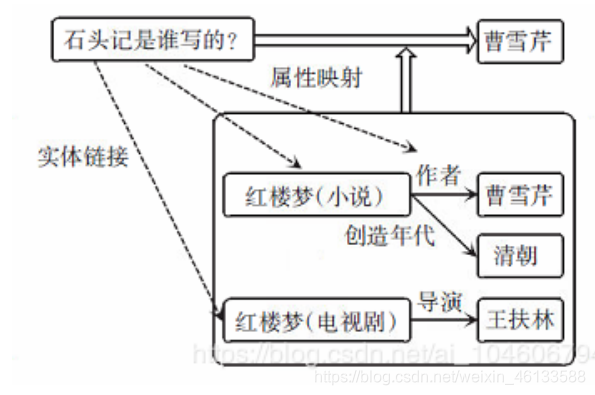
命名实体识别步骤,采⽤BERT+BiLSTM+CRF⽅法(另外加上⼀些规则映射,可以提⾼覆盖度)。
属性映射步骤,转换成⽂本相似度问题,采⽤BERT作⼆分类训练模型。
第二步:通过实体识别模型检测问句中的实体,得到实体
输⼊任意⼀个问句,⽤上⼀步训练好的命名实体识别模型进⾏预测。
本项⽬⽀持在线预测,即可以⾃⼰输⼊⼀句话,然后进⾏预测,得到实体,预测完后,可以再次输⼊。
第三步:在知识库中检索实体,得到和实体相关的前n个三元组。
完成实体识别模型和属性抽取模型后还需进⾏知识库检索。
由于知识库数据量庞⼤,不可能加载到缓存中遍历检索知识库。所以可以导⼊到mysql数据库中,然后
按上步预测的三元组的实体进⾏检索,得到和实体相关的前n个三元组。
第四步:通过属性抽取模型在n个三元组中挑选最合适的属性,得到唯⼀三元组。
这步采⽤了两种⽅式来返回答案。
- ⾮语义匹配:如果前n个三元组有某个三元组的属性是输⼊问题字符串的⼦集(相当于字符串匹配),将
这个三元组的答案作为正确答案返回。 - 语义匹配:⾮语义匹配失败后,可以再利⽤bert对前n个三元组的属性进⾏打分,排序,输出topK个
答案,选择分数最⾼的作为正确答案返回。
1.3-评价标准
命名实体识别和属性映射评价标准:召回率 (Recall),精确率 (Precision) ,F1-Score。⽽对话系统的评价标准以⼈⼯评价为主,以及BLEU和Perplexity。
2-命名实体识别模型训练代码理解
2.1-数据预处理
清洗训练数据、测试数据、知识库过滤属性,去除‘-’,‘•’,空格等噪音符号;同时把每一行lower()转成小写。
https://github.com/huangxiangzhou/NLPCC2016KBQA
2.2-[数据集准备]
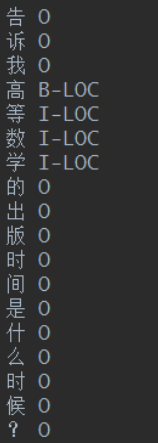
构造NER的数据集,我们的数据是有三元组实体信息的,可以反向标注问题,给训练集和测试集的
Question 打标签。我们这⾥采⽤BIO的标注⽅式,因为识别⼈名,地名,机构名的任务不是主要的,我
们只要识别出实体就可以了,因此,我们⽤B-LOC, I-LOC代替其他的标注类型,如下图,这⾥B是句
⾸,I是句中,O是⾮实体。
构造SIM的数据集:一个sample由“问题+属性+Label”构成,原始数据中的属性值置为1
0 你知道计算机应用基础这本书的作者是谁吗? 作者 1
1 你知道计算机应用基础这本书的作者是谁吗? 稀有程度 0
2 你知道计算机应用基础这本书的作者是谁吗? 已离开成员 0
3 你知道计算机应用基础这本书的作者是谁吗? 界面语言 0
4 你知道计算机应用基础这本书的作者是谁吗? 跨度 0
5 你知道计算机应用基础这本书的作者是谁吗? 英文名称 0
6 计算机应用基础这本书的出版社是那个? 出版社 1
7 计算机应用基础这本书的出版社是那个? 投资 0
8 计算机应用基础这本书的出版社是那个? 罗马拼音 0
9 计算机应用基础这本书的出版社是那个? 出身 0
10 计算机应用基础这本书的出版社是那个? 出生时间 0
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
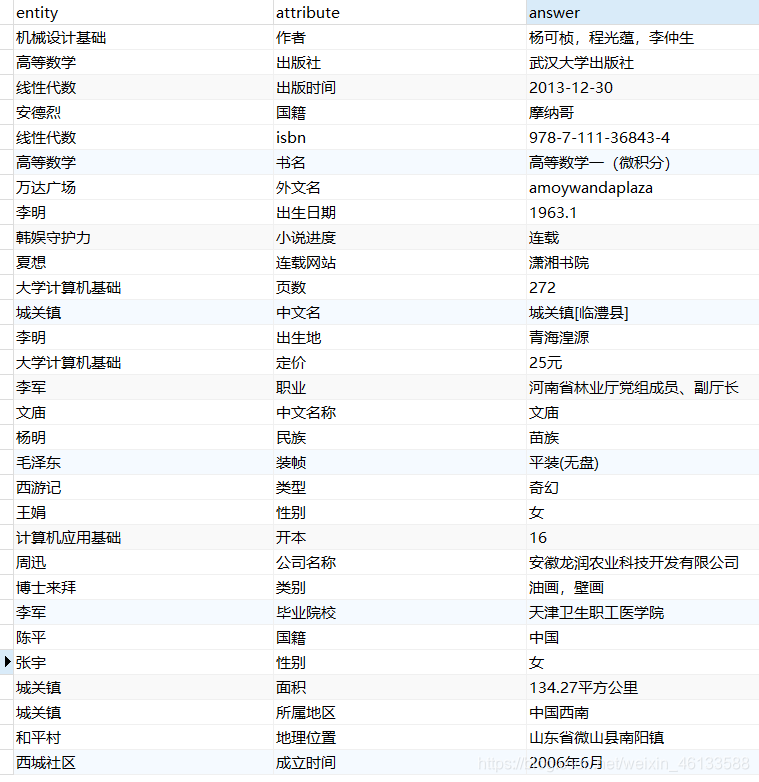
构造数据库的数据:实体+属性+答案
entity,attribute,answer
机械设计基础,作者,杨可桢,程光蕴,李仲生
高等数学,出版社,武汉大学出版社
线性代数,出版时间,2013-12-30
安德烈,国籍,摩纳哥
线性代数,isbn,978-7-111-36843-4
高等数学,书名,高等数学一(微积分)
万达广场,外文名,amoywandaplaza
李明,出生日期,1963.1
韩娱守护力,小说进度,连载
夏想,连载网站,潇湘书院
大学计算机基础,页数,272
城关镇,中文名,城关镇[临澧县]
李明,出生地,青海湟源
大学计算机基础,定价,25元
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中遇到的问题:
未完全匹配的实体样例:部分是识别错误,部分是同义词,部分是噪音
【识别错误】动物地鸠属是属于什么目呀? 地鸠属 动物地鸠
【同义词】《鲁迅全集》这本书是什么时候出版的呀? 《鲁迅全集》 鲁迅全集
【同义词】我想知道永安镇机场叫什么名字? 永安镇 永安镇机场
【同义词】海尔kfrd-35gw/03me-s4空调是什么类型的? 海尔kfrd-35gw/03me-s4 海尔kfrd-35gw/03me-s4空调
【问题噪音】你知道辛夷花粥管治疗什么吗? 辛夷花粥 辛夷花粥管
- 1
- 2
- 3
- 4
- 5
那么这少部分数据过滤掉。
最后生成插入到数据库中的数据:
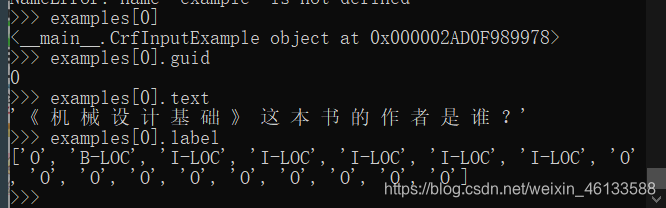
然后通过数据的相关处理,输入到模型中的数据如下:
2.3-定义主模型
class BertCrf(nn.Module): def __init__(self,config_name:str,model_name:str = None,num_tags: int = 2, batch_first:bool = True) -> None: self.batch_first = batch_first if not os.path.exists(config_name): raise ValueError( "未找到模型配置文件 '{}'".format(config_name) ) else: self.config_name = config_name if model_name is not None: if not os.path.exists(model_name): raise ValueError( "未找到模型预训练参数文件 '{}'".format(model_name) ) else: self.model_name = model_name else: self.model_name = None super().__init__() self.bert_config = BertConfig.from_pretrained(self.config_name) self.bert_config.num_labels = num_tags self.model_kwargs = {'config': self.bert_config} # 如果模型不存在 if self.model_name is not None: self.bertModel = BertForTokenClassification.from_pretrained(self.model_name, **self.model_kwargs) else: self.bertModel = BertForTokenClassification(self.bert_config) # 调用这里 self.crf_model = CRF(num_tags=num_tags,batch_first=batch_first) def forward(self,input_ids:torch.Tensor, tags:torch.Tensor = None, attention_mask:Optional[torch.ByteTensor] = None, token_type_ids=torch.Tensor, decode:bool = True, # 是否预测编码 reduction: str = "mean") -> List: emissions = self.bertModel(input_ids = input_ids,attention_mask = attention_mask,token_type_ids=token_type_ids)[0] new_emissions = emissions[:,1:-1] # [seq,batchs,3] seq = 64-2 =62 [32,62,3] new_mask = attention_mask[:,2:] # [32,62] if tags is None: loss = None pass else: new_tags = tags[:, 1:-1] # shape= [32.62] loss = self.crf_model(emissions=new_emissions, tags=new_tags, mask=new_mask, reduction=reduction) # [1] if decode: tag_list = self.crf_model.decode(emissions = new_emissions,mask = new_mask) return [loss, tag_list] return [loss]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
定义优化器和训练策略
no_decay = ['bias', 'LayerNorm.weight','transitions']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters,lr=args.learning_rate,eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3-BERT-BILSTM-CRF原理及使用
3.1-BERT原理介绍
参考论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
很多博客都有详细的介绍,这里就不多描述。
3.2-BERT+CRF模型
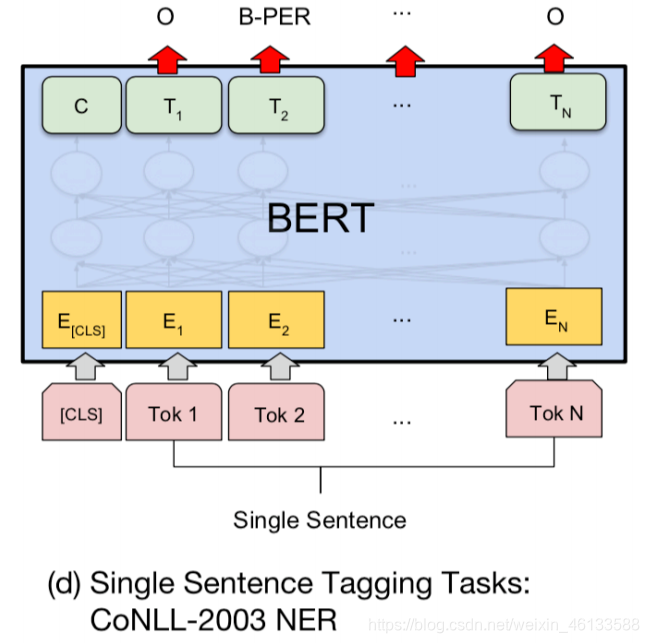
但是本项⽬的输⼊和输出有点不同,输⼊为分类符[CLS]+句⼦Token+结尾符[SEP],输出也是[CLS]+句
⼦Token+[SEP]对应的最后⼀层的向量,维度为[batch_sizes,seq_len,hidden_sizes]。
我参考的博客:
pytorch BiLSTM+CRF代码详解
pytorch中bilstm-crf部分code解析
最通俗易懂的BiLSTM-CRF模型中的CRF层介绍
Bidirectional LSTM-CRF Models for Sequence Tagging(论文翻译)
pytorch lstm crf 代码理解
我的代码:BERT_CRF.py / CRF_Model.py
- 模型的输入:
global_step = 0 tr_loss, logging_loss = 0.0, 0.0 model.zero_grad() train_iterator = trange(int(args.num_train_epochs), desc="Epoch") set_seed(args) best_f1 = 0. for _ in train_iterator: epoch_iterator = tqdm(train_dataloader, desc="Iteration") for step,batch in enumerate(epoch_iterator): batch = tuple(t.to(args.device) for t in batch) inputs = {'input_ids':batch[0], 'attention_mask':batch[1], 'token_type_ids':batch[2], 'tags':batch[3], 'decode':True }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 经过BERT
得到单词的发射概率。
# 发射概率,每个单词wi->tagj的概率
# emissions.shape [bs,sl,num_labels]
emissions = self.bertModel(input_ids = input_ids,attention_mask = attention_mask,token_type_ids=token_type_ids)[0]
- 1
- 2
- 3
- 经过CRF层
上节的发射矩阵输出作为CRF层的输⼊,可以得到总损失loss和状态转移矩阵trans[num_labels,num_labels]。
loss可以⽤来训练,状态转移矩阵trans可以⽤来预测。
class CRF(nn.Module): def __init__(self,num_tags : int = 2, batch_first:bool = True) -> None: super().__init__() self.num_tags = num_tags # 3 self.batch_first = batch_first self.start_transitions = nn.Parameter(torch.empty(num_tags)) self.end_transitions = nn.Parameter(torch.empty(num_tags)) self.transitions = nn.Parameter(torch.empty(num_tags,num_tags)) self.reset_parameters() def reset_parameters(self): init_range = 0.1 nn.init.uniform_(self.start_transitions,-init_range,init_range) nn.init.uniform_(self.end_transitions,-init_range,init_range) nn.init.uniform_(self.transitions, -init_range, init_range) def forward(self, emissions:torch.Tensor, tags:torch.Tensor = None, mask:Optional[torch.ByteTensor] = None, reduction: str = "mean") -> torch.Tensor: mask=torch.tensor(mask,dtype=torch.uint8) self._validate(emissions, tags = tags ,mask = mask) reduction = reduction.lower() # if reduction not in ('none','sum','mean','token_mean'): # raise ValueError(f'invalid reduction {reduction}') if mask is None: mask = torch.ones_like(tags,dtype = torch.uint8) if self.batch_first: # emissions.shape (seq_len,batch_size,tag_num) emissions = emissions.transpose(0,1) tags = tags.transpose(0,1) mask = mask.transpose(0,1) # numerator shape: (batch_size,) [32] numerator = self._computer_score(emissions=emissions,tags=tags,mask=mask) # 计算s(X,y) # shape: (batch_size,) [32] denominator = self._compute_normalizer(emissions=emissions,mask=mask) # 计算 log(Σe^(x,y')) # log(Σe^(S(X,y))) - S(X,y) llh = denominator - numerator # [batch_size] 32 if reduction == 'none': return llh elif reduction == 'sum': return llh.sum() elif reduction == 'mean': return llh.mean() assert reduction == 'token_mean' return llh.sum() / mask.float().sum() def decode(self,emissions:torch.Tensor, mask : Optional[torch.ByteTensor] = None) ->List[List[int]]: self._validate(emissions=emissions,mask=mask) if mask is None: mask = emissions.new_ones(emissions.shape[:2],dtype=torch.uint8) if self.batch_first: emissions = emissions.transpose(0,1) # [62,32,3] mask = mask.transpose(0,1) # [62,32] return self._viterbi_decode(emissions,mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
-
模型分析
总的来说,⽤单独的CRF和单独的BiLSTM都可以做命名实体识别,以下是两个模型的⼀些区别。
LSTM:像 RNN、 LSTM、BILSTM 这些模型,它们在序列建模上很强⼤,它们能够捕捉⻓远的上下⽂信息,此外还具备神经⽹络拟合⾮线性的能⼒,这些都是 CRF ⽆法超越的地⽅,对于t时刻来说,输出层y_t受到隐层h_t(包含上下⽂信息)和输⼊层x_t (当前的输⼊)的影响,但是y_t和其他时刻的y_t是相互独⽴的,感觉像是⼀种point wise,对当前t时刻来说,我们希望找到⼀个概率最⼤的y_t,但其他时刻的y_t对当前y_t没有影响,如果y_t之间存在较强的依赖关系的话(例如,形容词后⾯⼀般接名词,存在⼀定的约束),LSTM⽆法对这些约束进⾏建模,LSTM模型的性能将受到限制。CRF:它不像LSTM等模型,能够考虑⻓远的上下⽂信息,它更多考虑的是整个句⼦的局部特征的线性加权组合(通过特征模版去扫描整个句⼦)。关键的⼀点是,CRF的模型为p(y|x,w) ,注意这⾥y和x都是序列,它有点像list wise,优化的是⼀个序列y=(y1,y2,…,yn),⽽不是某个时刻的y_t,即找到⼀个概率最⾼的序列y=(y1,y2,…,yn)使得p(y1,y2,…,yn|x,w)最⾼,它计算的是⼀种联合概率,优化的是整个序列(最终⽬标),⽽不是将每个时刻的最优拼接起来,在这⼀点上CRF要优于LSTM。
HMM:CRF不管是在实践还是理论上都要优于HMM,HMM模型的参数主要是“初始的状态分布”,“状态之间的概率转移阵”,“状态到观测的概率转移矩阵”,这些信息在CRF中都可以有,例如:在特征模版中考虑h(y1) , f(yi-1,yi),g(yi,xi) 等特征。
CRF与LSTM:从数据规模来说,在数据规模较⼩时,CRF的试验效果要略优于BILSTM,当数据规模较⼤时,BILSTM的效果应该会超过CRF。从场景来说,如果需要识别的任务不需要太依赖⻓久的信息,此时RNN等模型只会增加额外的复杂度,此时可以考虑类似科⼤讯⻜FSMN(⼀种基于窗⼝考虑上下⽂信息的“前馈”⽹络)。
CNN+BILSTM+CRF:这是⽬前学术界⽐较流⾏的做法,BILSTM+CRF是为了结合以上两个模型的优点,CNN主要是处理英⽂的情况,英⽂单词是由更细粒度的字⺟组成,这些字⺟潜藏着⼀些特征(例如:前缀后缀特征),通过CNN的卷积操作提取这些特征,在中⽂中可能并不适⽤(中⽂单字⽆法分解,除⾮是基于分词后),这⾥简单举⼀个例⼦,例如词性标注场景,单词football与basketball被标为名词的概率较⾼, 这⾥后缀ball就是类似这种特征。
BERT+CRF:其实在整个项目中变动的是,emissions的不同,每个单词到不同tag的发射概率。BERT在特征抽取和上下文语义的理解上来说,是由于BILSTM的。但时间上是没有它快的。
3.3-训练结果
- NER训练集:
训练集数量:13637
总的epoch:15
batch_sizes:16
累计更新梯度step:4 (相当于64的batch_size)
总的step:6392
运⾏环境:GPU
训练过程如下,最后loss的范围在14左右,可以看到,在3000个step左右,loss降的差不多了。

- NER测试集:
训练集数量:9016
batch_sizes:8
运⾏环境:GPU
评估指标:这⾥的测试集的评估指标评估的是真实标签值id和预测标签id的差别。
# 计算真实句子的长度,返回真实句子长度的list # batch[3]真实的命名实体识别,batch[1]mask def statistical_real_sentences(input_ids:torch.Tensor,mask:torch.Tensor,predict:list)-> list: # shape (batch_size,max_len) assert input_ids.shape == mask.shape # batch_size assert input_ids.shape[0] == len(predict) # 第0位是[CLS] 最后一位是<pad> 或者 [SEP] new_ids = input_ids[:,1:-1] # [batch_size, seq_len-2] new_mask = mask[:,2:] real_ids = [] for i in range(new_ids.shape[0]): seq_len = new_mask[i].sum() # 计算每句话有多少个字 assert seq_len == len(predict[i]) real_ids.append(new_ids[i][:seq_len].tolist()) return real_ids
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
precision recall f1-score support
0 0.989159 0.983189 0.986165 47053
1 0.977180 0.975417 0.976298 4434
2 0.965636 0.977964 0.971761 22872
accuracy 0.981119 74359
macro avg 0.977325 0.978857 0.978075 74359
weighted avg 0.981210 0.981119 0.981146 74359
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
准确率很高,98.11%
3.4-离线预测
运行脚本python test_pro.py
运行中间变量展示:
question entity answer predict
你知道计算机应⽤基础这本书的作者是谁吗? 计算机应⽤基础 作者 秦婉,王蓉 计算机应⽤基础
计算机应⽤基础这本书的出版社是那个? 计算机应⽤基础 出版社 机械⼯业出版社 计算机应⽤基础
告诉我⾼等数学的出版时间是什么时候? ⾼等数学 出版时间 2004年 ⾼等数学
我想知道戴维斯是什么国家的⼈? 戴维斯 国籍 美国 戴维斯
你知道⾼等数学的isbn吗? ⾼等数学 isbn 9.7873E+12 ⾼等数学
你知道mc的外⽂名是什么吗? mc 外⽂名 emcee mc
王平的出⽣⽇期是哪⼀年呀? 王平 出⽣⽇期 1954年 王平
彼岸之界⼩说进度到哪⾥了? 彼岸之界 ⼩说进度 情节展开 彼岸之界
告诉我剑魔传的连载⽹站是哪个? 剑魔传 连载⽹站 天涯读书 剑魔传
.............
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
最终结果如下:基本都预测正确。
input the test sentence: 中华⼈⺠共和国成⽴于什么时候? # 输⼊的句⼦ [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']]# 预测的实体结果 识别的实体有:中华⼈⺠共和国 time used: 1 sec input the test sentence: 统计学习⽅法的作者是谁? [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O']] 识别的实体有:统计学习⽅法 time used: 0 sec input the test sentence: 机器学习这本书是哪个出版社出版的? [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']] 识别的实体有:机器学习 time used: 0 sec input the test sentence: 统计学习⽅法和机器学习哪本书⽐较好? # 这⾥的两个实体之间的 “和” 字没有预测到 [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'ILOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O']] 识别的实体有:统计学习⽅法和机器学习 time used: 0 sec input the test sentence: ⽯头记和红楼梦是同⼀本书嘛? [['B-LOC', 'I-LOC', 'I-LOC', 'O', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O']] 识别的实体有:⽯头记 红楼梦 time used: 0 sec input the test sentence: .............
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4-属性映射模型原理和训练代码
4.1-数据集处理
输入模型的数据格式处理代码:
def sim_convert_examples_to_features(examples,tokenizer, max_length=512, label_list=None, pad_token=0, pad_token_segment_id = 0, mask_padding_with_zero = True): label_map = {label: i for i, label in enumerate(label_list)} features = [] for (ex_index, example) in enumerate(examples): # inputs.keys = ['special_tokens_mask':, 'input_ids', 'token_type_ids'] # special_tokens_mask : 1 00000 1 00 1 1表示CLS或者SEP,前面的零表示问题,后面的零表示正文 # input_ids : 101 问题的idx 102 属性 102 # token_type_ids : 0000 111 其中111表示答案所在的位置 inputs = tokenizer.encode_plus( text = example.question, # 问题 text_pair= example.attribute, # 属性 add_special_tokens=True, max_length=max_length, truncation_strategy='longest_first', # We're truncating the first sequence in priority if True ) input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"] attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids) padding_length = max_length - len(input_ids) input_ids = input_ids + ([pad_token] * padding_length) attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length) token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length) assert len(input_ids) == max_length, "Error with input length {} vs {}".format(len(input_ids), max_length) assert len(attention_mask) == max_length, "Error with input length {} vs {}".format(len(attention_mask),max_length) assert len(token_type_ids) == max_length, "Error with input length {} vs {}".format(len(token_type_ids),max_length) # label = label_map[example.label] label = example.label if ex_index < 5: logger.info("*** Example ***") logger.info("guid: %s" % (example.guid)) logger.info("input_ids: %s" % " ".join([str(x) for x in input_ids])) logger.info("attention_mask: %s" % " ".join([str(x) for x in attention_mask])) logger.info("token_type_ids: %s" % " ".join([str(x) for x in token_type_ids])) logger.info("label: %s " % str(label)) features.append( SimInputFeatures(input_ids,attention_mask,token_type_ids,label) ) return features
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
训练代码就是:BERT分类fine-tine时取出的是BERT模型最后⼀层的CLS隐藏层向量model.get_pooled_output()。然后
在经过⼀层全连接层,就可以输出最终的类别输出概率了。
这部分内容的意思是:我给出一个问题,然后BERT+CRF识别,提取出我的问题中的实体,然后在数据库中找到这个实体,当然这个实体有可能有很多的
属性和答案。那么我们用bert来计算我的问题和哪些属性最相关,然后返回最相关的属性回来。并与正确答案属性ID进行匹配。统计正确率。
- 1
- 2
model = BertForSequenceClassification.from_pretrained(args.pre_train_model, **model_kwargs)
- 1
4.2-BERT分类模型训练
模型迭代的过程如下图所示:以下是3个epoch,总共7000个step的loss图,可以看到BERT⽐较粗暴,不到⼀个epoch,基本上已经
收敛了。

- 相似度匹配训练集、测试集和验证集结果:
test
loss 0.0680166557431221
question_acc 0.8998987078666687
label_acc 0.9826409816741943
dev
loss 0.026128364726901054
question_acc 0.9572441577911377
label_acc 0.9926713705062866
train
loss 0.01614166982471943
question_acc 0.9722089171409607
label_acc 0.9953110814094543
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5-知识库导入数据库,并抽取三元组
5.1-知识库导入数据库
这个章节我们主要解决项⽬介绍结束⽅案流程的第三步:在知识库中检索实体,得到和实体相关的前n个三元组。完成实体识别模型和属性抽取模型后还需进⾏知识库检索。知识库进⾏检索⽅式不可能⽤普通的for循环进⾏检索,所以这⾥直接把2个多G的⽂件nlpcc-iccpol-2016-total.kbqa.kb,导⼊mysql数据库中,有4千多万⾏,本地导⼊⼤概7个多⼩时,建议使⽤GPU服务器,我这边使⽤的本地数据库。导⼊数据库前需要下载安装mysql,具体安装⽅式根据⾃⼰的操作系统下载安装。安装完后,运⾏如下命令进⼊mysql数据库中。
mysql -u root -p
- 1
- 创建database
create database KB_QA character set utf8mb4 collate utf8mb4_unicode_ci;
use KB_QA;
- 1
- 2
- 安装mysql

新建MYSQL的链接。
填入对应的密码和信息。双击链接。 - 运行
python test_pro.py
5.2-返回分数最高的三元组
抽取三元组有两种⽅式。
- 非语义匹配
如果前n个三元组有某个三元组的属性是输⼊问题字符串的⼦集(相当于字符串匹配),将这个三元组的答
案作为正确答案返回,这个检索速度超级快。 - 语义匹配
⾮语义匹配失败后,可以再调⽤训练好的Bert属性映射模型,对前n个三元组的属性进⾏打分,排序,
输出topK个答案,选择分数最⾼的作为正确答案返回。
5.3-预测
# 测试第⼀个句⼦ ------------------------------ input the test sentence: 统计学习⽅法的作者是谁? your input is:['统', '计', '学', '习', '⽅', '法', '的', '作', '者', '是', '谁', '?'] [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O']] LOC: 统计学习⽅法 模型识别的实体有:统计学习⽅法 ------------------------------ 返回结果如下: # ⾮语义匹配,速度很快 提出的问题: 统计学习⽅法的作者是谁? 模型识别的实体+属性:统计学习⽅法+作者 知识库中得到的答案: 李航 Time used: 1 sec # 测试第⼆个句⼦ ------------------------------ input the test sentence: 中华⼈⺠共和国成⽴时间? your input is:['中', '华', '⼈', '⺠', '共', '和', '国', '成', '⽴', '时', '间', '?'] [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O']] LOC: 中华⼈⺠共和国 模型识别的实体有:中华⼈⺠共和国 ------------------------------------ # 可以看到中华⼈⺠共和国在知识库中的属性有下⾯这么多 # 属性没有输⼊问题的“成⽴时间”,⾮语义匹配不成功,转到BERT语义匹配 建国时间 0.9826155 国庆⽇ 0.91526103 国庆节 0.067031346 政体 0.013450251 国⼟⾯积 0.007624702 国旗 0.006048701 国⻦ 0.0048175533 国歌 0.003324484 国花 0.002280873 时区 0.0021266777 .................. 最⾼⽴法机构 8.25461e-05 主要节⽇ 8.20243e-05 英⽂名 8.030466e-05 主要宗教 7.857168e-05 官⽅语⾔ 7.641088e-05 货币 7.606106e-05 主要戏曲 7.542803e-05 著名⾼校 7.509416e-05 基尼系数 7.4889205e-05 ⾼等学府 7.221342e-05 国家代码 7.152084e-05 返回结果如下: 提出的问题: 中华⼈⺠共和国成⽴时间? 模型识别的实体+属性:中华⼈⺠共和国+建国时间 知识库中得到的答案: 1949年10⽉1⽇ Time used: 13 sec # 在本地运⾏,有点慢,建议到GPU运⾏,会快很多。 # 第三个句⼦ ------------------------------ 平安大厦的地址在哪? your input is:['平', '安', '大', '厦', '的', '地', '址', '在', '哪', '?'] [['B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O']] LOC: 平安大厦 模型识别的实体有:平安大厦 # 知识库中没有平安大厦这个实体 ------------------------------ 返回结果如下: 知识库中没有此实体 input the test sentence:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
6-总结
其实用question和attribute进行一个相似度计算做排序是有缺陷的,毕竟question的句子明显更长,语义明显比attribute更丰富,单拿attribute进行匹配有种断章取义的感觉,所以不提倡,但是也适用。
本项⽬的检索⽅式为完全匹配,⽐如《中国的⾸都在哪?》,假如我们的数据库中没有《中国》这个实体,但是有《中华⼈⺠共和国 ||| ⾸都 ||| 北京》这个三元组,我们可以想办法让数据库检索《中国》时,能同时检索到《中华⼈⺠共和国》作为候选三元组返回。⼀个好的想法是检索包含《中国》的所有实体,但是这样检索数据库时会需要遍历数据库,⾮常耗时间。
- TO DO
知识库问答⾮常适合前后端部署,效果看起来会很不错。
https://github.com/hquzhuguofeng/KBQA-BERT-CRF/tree/master/KBQA-BERT-CRF-master
7-参考:
https://zhuanlan.zhihu.com/p/62946533
https://github.com/WenRichard/KBQA-BERT?tdsourcetag=s_pctim_aiomsg
https://www.zhihu.com/question/46688107?sort=created
https://www.jiqizhixin.com/articles/2019-01-09-17
https://blog.csdn.net/Jason__Liang/article/details/81772632
https://zhuanlan.zhihu.com/p/59845590
https://github.com/jkszw2014/bert-kbqa-NLPCC2017
https://github.com/WenRichard/KBQA-BERT?tdsourcetag=s_pctim_aiomsg
https://github.com/zhangyunxing37/knowledge_grapy-kbqa_demo?tdsourcetag=s_pctim_aiomsg
https://github.com/huangxiangzhou/NLPCC2016KBQA
https://zhuanlan.zhihu.com/p/44042528
https://blog.csdn.net/Elvira521yan/article/details/88415512
https://blog.csdn.net/appleml/article/details/78579675

