
- 1leetcode 每日一题复盘(线性dp)
- 2RabbitMQ入门(一)——RabbitMQ的安装以及使用(Windows环境下)_mq的搭建以及使用
- 3Unity UGUI的Text(文本)组件的介绍及使用_unity3d uitext显示
- 4微信小程序 布局对齐属性_微信小程序图片靠右对齐
- 5【NLP】关键词提取:TFIDF、TextRank_tfidf textrank
- 6jenkins+ant+svn持续集成环境搭建_ant jekins svn
- 7MySQL的图形用户界面(GUI)工具及其编程实现_mysql自带的gui
- 8uniapp创建vue3项目_uniapp vue3
- 9Excel学习记录之分类汇总与合并计算_分类汇总和合并计算
- 10【Arduino+ESP32专题】PlatformIO IDE使用第三方库_platformio第三方库添加依赖
【AI实战】超赞的几个OCR开源项目_开源ocr
赞
踩
超赞的几个OCR开源项目
OCR
OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程。
点击查看百科:OCR文字识别 介绍
历史背景
光学文字识别的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。
1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
早期的OCR软件结构
1、图像输入、预处理
2、二值化
3、噪声去除
4、倾斜较正
5、版面分析
6、字符切割
7、字符识别
8、版面恢复
9、后处理、校对
超赞的几个OCR开源项目介绍
-
第一名:PaddleOCR
-
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
-
特性
支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程。
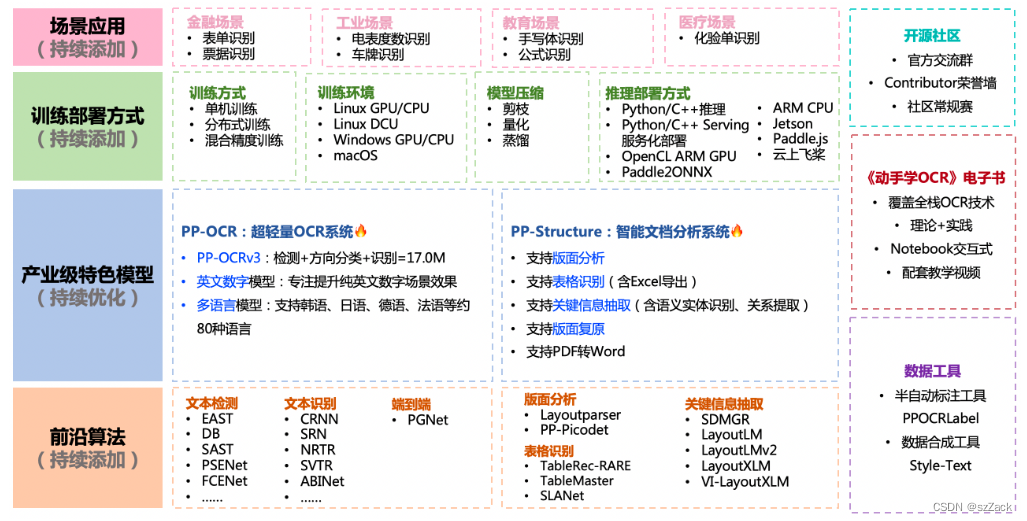
-
在线网站体验:
超轻量PP-OCR mobile模型体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr -
移动端demo体验:
安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)https://ai.baidu.com/easyedge/app/openSource?from=paddlelite -
文本检测算法效果
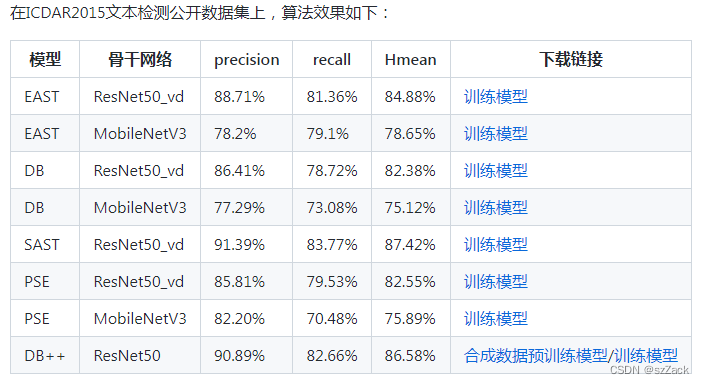
-
文本识别算法效果
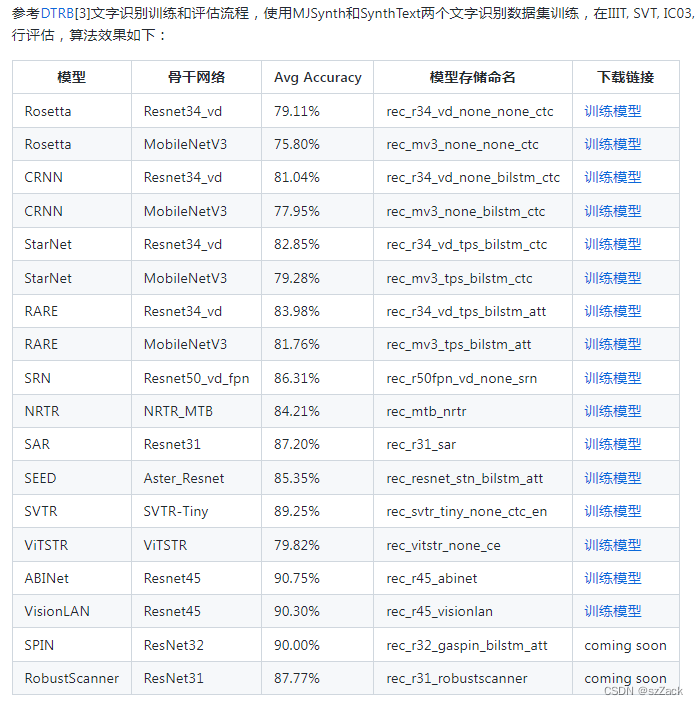
-
-
第二名:EasyOCR
-
Ready-to-use OCR with 80+ supported languages and all popular writing scripts including: Latin, Chinese, Arabic, Devanagari, Cyrillic, etc.
-
算法效果
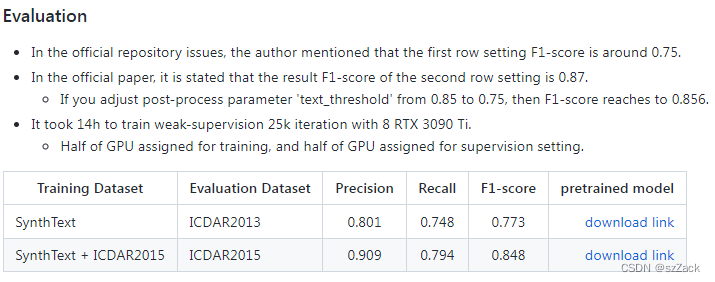
-
-
第三名:chineseocr
-
本项目基于yolo3 与crnn 实现中文自然场景文字检测及识别
-
该项目提供了数据集
ocr ctc训练数据集(压缩包解码:chineseocr)
百度网盘地址:链接: https://pan.baidu.com/s/1UcUKUUELLwdM29zfbztzdw 提取码: atwn -
实现功能
文字方向检测 0、90、180、270度检测(支持dnn/tensorflow)
支持(darknet/opencv dnn /keras)文字检测,支持darknet/keras训练
不定长OCR训练(英文、中英文) crnn\dense ocr 识别及训练 ,新增pytorch转keras模型代码(tools/pytorch_to_keras.py)
-
-
第四名:YCG09/chinese_ocr
-
基于Tensorflow和Keras实现端到端的不定长中文字符检测和识别
文本检测:CTPN
文本识别:DenseNet + CTC -
该项目提供了数据集:
https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)共约364万张图片,按照99:1划分成训练集和验证集
数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成
包含汉字、英文字母、数字和标点共5990个字符
每个样本固定10个字符,字符随机截取自语料库中的句子
图片分辨率统一为280x32
-
其他开源项目
https://github.com/eragonruan/text-detection-ctpn
https://github.com/senlinuc/caffe_ocr
https://github.com/chineseocr/chinese-ocr
https://github.com/xiaomaxiao/keras_ocr
https://github.com/alisen39/TrWebOCR
https://github.com/da03/Attention-OCR
https://github.com/JinpengLI/deep_ocr

