
热门标签
热门文章
- 1ArrayBuffer转为base64字符串_arraybuffertobase64
- 2python基础(八):函数yield生成器和iter迭代器_yield iter
- 3[LeetCode][C++]单词接龙_c++单词接龙
- 4win11预览版更新,并尝试使用Copilot_vivetool v0.3.3
- 5使用python爬取互联网设备信息
- 6安装glibc_glibc2.27安装
- 7python+opencv显示图片的直方图、高斯滤波、直方图均衡化的结果_显示图片直方图
- 8(LeetCode)Java 求解盛最多水的容器_盛最多水的容器 java栈
- 9详解gmssl和tls1.2握手流程分析及接口实现
- 10HTML中常用的颜色词汇
当前位置: article > 正文
使用go-llama.cpp 运行 yi-01-6b大模型,使用本地CPU运行,速度挺快的
作者:很楠不爱3 | 2024-02-22 20:38:52
赞
踩
使用go-llama.cpp 运行 yi-01-6b大模型,使用本地CPU运行,速度挺快的
1,视频地址
2,关于llama.cpp 项目
https://github.com/ggerganov/llama.cpp
LaMA.cpp 项目是开发者 Georgi Gerganov 基于 Meta 释出的 LLaMA 模型(简易 Python 代码示例)手撸的纯 C/C++ 版本,用于模型推理。所谓推理,即是给输入-跑模型-得输出的模型运行过程。
那么,纯 C/C++ 版本有何优势呢?
无需任何额外依赖,相比 Python 代码对 PyTorch 等库的要求,C/C++ 直接编译出可执行文件,跳过不同硬件的繁杂准备;
支持 Apple Silicon 芯片的 ARM NEON 加速,x86 平台则以 AVX2 替代;
具有 F16 和 F32 的混合精度;
支持 4-bit 量化;
golang 的项目地址:
https://github.com/go-skynet/go-llama.cpp
3,准备工作,解决cgo编译问题
关于go-llama.cpp 项目地址:
https://github.com/go-skynet/go-llama.cpp
首先下载模型:
https://hf-mirror.com/TheBloke/Yi-6B-GGUF/tree/main
然后运行测试:
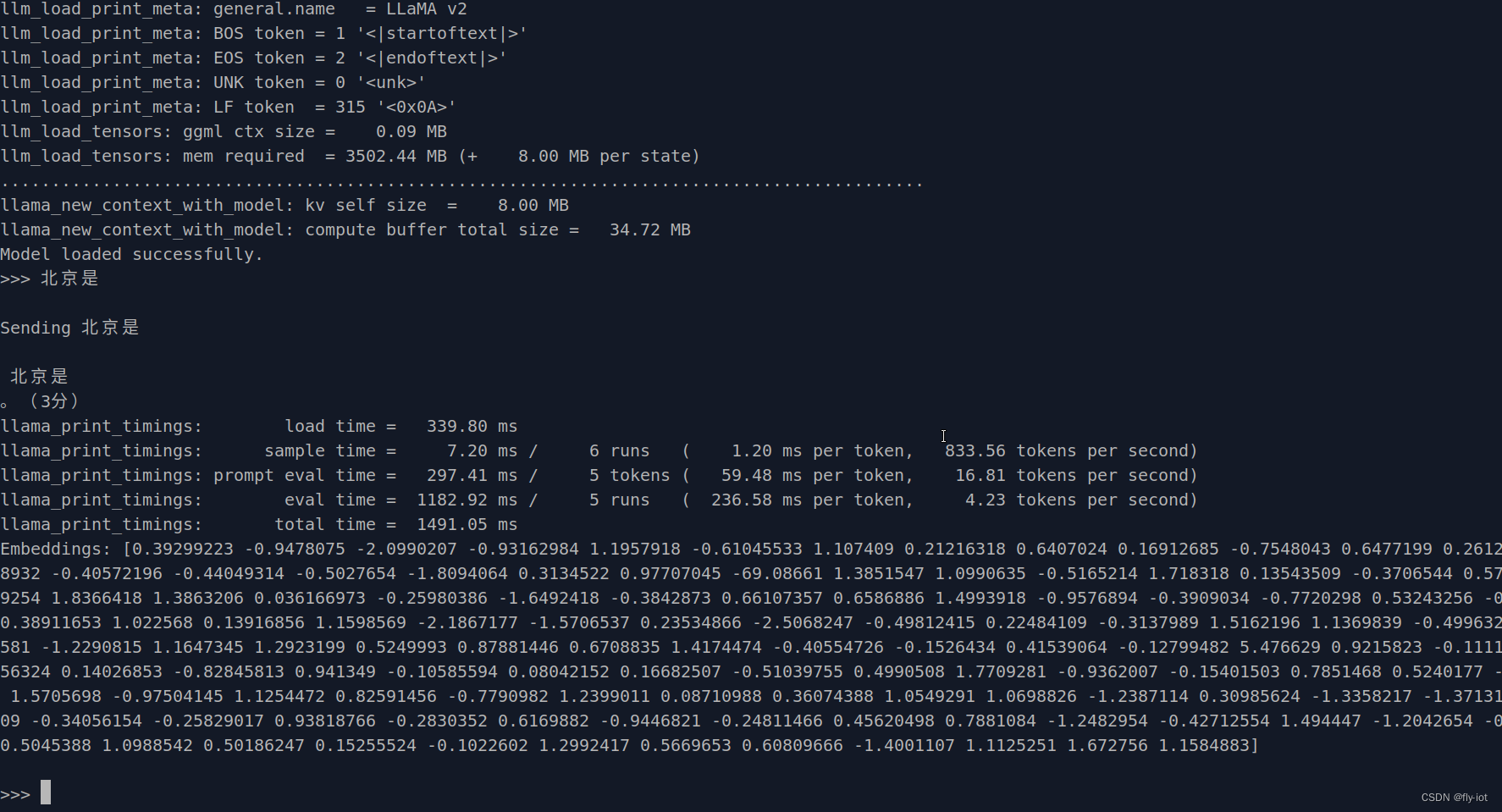
虽然模型回答的不太对,但是可以运行了,速度确实还可以。
4,只要是llama.cpp支持的模型就可以
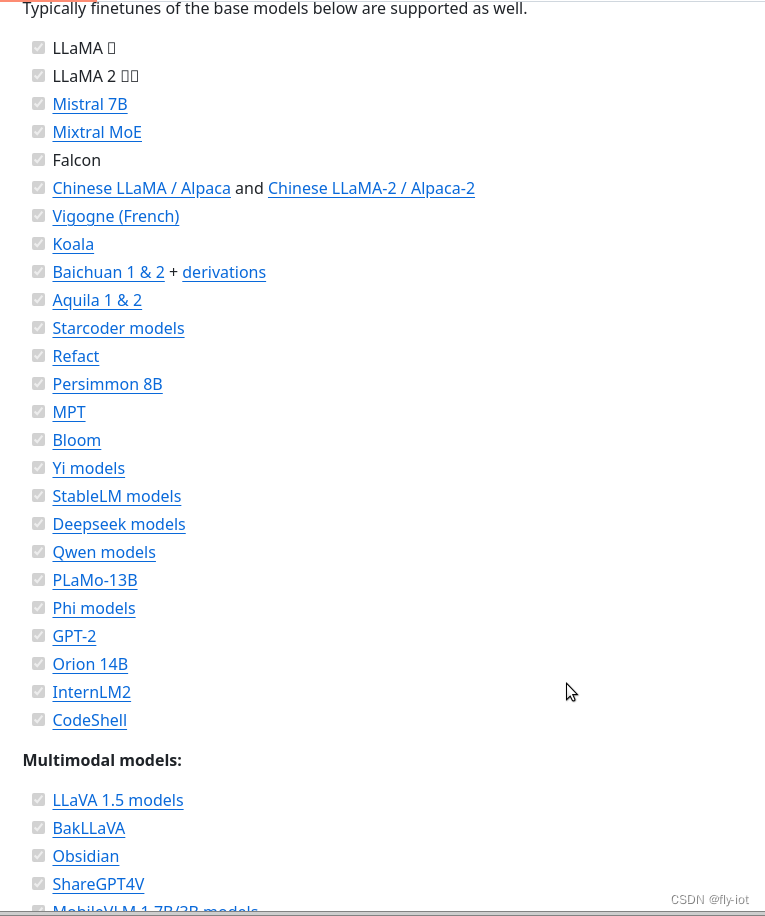
已经支持很多模型了,都需要测试下效果。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/131337
推荐阅读
相关标签

