
- 1String中null变为"null"字符串的问题_将string中的null转为“”
- 2【高效能人士的七个习惯】 第二部分 个人的成功:从依赖到独立(史蒂芬·柯维)...
- 3【Java基础】对比Vector、ArrayList、LinkedList有何区别?_java vector与数组的区别
- 4ubuntu 如何使用阿里云盘_ubunut 如何挂载阿里云盘
- 5caused by: java.lang.ClassNotFoundException: org.springframework.transaction.ReactiveTransactionMana
- 6【编程技术】低代码开发的入门到精通_低代码开发学习
- 7fastboot 详解_fastboot 位于 系统包 那个位置
- 8Android 获取签名公钥 和 公钥私钥加解密_android 获取app 公钥 数字格式
- 9效率神器,边看网页边问ChatGPT!神级ChatGPT插件(浏览器扩展)推荐!_sider 原理
- 10反编译微信小程序,可导出uniapp或taro项目_微信小程序反编译uniapp
GradCAM神经网络可视化解释(原理和实现)_gradcam可视化
赞
踩
GradCAM是经典的特征图可视化工具,在CV任务中,能用于分析CNN学到了什么东西。先看一张图:

这就是GradCAM做出的效果,它直观地表示出咱们模型认为图片是Dog的是依据哪些地方。
GradCAM借用梯度来进行注意力表示,发表于ICCV2017,如今依然活跃在学术和工程界。
论文链接:https://arxiv.org/abs/1610.02391
GradCAM原理
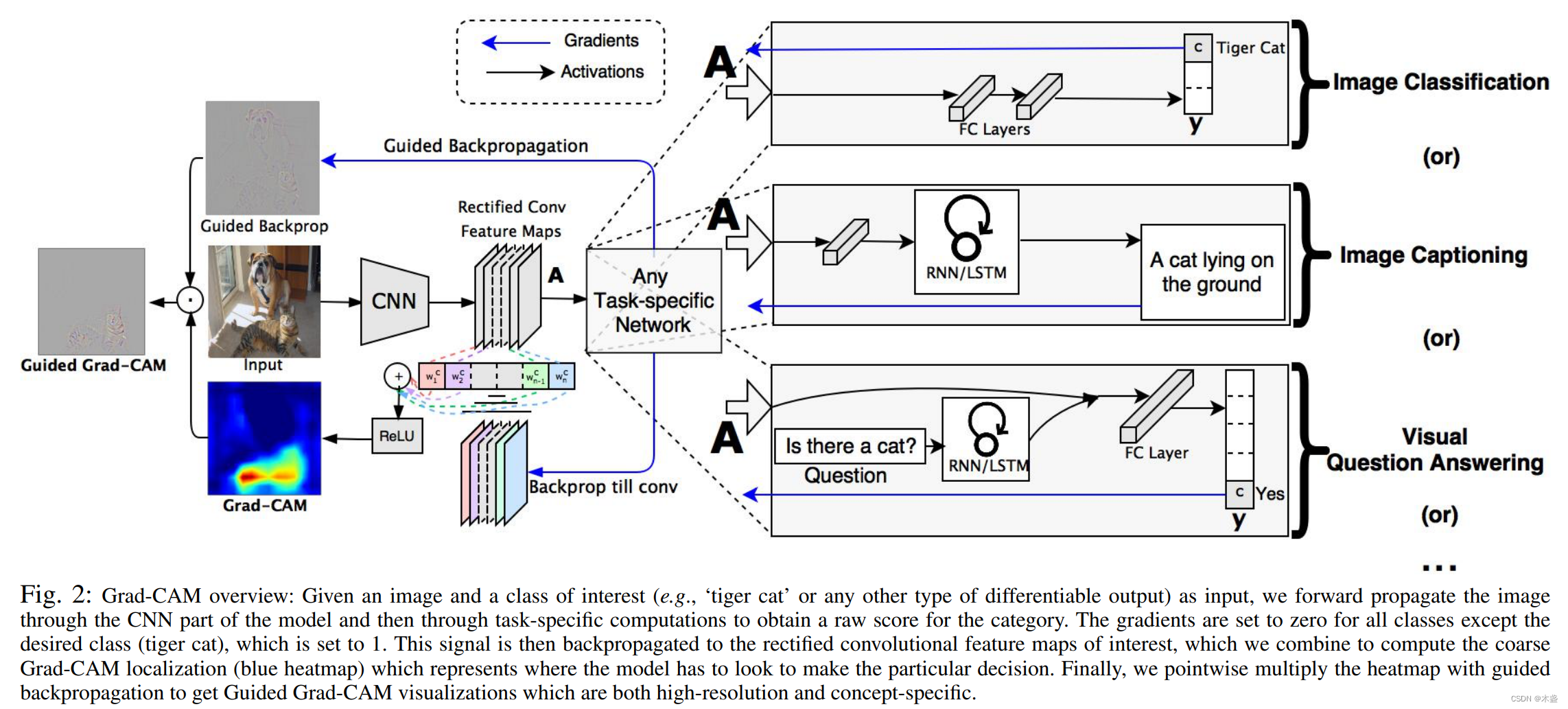
对于视觉任务,包括图像分类、目标检测等,通常都是backbone+head的形式。如图1所示。所以,GradCAM可以无差别地对各种视觉任务进行可视化。
在操作上,GradCAM拿到backbone的输出梯度,一般是4维张量,将这一层梯度进行平均化作为权重,然后跟这一层的输出张量做一个加权平均(先乘再加),然后过一层relu去掉负值,最后等比例投影在调整过的原图上。
我以图像分类为例进行剖析:(假设我们做5分类)
第一步,前向传播得到特征图。需要进行一次前向计算,得到backbone的特征图输出。
第二步,反向传播得到梯度。模型的输出为一个5-d的向量res,假设我们要看类别1的可视化,咱们就把res[1]当作loss进行反向传播。这么做的原理:咱们需要知道模型识别出类别1会认为哪些特征图是重要的,而梯度直接表达了参数要调整的方向,假设参数调整方向为正向,那么这些特征图就应该是重要的。所以,在这一层的对应位置的平均梯度可以表示该特征图的重要性,即权重。再结合第一步得到的特征图,进行加权平均就可以了~
咱们看一下代码:(来自https://github.com/leftthomas/GradCAM)
import cv2 import numpy as np import torch import torch.nn.functional as F import torchvision.transforms as transforms from torch.autograd import Variable class GradCam: def __init__(self, model): self.model = model.eval() self.feature = None self.gradient = None def save_gradient(self, grad): self.gradient = grad def __call__(self, x): image_size = (x.size(-1), x.size(-2)) datas = Variable(x) heat_maps = [] for i in range(datas.size(0)): img = datas[i].data.cpu().numpy() img = img - np.min(img) if np.max(img) != 0: img = img / np.max(img) feature = datas[i].unsqueeze(0) for name, module in self.model.named_children(): print(name) if name == 'classifier' or name == 'fc': feature = feature.view(feature.size(0), -1) feature = module(feature) if name == 'features' or name == 'backbone': feature.register_hook(self.save_gradient) # get backbone gradients self.feature = feature classes = torch.sigmoid(feature) print(torch.argmax(F.softmax(classes), dim=-1)) one_hot, _ = classes.max(dim=-1) self.model.zero_grad() one_hot.backward() weight = self.gradient.mean(dim=-1, keepdim=True).mean(dim=-2, keepdim=True) mask = F.relu((weight * self.feature).sum(dim=1)).squeeze(0) mask = cv2.resize(mask.data.cpu().numpy(), image_size) mask = mask - np.min(mask) if np.max(mask) != 0: mask = mask / np.max(mask) heat_map = np.float32(cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)) cam = heat_map + np.float32((np.uint8(img.transpose((1, 2, 0)) * 255))) cam = cam - np.min(cam) if np.max(cam) != 0: cam = cam / np.max(cam) heat_maps.append(transforms.ToTensor()(cv2.cvtColor(np.uint8(255 * cam), cv2.COLOR_BGR2RGB))) heat_maps = torch.stack(heat_maps) return heat_maps

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
代码中通过register_hook来获取backbone的梯度,想进一步了解hook的可戳《python中的register_hook》

