
- 1C++中的参数传递方式:传值、传地址、传引用总结_c++实参是对象 传值还是引用
- 2如何优雅地完整的一键卸载腾讯云监控(sgagent && barad_agent)
- 3通过xbt_tracker.pid实现自动重启xbt_tracker
- 4【openvino+树莓派】实现实时摄像头人脸检测_openpose部署树莓派
- 5SpringCloud Gateway + Jwt + Oauth2 实现网关的鉴权操作
- 6国基北盛-openstack-容器云-环境搭建_国基北盛容器云
- 7关键点平滑算法笔记
- 8记录导入excel转换类型报错问题_@excelproperty 导入支持integer类型吗
- 9关于def __init__(self)的一些知识点_def __init__(self):
- 10计算机数值分析:线性方程组的迭代法:雅可比迭代公式(Python实现_雅可比迭代算法程序流程图
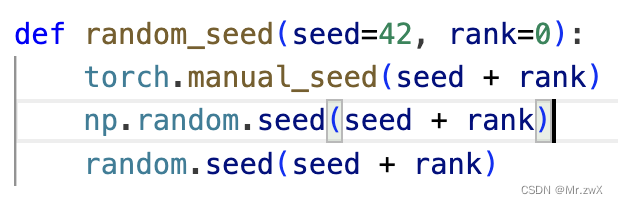
【随机种子初始化】一个神经网络模型初始化的大坑_模型初始数据的随机化
赞
踩
1 问题起因和经过
半年前写了一个模型,取得了不错的效果(简称项目文件1),于是整理了一番代码,保存为了一个新的项目(简称项目文件2)。半年后的今天,我重新训练这个整理过的模型,即项目文件2,没有修改任何的超参数,并且保持完全一致的随机种子,但是始终无法完全复现出半年前项目文件1跑出来的结果(按道理来说,随机种子控制好后,整个训练过程都应该能够复现,第一个epoch的accuracy就应该对上)。我找到项目文件1,跑了跑,能复现之前的训练结果。并且,分别训练项目文件1和2的模型,都能重复自己的训练结果,而两个项目文件的结果无法对上。
花了半天的时间反复仔细检查数据集和训练超参数的设置后,也没能看出项目文件2有什么毛病。非常奇怪,为什么同样的模型、配置、服务器、随机种子,在不同的项目文件中出现不同的结果?!实在想不通。
于是,决定动手debug看看问题出在了哪里。
我发现第一个epoch的结果就对不上,所以我猜测问题出在了模型的初始化上,那初始化与什么相关呢?很自然地,我把问题聚焦在了随机种子上,是不是没有有效固定住随机性?所以我将两个项目文件构建model后的参数打印出来看了看,发现,完全不同!
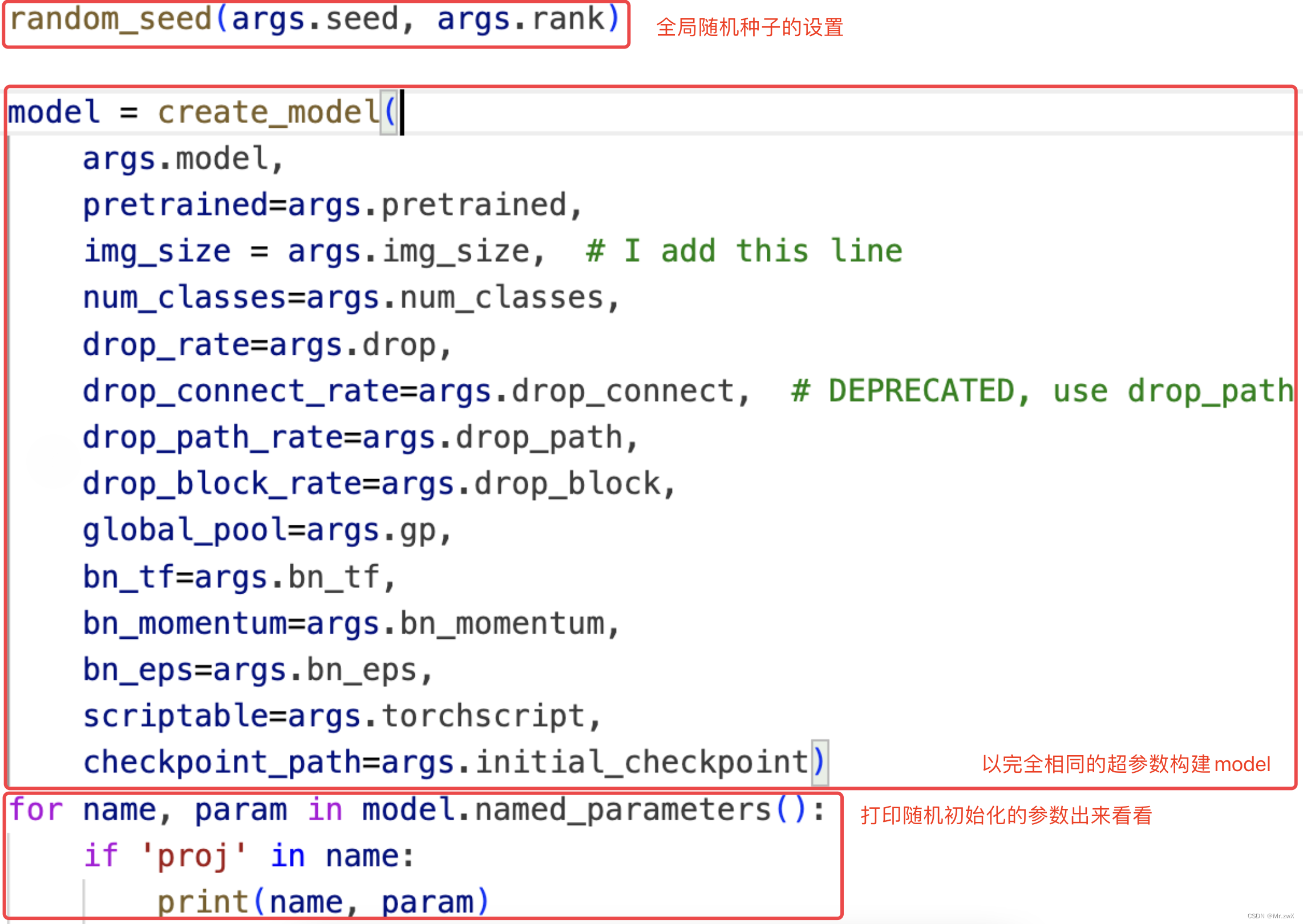
项目文件1中的部分打印结果:

项目文件2中的部分打印结果:

很明显地说明了一件事:同样的随机种子,在这两个项目文件中,产生了完全不一样的初始化值! 这个结果是违背我的常识的,为什么会出现这样的情况?
于是,我 猜测是不是因为两个项目在同一服务器上发生了未知的冲突,所以我copy了一份项目文件1为项目文件3,然后跑项目文件3的初始化结果,发现和项目文件1的初始化结果一致,居然没问题!?那这个项目文件2怎么回事,凭空出现了不同的初始化值?
排除了项目冲突这个猜想后,我把视野放在了模型本身上。我试着print(model)进行观察,发现项目文件2相比项目文件1的模型架构多了一些参数,这些参数是我当初在整理代码并补充新算法时补充定义的(比如:self.gamma = Parameter(torch.randn((1, self.num_heads, 1, 1)))),但是后面并没有真正用上这个参数。
于是,我又有了一个新的猜想:是不是因为多出来的这些新定义的参数,导致在同一随机种子的设置下,仍然出现不一致的初始化行为?
顺着这个思路,我给项目文件1做了如下简单的尝试:直接给模型架构多定义一个模块,但无需使用它,看看初始化是否受影响。 这里我简单加了个nn.Linear()进去。
代码解释如下,原本的架构为:
class Attention(Module): """ Obtained from timm: github.com:rwightman/pytorch-image-models """ def __init__(self, dim, num_heads=8, attention_dropout=0.1, projection_dropout=0.1): super().__init__() self.num_heads = num_heads head_dim = dim // self.num_heads self.scale = head_dim ** -0.5 self.qkv = Linear(dim, dim * 3, bias=False) self.attn_drop = Dropout(attention_dropout) self.proj = Linear(dim, dim) self.proj_drop = Dropout(projection_dropout) self.relu = ReLU() self.eps = 1e-8 self.alpha = Parameter(torch.ones(1, self.num_heads, 1, 1), requires_grad=False) self.alpha.data.fill_(1.0) def forward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
我在init函数中多定义一行线性层后为:
class Attention(Module): """ Obtained from timm: github.com:rwightman/pytorch-image-models """ def __init__(self, dim, num_heads=8, attention_dropout=0.1, projection_dropout=0.1): super().__init__() self.num_heads = num_heads head_dim = dim // self.num_heads self.scale = head_dim ** -0.5 self.qkv = Linear(dim, dim * 3, bias=False) self.attn_drop = Dropout(attention_dropout) self.proj = Linear(dim, dim) self.proj_drop = Dropout(projection_dropout) self.relu = ReLU() self.eps = 1e-8 self.alpha = Parameter(torch.ones(1, self.num_heads, 1, 1), requires_grad=False) self.alpha.data.fill_(1.0) self.linear = Linear(dim, dim) # 这里是新加的模块,但是无需使用 def forward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
于是,打印初始化参数得到:

初始化的结果仍然改变了!!! 看来果然是模型架构的不一致性导致了随机种子“失效”。
2 总结上述问题
两个项目文件,看似模型、超参数、数据集、随机种子、服务器完全一致时,发现训练时两者无法保持完全一致,并且进一步发现两个项目文件在初始化模型参数时就不一致了。
而单独地重复训练每一个项目文件,都能重复自身的结果。
直观感觉就是随机种子并没有有效地作用到另一个项目上,是一个很奇怪的问题,有点违背常识。
3 总结解决方案
训练过程不一致是表象,实际上是模型初始化就不一致了。
如果想要用随机种子控制模型初始化参数完全一致,就必须保证模型的架构完全一致! 但凡在model类的init函数里多定义一个无用参数比如Linear,都会改变整个初始化结果,从而影响后面的训练进程(应该是很微小的影响,但是对于我们复现项目时扣细节来说,会放大这个影响)。
4 可能的解释
咨询了一些遇到过这个问题的同学,大概有如下的可能的解释:在模型的定义中加入了新的模块后,不管是否真正使用,都会影响初始化(已控制了随机种子)。因为加入了新的模块后,整个初始化的顺序会发生改变,于是就乱套了。随机种子只能保证你调用后生成的随机数列是一样的,而在构建模型时的调用顺序,是会随着模型架构的改变而改变的。

