
- 1YOLO 3/4/5/6/7/x、Efficient、MaskRcnn、FasterRcnn、FCOS、SSD、M2Det、Retina、CenterNet、PicoDet等系列数据模型汇总持续更新中_fasterrcnn cascadercnn yolov3 picodet
- 2Vue3+element-plus+vite 组件的二次封装-- 新建npm打包项目,生成二次封装npm组件库,本地测试_vue3 vite 二次封装element plus成一个npm包
- 3Java 异常Exception e中e的getMessage()和toString()方法的区别_exception.getmessage
- 4文心一言4.0相当于GPT几?揭秘AI巨头的实力对比
- 5【 数据可视化——词云图绘制 】四步搞定从图片提取颜色的词云图绘制 基于Python_词云图图形
- 6推荐系统[四]:精排-详解排序算法LTR (Learning to Rank): poitwise, pairwise, listwise相关评价指标,超详细知识指南。_ltr listwise
- 7QT 界面设计篇(水波纹进度条QProgressBarWater)_qt qprogressbar美化,水波纹进度条
- 8ubuntu22.04配置静态ip问题_permissions for /etc/netplan/01-network-manager-al
- 9Bert论文翻译
- 10Python淘宝书籍图书销售数据爬虫可视化分析大屏全屏系统
大力出奇迹的CLIP模型 | 一文了解CLIP模型!_clip模型图像头用的是啥
赞
踩
论文地址:Learning Transferable Visual Models From Natural Language Supervision
CLIP(Contrastive Language-Image Pre-Training)是由OpenAI团队于2021年推出的一种深度学习模型,它是一种可以同时处理文本和图像的预训练模型。
与以往的图像分类模型不同,CLIP并没有使用大规模的标注图像数据集来进行训练,而是通过自监督对比学习的方式从未标注的图像和文本数据中进行预训练,使得模型能够理解图像和文本之间的语义联系。CLIP模型具有超强的泛化能力,下图是有监督训练的ResNet101与Zero-Shot CLIP在ImageNet数据集上与其他数据集上的性能对比:

1 模型
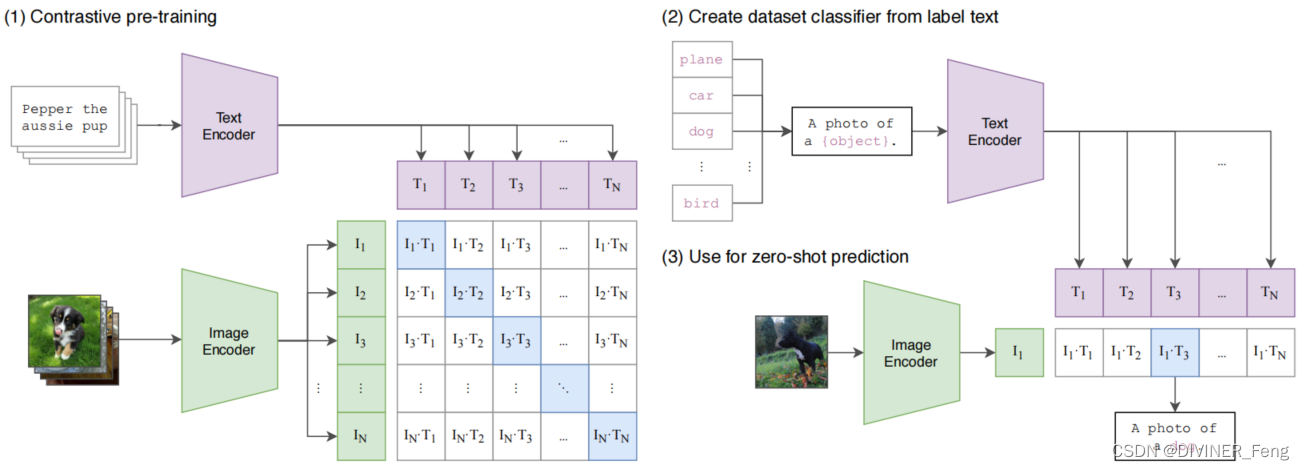
标准的图像模型联合训练图像特征提取器和线性分类器来预测某些标签,而CLIP联合训练图像编码器和文本编码器来预测一批图像与文本的正确配对。
2 训练方法
数据集:由于现有的数据集相对较小,不足以使得模型达到一鸣惊人的效果。因此,OpenAI团队自己生成了一个包含4亿样本的数据集(WIT数据集),在训练CLIP的同时孕育了OpenAI旗下的图像生成工具DALL·E。
利用自然语言的监督信号来训练一个比较好的视觉模型。这样训练有以下优势:
(1)不需要提前标注好数据;
(2)由于在训练时将文字与图片绑定在一起,因此学习到的特征不仅仅是一个视觉特征,而是一个多模态特征。
3 推理
CLIP模型如何做zero-shot推理?
CLIP模型经过与训练后只能得到视觉上与文本上的特征,并没有在任何分类的任务上继续做训练或微调。因此,它没有这种分类头。该模型通过prompt template的方式将物体的类别标签转化为一个句子,这样就可以不受Categorical Table的限制。
推理过程:
(1)给Image Encoder任意一张图像,得到图片特征;
(2)将感兴趣的标签(例如:"plane","car","dog", ....)通过prompt engineering对应变成句子(例如:“A photo of a plane.”),将每个句子经过Text Encoder得到对应的文本特征;
(3)将取得的多个文本特征与一个图像的特征分别计算Cosine Similarity;
(4)将得到的相似度通过一层Softmax得到一个概率分布。
建议将上面的推理过程配合下图更容易理解。

4 局限性
虽然CLIP模型在一些任务上展现了一鸣惊人的效果,但仍存在以下局限性:
(1)CLIP模型在一些数据集上仍不是state-of-the-art,但如果再扩大数据集与模型的规模,CLIP的性能还能有所提高。若想在各个数据集上均达到SOTA,则还要在目前训练CLIP计算量的基础上乘以1000,即使对于OpenAI现有的硬件条件也无法训练;
(2)CLIP在一些数据集上zero-shot的结果并不理想。比如在一些细分类的数据集上CLIP模型的效果低于有监督训练resNet-50的基线网络,且CLIP无法处理特别抽象的概念或更难的任务,例如统计图片中物体的数量或区分监控视频当前帧是异常或非异常;
(3)CLIP模型泛化性好,对于自然图像的分布偏移模型相对稳健,但如果推理时的数据与训练数据差距很大(out-of-distribution),则CLIP的泛化性也会较差。例如:在MNIST数据集上CLIP模型的准确率只有88%,作者查看4亿数据集中的图片,发现数据集中并没有有MNIST数据集中类似的图像;
(4)虽然CLIP模型可以做zero-shot的分类任务,但它还是从已给定的类别中去做选择。同时,作者提出了一种更灵活的方式,即做成一个生成式模型,直接生成图像的标题。但由于计算资源受限,难以训练出图像标题生成的基线网络;
(5)CLIP模型对数据的利用并不是很高效,与其他深度学习网络一样需要大量的数据去投喂。在CLIP的训练过程中用了32个Epoch,每个Epoch有4亿张图片;
(6)在研发CLIP的过程中,为了能与其他模型做公平的比较,会在相应数据集的整个测试集上不停地做测试。例如:CLIP在ImageNet数据集上分数比较高,但他不是第一次训练出来分数就是如此,而是在这个过程中测试了很多变体,做了很多超参调整才得到如此效果。在这个过程中,每次都用ImageNet测试集做指导,因此在无形中就已经带入了偏见,并不是真正的zero-shot;
(7)数据集中的数据均是从网上爬取的,并没有经过清洗。因此最终得到的CLIP模型可能带有社会上的偏见;
(8)通常情况下,如果在做下游任务时能提供一些训练样本是非常有帮助的。但CLIP模型的提出并是不为了few-shot的情况。因此导致为CLIP模型提供一些样本(one-shot, two-shot, ....)时的效果并不如直接用zero-shot;
5 总结
CLIP真正的把视觉语义与文字语义联系到了一起。因此,该模型学习到的特征语义性非常强,迁移的效果也非常好。CLIP模型最大的贡献是打破了之前固定种类标签的范式,无论是在收集数据集时或训练模型时,都无需像ImageNet那样分1000类,设置1000个类别标签,可以直接搜集图片-文本的配对,然后用无监督的方式去预测其相似性。

