
- 1Git 解决 Permission denied, please try again 问题_git permission denied, please try again.
- 2前端开发者必备:Nginx入门实战宝典,从部署到优化一网打尽
- 3HTML+CSS+JavaScript实现的动态爱心,超简单直接用!_html代码草莓熊
- 4霍兰德职业兴趣测试全解析,助你找到理想工作!_职业性向测试
- 5详解数据中台的底层架构逻辑
- 6Let’s Move Sui , 一起来学习吧
- 7路由器就能赚钱? 揭秘京东云无线宝背后的黑科技
- 8YoloV8改进策略:RefConv打造轻量化YoloV8利器_yolov8引入refconv
- 9Redis分布式集群--Redis的优势_集群中的redis数据库的作用
- 10数据结构之排序_堆排序和顺序表
树模型系列之XGBoost算法_xgboost算法流程图
赞
踩
树模型系列之XGBoost算法
概要
主要是基于陈天奇论文和slide以及其他博客文章(见参考文献)的整理,完整的记录XGBoost的理论和关键问题讨论,以备温习和加深记忆。强烈建议看看前两个参考文献
主要从以下几个方面进行阐述
- XGBoost的理论推导
- XGBoost的几个关键核心问题
- XGBoost的优缺点
原理
推导XGBoost:
损失函数
任何机器学习的问题都可以从目标函数(objective function)出发,目标函数的主要由两部分组成 损失函数+正则项
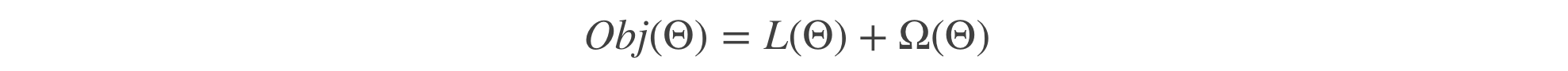
损失函数用于描述模型拟合数据的程度。
正则项用于控制模型的复杂度
对于正则项,我们常用的L2正则和L1正则:
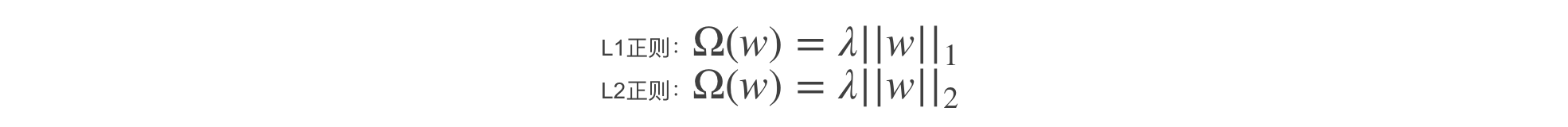
在这里,当选择树模型为基学习器时,我们需要正则的对象,或者说需要控制复杂度的对象就是这K颗树,通常树的参数有树的深度,叶子节点的个数,叶子节点值的取值(xgboost里称为权重weight)
所以,我们的目标函数形式如下:
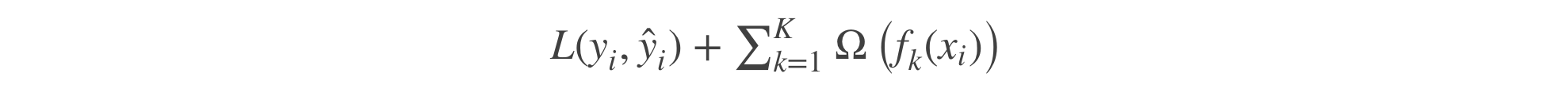
对一个目标函数,我们最理想的方法就选择一个优化方法算法去一步步的迭代的学习出参数。但是这里的参数是一颗颗的树,没有办法通过这种方式来学习。
既然如此,我们可以利用Boosting的思想来解决这个问题,我们把学习的过程分解成先学第一颗树,然后基于第一棵树学习第二颗树。也就是说:
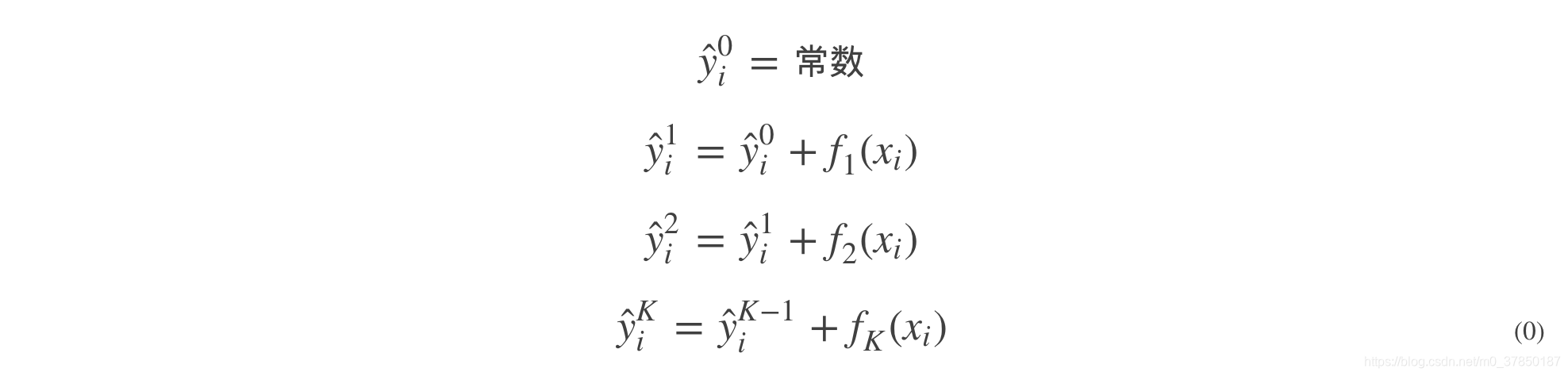
所以,对于第K次的目标函数为:
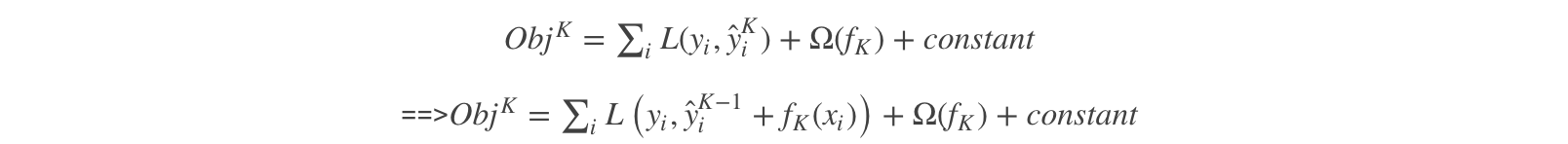
上面的式子意义很明显,只需要寻找一颗合适的树fk使得目标函数最小。然后不断的迭代K次就可以完成K个学习器的训练。
子树
如何寻找合适的子树fk
在GBDT里面(当然GBDT没有正则),我们的树是通过拟合上一颗树的负梯度值,建树的时候采用的启发式准则;
然而,在xgboost里面,它是通过对损失函数进行泰勒展开。(其思想主要来自于文章:Additive logistic regression a statistical view of boosting也是Friedman大牛的作品)
二阶泰勒展开:

对损失函数二阶泰勒展开:
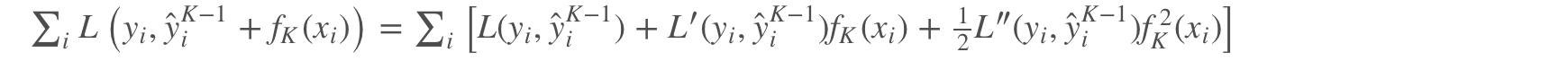

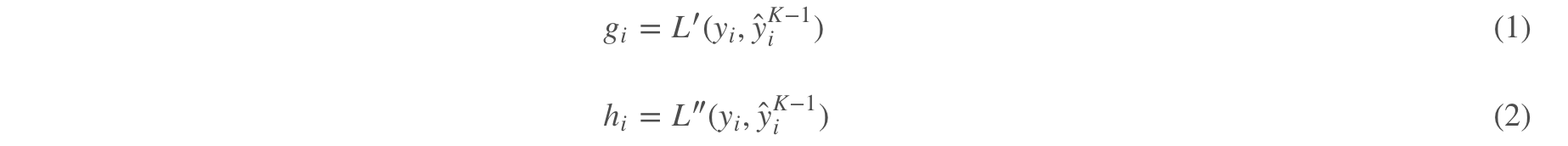
(1)式和(2)非常的重要,贯穿了整个树的构建(分裂,叶子节点值的计算)。以及(2)式是我们利用xgboost做特征选择时的其中一个评价指标。
所以我们可以得到我们进化后的目标函数:
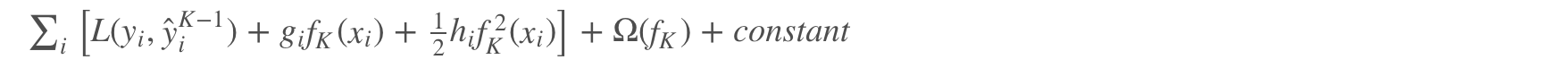
一颗树用数学模型来描述是什么样,很简单其实就是一个分段函数。比如有下面一颗树:
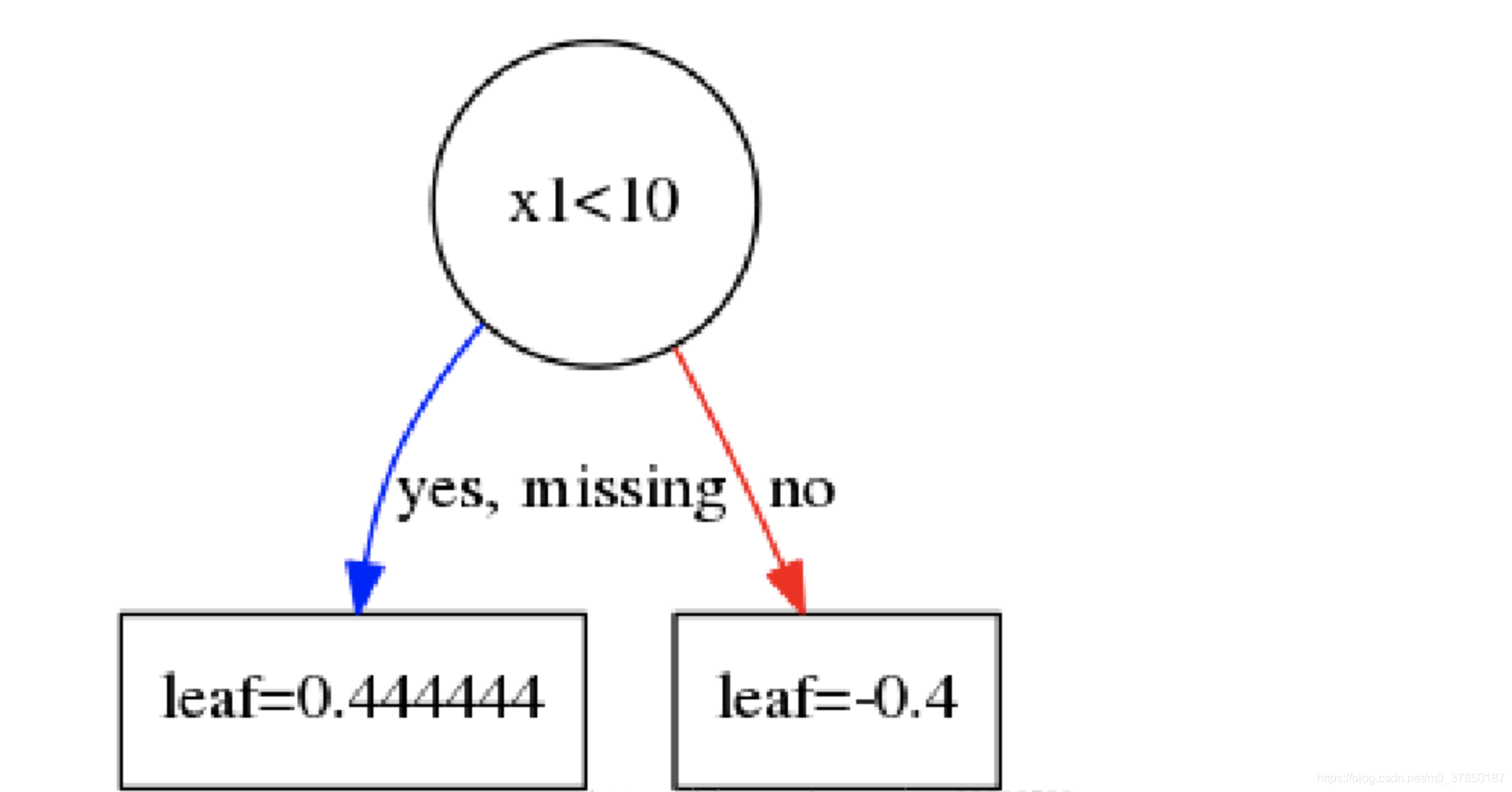

也就是说,一棵树其实可以由一片区域以及若干个叶子节点来表达。而同时,构建一颗树也是为了找到每个节点的区域以及叶子节点的值。
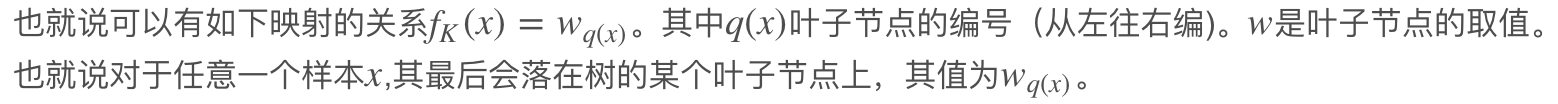
既然一棵树可以用叶子节点来表达,那么,我们上面的正则项就了其中一个思路。我们可以对叶子节点值进行惩罚(正则),比如取L2正则,以及我们控制一下叶子节点的个数T,那么正则项有:

其实正则为什么可以控制模型复杂度呢?有很多角度可以看这个问题,最直观就是,我们为了使得目标函数最小,自然正则项也要小,正则项要小,叶子节点个数T要小(叶子节点个数少,树就简单)。
而为什么要对叶子节点的值进行L2正则,这个可以参考一下LR里面进行正则的原因,简单的说就是LR没有加正则,整个w的参数空间是无限大的,只有加了正则之后,才会把w的解规范在一个范围内。(对此困惑的话可以跑一个不带正则的LR,每次出来的权重w都不一样,但是loss都是一样的,加了L2正则后,每次得到的w都是一样的)
这个时候,我们的目标函数(移除常数项后)就可以改写成这样(用叶子节点表达):
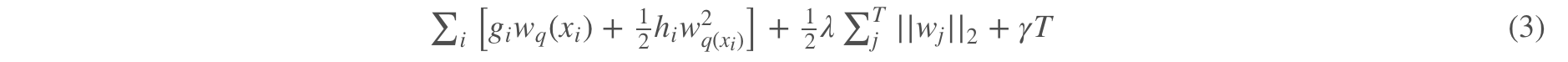
其实我们可以进一步化简,那么最后可以化简成:
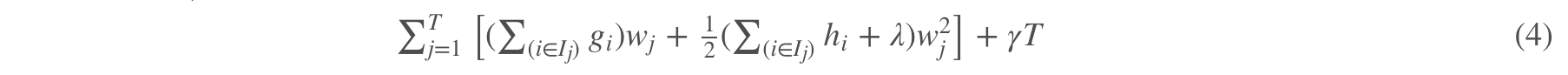
(3)式子展开之后按照叶子节点编号进行合并后可以得到(4)。可以自己举T=2的例子推导一下。j 表示叶子节点编号,同一个编号的叶子节点数据合并;i 表示第几次分裂

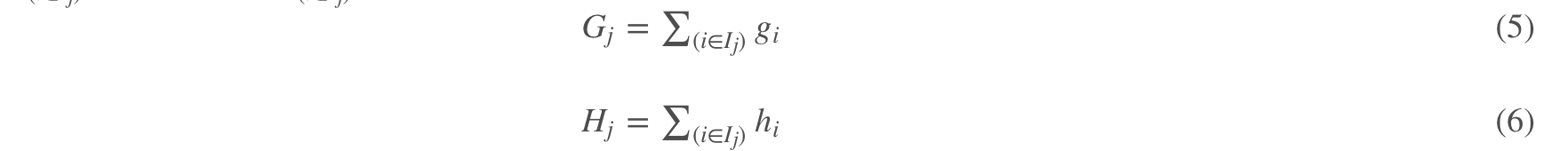
那么目标函数可以进一步简化为:
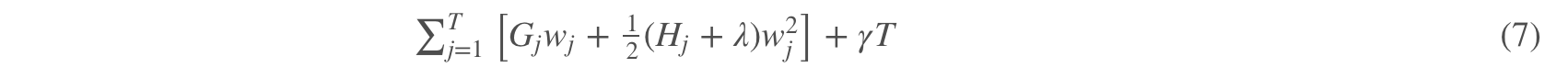
我们做了这么多,其实一直都是在对二阶泰勒展开后的式子化简,其实刚展开的时候就已经是一个二次函数了,只不过化简到这里能够把问题看的更加清楚。所以对于这个目标函数,我们对wj求导,然后带入极值点,可以得到一个极值(叶子节点取值):
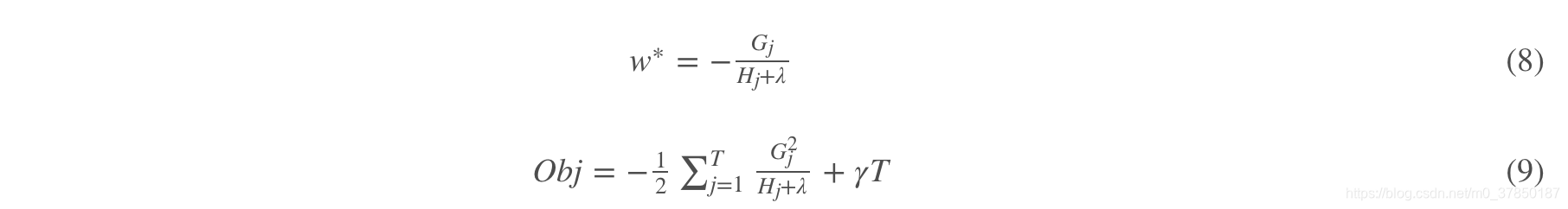
花了这么大的功夫,得到了叶子结点取值的表达式。
如果有看过我们前面GBDT文章的朋友应该没有忘记当时我们也给出了一系列的损失函数下的叶子节点的取值,在xgboost里,叶子节点取值的表达式很简洁,推导起来也比GBDT的要简便许多
到这里,我们一直都是在围绕目标函数进行分析,这个到底是为什么呢?这个主要是为了后面我们寻找fk(x),也就是建树的过程。 XGBoost 分裂规则直接与损失函数有关
具体来说,我们回忆一下建树的时候需要做什么,建树的时候最关键的一步就是选择一个分裂的准则,也就如何评价分裂的质量。比如在前面文章GBDT的介绍里,我们可以选择MSE,MAE来评价我们的分裂的质量,但是,我们所选择的分裂准则似乎不总是和我们的损失函数有关,因为这种选择是启发式的。
比如,在分类任务里面,损失函数可以选择logloss,分裂准确选择MSE,这样看来,似乎分裂的好坏和我们的损失并没有直接挂钩。
但是,在xgboost里面,我们的分裂准则是直接与损失函数挂钩的准则,这个也是xgboost和GBDT一个很不一样的地方
具体来说,xgboost选择这个准则,计算增益Gain
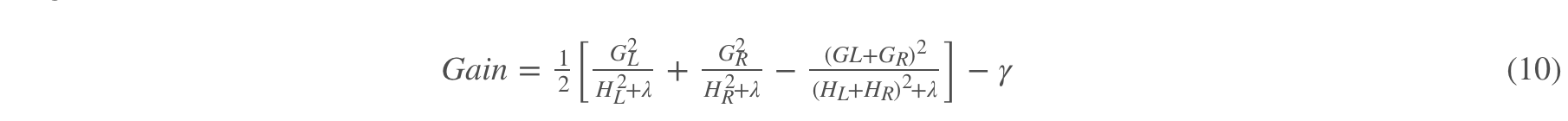
其实选择这个作为准则的原因很简单也很直观。

既然要分裂的时候,我们当然是选择分裂成左右子节点后,损失减少的最多(或者看回(9)式,由于前面的负号,所以欲求(9)的最小值,其实就是求(10)的最大值)
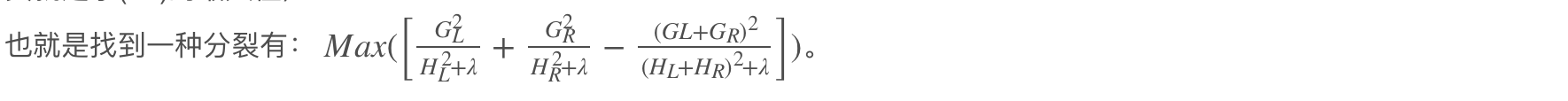
那么γ的作用是什么呢?利用γ可以控制树的复杂度,进一步来说,利用γ来作为阈值,只有大于γ时候才选择分裂。这个其实起到预剪枝的作用。
最后就是如何得到左右子节点的样本集合?这个和普通的树一样,都是通过遍历特征所有取值,逐个尝试。
至此,我们把xgboost的基本原理阐述了一遍。我们总结一下,其实就是做了以下几件事情。
1.在损失函数的基础上加入了正则项。
2.对目标函数进行二阶泰勒展开。
3.利用推导得到的表达式作为分裂准确,来构建每一颗树。
xgboost算法流程总结
xgboost核心部分的算法流程图如下:

(这里的m貌似是d)
关键问题
主要总结xgboost训练时几个关键问题
缺失值处理(稀疏问题的分裂点查找 Sparsity-aware Split Finding)
训练时候
对于数据缺失数据、one-hot编码等造成的特征稀疏现象,作者在论文中提出可以处理稀疏特征的分裂算法,主要是对稀疏特征值缺失的样本学习出默认节点分裂方向:

这样最后求出增益最大的特征值以及 miss value 的分裂方向,作者在论文中提出基于稀疏分裂算法: (修正:下文 “Input: d feature dimension” 这里 “d” 应该改为 “m”)
具体看下面的算法流程:

使用了该方法,相当于比传统方法多遍历了一次,但是它只在非缺失值的样本上进行迭代,因此其复杂度与非缺失值的样本成线性关系
预测时候
直接将确实样本特征归属到右子树
查找分裂点的近似算法 Approximate Algorithm
当数据量十分庞大,以致于不能全部放入内存时,精确的贪婪算法就不可能很有效率,通样的问题也出现在分布式的数据集中,为了高效的梯度提升算法,在这两种背景下,近似的算法被提出使用,算法的伪代码如下图所示

概括一下:枚举所有特征,根据特征,比如是第 k 个特征的分布的分位数来决定出 l 个候选切分点 Sk={sk1,sk2,⋯skl} ,然后根据这些候选切分点把相应的样本映射到对应的桶中,对每个桶的 G,H 进行累加。最后在候选切分点集合上贪心查找,和Exact Greedy Algorithm类似。
特征分布的分位数的理解
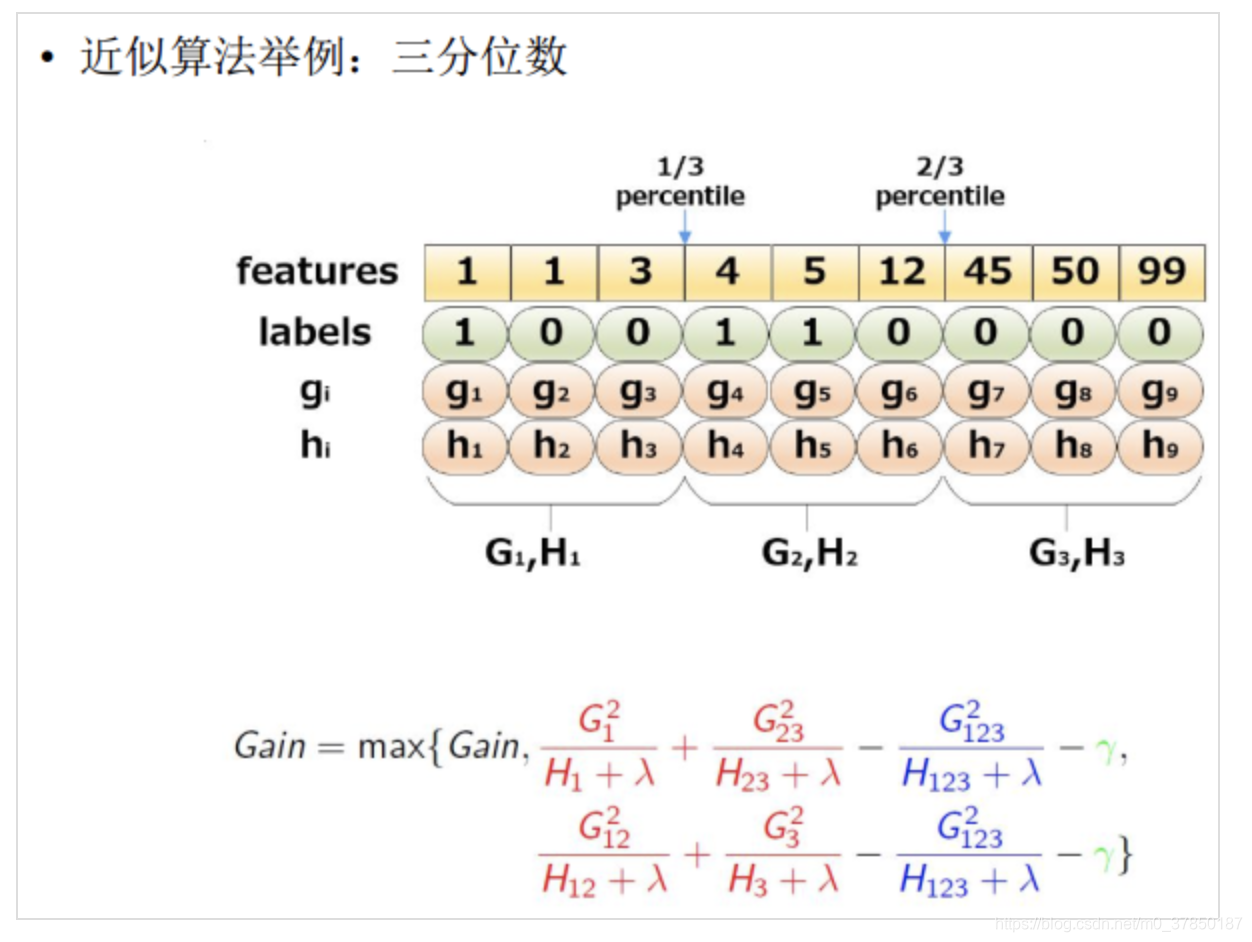
论文给出近似算法的2种变体,主要是根据候选点的来源不同区分:
- 在建树之前预先将数据进行全局(global)分桶,需要设置更小的分位数间隔,这里用 ϵ 表示,3分位的分位数间隔就是 1/3,产生更多的桶,特征分裂查找基于候选点多,计算较慢,但只需在全局执行一次,全局分桶多次使用。
- 每次分裂重新局部(local)分桶,可以设置较大的 ϵ ,产生更少的桶,每次特征分裂查找基于较少的候选点,计算速度快,但是需要每次节点分裂后重新执行,论文中说该方案更适合树深的场景
局部选择的近似算法的确比全局选择的近似算法优秀的多,所得出的结果和贪婪算法几乎不相上下。当然 局部选择的近似算法也比全局选择的近似算法速度慢
带权的分位方案 Weighted Quantile Sketch
二阶导hi作为权重
在近似的分裂点查找算法中,一个步骤就是提出候选分裂点,通常情况下,一个特征的分位数使候选分裂点均匀地分布在数据集上,就像前文举的关于特征分位数的例子

现在应该明白 Weighted Quantile Sketch 带权的分位方案的由来,下面举个例子:
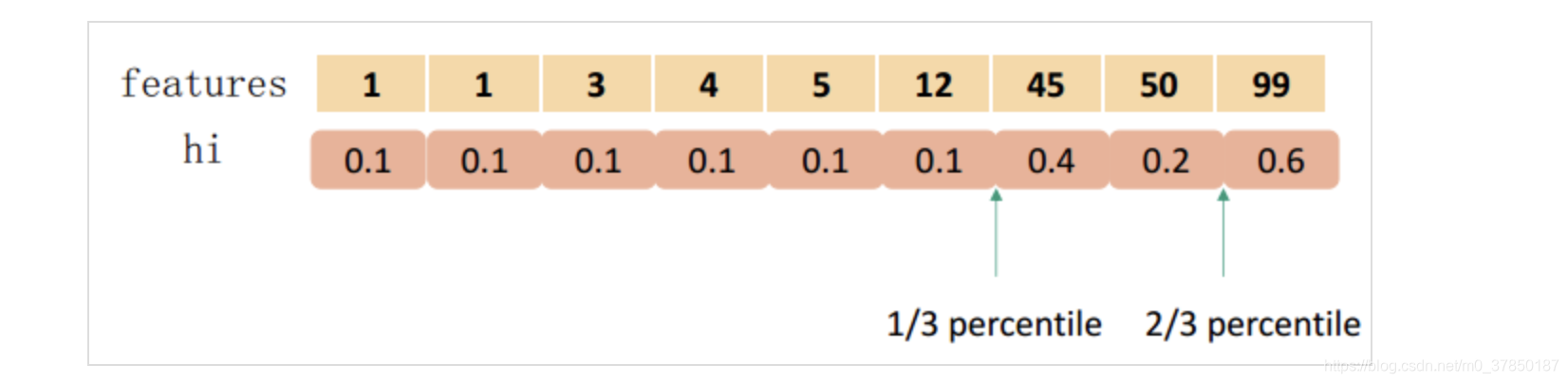
即要切分为3个,总和为1.8,因此第1个在0.6处,第2个在1.2处。此图来自知乎weapon大神的《 GBDT算法原理与系统设计简介》
旨在并行学习的列块结构 Column Block for Parallel Learning
CSR vs CSC
稀疏矩阵的压缩存储形式,比较常见的其中两种:压缩的稀疏行(Compressed Sparse Row)和 压缩的稀疏列(Compressed Sparse Row)
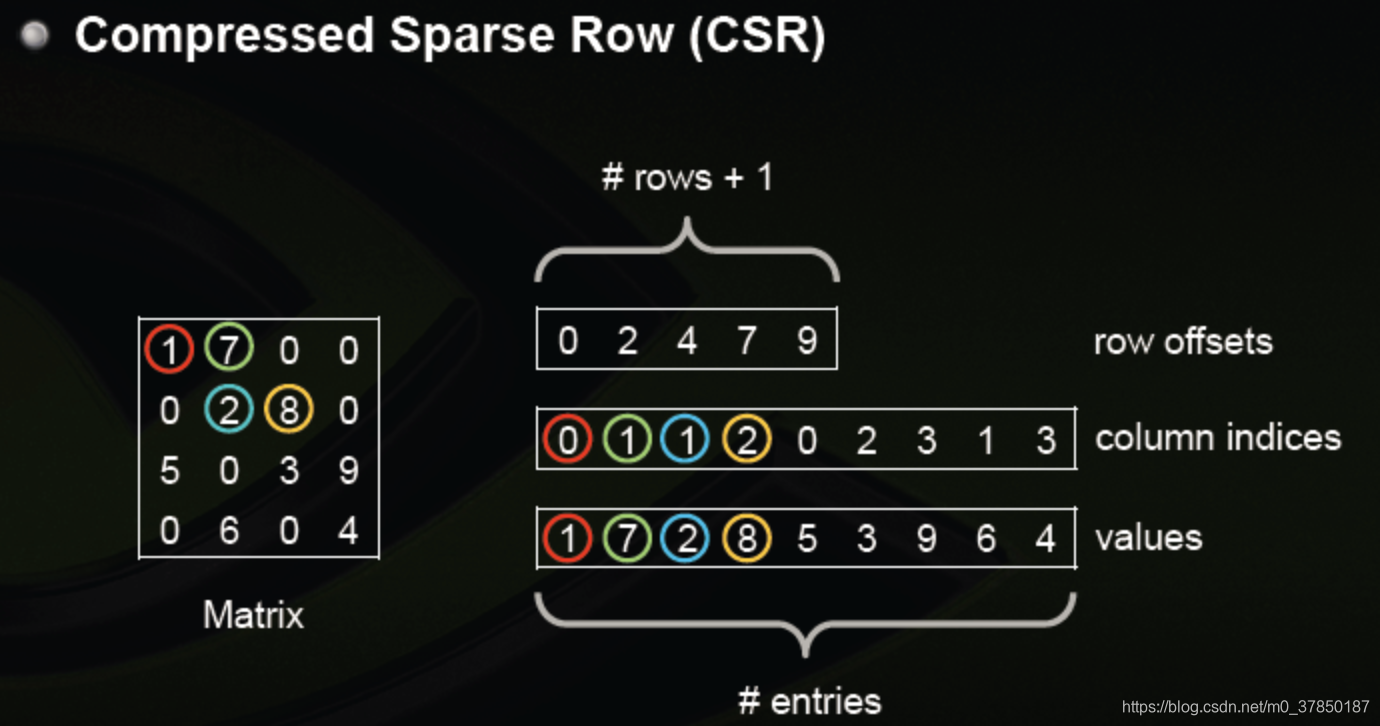
CSR结构包含非0数据块values,行偏移offsets,列下标indices。offsets数组大小为(总行数目+1),CSR 是对稠密矩阵的压缩,实际上直接访问稠密矩阵元素 (i,j) 并不高效,毕竟损失部分信息,访问过程如下:
- 根据行 i 得到偏移区间开始位置 offsets[i]与区间结束位置
offsets[i+1]-1,得到 i 行数据块values[offsets[i]..(offsets[i+1]-1)], 与非0的列下表indices[offsets[i]..(offsets[i+1]-1)] - 在列下标数据块中二分查找 j,找不到则返回0,否则找到下标值 k,返回
values[offsets[i]+k]
从访问单个元素来说,相比坐标系的存储结构,那么从 O(1) 时间复杂度升到 O(logN), N 为该行非稀疏数据项个数。但是如果要遍历访问整行非0数据,则无需访问indices数组,时间复杂度反而更低,因为少了大量的稀疏为0的数据访问。
CSC 与 CSR 变量结构上并无差别,只是变量意义不同
- values仍然为矩阵的非0数据块
- offsets为列偏移,即特征id对应数组
- indices为行下标,对应样本id数组
XBGoost使用CSC 主要用于对特征的全局预排序。预先将 CSR 数据转化为无序的 CSC 数据,遍历每个特征,并对每个特征 i 进行排序:sort(&values[offsets[i]], &values[offsets[i+1]-1])。全局特征排序后,后期节点分裂可以复用全局排序信息,而不需要重新排序。
矩阵的存储形式,参考此文稀疏矩阵存储格式总结+存储效率对比:COO,CSR,DIA,ELL,HYB

存储与计算
关注缓存的存取 Cache-aware Access
使用Block结构的一个缺点是取梯度的时候,是通过索引来获取的,而这些梯度的获取顺序是按照特征的大小顺序的。这将导致非连续的内存访问,可能使得CPU cache缓存命中率低,从而影响算法效率
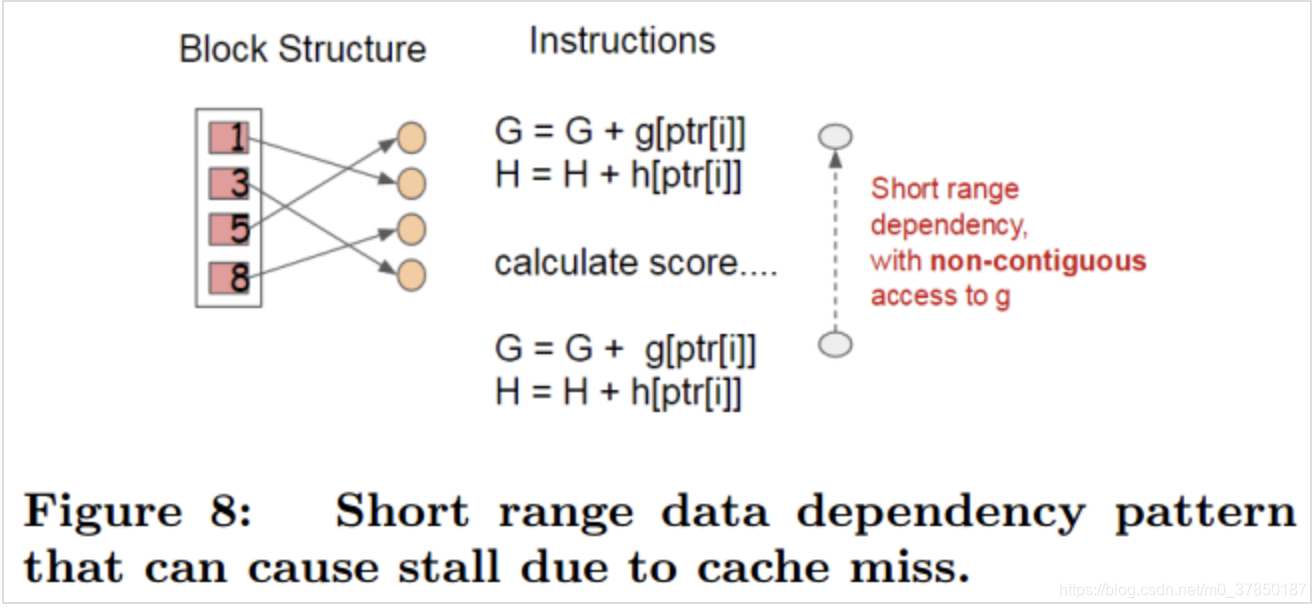
因此,对于exact greedy算法中, 使用缓存预取。具体来说,对每个线程分配一个连续的buffer,读取梯度信息并存入Buffer中(这样就实现了非连续到连续的转化),然后再统计梯度信息。该方式在训练样本数大的时候特别有用
在近似算法中,对块的大小进行了合理的设置。定义Block的大小为Block中最多的样本数。设置合适的大小是很重要的,设置过大则容易导致命中率低,过小则容易导致并行化效率不高
核外块的计算 Blocks for Out-of-core Computation
XGBoost 中提出 Out-of-core Computation优化,解决了在硬盘上读取数据耗时过长,吞吐量不足
- 多线程对数据分块压缩 Block Compression存储在硬盘上,再将数据传输到内存,最后再用独立的线程解压缩,核心思想:将磁盘的读取消耗转换为解压缩所消耗的计算资源。
- 分布式数据库系统的常见设计:Block Sharding将数据分片到多块硬盘上,每块硬盘分配一个预取线程,将数据fetche到in-memory buffer中。训练线程交替读取多块缓存的同时,计算任务也在运转,提升了硬盘总体的吞吐量
xgboost用于特征选择
xgboost主要提供了3个指标来衡量特征重要性:weight、gain、cover
weight指标
调用xgb库的get_fscore()得到 指标weight,这个指标代表着某个特征被选作分裂的次数
比如我们得到这两颗树:


可以看到特征x1被选作分裂点的次数为6,x2被选做分裂点的次数为2。
get_fscore()就是返回这个指标。
gain指标
gain是指某个特征的平均增益。
比如,特征x1被选了6次作为分裂的特征,每次的增益假如为Gain1,Gain2,…Gain6,那么其平均增益为(Gain1+Gain2+…Gain3)/6
cover指标
cover指的是每个特征在分裂时结点处的平均二阶导数。
‘cover’ - the average coverage of the feature when it is used in trees。大概的意义就是特征覆盖了多少个样本。
这里,我们不妨假设损失函数是mse,也就是0.5∗(yi−ypred)20.5∗(yi−ypred)2,我们求其二阶导数,很容易得到为常数1。也就是每个样本对应的二阶导数都是1,那么这个cover指标不就是意味着,在某个特征在某个结点进行分裂时所覆盖的样本个数吗?
缩放和列抽样 shrinkage and column subsampling
随机森林中的用法和目的一样,用来防止过拟合,主要参考论文2.3节
- 这个xgboost与现代的gbdt一样,都有shrinkage参数 (最原始的gbdt没有这个参数)类似于梯度下降算法中的学习速率,在每一步tree boosting之后增加了一个参数 η(被加入树的权重),通过这种方式来减小每棵树的影响力,给后面的树提供空间去优化模型。
- column subsampling 列(特征)抽样,这个经常用在随机森林,不过据XGBoost的使用者反馈,列抽样防止过拟合的效果比传统的行抽样还好(xgboost也提供行抽样的参数供用户使用),并且有利于后面提到的并行化处理算法。
小问题
-
剪枝与正则化Pruning and Regularization

-
提升树算法 Recap: Boosted Tree Algorithm

-
列(特征)抽样作用Column Subsampling
Column Subsampling类似于随机森林中的选取部分特征进行建树。其可分为两种,一种是按层随机采样,在对同一层内每个结点分裂之前,先随机选择一部分特征,然后只需要遍历这部分的特征,来确定最优的分割点。另一种是随机选择特征,则建树前随机选择一部分特征然后分裂就只遍历这些特征。一般情况下前者效果更好。 -
并行处理
两处并行:同层级节点可并行虽然树与树之间是串行关系,但是同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。训练速度快。
对比分析
XGBoost与GBDT
区别
-
分类器:传统GBDT以CART作为基分类器,xgboost支持多种基础分类器。比如,线性分类器,这个时候xgboost相当于带 L1 和 L2正则化项 的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
-
二阶导数:传统GBDT在优化时只用到一阶导数信息,xgboost则对损失函数函数进行了二阶泰勒展开,同时用到了一阶和二阶导数,这样相对会精确地代表损失函数的值。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导,详细参照官网API。(xgboost在建树的时候利用的准则来源于目标函数推导,也是为啥要费劲二阶泰勒展开)
-
并行处理,相比GBM有了速度的飞跃
- 借助 OpenMP ,自动利用单机CPU的多核进行并行计算
- 支持GPU加速
- 支持分布式
- 剪枝:
- 当新增分裂带来负增益时,GBM会停止分裂(贪心策略,非全局的剪枝)
- XGBoost一直分裂到指定的最大深度(max_depth),然后回过头来剪枝(事后,进行全局剪枝)
- min_child_weight : 分裂最小子节点的增益要大于这个阈值,min_child_weight < min(HL,HR),否则,放弃这个最大增益,考虑次最大增益。如果次最大增益也不满足min_child_weight<min(HL,HR),则继续往下找,如果没有找到一个满足的,则不进行分裂
-
加入正则项:boost在代价函数里加入了显示的正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和,防止过拟合,这也是xgboost优于传统GBDT的一个特性。正则化的两个部分,都是为了防止过拟合,剪枝是都有的,叶子结点输出L2平滑是新增的。
-
内置交叉验证 Built-in Cross-Validation
- XGBoost允许在每一轮boosting迭代中使用交叉验证,这样可以方便地获得最优boosting迭代次数
- GBM使用网格搜索,只能检测有限个值
-
列采样 传统的GBDT在每轮迭代时使用全部的数据,XGBoost则采用了与随机 森林相似的策略,支持对数据进行采样
-
缺失值处理 传统的GBDT没有设计对缺失值进行处理,XGBoost能够自动学习出缺 失值的处理策略。
决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行
联系
- xgboost和GBDT的学习过程都是一样的,都是基于Boosting的思想,先学习前n-1个学习器,然后基于前n-1个学习器学习第n个学习器。(Boosting)
- 建树过程都利用了损失函数的导数信息(Gradient),只是大家利用的方式不一样而已。
- 都使用了学习率来进行Shrinkage,从前面我们能看到不管是GBDT还是xgboost,我们都会利用学习率对拟合结果做缩减以减少过拟合的风险。
参考文献
xgboost原理分析以及实践
XGBoost原理和底层实现剖析
陈天奇slide https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
陈天奇XGBoost论文 https://arxiv.org/pdf/1603.02754.pdf
其他可参考下列博文:
XGBoost详解
一文读懂机器学习大杀器XGBoost原理
xgboost原理?
xgboost专栏
深入浅出学会xgboost 系列
GBDT与XGBoost
XGBoost Documentation
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?
深入理解XGBoost,优缺点分析,原理推导及工程实现
《统计学习方法》第8章 提升方法之AdaBoost\BoostingTree\GBDT

