
- 1同样的APP为何在Android 8以后网络感觉变卡?
- 2史上最全!用Pandas读取CSV,看这篇就够了
- 3基础编码管理组件 Example 程序
- 4【实用党】推荐几款实用的AI工具_手绘生成图片
- 5【C语言篇】链表的基本操作-创建链表、插入节点、删除节点、打印链表_链表结构体打印链表程序
- 6【行为识别现状调研1】_多尺度时空特征和运动特征的异常行为识别
- 7QUIC:基于UDP的多路复用安全传输(部分翻译)_quic的多路复用
- 8mysql查询和修改的底层原理_数据库修改的实质是什么
- 9技术的正宗与野路子 c#, AOP动态代理实现动态权限控制(一) 探索基于.NET下实现一句话木马之asmx篇 asp.net core 系列 9 环境(Development、Staging ...
- 10中兴新支点桌面操作系统——一些小而美的功能
脉冲神经网络_【强基固本】脉冲神经网络(SNN)
赞
踩
“强基固本,行稳致远”,科学研究离不开理论基础,人工智能学科更是需要数学、物理、神经科学等基础学科提供有力支撑,为了紧扣时代脉搏,我们推出“强基固本”专栏,讲解AI领域的基础知识,为你的科研学习提供助力,夯实理论基础,提升原始创新能力,敬请关注。
作者: 初识CV地址:https://www.zhihu.com/people/AI_team-WSF
本文大部分内容来自:脉冲神经网络的五脏六腑,做一下笔记对原始文章增添一下自己的理解。
https://blog.csdn.net/u011853479/article/details/61414913
第一代神经网络:感知机,第二代神经网络:ANN,第三代神经网络:脉冲神经网络。由于DCNN采用基于速率的编码,所以其硬件实现需要消耗更多的‘能量’。SNN中每个神经元最多使用一个脉冲,而大多数神经元根本不放电,导致能量消耗最小。
Spike-YOLO:SNN在目标检测上的首次尝试:
https://zhuanlan.zhihu.com/p/159982953
SNN的构建过程
构建脉冲神经元模型(建模)——构建神经脉冲序列(编码)——脉冲神经网络的训练方法 简化过程:建模——编码——训练(学习规则、转换等)
学习规则
简单介绍无监督的STDP和有监督的R-STDP 无监督的STDP(特征要多):利用STDP网络可以成功地提取频繁出现的视觉特征。但是需要额外的分类器,例如:SVM等。 有监督的R-STDP(特征少也可以):提取对任务有诊断作用的特征,然后丢弃其他特征。网络可以只根据最后一层中最早的峰值来决定对象的类别,而不使用任何外部分类器,使用R-STDP训练的神经决策层。 特征图数量较少时,R-STDP在寻找诊断特征(丢弃干扰物)方面明显优于STDP。R-STDP在提高性能和置信水平方面表现出单调的行为,但在置信水平上,R-STDP不如R-STDP稳健。ANN向SNN转换
采用近似转换的方式,Reset to zero(适用于浅层网络)和Reset by subtraction(适用于深层网络)两种转换方式,脉冲发射率 和ANN的激活值
和ANN的激活值
 成比例
成比例
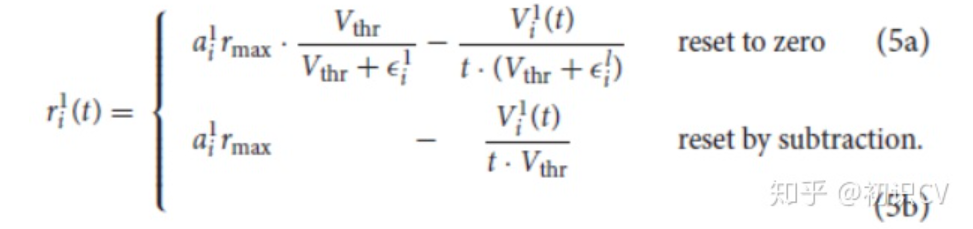
https://blog.csdn.net/h__ang/article/details/90609793
01
构建脉冲神经元模型
传统的人工神经元模型主要包含两个功能,一是对前一层神经元传递的信号计算加权和,二是采用一个非线性激活函数输出信号。 前者用于模仿生物神经元之间传递信息的方式,后者用来提高神经网络的非线性计算能力。相比于人工神经元,脉冲神经元则从神经科学的角度出发,对真实的生物神经元进行建模。 SNN所构成的深度网络是一种高效节能的神经网络,每幅图像只有几个峰值作为特征,这使得它适合于神经形态硬件的实现。(虽然现在SDNN只能在小的数据集上面进行测试,而且识别精度不如DCNN,但是相信不久的将来SDNN会是一个发展很好的方向)。1.1 Hodgkin-Huxley( HH)模型
HH模型的数学公式推导和MATLAB代码: https://zhuanlan.zhihu.com/p/102770891 HH模型是一组描述神经元细胞膜的电生理现象的非线性微分方程,直接反映了细胞膜上离子通道的开闭情况。 HH模型所对应的电路图如图1-2所示,其中 C 代表脂质双层(lipid bilayer) 的电容;RNa, RK, Rl分别代表钠离子通道、 钾离子通道与漏电通道的电阻(RNa, RK 上的斜箭头表明其为随时间变化的变量, 而 R l 则为一个常数);E l, E Na, E K 分别代表由于膜内外电离子浓度差别所导致的漏电平衡电压、钠离子平衡电压、钾离子平衡电压;膜电压V代表神经膜内外的电压差,可以通过HH模型的仿真来得到V随时间变化的曲线。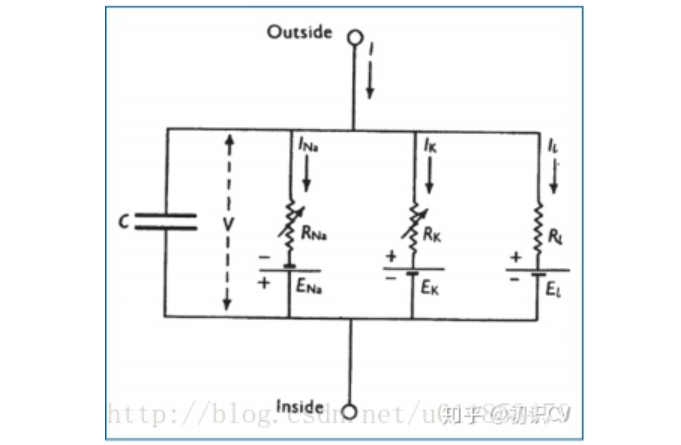
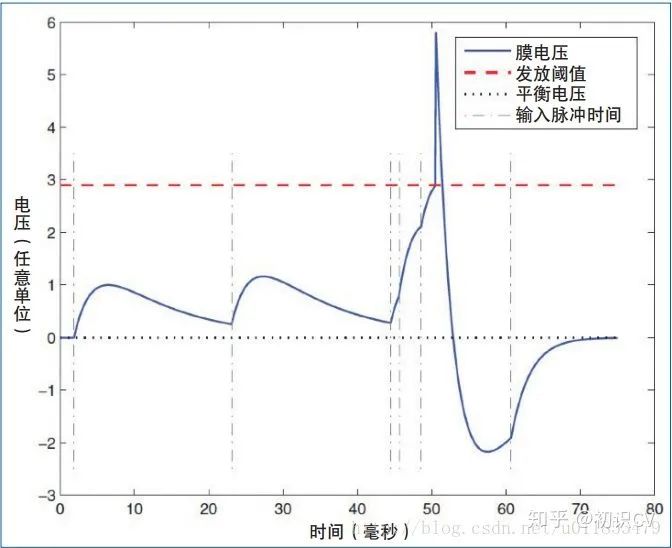 神经元的膜电压变化,图1-2
神经元的膜电压变化,图1-2
1.2 Leaky Integrate and Fire(LIF)模型
为了解决HH模型运算量的问题,许多学者提出了一系列的简化模型。LIF模型将细胞膜的电特性看成电阻和电容的组合。 简单介绍:https://blog.csdn.net/qq_34886403/article/details/75735448
1.3 Izhikevich模型 HH模型精确度高,但运算量大。LIF模型运算量小,但牺牲了精确度。Izhikevich模型结合了两者的优势,生物精确性接近HH模型,运算复杂度接近LIF模型。02
神经脉冲序列
在完成神经元的建模之后,需要对神经元传递的信息进行编码,一种主流的方法是通过神经元的放电频率来传递信息。在大脑皮层,连续动作电位的时序非常没有规律。一种观点认为这种无规律的内部脉冲间隔反映了一种随机过程,因此瞬时放电频率可以通过求解大量神经元的响应均值来估计。另一种观点认为这种无规律的现象可能是由突触前神经元活动的精确巧合所形成的,反映了一种高带宽的信息传递通路。本文主要基于第一种观点,用随机过程的方法生成脉冲序列。
2.1 瞬时放电频率
神经元的响应函数由一系列的脉冲函数所构成,如公式所示。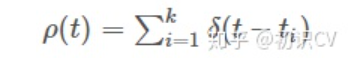
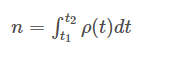
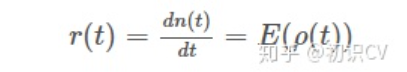
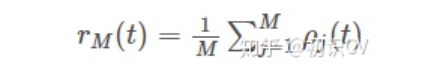
2.2 齐次泊松过程
假设每个脉冲的生成是相互独立的,并且瞬时放电频率是一个常数。设时间段内含有k个脉冲,那么在时间段内含有n个脉冲的概率可由公式表示。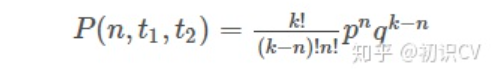
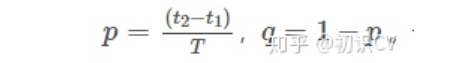
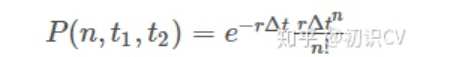
2.2.1 泊松脉冲序列的生成
2.2.1.1 相邻脉冲间的时间间隔固定
对于齐次泊松过程,在固定时间间隔δt内,产生一个脉冲的概率为: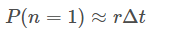
2.2.1.2 相邻脉冲见的时间间隔不固定
根据上面的讨论,在间隔[ ,
+τ]内,发放的脉冲数为0的概率为:
,
+τ]内,发放的脉冲数为0的概率为:
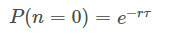 +τ之前发放脉冲的概率可表示为:
+τ之前发放脉冲的概率可表示为:
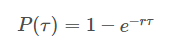
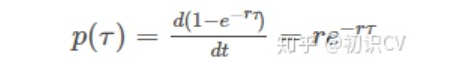
2.3 非齐次泊松过程
相较于齐次泊松过程,非齐次泊松模型假设放电频率是时间的函数 ,更具有一般性。只有间隔 足够小,那么在这段时间内,放电频率仍可以视为常数。上述的理论依然有效。2.4 扩展
2.4.1 不应期
根据神经科学理论,神经元在放电之后的短暂时间内存在不应期,即对输入信号不响应。为了在脉冲序列中模拟这个过程,在神经元放电之后的不应期内将瞬时放电频率置为0。在不应期结束之后,瞬时放电频率在限定时间内逐渐回到原始值。2.4.2 涌现
神经元在某个时刻会集中性的放电,称为涌现现象。为了模拟这种现象,设置每个时刻发放的泊松脉冲数不固定,可能包含0,1,或多个脉冲。每个时刻发放的脉冲数符合一定的概率分布。例如,设x是 上符合均匀分布的一个随机数,当x取不同值时,该时刻发放的脉冲数也不同。03
脉冲神经网络的训练方法
人工神经网络主要基于误差反向传播(BP)原理进行有监督的训练,目前取得很好的效果。对于脉冲神经网络而言,神经信息以脉冲序列的方式存储,神经元内部状态变量及误差函数不再满足连续可微的性质,因此传统的人工神经网络学习算法不能直接应用于脉冲神经神经网络。目前,脉冲神经网络的学习算法主要有以下几类。 需要注意的点:
- 突触的权重的调整是由突触前和突触后神经元的相对峰值时间决定的以及teacher的反馈。
- STDP 分为LTP(长期增强作用)和LTD(长期抑制作用)。
- 在训练中,无论何时z神经元释放一个峰值,它都会经历某种形式的STDP。
- teacher决定输出的z神经元是进行Hebbian STDP还是anti-Hebbian STDP,如果z神经元表示目标类别,那么它将进行Hebbian STDP。否则,它将进行anti-Hebbian STDP。
- 使用正则化技术对权重进行了重新规范化(最后的改进将会讲到为什么要这样做)。
3.1 无监督学习算法
这类算法从生物可解释性出发,主要基于赫布法则 (Hebbian Rule)。Hebb在关于神经元间形成突触的理论中提到,当两个在位置上临近的神经元,在放电时间上也临近的话,他们之间很有可能形成突触。而突触前膜和突触后膜的一对神经元的放电活动(spike train)会进一步影响二者间突触的强度。这个假说也得到了实验验证。华裔科学家蒲慕明和毕国强在大树海马区神经元上,通过改变突触前膜神经元和突触后膜神经元放电的时间差,来检验二者之间突触强度的变化。实验结果如图3-1所示。
3.1.1 三相STDP
权值更新规则如公式所示。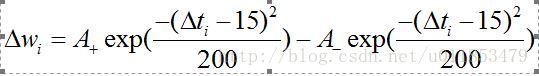
 和
和
 表示学习率, 表示突触前脉冲传到突触后脉冲所需的时间。函数关系如图3-2所示。
表示学习率, 表示突触前脉冲传到突触后脉冲所需的时间。函数关系如图3-2所示。
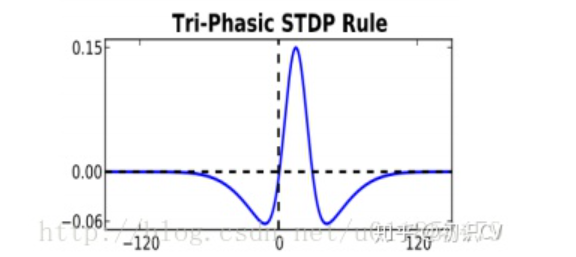
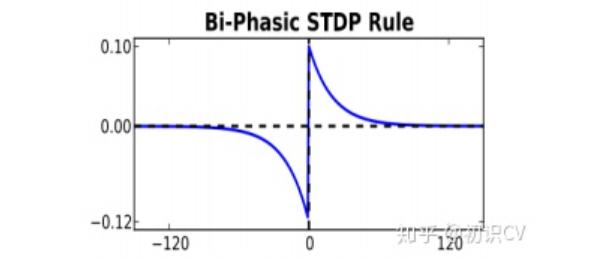
3.1.2 二相STDP
权值更新规则如公式所示。
 和
和
 用来控制电压下降的速度,被视为时间常数。函数关系如图3-3所示。
用来控制电压下降的速度,被视为时间常数。函数关系如图3-3所示。
3.2 有监督学习算法
有监督学习算法依据是否具有生物可解释性分为两大类,一种是基于突触可塑性的监督学习算法,另外两种分别是基于梯度下降规则的监督学习算法和基于脉冲序列卷积的监督学习算法。3.2.1 基于突触可塑性的监督学习算法
3.2.1.1 监督Hebbian学习算法
通过“教师”信号使突触后神经元在目标时间内发放脉冲,“教师”信号可以表示为脉冲发放时间,也可以转换为神经元的突触电流形式。在每个学习周期,学习过程由3个脉冲决定,包括2个突触前脉冲和1个突触后脉冲。第一个突触前脉冲表示输入信号,第二个突触前脉冲表示突触后神经元的目标脉冲,权值的学习规则可表示为: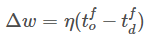
 和
和
 分别表示突触后神经元的实际和目标脉冲时间。
分别表示突触后神经元的实际和目标脉冲时间。
3.2.1.2 远程监督学习算法(ReSuMe)
远程监督方法结合STDP和anti-STDP两个过程,提出的突触权值随时间变化的学习规则为:

3.2.1.3 其他监督学习算法
结合BCM(Bienenstock-Cooper-Munro)学习规则和STDP机制,Wade等人提出了多层前馈脉冲神经网络的SWAT(Synaptic Weight Association Training)算法。研究者应用奖惩调制的STDP机制实现了脉冲神经网络脉冲序列模式的学习。此外,有学者从统计学的角度出发提出了一种脉冲神经网络的监督学习算法,学习规则可有一个类似于STDP的二阶学习窗口来描述,学习窗口的形状是通过优化过程的不同场景所加入的约束来影响的。 基于脉冲序列卷积的监督学习算法,通过对脉冲序列基于核函数的卷积计算,可将脉冲序列解释为特定的神经生理信号,比如神经元的突触后电位或脉冲发放的密度函数。通过脉冲序列的内积来定量地表示脉冲序列之间的相关性,评价实际脉冲序列与目标脉冲序列的误差。 基于梯度下降的监督学习算法。借鉴传统人工神经网络的误差反向传播算法,利用神经元目标输出与实际输出之间的误差,应用梯度下降法和delta更新规则更新权值。比如SpikiProp算法。04
ANN向SNN的转化
由于脉冲神经网络的训练算法不太成熟,一些研究者提出将传统的人工神经网络转化为脉冲神经网络,利用较为成熟的人工神经网络训练算法来训练基于人工神经网络的深度神经网络,然后通过触发频率编码将其转化为脉冲神经网络,从而避免了直接训练脉冲神经网络的困难。4.1 CNN转化为SNN
对原始的CNN进行训练,将训练好的权值直接迁移到相似网络结构的SNN。 转换的难点在于:- CNN中的某一层神经元可能会输出负值,这些负数用SNN表示会比较困难。比如,CNN中的sigmoid函数的输出范围为-1到1,每个卷积层的加权和可能也为负值,在进行颜色空间变换时某个颜色通道也可能取到负值。虽然,SNN可以采用抑制神经元来表示负值,但会成倍地增加所需要的神经元数目,提高计算的复杂度。
- 对于SNN,CNN中神经元的偏置很难表示。
- CNN中的Max-pooling层对应到SNN中,需要两层的脉冲神经网络。同样提高了SNN的复杂度。
- 保证CNN中的每个神经元的输出值都是正数。在图像预处理层之后,卷积层之前加入abs()绝对值函数,保证卷积层的输入值都是非负的。将神经元的激活函数替换为ReLU函数。一方面可以加快原始CNN的收敛速度,另一方面ReLU函数和LIF神经元的性质比较接近,可以最小化网络转化之后的精度损失。
- 将CNN所有的偏置项都置为0。
- 采用空间线性降采样层代替Max-pooling层。
- SNN的网络结构与裁剪后的CNN相同,单纯地将CNN中的人工神经元替换为脉冲神经元。
- 在CNN的卷积层之前增加用于脉冲序列生成的一层网络,对输入的图像数据进行编码,转化为脉冲序列。
- 变换决策方式。在某一段时间内,对全连接层输出的脉冲数进行统计,取脉冲数最多的类别作为最终的分类结果。
- 将裁减后的CNN训练得到的权值全部迁移到对应的SNN。
 图4-1
图4-1
- 神经元的输入脉冲不够,导致神经元的膜电压无法超过设定的阈值,造成放电频率过低。
- 神经元的输入脉冲过多,导致ReLU模型在每个采样周期内输出多个脉冲。
- 因为脉冲序列输入是以一定的概率选择的,会导致某些特征一直处于边缘地带或占据了过多的主导地位。
参考文献
[1] Gerstner W, Kistler W M. Spiking neuron models: Single neurons, populations, plasticity[M]. Cambridge university press, 2002.
[2] Izhikevich E M. Simple model of spiking neurons[J]. IEEE Transactions on neural networks, 2003, 14(6): 1569-1572.
[3] Izhikevich E M. Hybrid spiking models[J]. Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, 2010, 368(1930): 5061-5070.
[4] Heeger D. Poisson model of spike generation[J]. Handout, University of Standford, 2000, 5: 1-13.
[5] Hebb D O. The organization of behavior: A neuropsychological theory[M]. Psychology Press, 2005.
[6] Caporale N, Dan Y. Spike timing-dependent plasticity: a Hebbian learning rule[J]. Annu. Rev. Neurosci., 2008, 31: 25-46.
[7] Ponulak F, Kasinski A. Supervised learning in spiking neural networks with ReSuMe: sequence learning, classification, and spike shifting[J]. Neural Computation, 2010, 22(2): 467-510.
[8] Wade J J, McDaid L J, Santos J A, et al. SWAT: a spiking neural network training algorithm for classification problems[J]. IEEE Transactions on neural networks, 2010, 21(11): 1817-1830.
[9] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Cognitive modeling, 1988, 5(3): 1.
[10] Bohte S M, Kok J N, La Poutre H. Error-backpropagation in temporally encoded networks of spiking neurons[J]. Neurocomputing, 2002, 48(1): 17-37.
[11] Ghosh-Dastidar S, Adeli H. A new supervised learning algorithm for multiple spiking neural networks with application in epilepsy and seizure detection[J]. Neural networks, 2009, 22(10): 1419-1431.
[12] Mohemmed A, Schliebs S, Matsuda S, et al. Span: Spike pattern association neuron for learning spatio-temporal spike patterns[J]. International Journal of Neural Systems, 2012, 22(04): 1250012.
[13] Mohemmed A, Schliebs S, Matsuda S, et al. Training spiking neural networks to associate spatio-temporal input–output spike patterns[J]. Neurocomputing, 2013, 107: 3-10.
[14] Yu Q, Tang H, Tan K C, et al. Precise-spike-driven synaptic plasticity: Learning hetero-association of spatiotemporal spike patterns[J]. Plos one, 2013, 8(11): e78318.
[15] Cao Y, Chen Y, Khosla D. Spiking deep convolutional neural networks for energy-efficient object recognition[J]. International Journal of Computer Vision, 2015, 113(1): 54-66.
[16] Diehl P U, Neil D, Binas J, et al. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing[C]//2015 International Joint Conference on Neural Networks (IJCNN). IEEE, 2015: 1-8.
[17] O’Connor P, Neil D, Liu S C, et al. Real-time classification and sensor fusion with a spiking deep belief network[J]. Neuromorphic Engineering Systems and Applications, 2015: 61.
[18] Maass W, Natschläger T, Markram H. Real-time computing without stable states: A new framework for neural computation based on perturbations[J]. Neural computation, 2002, 14(11): 2531-2560.
[19] LIN X, WANG X, ZHANG N, et al. Supervised Learning Algorithms for Spiking Neural Networks: A Review[J]. Acta Electronica Sinica, 2015, 3: 024.
[20] 顾宗华, 潘纲. 神经拟态的类脑计算研究[J]. 中国计算机学会通讯, 2015, 11(10): 10-20.
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。

直播预告

“强基固本”历史文章

分享、点赞、在看,给个三连击呗!

