
热门标签
热门文章
- 1项目实战-外卖自提柜 3. FreeRTOS主要API的应用_freertos大项目实战
- 2Android使用adb截屏_android adb 截屏
- 3hbase安装教程_hbase 安装
- 4游戏开发的最新发展趋势分析_游戏开发方面的最前沿趋势
- 5Java进阶 1-3 枚举(switch的新特性)_java switch 枚举
- 6本地pycharm远程连接服务器运行自己的项目_pychram 运行服务器上已有项目
- 7向量数据库入坑指南:初识 Faiss,如何将数据转换为向量(一)_向量库的向量和内容怎么转换
- 8头哥数据库实战答案及解析(1-1 到 1-5)_头歌数据库答案
- 9图书管理系统(SpringBoot+SpringMVC+MyBatis)
- 10[微机原理]智慧交通路口测速实验_智慧交通测速实验
当前位置: article > 正文
数据挖掘实战(4)——聚类(Kmeans、MiniBatchKmeans、DBSCAN、AgglomerativeClustering、MeanShift)_聚类分析meanshift
作者:小蓝xlanll | 2024-06-13 15:23:06
赞
踩
聚类分析meanshift
1 导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
from collections import Counter
from sklearn.datasets import make_blobs, make_circles, make_moons, make_classification
from sklearn.cluster import KMeans, MiniBatchKMeans, DBSCAN, AgglomerativeClustering, MeanShift
from sklearn.decomposition import PCA
from sklearn.metrics import adjusted_rand_score, silhouette_score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2 构建数据
step1:使用sklearn自带的函数make_blobs()、make_circlues()、make_moons()、make_classification()构建数据集
step2:绘制二维散点图
step3:定义绘图函数便于下面使用,为了避免估计的标签类别数少于实际类别数导致计算轮廓系数报错,故加上try-except语句
# 生成数据集 X1, y1 = make_blobs(n_samples=1000, n_features=2, centers=4, shuffle=True, random_state=3) X2, y2 = make_circles(n_samples=1000, noise=0.05, factor=0.6, shuffle=True, random_state=0) X3, y3 = make_moons(n_samples=1000, noise=0.05, shuffle=True, random_state=0) X4, y4 = make_classification(n_samples=1000, n_features=2, n_classes=3, n_redundant=0, n_repeated=0, n_clusters_per_class=1, shuffle=True, random_state=5) # 绘制图 # 1 dataset1 = pd.DataFrame({"x1": X1[:, 0], "x2": X1[:, 1], "label": y1}) plt.figure(figsize=(6, 6)) grouped = dataset1.groupby('label') colors = ['r', 'g', 'b', 'm'] for label, df in grouped: plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=colors[label], s=1, label=label) plt.legend() plt.show() # 2 plt.figure(figsize=(6, 6)) plt.scatter(X2[:, 0], X2[:, 1], c=y2, s=1) plt.show() # 3 plt.figure(figsize=(6, 6)) plt.scatter(X3[:, 0], X3[:, 1], c=y3, s=1) plt.show() # 4 plt.rcParams['figure.figsize'] = (12, 6) plt.subplots(1, 2) plt.subplot(1, 2, 1) plt.scatter(X4[:, 0], X4[:, 1], c=y4, s=1) plt.subplot(1, 2, 2) sns.kdeplot(x=X4[:, 0]) plt.show() # 打印预测的散点图 def plot_predict_scatters(datas): plt.rcParams['figure.figsize'] = (16, 16) plt.subplots(2, 2) for i, data in enumerate(datas): x, y, y_predict = data plt.subplot(2, 2, i + 1) plt.scatter(x[:, 0], x[:, 1], c=y_predict, s=1) rand_score = adjusted_rand_score(y, y_predict) try: sil_score = silhouette_score(x, y_predict) except Exception as e: warnings.warn(message=str(e)) sil_score = None plt.title('Figure %d: rand_score=%.2f' % (i + 1, rand_score)) if sil_score != None: plt.title('Figure %d: rand_score=%.2f sil_score=%.2f' % (i + 1, rand_score, sil_score)) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
展示:
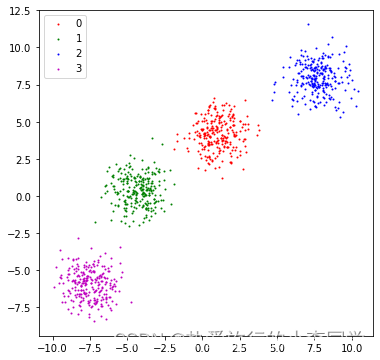
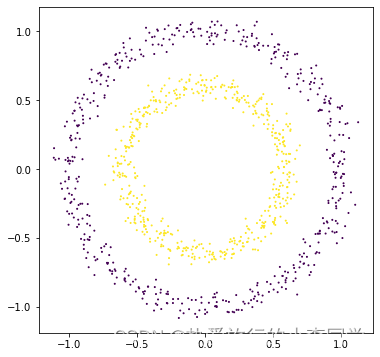
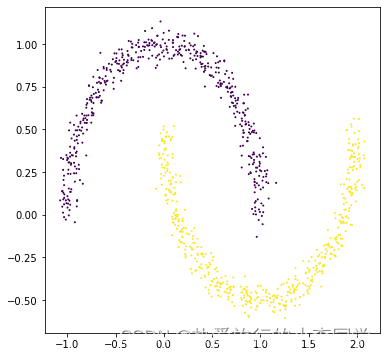
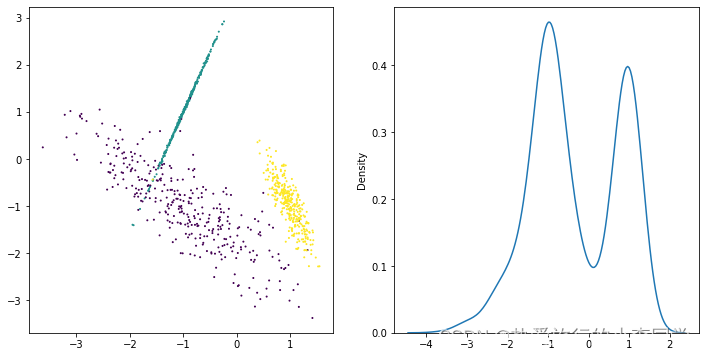
3 模型对比
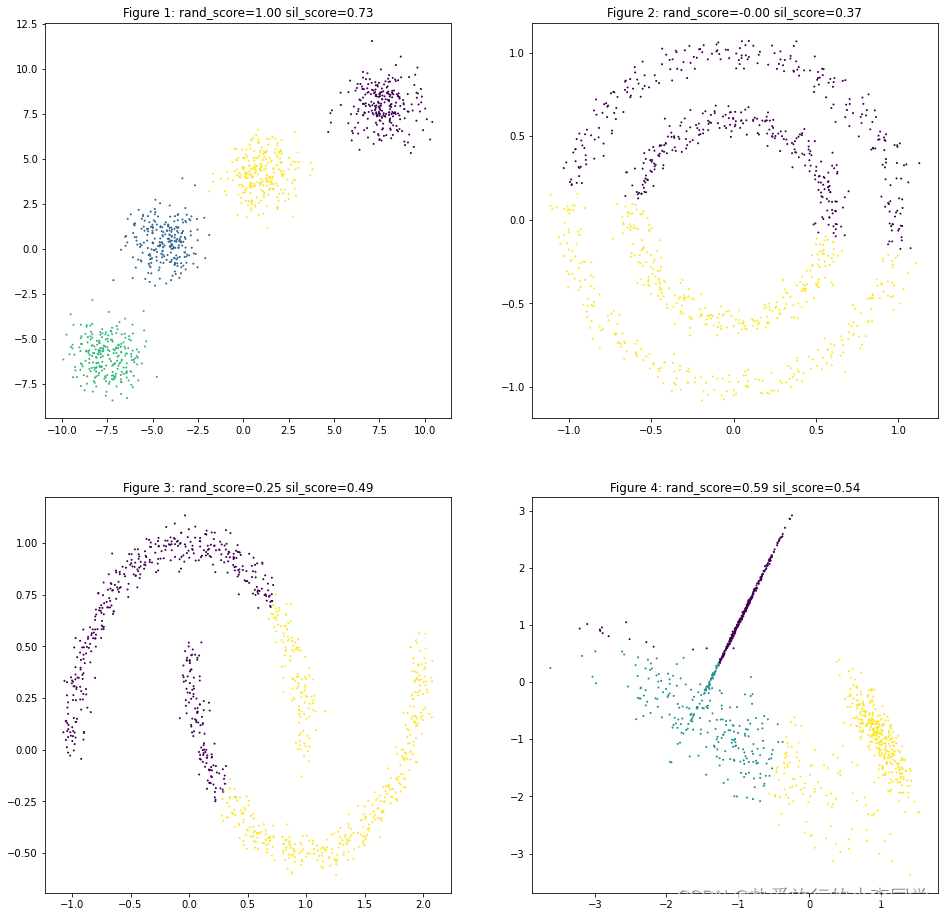
Kmeans
# KMeans聚类
y_predict11 = KMeans(n_clusters=4).fit_predict(X1)
y_predict12 = KMeans(n_clusters=2).fit_predict(X2)
y_predict13 = KMeans(n_clusters=2).fit_predict(X3)
y_predict14 = KMeans(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict11),
(X2, y2, y_predict12),
(X3, y3, y_predict13),
(X4, y4, y_predict14)]
plot_predict_scatters(datas)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
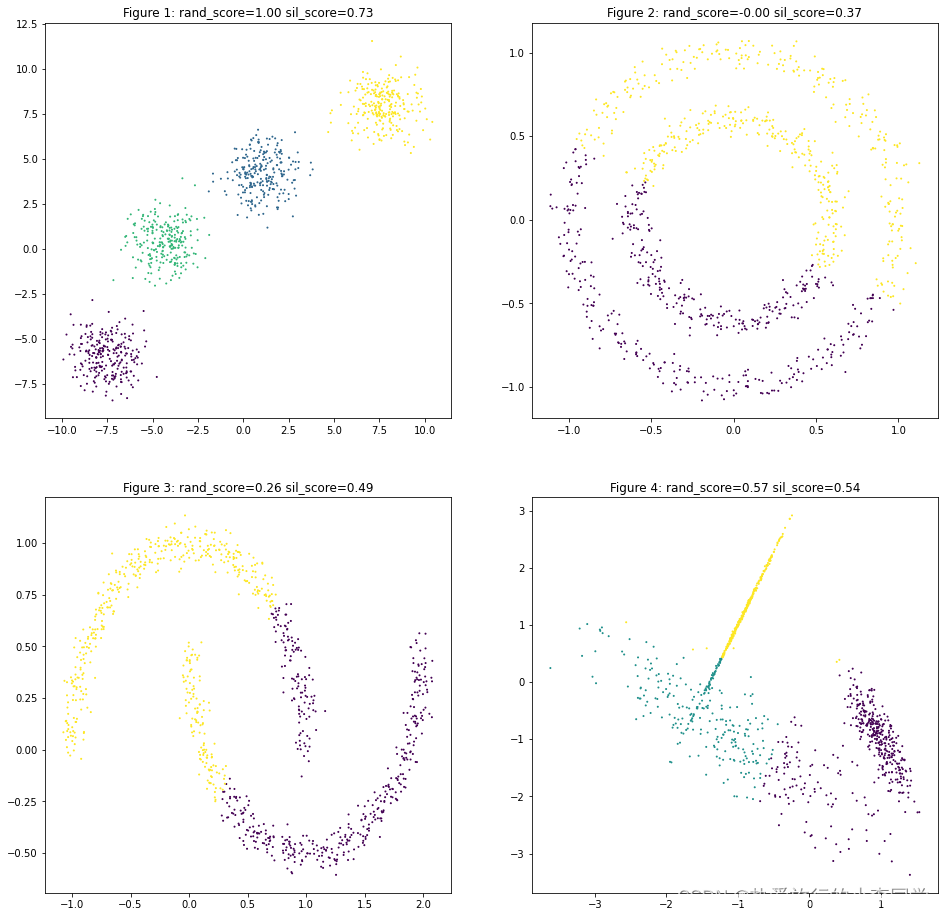
MiniBatchKmeans
# MnniBatch聚类
y_predict21 = MiniBatchKMeans(n_clusters=4).fit_predict(X1)
y_predict22 = MiniBatchKMeans(n_clusters=2).fit_predict(X2)
y_predict23 = MiniBatchKMeans(n_clusters=2).fit_predict(X3)
y_predict24 = MiniBatchKMeans(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict21),
(X2, y2, y_predict22),
(X3, y3, y_predict23),
(X4, y4, y_predict24)]
plot_predict_scatters(datas)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
DBSCAN
# DBSCAN聚类
y_predict31 = DBSCAN(eps=1.0, min_samples=10).fit_predict(X1)
y_predict32 = DBSCAN(eps=0.2, min_samples=50).fit_predict(X2)
y_predict33 = DBSCAN(eps=0.2, min_samples=20).fit_predict(X3)
y_predict34 = DBSCAN(eps=0.1, min_samples=10).fit_predict(X4)
datas = [(X1, y1, y_predict31),
(X2, y2, y_predict32),
(X3, y3, y_predict33),
(X4, y4, y_predict34)]
plot_predict_scatters(datas)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
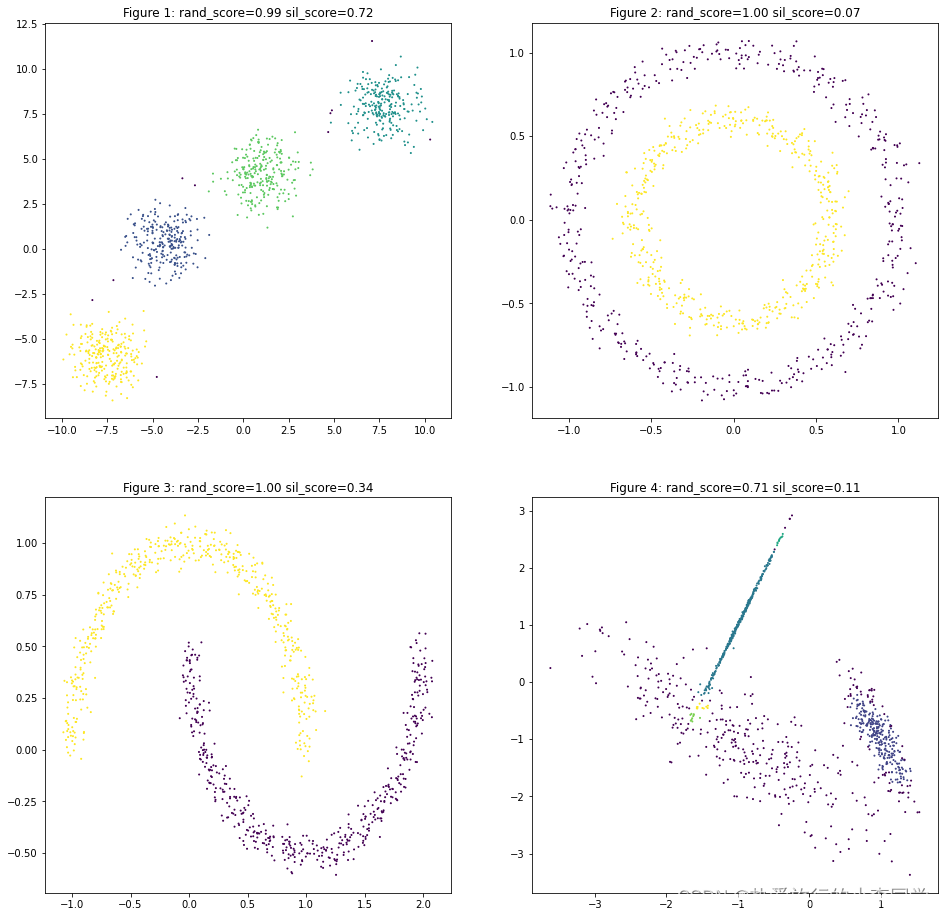
DBSCAN对第2类、第3类、第4类聚类效果均好于KMeans,不过需要适当的调参。
AgglomerativeClustering
# 层次聚类
y_predict41 = AgglomerativeClustering(n_clusters=4).fit_predict(X1)
y_predict42 = AgglomerativeClustering(n_clusters=2).fit_predict(X2)
y_predict43 = AgglomerativeClustering(n_clusters=2).fit_predict(X3)
y_predict44 = AgglomerativeClustering(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict41),
(X2, y2, y_predict42),
(X3, y3, y_predict43),
(X4, y4, y_predict44)]
plot_predict_scatters(datas)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
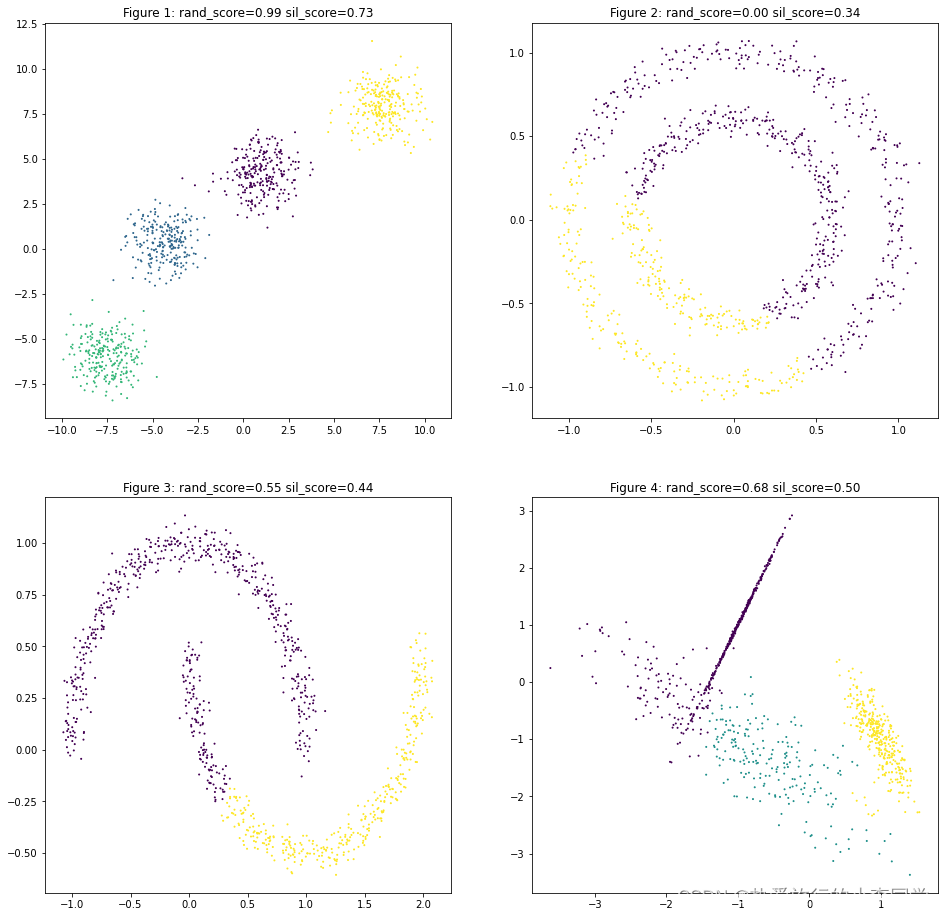
MeanShift
# MeanShift
y_predict51 = MeanShift(bandwidth=1).fit_predict(X1)
y_predict52 = MeanShift().fit_predict(X2)
y_predict53 = MeanShift().fit_predict(X3)
y_predict54 = MeanShift().fit_predict(X4)
datas = [(X1, y1, y_predict51),
(X2, y2, y_predict52),
(X3, y3, y_predict53),
(X4, y4, y_predict54)]
plot_predict_scatters(datas)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
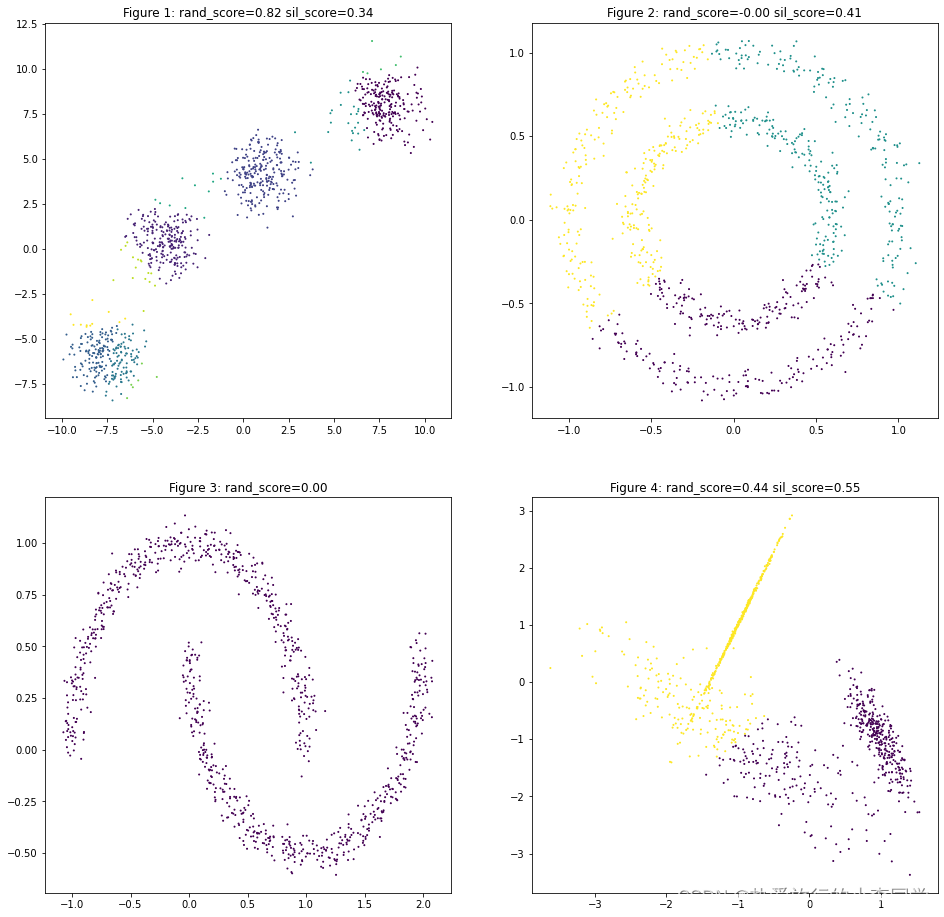
可以观察到MeanShift对第3类数据聚类结果只聚为了1类,因此兰德指数为0,轮廓系数无法计算。
4 总结
聚类的评价指标
兰德指数:计算真实标签与聚类标签两种分布相似性之间的相似性,取值范围为 [0,1]
轮廓系数:是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。 它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。取值范围:[-1,1],轮廓系数越大,聚类效果越好
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

