
- 1深度学习--反向传播_深度学习 反向传播
- 2Hadoop大数据简介_doug cutting和mike cafarella
- 3刷题DAY57 | LeetCode 647-回文子串 516-最长回文子序列
- 4ARM架构和X86架构区别
- 5Kafka 架构深入探索
- 6修复vscode运行vue不能显示network的地址_vdcode network地址
- 7大规模向量检索库Faiss学习总结记录_faiss数据库教程
- 8m基于matlab的光通信误码率仿真,分别对比了OFDM+BPSK和OFDM+4QAM的误码率和星座图_仿真qam或ofdm调制解调实现及误码率分析
- 9神经网络实用工具(整活)系列---使用OpenAI的翻译模型whisper实现语音(中、日、英等等)转中字,从此生肉变熟肉---提高篇(附带打包好的程序)_whisper 幻听
- 10【离线语音专题④】安信可VC离线语音开发板二次开发语音控制LED灯_vc-02 ai-thinker
Java 面试八股文 —— SSM 框架常见面试题_ssm八股文面试题
赞
踩
前言:
本文章主要用于记录博主准备面试的题目记录,有哪个题目有问题或者解释不清的,还请及时下方留言,感谢支持!!!
目录:
- 1、常见的 ORM 框架有哪些
- 2、Bean 容器 / Ioc 容器的理解
- 3、Ioc / DI 的理解
- 4、Spring 中单例 bean 的线程安全问题
- 5、Spring 中 bean 的作用域
- 6、FactoryBean和BeanFactory
- 7、Bean 的生命周期
- 8、Spring 三级缓存的理解【Spring 中如何解决循环依赖】
- 9、Spring AOP 的理解
- 10、Spring 事务的隔离级别
- 11、Spring 事务中有哪几种事务传播行为
- 12、Spring MVC 流程
- 13、MyBatis 中 # 和 $ 的区别
- 14、MyBatis 如何一对一、一对多关联
- 15、SpringBoot 自动配置原理
1、常见的 ORM 框架有哪些
①、首先 ORM 为:
- 对象关系映射模式,为了解决面向对象和关系数据库存在互不匹配的现象的技术,它是通过使用描述对象和数据库之间的关系的元数据,将程序中的对象自动持久化存储到数据库中。至于如何实现持久化,一种简单的方式就是通过硬编码的方式,为每一种数据库访问操作提供单独的方法
此种方法有以下不足:
Ⅰ、持久层缺乏弹性,不能响应需求的变化,修改变化随之就需要修改持久层的接口
Ⅱ、持久层同时和域模型与关系数据库模型绑定,一旦域模型或者是关系数据库模型改变,毒药修改持久层的代码,增加软件的维护成本
- ORM 提供了另外一种实现持久化的模式,它采用映射元数据的方式来描述对象关系的映射。使得任意 ORM 中间件能在任何一个业务逻辑层和数据持久层起到桥梁的作用
- ORM 基于三个核心原则:简单、传达性、精确性,其优点是:提高开发效率,由于 ORM 可以自动对对象和数据库中的 table 表中的字段进行映射,所以不需要一个庞大的数据访问层,同时可以像操作对象一样从数据库中获取数据。同时其也存在缺点,ORM 会牺牲程序效率和固有思维模式,采用 ORM 的系统一般都是多层系统,系统的层数多了,效率就会降低。ORM 是一种完全面向对象的做法,而面向对象也会对性能产生一定的影响
②、Java 中常见的 ORM 框架:
Ⅰ、MyBatis 半自动的 ORM 框架,需要手动去实现 sql,再由框架根据 sql 及 sql 传入的数据来组装为要执行的 sql。其优点为:
- ①、程序员手动写 sql 学习成本低
- ②、更方便做 sql 性能的优化和维护
- ③、对关系型数据库模型要求不高,这样在做数据库调整时,影响不会太大,适合比较频繁变动需求的系统,因此国内大部分系统都是使用的半自动的 ORM 框架
- Mybatis 的缺点:不能跨数据库,因为写的 sql 存在某种数据库的特有的语法或关键词
Ⅱ、Hibernate 全自动的 ORM 框架,不需要手动实现 sql ,调用框架提供的 API,可以自动将对象组装为要执行的 sql,其优点为:
- ①、可以跨数据库
- ②、全自动 ORM 框架,自动组装为 sql 语句
- 其缺点为:学习门槛高,要学习框架 API 与 sql 的转换关系
- 对数据库的模型依赖非常大,在软件需求的频发变更中,会导致维护的难度高,很难定位问题,也很难进行性能优化,需要精通框架,对数据库的框架需要十分熟悉
2、Bean 容器 / Ioc 容器的理解
Spring 容器是对 Ioc 设计模式的实现,使用统一的容器去存储 Bean 对象,及管理对象的依赖关系,创建容器的 API 主要是 BeanFactory 和 ApplicationContext 两种:
- 1、BeanFactory 是最底层的容器接口,只有最基础的容器功能,Bean 对象实例化和依赖注入,并且使用懒加载的方式,这意味着 bean 对象只有在通过 getBean 方法直接调用的时候他们才进行实例化
- 2、ApplicationContext (上下文),是 BeanFactory 的子接口,为预加载,每一个 bean 对象都在 ApplicationContext 启动时,进行实例化,除了基础功能还具备以下功能:
①、整合了 bean 的生命周期管理
②、国际化功能
③、载入多个上下文关系(存在继承关系),使得上下文都专注于一个特定的层次,比如应用的 web 层
④、事件发布响应机制
⑤、AOP
两种 API 创建容器的方式:
- 1、方法一:ApplicationContext 扫描的路径是 spring 配置文件的路径,再通过 context 去获取 bean 对象即可
ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml");
- 1
- 2、方法二、 BeanFactory,同样的扫描路径以及通过 factory 的 getBean 方法获取到 bean 对象
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("spring-config.xml"));
- 1
3、Ioc / DI 的理解
- Ioc 中文含义为 “控制反转”,我们在面向对象设计的软件系统中,其底层是由多个对象构成的,各个对象通过相互合作,完成最终的业务逻辑
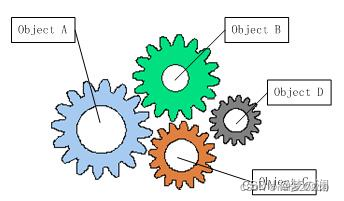
- 看上图的齿轮图,四个齿轮分别代表四个对象,这四个齿轮相互咬在一起转动,任何一个齿轮发生故障都有可能导致整个系统的崩溃,齿轮之间的咬合关系就是程序中的对象的耦合关系十分相似,对象的耦合是必然存在无法避免的,这是协同工作的基础,随着软件的规模的增大,对象间的依赖关系越来越复杂,对于对象耦合度过高的系统,就会容易出现牵一发而动全身的情形
- Ioc 提出的理论大体就是这样的:借助第三方实现依赖关系的对象的解耦,再看下一张的齿轮图:
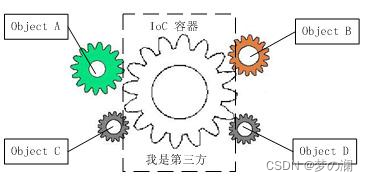
- 四个有颜色的齿轮代表四个对象,中间的大齿轮就是 Ioc 容器,此容器就使得 A B C D 四个对象没有了依赖,所有的齿轮的转动都是依靠着 Ioc 容器的转动(第三方),所有齿轮的控制权都上交给了第三方(Ioc 容器),所以 Ioc 就称为整个系统的关键核心,他起到了一种类似粘合剂的作用,把所有的对象粘合在一起发挥作用,如果没有整个粘合剂,对象和对象之间就会失去联系(这就是控制反转)
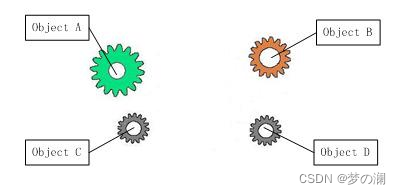
- 反过来再看这个齿轮系统,去掉 Ioc 容器,此时的四个对象的耦合度已经降到了最低,当实现 A 时无需求去关心 B C D 的实现,对象之间的依赖程度已经降到了最低,对开发系统是一件非常好的事情
- 既然 Ioc 是控制反转,那么到底是在哪些方面的控制被反转了?
即是在依赖对象的时候被反转了,控制反转之后,获取依赖对象的过程由自身管理转换为由 Ioc 容器主动注入,所以在 Ioc 容器在运行时,动态的将依赖关系,注入到对象之中被称为:“依赖注入”(DI)
- 依赖注入(DI),控制反转(Ioc)是从不同角度去描述同一件事情,通过引入 Ioc 容器和依赖注入,实现对象间的解耦合,DI 是 Ioc 思想的一种实现,具体实现方式:属性注入、setter注入、构造方法注入,实现原理:反射及ASM字节码框架实现。具体依赖注入的代码:
1、属性注入:(此示例是在 userController 类中注入一个 userService 类)
@Autowired
private UserService userService;
- 1
- 2
2、setter 注入:
@Autowired // 必须要添加
public void setUserService(UserService userService) {
this.userService = userService;
}
- 1
- 2
- 3
- 4
3、构造方法注入:
@Autowired
public UserController2(UserService userService) {
this.userService = userService;
}
- 1
- 2
- 3
- 4
4、三种注入方式的优缺点:
- ①、属性注入:简洁方便使用,只能用于 Ioc 容器,并且在使用时才会报出空指针异常
- ②、构造方法注入:spring 官方的推荐注入方式,在使用时一定保证注入的类不能为空,多个注入会显得程序比较臃肿
- ③、setter 注入通用性不如构造方法注入
5、两种注入方式: @Resource / @Autowired 二者区别:
- Autowired 来自 spring、Resource 来自 JDK
- 作用范围不同:Resource 不能进行构造方法注入,Autowired 三种注入方法都可以
- Resource 支持更多参数的设置
4、Spring 中单例 bean 的线程安全问题
单例 bean 存在线程安全问题,当多线程同时操作一个同一对象时,对这个对象的非静态成员变量的写操作会存在线程安全问题。常见的有两种解决方法:
- 在对象中尽可能定义不可变的成员变量(不现实)
- 在类中定义一个 ThreadLocal 类将需要的可变成员变量保存到 ThreadLocal 中(推荐)
关于 ThreadLocal:
①、ThreadLocal 是什么
ThreadLocal 为本地线程变量,其中填充的是当前线程的变量,该变量对于其他线程来说是封闭且隔离的。ThreadLocal 为变量在每个线程中创建了一个副本,这样每个线程都可以访问到自己的副本变量
1、在进行对象跨层传递时,使用 ThreadLocal 可以避免多次传递,打破层次间的约束
2、线程间数据隔离
3、进行事物操作,用于存储线程事物信息
4、数据库连接,session 会话管理
②、ThreadLocal怎么用
public static void main(String[] args) {
ThreadLocal<String> local = new ThreadLocal<>();
for (int i = 0; i < 10; i++) {
int finalI = i;
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
local.set(Thread.currentThread().getName() + ":" + finalI);
System.out.println(Thread.currentThread().getName() + ":" + finalI);
}
});
thread.start();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 运行结果:可以看到每一个线程都有自己的 local 值
线程:Thread-0,local:Thread-0:0
线程:Thread-1,local:Thread-1:1
线程:Thread-2,local:Thread-2:2
线程:Thread-3,local:Thread-3:3
线程:Thread-4,local:Thread-4:4
线程:Thread-5,local:Thread-5:5
线程:Thread-6,local:Thread-6:6
线程:Thread-7,local:Thread-7:7
线程:Thread-8,local:Thread-8:8
线程:Thread-9,local:Thread-9:9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
③、ThreadLocal源码分析
- set 原码:ThreadLocalMap 为 ThreadLocal 的静态内部类 定义 Entry 来保存数据,继承是弱引用,在 Entry 中使用 ThreadLocal 作为 key ,使用我们自己设置的 value 作为 value ,对于每个线程内部有个ThreadLocal.ThreadLocalMap 变量,存取值的时候,也是从这个容器中来获取
/** * Sets the current thread's copy of this thread-local variable * to the specified value. Most subclasses will have no need to * override this method, relying solely on the {@link #initialValue} * method to set the values of thread-locals. * * @param value the value to be stored in the current thread's copy of * this thread-local. */ public void set(T value) { //首先获取当前线程对象 Thread t = Thread.currentThread(); //获取线程中变量 ThreadLocal.ThreadLocalMap ThreadLocalMap map = getMap(t); //如果不为空, if (map != null) map.set(this, value); else //如果为空,初始化该线程对象的map变量,其中key 为当前的threadlocal 变量 createMap(t, value); } /** * Create the map associated with a ThreadLocal. Overridden in * InheritableThreadLocal. * * @param t the current thread * @param firstValue value for the initial entry of the map */ //初始化线程内部变量 threadLocals ,key 为当前 threadlocal void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue); } /** * Construct a new map initially containing (firstKey, firstValue). * ThreadLocalMaps are constructed lazily, so we only create * one when we have at least one entry to put in it. */ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
2、get 方法:同过 ThreadLocal (当前的线程)作为 key 去查询 value 值
/** * Returns the value in the current thread's copy of this * thread-local variable. If the variable has no value for the * current thread, it is first initialized to the value returned * by an invocation of the {@link #initialValue} method. * * @return the current thread's value of this thread-local */ public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
④、ThreadLocal 内存泄漏问题:先看下面的类
/** * The entries in this hash map extend WeakReference, using * its main ref field as the key (which is always a * ThreadLocal object). Note that null keys (i.e. entry.get() * == null) mean that the key is no longer referenced, so the * entry can be expunged from table. Such entries are referred to * as "stale entries" in the code that follows. */ static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 注释中 Note that null keys (i.e. entry.get() * == null) 如果 key 值为空,这个 entry 就可以清除掉了,ThreadLocal是一个弱引用,当为null时,会被当成垃圾回收 。但是 ThreadLocalMap 为静态成员变量(和 Thread 的生命周期一样),他不会回收,那就是 ThreadLocalMap 的 key 值为 null 但是 value 值还是存在,这就造成了内存泄漏
- 解决办法:使用完 ThreadLocal 后,执行 remove 操作避免内存溢出情况,清除当前线程的数值
⑤、为什么 key 为弱引用
- 如果是强引用,当 ThreadLocal 的对象引用被回收后,ThreadLocalMap 还持有 ThreadLocal 的强引用,如果没有删除这个 key ,那么 ThreadLocal 就不会被回收,只要线程还存在 ThreadLocalMap 引用的那些对象就不会被回收,可以认为这导致 Entry 内存泄漏
附:强弱引用
- 强引用:普通的引用,强引用指向的对象不会被回收
- 软引用:仅有软引用指向的对象,只有发生 gc 且内存不足,才会被回收
- 弱引用,仅有弱引用指向的对象,只要发生 gc 就回收
5、Spring 中的 bean 对象的作用域
- ①、singleton:唯一的 bean 实例,spring 中的 bean 默认都是单例
- ②、prototype:每次请求都创建一个新的 bean 实例
- ③、request:每次一个 HTTP 请求都会产生一个新的 Bean 该 bean 仅在当前的 HTTP request 有效
- ④、session:每次一个 HTTP 请求都会产生一个新的 Bean 该bean 仅在当前的 HTTP session 有效
- ⑤、application:在一个引用 servlet 上下文生命周期中,产生一个新的 bean
- ⑥、websocket:在一个 websocket 生命周期中,产生一个新的 bean
6、FactoryBean和BeanFactory
- BeanFactory 是 spring 中的顶级接口,所有的 bean 对象都是通过 BeanFactory 进行管理的。
- FactoryBean 是实例化一个 bean 对象的工厂类实现了 FactoryBean 接⼝的 Bean 根据该 bean 的 id 从BeanFactory中获取的实际上是FactoryBean中 getObject() ⽅法返回的对象,⽽不是 FactoryBean本身,如果要获取FactoryBean对象,请在id前⾯加⼀个 & 符号来获取
7、Bean的⽣命周期
- ①、实例化 Bean (通过反射调用构造方法实现对象的实例化)
- ②、依赖注入(实现对象的属性)
- ③、Bean 的初始化
- Ⅰ、执行各种 Aware
- Ⅱ、执行 BeanPostProcessor 初始化前置方法
- Ⅲ、执行 @PostConstruct 方法,依赖注入后被执行
- Ⅳ、执行自己的 init_method 方法
- Ⅴ、执行 BeanPostProcessor 初始化后置方法
- ④、使用 Bean
- ⑤、销毁 Bean
- Ⅰ、执行销毁前方法 @PreDestory
- Ⅱ、如果有接口 DisposableBean 执行实现方法
- Ⅲ、执行销毁前的方法 destory-method
8、Spring 三级缓存的理解【Spring 中如何解决循环依赖】
- 至于什么是循环依赖:就是 A 对象依赖 B 对象,B 对象又依赖 A 对象,类似于下面的代码:
@Component
public class A{
@Autowired
private B b;
}
@Component
public class B{
@Autowired
private A a;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- A 在实例化后,发现需要依赖 B ,当前 spring 容器中没有 B 对象,就会先去实例化 B 对象,在实例化 B 对象时,发现需要依赖 A 对象,又会继续去实例化 A ,这样会一直反复,这就套娃了, 你猜是先 StackOverflow 还是 OutOfMemory ?Spring怕你不好猜,就先抛出了BeanCurrentlyInCreationException,这就是循环依赖问题,这里不叫死锁(叫法不一样),在 spring boot 3.0 之后就关闭了循环依赖的功能,所以这样的代码只有在 spring boot 3.0 之前写不会报错,至于官方是如何解决循环依赖问题的,这里就使用到了三级缓存
- 这里回顾一下,上面 bean 对象的生命周期:
- 实例化 Bean
- 依赖注入:装配 Bean 的属性
- 初始化:执行各种 aware 方法,执行初始化前置方法,执行初始化方法,执行初始化后置方法
- 使用 bean
- 销毁 bean
- spring 保存 bean 对象的方式采用的是缓存的方式,使用 Map<String, Object> 的结构,key 为 bean 的名字,Object 为 bean 对象
- 在 spring 容器中注册循环依赖的 bean 必须是单例模型,且依赖注入的方式为属性注入,原型模型或构造方法注入都是不行的
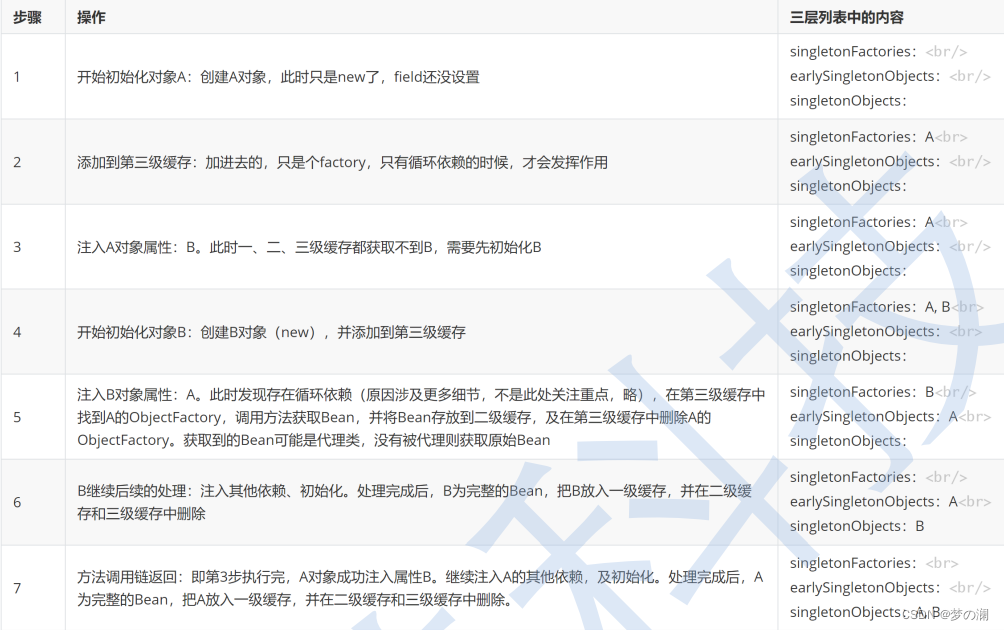
- spring 解决循环依赖,采用如下图的三级缓存(每一级缓存都是一张哈希表):
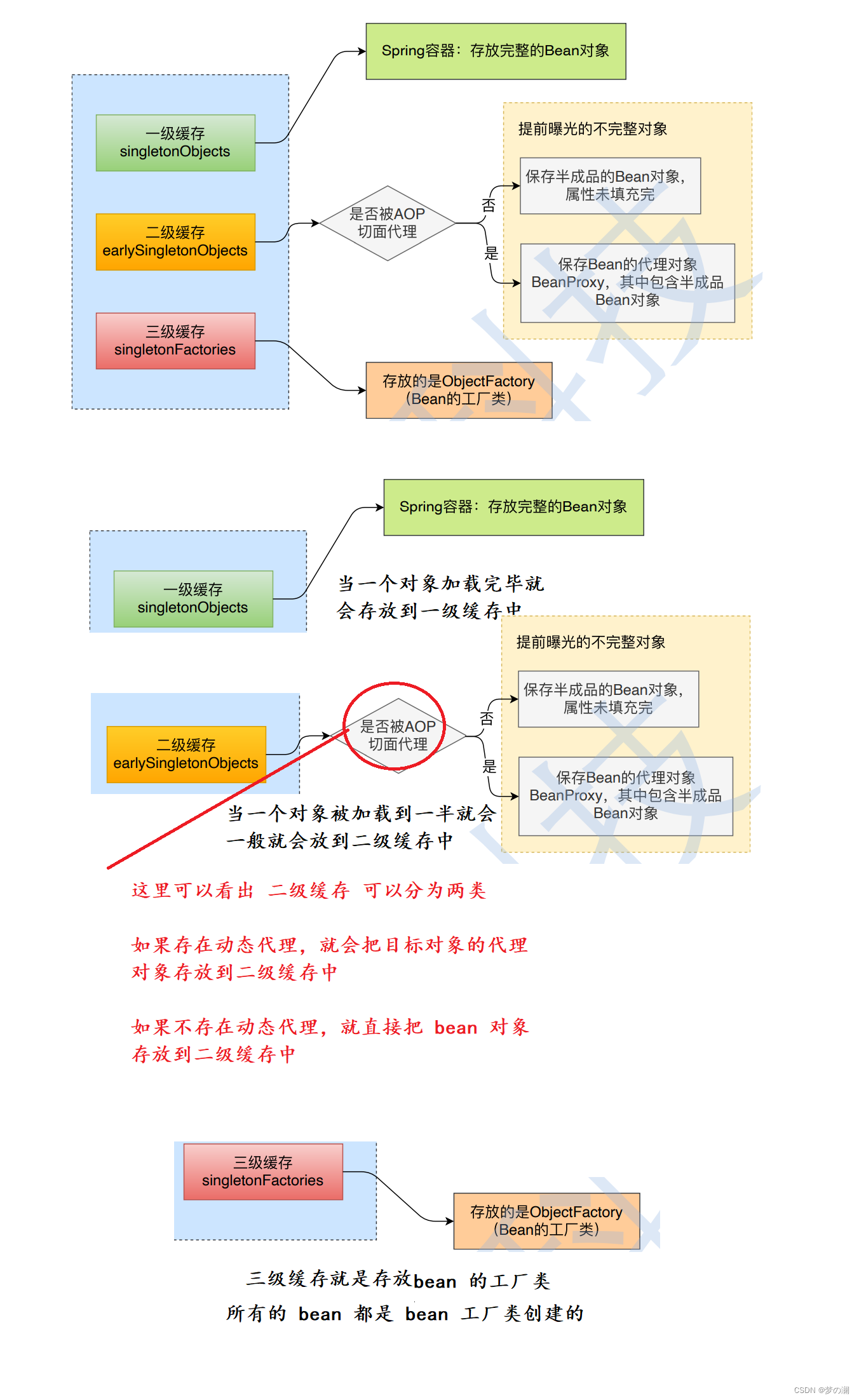
- 在这三级缓存中,每一个对象只能在存在于一个缓存中,其他缓存都会被删掉。查找缓存是从1☞3,存储对象是 3 ☞ 1
- 那么针对上面的循环依赖的问题,三级缓存又是怎样去解决的?
首先实例化 A 对象,将其放入到三级缓存中,依赖注入 B,在缓存中寻找 B 发现是找到不的,此时的 A 是一个半成品,将 A 放入到 二级缓存中,去实例化 B ,将 B 放入到三级缓存,后依赖注入 A 可以在二级缓存中找到 A,那么将此时的 A 对象指向二级缓存中的 A 的地址,虽然 A 是一个半成品,但是我们仅仅只是把引用指向了缓存中的 A ,后 B 再进行初始化,将 B 放入到一级缓存中,最后进行 A 对象可以继续向下执行,在一级缓存中找到了 B ,后再执行 A 的初始化方法,将 A 放入到一级缓存中,此时循环依赖的问题就被解决了
- 那么就抛出了一个问题,三级缓存可以解决循环依赖的问题,那么二级缓存能否可以解决?
答案是不行的,这三个缓存中存储的内容是不一样的,当一个 Bean 开始实例化时,是存放在三级缓存中的,当加载到一半时,就会放到二级缓存,将三级缓存的数据清除,而二级缓存又被分为两部分,二级缓存这里多了 AOP 的问题,导致二级缓存变复杂了,如果没有 AOP 这一环节,二三级是可以合并在一起的。最后一个完整的 bean 对象肯定是需要一个单独的缓存来进行存储,所以三级缓存是必要的,下面的是更细一点的循环依赖的解决:
9、Spring AOP 的理解
-
AOP :面向切面编程,对于多个业务逻辑横切来实现统一的代码管理,而不用切入代码本身,这样面向切面编程的思想就被称为 AOP(一种思想),AOP 是对某一类事件进行处理,让后面程序没有后顾之忧去写程序,比如博客查询,你就单纯去写查询博客的代码,不用考虑登录情况检查,直接 AOP 解决
-
Ⅰ、切面:定义 AOP 针对哪一个的功能的,这个功能就叫做一个切面,比如用户登录,方法日志统计,切面是由切点和通知组成
-
Ⅱ、连接点:可以触发 AOP 的点,就是连接点,需要被增强的某个 AOP 功能的所有方法
-
Ⅲ、切点:定义 AOP 拦截规则
-
Ⅳ、通知:规定 AOP 执行的时期和执行的方法
-
实现步骤:
-
Ⅰ、引入 Spring-AOP 依赖
-
Ⅱ、定义切面
-
使用场景:日志记录,异常控制,事务管理,安全控制,性能统计
-
优点:代码解耦合,统一功能业务对代码没有入侵,可扩展能力强,灵活性高
-
springAOP 是采取动态代理的方式具体是基于 jdk 和 CGLIB 两种:
- ①、jdk 动态代理:需要被代理类实现接口, InvocationHandler 和 Proxy 动态的⽣成代理类
- ②、CGLIB 动态代理:需要被被代理类可以被继承,不能被 final 修饰,使用 MethodInterceptor 来对方法拦截,CGLIB 底层是基于 ASM 框架的,在运行时动态生成代理类
-
SpringAOP 如何使用,@Aspect 定义切面,point 定义切点方法后,可以对目标方法进行拦截
- 前置通知:@Before 通知方法会在目标方法调用之前执行
- 后置通知:@After 通知方法会在目标方法返回或者抛出异常后调用
- 返回之后通知:使⽤@AfterReturning:通知⽅法会在⽬标⽅法返回后调⽤。
- 抛异常后通知:使⽤@AfterThrowing:通知⽅法会在⽬标⽅法抛出异常后调⽤。
- 环绕通知:使⽤@Around:通知包裹了被通知的⽅法,在被通知的⽅法通知之前和调⽤之后执⾏⾃定义的⾏为。
-
代码实例:定义切面、定义切点、定义通知
@Aspect @Component public class UserAspect { @Pointcut("execution(* com.example.demo.controller.UserController.*(..))") public void pointcut(){} @Before("pointcut()") public void doBefore(){ System.out.println("执行前置方法"); } @After("pointcut()") public void doAfter(){ System.out.println("执行后置方法"); } @AfterReturning("pointcut()") public void doAfterReturning(){ System.out.println("执行 AfterReturning"); } @AfterThrowing("pointcut()") public void doAfterThrowing(){ System.out.println("执行 AfterThrowing"); } @Around("pointcut()") public Object doAround(ProceedingJoinPoint joinPoint){ Object o = null; System.out.println("执行 Around"); StopWatch stopWatch = new StopWatch(); stopWatch.start(); try{ o = joinPoint.proceed(); }catch (Throwable throwable) { throwable.printStackTrace(); } stopWatch.stop(); System.out.println("Around 执行结束"); System.out.println("执行时间:" + ); return o; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 具体的被代理类:
@RestController
public class UserController {
@RequestMapping("/sayhi")
public String sayHi(){
System.out.println("你好世界");
return "你好世界";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10、Spring 事务的隔离级别
Spring 事物一共五种隔离级别:
- ①、ISOLATION_DEFAULT:使用后端数据库的默认隔离级别,mysql 默认采用 REPEATABLE_READ 隔离级别
- ②、ISOLATION_READ_UNCOMMITTED:读未提交,允许读取尚未提交的数据变更,可能会导致不可重复读,脏读,幻读的问题
- ③、ISOLATION_READ_COMMITTED:读已提交,允许读取并发事务已经提交的数据,可以阻止脏读问题,但是可能会有不可重复读,幻读的问题
- ④、ISOLATION_REPEATABLE_READ:重复读,同一字段多次读取到的结果都是一样的,避免了脏读,不可重复读,但是会有幻读的问题
- ⑤、ISOLATION_SERIALIZABLE:最高隔离级别,完全服从 ACID 隔离界别,所有事务逐个执行,这样事务之间就完全不可能产生干扰,该级别可以阻止幻读、可重复读、脏读问题,但是程序的性能也会大大降低,通常情况下不会使用该隔离级别
11、Spring 事务的传播机制
在 TransactionDefinition 中定义了七种表示事物传播行为的常量
-
支持当前事物的情况:
- ①、PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务,如果当前事务不存在,则创建一个新的事务
- ②、PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务,如果当前事务不存在,则以非事务的方式继续运行
- ③、PROPAGATION_MANDATORY:如果当前事务存在,则加入该事务,如果当前事务不存在,则抛出异常
-
不支持当前事务:
- ①、PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起
- ②、PROPAGATION_NOT_SUPPORTED:以非事务的方式运行,如果当前存在事务,就将当前事务挂起
- ③、PROPAGATION_NEVER:以非事务的方式运行,如果当前存在事务,就抛出异常
-
其他情况:
- ①、PROPAGATION_NESTED:如果存在事务,则创建一个事务作为当前事务的嵌套事务运行,如果当前没有事务,则该取值等价为 PROPAGATION_REQUIRED
12、Spring MVC 流程
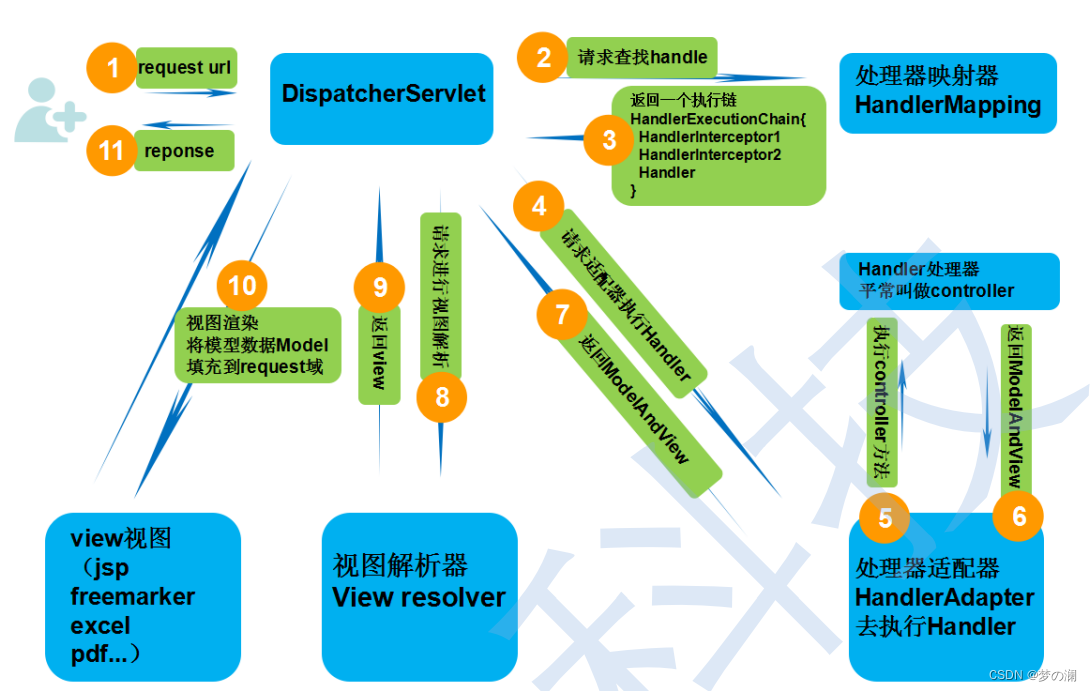
- 流程:
- ①、(发起)发起请求到前端控制器:DispatcherServlet
- ②、(查找)前端控制器请求 HandlerMappering 查找 Handler (可以根据 xml / 注解进行查找)
- ③、(返回)处理器映射器 HandlerMappering 向前端控制器返回 Handler ,HandlerMapping 会把请求映射为 HandlerExecutionChain 对象 (包含一个 Handler 处理器(页面控制器)对象,多个 HandlerInterceptor 拦截器对象),通过这种策略很容易添加新的映射策略
- ④、(调用)前端控制器去调用处理器适配器去执行 Handler
- ⑤、(执行)处理器适配器HandlerAdapter将会根据适配的结果去执⾏Handler
- ⑥、(返回)Handler 执行完给适配器返回 ModelAndView
- ⑦、(接收)处理器控制器向前端控制器返回 ModelAndView (SpringMVC 的底层对象,包括 model 和 view)
- ⑧、(解析)前端控制器请求视图解析器去进⾏视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
- ⑨、(返回)视图解析器向前端控制器返回 view
- ⑩、(渲染)前端控制器进⾏视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充
到request域) - ⑪、(响应)前端控制器向⽤户响应结果
- 上述流程返回的是一个静态页面,还有一种执行模式,缺少 8 ~ 10 的步骤,返回的就是一个 普通的数据。简单来说就是一个没有使用 @ResponseBody 或 @RestController 注解,项目默认返回的是一个静态页面,反之,使用了这两个注解之一,返回的就是一个普通的数据。
13、MyBatis 中 # 和 $ 的区别
- ①、#{变量名} 是预处理的方式,本质是 jdbc 占位符的替换,如果传入字符串,会替代为带有单引号的值,安全性更好
- ②、${变量名} 是字符串替换,只是对 sql 字符串进行拼接。如果传入字符串,会被替代成字符串的值,不会加单引号
- #的方式可以防止 sql 注入,相对来说更安全
14、MyBatis 如何一对一、一对多关联
①、一对一的情况:例如 CSDN 的博客一篇博客对应的就是一个作者,这就是一对一的情况
使用 association 标签,用户表和文章表分别在 xml 文件中映射自己的字段,对于此处 一对一的情况,是在文章实体类中存在 user 属性,对于 user 属性的映射采用 association 标签,其中有三个属性:property 指定文章实体类中的属性名、resultMap :指定关联的结果集,基于该结果集组织用户数据,columnPrefix 为了防止两张表同名字段的覆盖,绑定一对一对象
- 主要代码:
<resultMap id="BaseMap" type="com.example.demo.model.Ariticle"> <id column="id" property="id"></id> <result column="title" property="title"></result> <result column="content" property="content"></result> <result column="createtime" property="createtime"></result> <result column="updatetime" property="updatetime"></result> <result column="uid" property="uid"></result> <result column="rcount" property="rcount"></result> <result column="state" property="state"></result> <association property="user" resultMap="com.example.demo.mapper.UserMapper.BaseMap" columnPrefix="u_"></association> </resultMap> <select id="getArticleById" resultMap="BaseMap"> select a.*,u.id u_id,u.username u_username,u.password u_password from articleinfo a left join userinfo u on a.uid=u.id where a.id=#{id} </select>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 测试结果:

②、一对多的情况:反过来看,当一篇文章对应一个作者,那么一个作者就可以对应多篇文章,这就是一对多的关系
对于 一对多 的情况使用的是 collection 标签,用户实体类的属性一一进行映射,ariticles 属性需要使用到 collection 对应的关联的结果集是:com.example.demo.mapper.AriticleMapper.BaseMap,使用方式大体和一对一的使用方式一致
- 主要代码:
<resultMap id="BaseMap" type="com.example.demo.model.User"> <!-- 主键映射 --> <id column="id" property="id"></id> <!-- 普通属性映射 --> <result column="username" property="username"></result> <result column="password" property="password"></result> <result column="createtime" property="createtime"></result> <result column="updatetime" property="updatetime"></result> <result column="state" property="state"></result> <collection property="ariticles" resultMap="com.example.demo.mapper.AriticleMapper.BaseMap" columnPrefix="a_"> </collection> </resultMap> <select id="getUserAndArticleByUid" resultMap="BaseMap"> select u.*,a.id a_id,a.title a_title,a.content a_content, a.createtime a_createtime, a.updatetime a_updatetime from userinfo u left join articleinfo a on u.id=a.uid where u.id=#{uid} </select>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 测试结果:

15、SpringBoot 自动配置原理
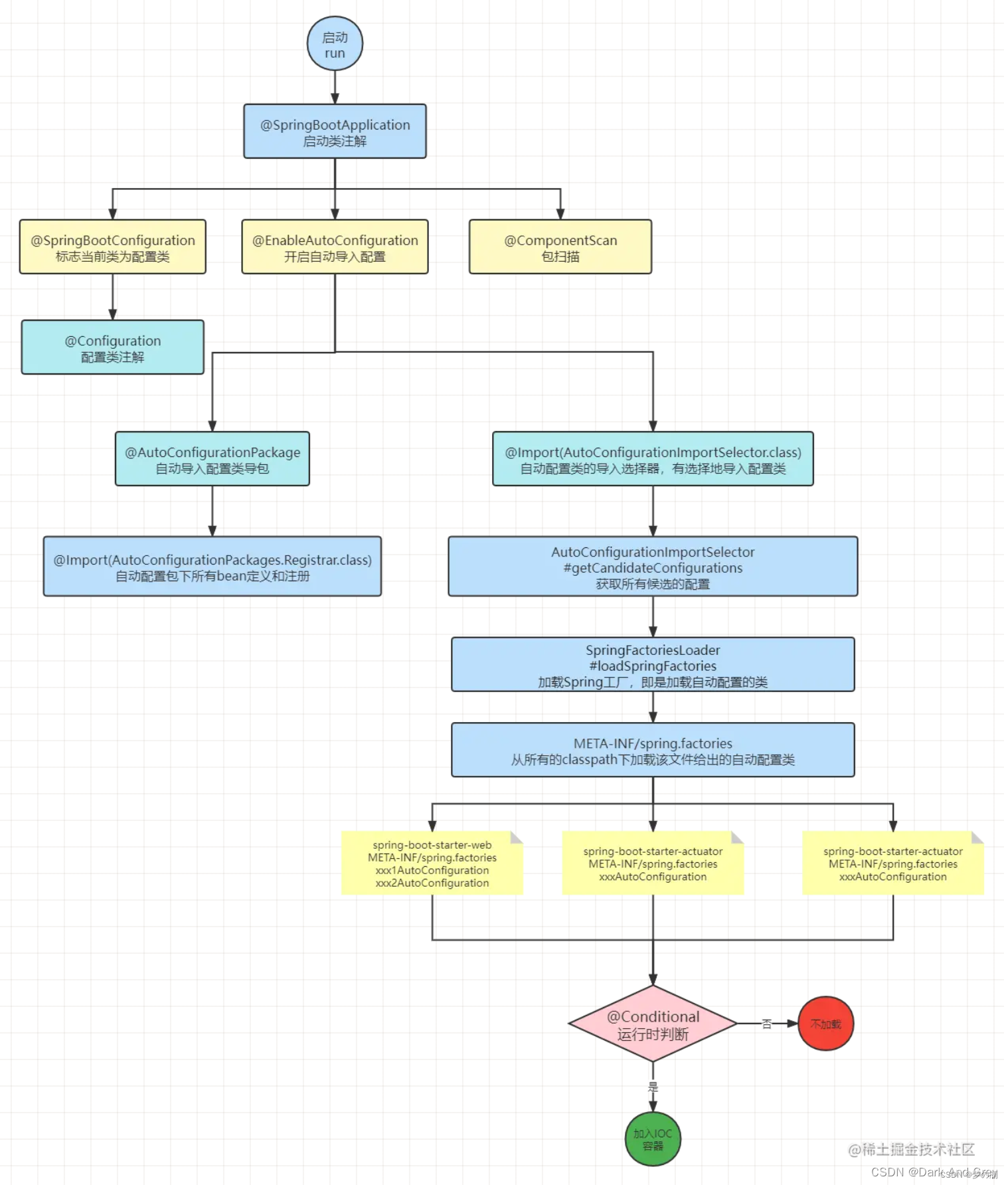
SpringBoot 能够自动配置,只需要了解下面几个点:
- SpringBoot 能够自动配置,主要是因为 @SpringBootApplication 这个注解
- @SpringBootApplication 的分支 @EnableAutoConfiguration(开启自动导入配置),其里面有一个 @Import(AutoConfigurationPackages.Registrar,class)【自动配置包下所有的Bean定义和注册】注解,它会将需要自动装配的所有的Bean全部装配起来。
问题来了:哪些类是需要自动装配呢?
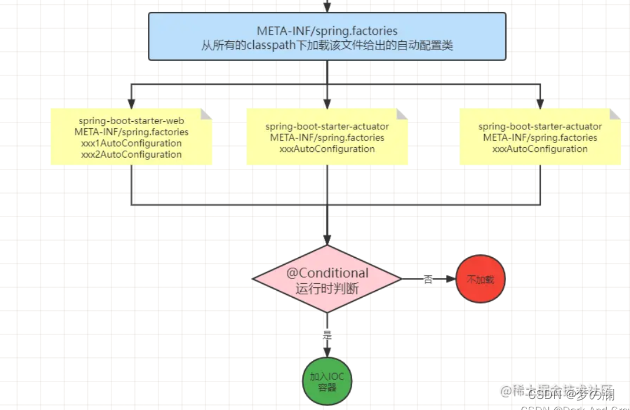
如上图,spring factories 里面就配置了(标识了)哪一些需要配置的类

