
- 1Verilog中双向端口(inout) 的原理和使用方法_verilog inout
- 2突破编程_前端_ACE编辑器(选中区域、跳转行以及点击事件)
- 3软件测试界的三无简历,企业拿什么来招聘你,石沉大海的简历_三无简历怎么找软件测试实习
- 4使用谷歌浏览器Chrome://inspect调试 cordova 项目_chrome inspect
- 5GAN在图像分割中的应用_gan做分割
- 62024年中国医疗领域AI Models Overview
- 7决胜关键——自动驾驶的云未来
- 8养老服务平台市场现状研究分析-_养老服务平台市场分析
- 9Idea必备插件、必要配置_idea代码提示插件
- 10安卓入门-动画(Animation)(由简单的单一动画到复杂的时间顺序叠加动画)(XML实现方式+JAVA实现方式)_android anim.xml顺序执行
28个python爬虫项目,看完这些你离爬虫高手就不远了_python爬虫可以爬取哪些数据
赞
踩
互联网的数据爆炸式的增长,而利用 Python 爬虫我们可以获取大量有价值的数据:
1.爬取数据,进行市场调研和商业分析
爬取知乎优质答案,筛选各话题下最优质的内容; 抓取房产网站买卖信息,分析房价变化趋势、做不同区域的房价分析;爬取招聘网站职位信息,分析各行业人才需求情况及薪资水平。
2.作为机器学习、数据挖掘的原始数据
比如你要做一个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。
3.爬取优质的资源:图片、文本、视频
爬取商品(店铺)评论以及各种图片网站,获得图片资源以及评论文本数据。
掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现。
但建议你从一开始就要有一个具体的目标,在目标的驱动下,你的学习才会更加精准和高效。这里给你一条平滑的、零基础快速入门的学习路径:
1.了解爬虫的基本原理及过程
2.Requests+Xpath 实现通用爬虫套路
3.了解非结构化数据的存储
4.应对特殊网站的反爬虫措施
5.Scrapy 与 MongoDB,进阶分布式
有些项目可能比较老了,不能用了,大家可以参考一下,重要的是一个思路,借鉴前人的一些经验,希望能帮到大家,需要的小伙伴们私信小编“学习”领取下资料包。
一、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
二、爬虫的基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求—>下载网页代码—>解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
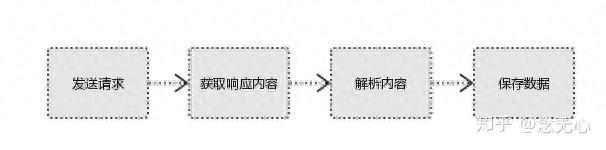
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
三、http协议 请求与响应

**Request:**用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
**Response:**服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
**ps:**浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、 request
1、请求方式:
常见的请求方式:GET / POST
2、请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
url编码
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意:一般做爬虫都会加上请求头
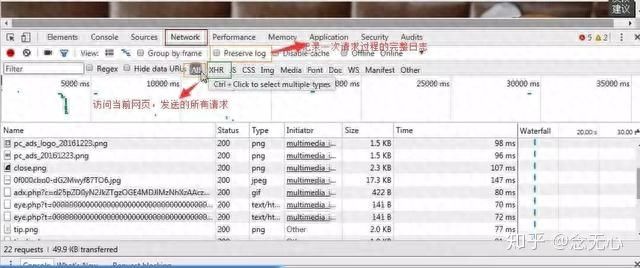
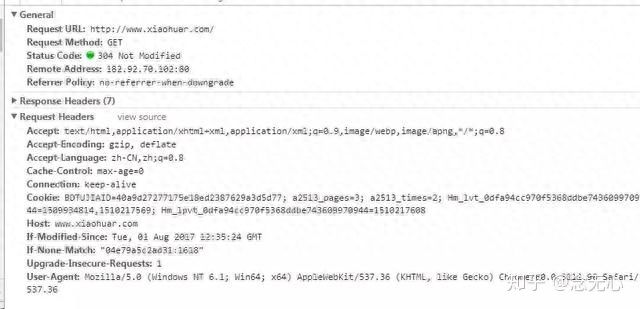
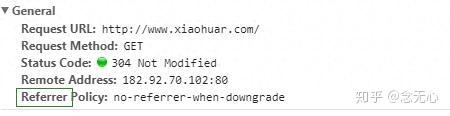
请求头需要注意的参数:
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
4、请求体
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应Response
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2、respone header
响应头需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(2)Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
3、preview就是网页源代码
JSON数据
如网页html,图片
二进制数据等
六、总结
1、总结爬虫流程:
爬取—>解析—>存储
2、爬虫所需工具:
**请求库:**requests,selenium(可以驱动浏览器解析渲染CSS和JS,但有性能劣势(有用没用的网页都会加载);) **解析库:**正则,beautifulsoup,pyquery **存储库:**文件,MySQL,Mongodb,Redis
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
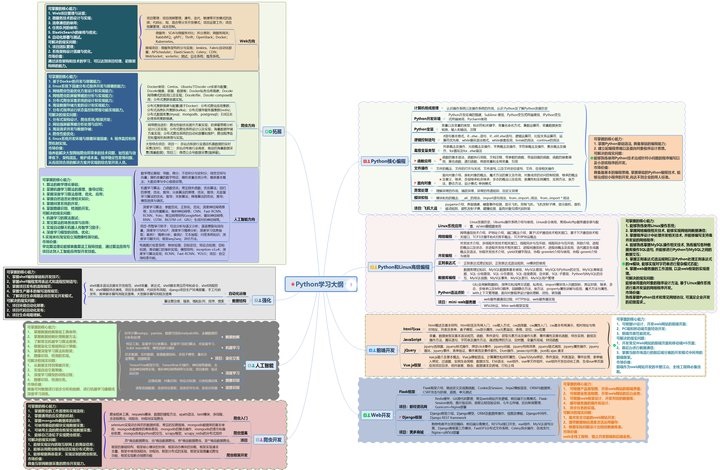
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
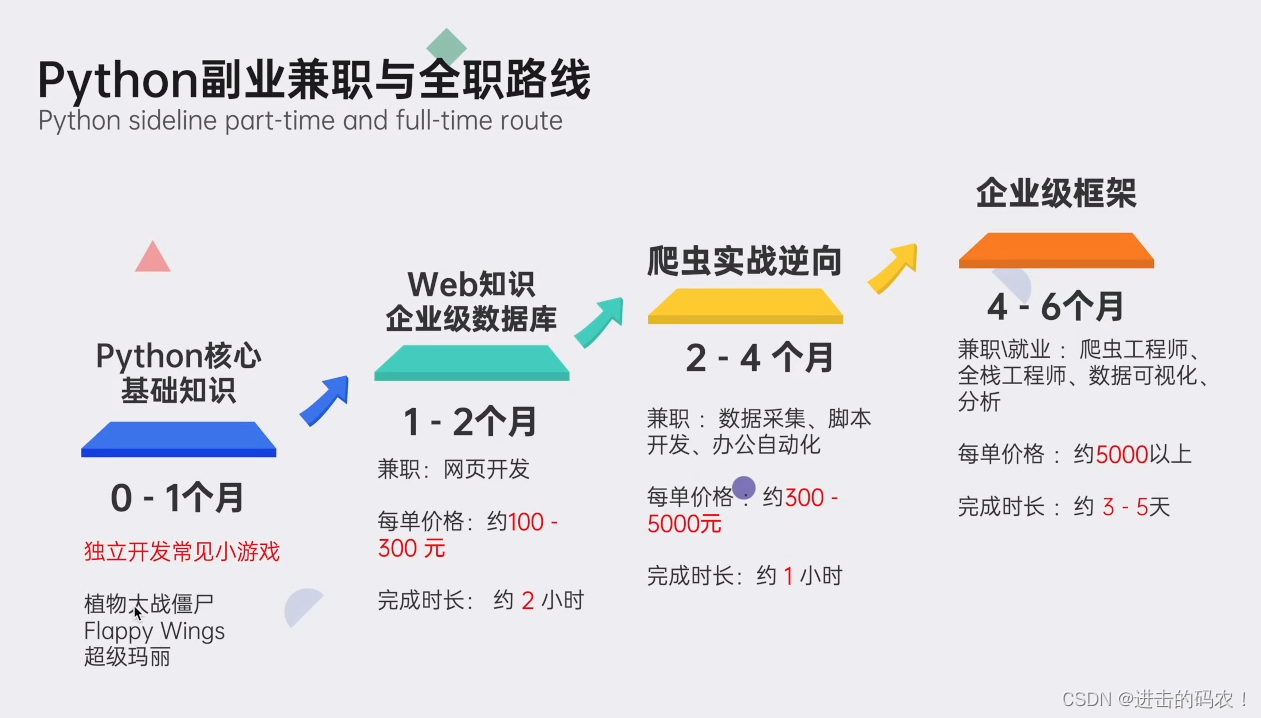
五、python副业兼职与全职路线
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

