
- 1pyqt5背景色设置使用css或者是调色板
- 2五一 Llama 3 超级课堂 | 第一节 本地Web Demo部署 实践笔记
- 3HBase优化之Apache Phoenix二级索引_skip-scan-join table 0
- 4【idea插件神器】教你如何使用IDEA一键set实体类中所有属性_idea设置set所有bean属性
- 5群晖HomeAssistant安装HACS插件商店结合内网穿透实现公网访问本地智能家居_群晖hacs安装包
- 6学习通刷课_学习通自动刷视频插件
- 7RP2040-HAT-MODBUS-C_arduino rp2040 modbus
- 8腾讯计算机编程本科年薪,腾讯程序员年薪80万,却感慨:天花板太低,想放弃工作去读研!...
- 9【云原生】kubernetes中pod的生命周期、探测钩子的实战应用案例解析
- 107 Series FPGAs Integrated Block for PCI Express IP核 Advanced模式配置详解(三)_advanced设置
数学建模笔记-1_考察 9条一维数据: z=,i=1,2,..,9。用合并聚类算法将这组数据聚成3类
赞
踩
用到的软件:Matlab 2018, 26,Stata 14,Excel,World,Python.
一.层次分析法(AHP)
1.适用与局限:
适用:通过建立递阶层次结构,把人类的判断转化到若干因素两两比较上。主要用于解决评价类问题——例如:那种方案最好、哪位运动员或者员工表现的更优秀
局限:判断矩阵的主观性较强,适用于指标n较少的情况(n<15),否则判断矩阵和一致矩阵差异很大
2.做题步骤:
(1)建立系统的递阶层次结构——分析系统中各因素的关系
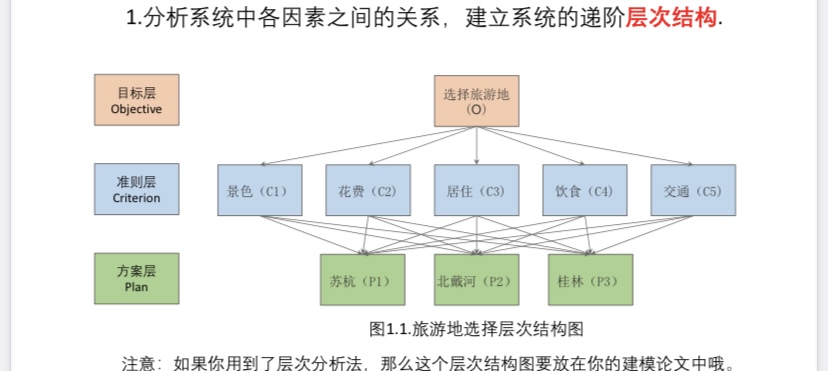
(2)构造判断矩阵——重要性两两比较
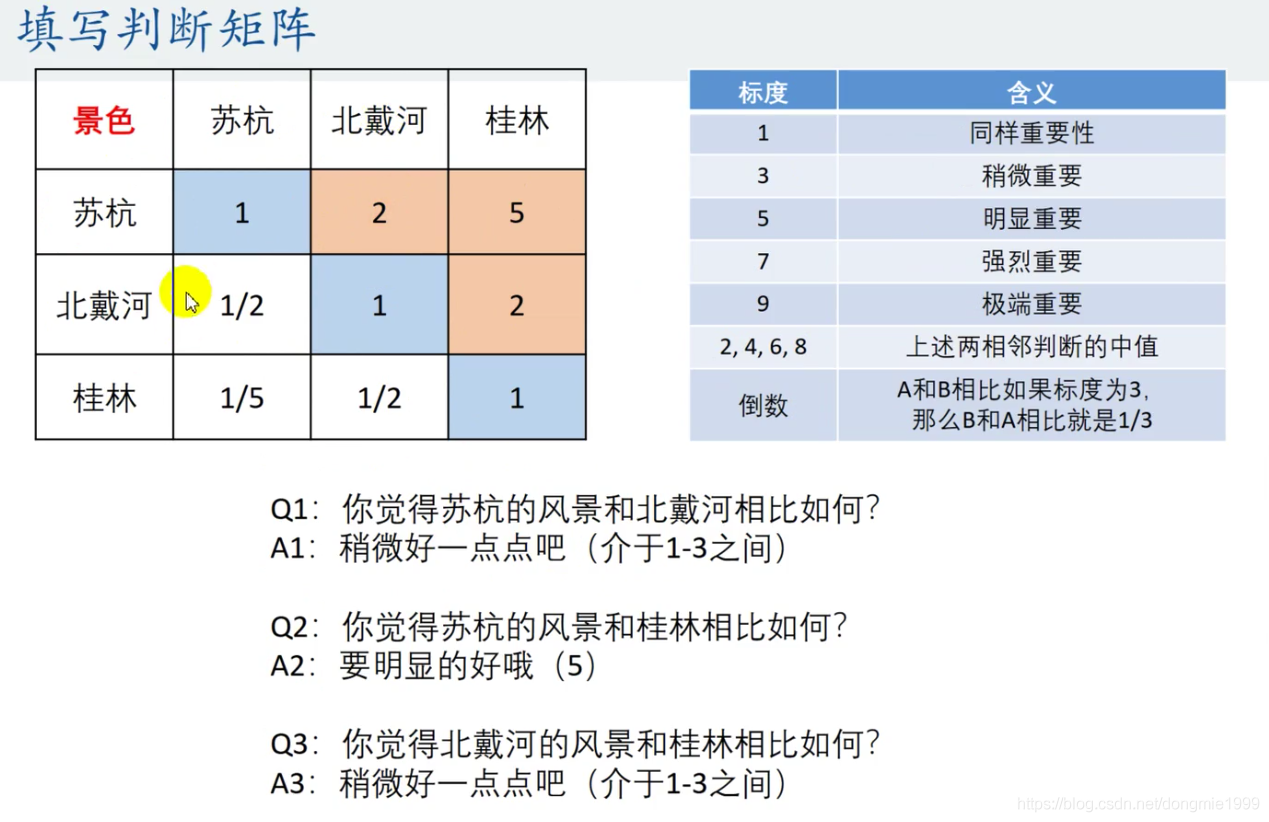
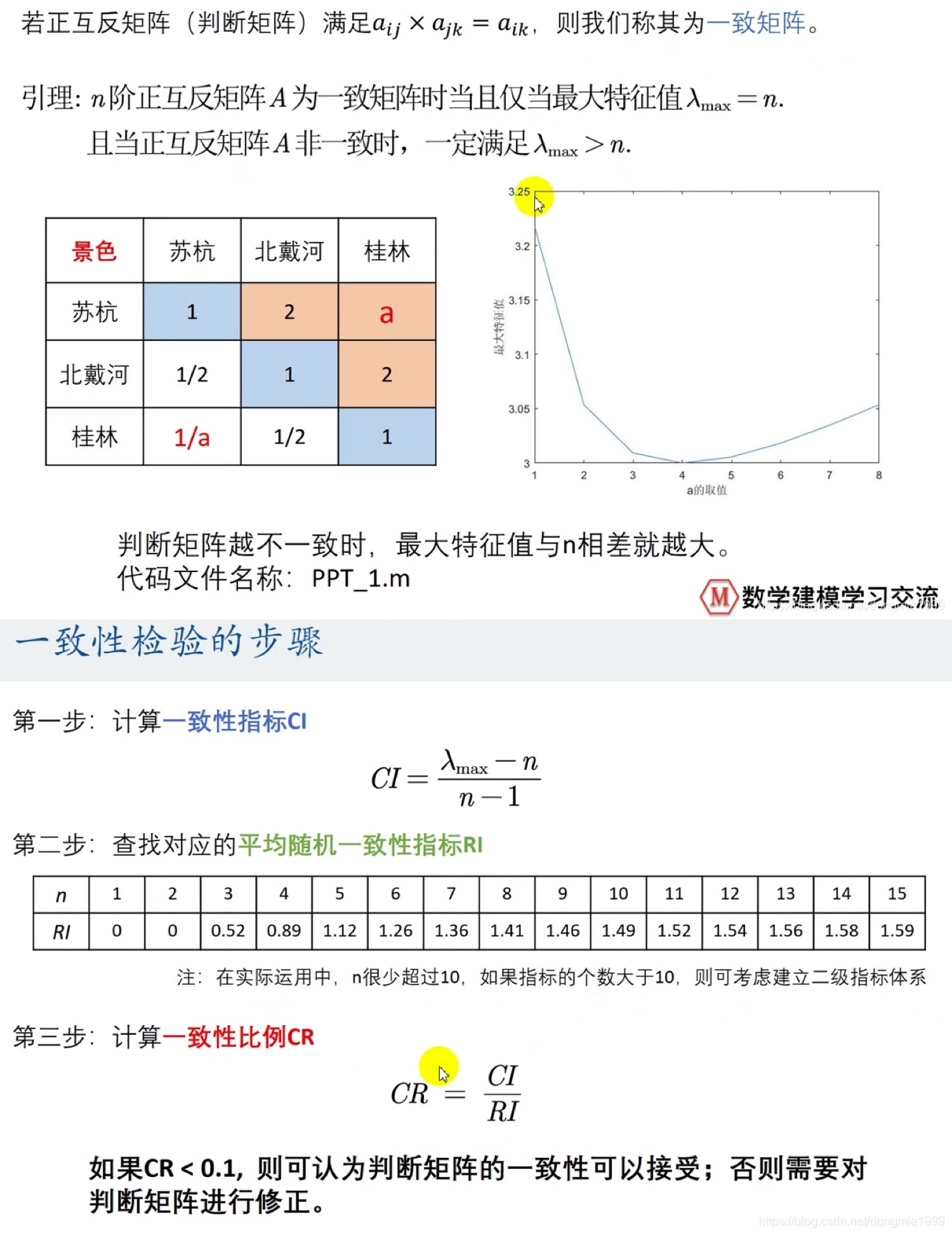
(3)一致性检验
原理:检验我们构造的判断矩阵和一致矩阵是否相差太大
判断矩阵:又称正互反矩阵,其特点为 aij > 0 且 aij x aji = 1
一致矩阵:各行(各列)之间成倍数,aik = aij x ajk = 1
注意:在层次分析法中,我们构造的判断矩阵均是正互反矩阵,故在使用判断矩阵求权重之前,必须进行一致性检验
求特征值入代码如下:
a = [1:1:8]
b = []
for i = 1:size(a,2)
A = [1,2,a(i);1/2,1,2;1/a(i),1/2,1]
b = [b,max(eig(A))]
end
plot(a,b
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(4)由判断矩阵得到权重——计算得分后排名
三种方法:算术平均法、几何平均法、特征值平均法 (其中特征值法常用)
以往的论文利用层次分析法解决实际问题时,都是采用其中某一种方法求权重,而不同的计算方法可能会导致结果有所偏差。为了保证结果的稳健性,采用三种方法分别求出了权重后计算平均值,再根据得到的权重矩阵计算各方案的得分,并进行排序和综合分析,这样避免了采用单一方法所产生的偏差,得出的结论将更全面、更有效。
注:一致矩阵不需要进行一致性检验,只有非一致矩阵的判断矩阵才需
Matlab上代码如下:
%% 输入判断矩阵 clear;clc disp('请输入判断矩阵A: ') % A = input('判断矩阵A=') A =[1 1 4 1/3 3; 1 1 4 1/3 3; 1/4 1/4 1 1/3 1/2; 3 3 3 1 3; 1/3 1/3 2 1/3 1] % matlab矩阵有两种写法,可以直接写到一行: % [1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1] % 也可以写成多行: [1 1 4 1/3 3; 1 1 4 1/3 3; 1/4 1/4 1 1/3 1/2; 3 3 3 1 3; 1/3 1/3 2 1/3 1] % 两行之间以分号结尾(最后一行的分号可加可不加),同行元素之间以空格(或者逗号)分开。 %% 方法1:算术平均法求权重 % 第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和) Sum_A = sum(A) [n,n] = size(A) % 也可以写成n = size(A,1) % 因为我们的判断矩阵A是一个方阵,所以这里的r和c相同,我们可以就用同一个字母n表示 SUM_A = repmat(Sum_A,n,1) %repeat matrix的缩写 % 另外一种替代的方法如下: SUM_A = []; for i = 1:n %循环哦,这一行后面不能加冒号(和Python不同),这里表示循环n次 SUM_A = [SUM_A; Sum_A] end clc;A SUM_A Stand_A = A ./ SUM_A % 这里我们直接将两个矩阵对应的元素相除即可 % 第二步:将归一化的各列相加(按行求和) sum(Stand_A,2) % 第三步:将相加后得到的向量中每个元素除以n即可得到权重向量 disp('算术平均法求权重的结果为:'); disp(sum(Stand_A,2) / n) % 首先对标准化后的矩阵按照行求和,得到一个列向量 % 然后再将这个列向量的每个元素同时除以n即可(注意这里也可以用./哦) %% 方法2:几何平均法求权重 % 第一步:将A的元素按照行相乘得到一个新的列向量 clc;A Prduct_A = prod(A,2) % prod函数和sum函数类似,一个用于乘,一个用于加 dim = 2 维度是行 % 第二步:将新的向量的每个分量开n次方 Prduct_n_A = Prduct_A .^ (1/n) % 这里对每个元素进行乘方操作,因此要加.号哦。 ^符号表示乘方哦 这里是开n次方,所以我们等价求1/n次方 % 第三步:对该列向量进行归一化即可得到权重向量 % 将这个列向量中的每一个元素除以这一个向量的和即可 disp('几何平均法求权重的结果为:'); disp(Prduct_n_A ./ sum(Prduct_n_A)) %% 方法3:特征值法求权重 % 第一步:求出矩阵A的最大特征值以及其对应的特征向量 clc [V,D] = eig(A) %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0) Max_eig = max(max(D)) %也可以写成max(D(:))哦~ % 那么怎么找到最大特征值所在的位置了? 需要用到find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。 % 那么问题来了,我们要得到最大特征值的位置,就需要将包含所有特征值的这个对角矩阵D中,不等于最大特征值的位置全变为0 % 这时候可以用到矩阵与常数的大小判断运算 D == Max_eig [r,c] = find(D == Max_eig , 1) % 找到D中第一个与最大特征值相等的元素的位置,记录它的行和列。 % 第二步:对求出的特征向量进行归一化即可得到我们的权重 V(:,c) disp('特征值法求权重的结果为:'); disp( V(:,c) ./ sum(V(:,c)) ) % 我们先根据上面找到的最大特征值的列数c找到对应的特征向量,然后再进行标准化。 %% 计算一致性比例CR clc CI = (Max_eig - n) / (n-1); RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15 CR=CI/RI(n); disp('一致性指标CI=');disp(CI); disp('一致性比例CR=');disp(CR); if CR<0.10 disp('因为CR < 0.10,所以该判断矩阵A的一致性可以接受!'); else disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!'); end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
二.优劣解距离法(TOPSIS法)
1.适用:
TPOPSIS法是一种常用的综合评价方法,其能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
2.做题步骤:
(1)将原始矩阵正向化

(2)正向化矩阵标准化

(3)计算得分并归一化

Matlab上代码如下:
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X % (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X % (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V) % (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据) % (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。 clear;clc load data_water_quality.mat %% 注意:如果提示: 错误使用 load,无法读取文件 'data_water_quality.mat'。没有此类文件或目录。 % 那么原因是因为你的Matlab的当前文件夹中不存在这个文件 % 可以使用cd函数修改Matlab的当前文件夹 % 比如说,我的代码和数据放在了: D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据 % 那么我就可以输入命令: % cd 'D:第2讲.TOPSIS法(优劣解距离法)\代码和例题数据' % 也可以看我更新的视频:“更新9_Topsis代码为什么运行失败_得分结果怎么可视化以及权重的确定如何更加准确”,里面有介绍 %% 第二步:判断是否需要正向化 [n,m] = size(X); disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标']) % number to string:s = num2str(A)将数组A中的数转换成字符串表示形式 Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']); if Judge == 1 Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4] disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ') Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3] % 注意,Position和Type是两个同维度的行向量 for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数 X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i)); % Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数 % 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素 % 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型) % 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列 % 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量 end disp('正向化后的矩阵 X = ') disp(X) end %% 第三步:对正向化后的矩阵进行标准化 Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1); disp('标准化矩阵 Z = ') disp(Z) %% 第四步:计算与最大值的距离和最小值的距离,并算出得分 D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量 D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量 S = D_N ./ (D_P+D_N); % 未归一化的得分 disp('最后的得分为:') stand_S = S / sum(S) [sorted_S,index] = sort(stand_S ,'descend') % A = magic(5) % 幻方矩阵 % M = magic(n)返回由1到n^2的整数构成并且总行数和总列数相等的n×n矩阵。阶次n必须为大于或等于3的标量。 % sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。 % sort(A)若A是矩阵,默认对A的各列进行升序排列 % sort(A,dim) % dim=1时等效sort(A) % dim=2时表示对A中的各行元素升序排列 % A = [2,1,3,8] % Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量; % 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60

