
- 1园区内网配置——华为
- 2C语言实现二叉树(链式)_写出用 c 语言定义一个二叉树的二叉链表结点结构的算法。
- 3ECCV2020 商汤提出语义分割模型新框架
- 41.3 Photoshop工作区的操作讲解 [Ps教程]_ps怎么导入保存好的工作区设置
- 5Mac:Flutter环境配置_script '/users/zon/library/flutter/packages/flutte
- 6iOS手机模拟器配置
- 7mq4气体传感器流程图_气体传感器Word版
- 8spring boot application.properties 配置参数详情_allow-pool-suspension
- 9局域网下mac与win通过ssh互联(端口映射)_mac ssh windows
- 10Python--break语句_python break语句
手把手教你做一个 ChatGPT !丝滑小白版,只需一张单卡 GPU,轻松开启个性化训练!...
赞
踩
大家好,我是贺同学。
一直以来密切关注 ChatGPT 的趋势,最近相关的话题可谓是热度不减,虽然从事互联网行业,但一直对 LLM 相关领域关注较少。
最近的 ChatGPT 的火热,让我对 LLM 相关开源社区也关注了起来,相关的开源社区,也涌现了很多优秀的工作,吸引了很多人的关注。
其中,大家比较关注的是 Stanford 基于 LLaMA 的 Alpaca 和随后出现的 LoRA 版本 Alpaca-LoRA。原因很简单,便宜。
https://github.com/tloen/alpaca-lora
Alpaca 宣称只需要 600$ 不到的成本(包括创建数据集),便可以让 LLaMA 7B 达到近似 text-davinci-003 的效果。而 Alpaca-LoRA 则在此基础上,让我们能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
下面是开源社区成员分享的可以跑通的硬件规格及所需时间:
| GPU 规格 | Epochs | 训练耗时 (h) |
|---|---|---|
| RTX 4070 Ti 12GB | 2 | 9.8 |
| RTX 4080 16GB | 2 | 5.5 |
| RTX 4090 24GB | 2 | 4 |
| 2 * RTX 3090Ti 24GB | 3 | 4.5 |
根据大家分享的信息,fine-tune 7B 模型仅需要 8-10 GB vram。因此我们很有可能可以在云服务器上完成所需要的 fine-tune!
另外,自 ChatGPT 惊艳问世后,大模型部署的话题一直高热不退,但是这里面存在两个显著的问题:
一方面 ChatGPT 只有蛛丝马迹的论文,没有开源代码;另一方面 ChatGPT 官方公布的训练硬件配置,至少数千块 80G A100 的高昂算力成本。
以上两点,无论哪一个,对于很多想尝试动手搭建的普通人或者非计算机行业的朋友们,都是不小的挑战,导致很多个人用户无法上手。
那么,有个想法就在脑子里酝酿了,我们能不能自己动手训练一个ChatGPT出来呢?说干就干!

和小伙伴一起,花了一个周末,经过不断尝试踩坑,终于在云服务器上调通了!基于最新的 Stanford 发布的基于 LLaMA的Alpaca-LoRA,70 亿参数规模,只需要 A5000,3090 等最低 24G 显存的消费级的单卡 GPU 就可以训练。
而且还可以更新语料库进行训练,这一步,无疑大大降低了大语言模型的上手入门的门槛,我一直坚信,分享即学习,好知识值得分享和传播,话不多说,我们接下来开始进行逐步讲解。
第一步,搭建云 GPU 服务器环境
云 GPU 服务器,这里有两个厂商推荐(没有广告,纯粹推荐)
DBChina https://www.haibaogpu.com/wholeVirtual?type=gpu
阿某云的 GPU 服务器
根据个人情况租用或者购买,如果自己有更牛的硬件配置,那就当我没说,可以自己本地就 run 起来!
推荐跑模型的话,DBChina 平台推荐按小时去租一个单卡的机器,具体操作大家可以网上搜索。
其实看了下,最便宜的日租金大概算下来几十块钱,性价比还是可以的,所以想亲身体验的朋友,可以尝试一下。
笔者买的是阿某云 GPU服务器,这里推荐大家可以按量购买,参考下面的规格来买,一个 V100的 GPU,内存 >= 24G 的,这里我在厂商买的时候,最小的机器配置只有 92GB 的,所以就买了这个。
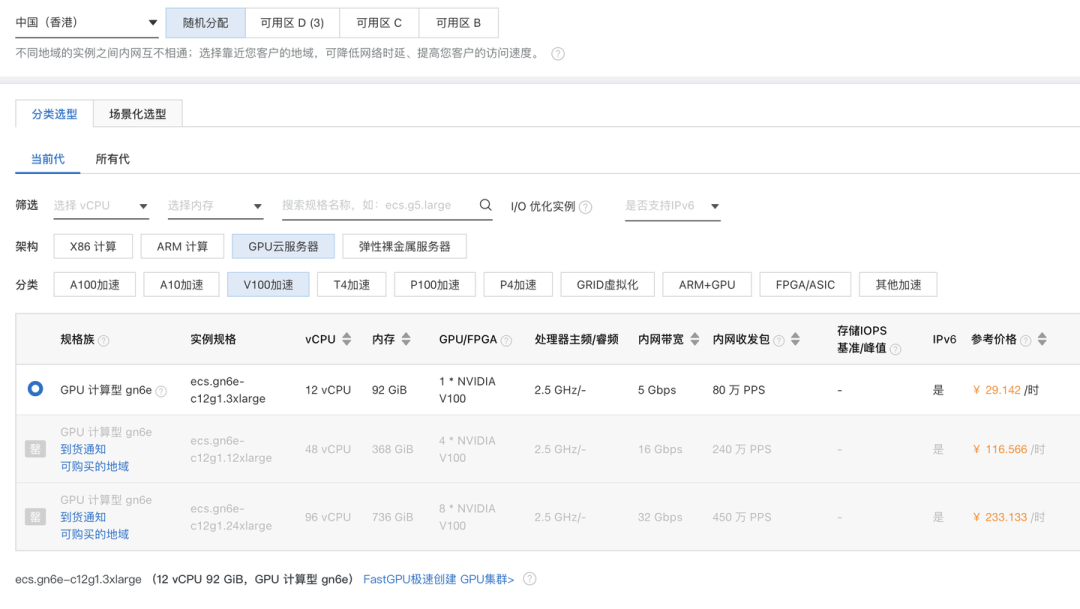
踩坑一:推荐买香港的或者国外的机器,下载开源仓库的时候需要访问 GitHub ,国内的机器大家懂的,会不太稳定,当切换了香港的机器之后,你就会立体验到那种丝滑的感觉!
第二步:配置机器
拿到机器后,登录进去,需要配置一下开发的环境,配置 Git ,命令:yum install git 安装 conda 环境,下载一个 miniconda 就好,非常快
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh其他版本下载地址:https://www.anaconda.com/products/distribution#Downloads
安装好之后,执行安装脚本,bash Miniconda3-latest-Linux-x86_64.sh 即可,一路 yes 。
接下来,需要下载 Alpaca-LoRA 项目代码,下载前,我们需要配置本地的 Git 的环境:
1. 设置的用户名和邮箱
2. 生成SSH Key密钥
3. 获取SSH Key密钥
- git cofig --global user.name "你的GitHub用户名"
- git config --global user.email "你的GitHub邮箱名"
- ssh-keygen -t rsa -C "你的GitHub邮箱名"
具体步骤可以参考网上文章,这里就不详细说了
那么机器配置好了 Git 环境之后,我们就可以正常下载代码了。
下载 Alpaca-LoRA 项目代码 终端输入命令:
git clone https://github.com/tloen/alpaca-lora.git创建对应的虚拟环境,并安装项目所需的依赖
- conda create -n alpaca python=3.9
- conda activate alpaca
- cd alpaca-lora
- pip install -r requirements.txt

接下来,我们下载项目训练的数据集
wget https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json(有坑)
踩坑二:这里有个坑,其他教程这里都说直接下载这个文件,当初我也是这个文件下载的,美滋滋的下载完开始跑的时候,发现报错了!
报错原因是文件格式不对!!导致模型启动失败!其实,上面这个文件格式不正确,至少在我今天跑的时候有问题,正确做法是执行这个命令:git clone https://github.com/LC1332/Chinese-alpaca-lora.git
克隆项目之后,切换到 data 目录下,可以看到 trans_chinese_alpaca_data.json 数据集文件的位置,把它 cp 一份,拷贝到 alpaca-lora 目录下。
所以说,注意下载完后,要进行检查,下载好的数据集文件内容格式是如下这样的 JSON 格式,这个数据集当然也可以更换成自己的 :

第三步:开始训练模型!
训练
进入 alpaca-lora 项目目录,执行命令
踩坑三:经验丰富的工程师,都会知道,一个命令如果需要长时间执行的话,最保险的做法就是把它挂到后台运行,这样及时你一不小心把前台关闭了,程序仍然老老实实的继续默默运行着。(老程序员也有大意失荆州的时候
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

